






一、双重机器学习简介
最近,学界内有关双重机器学习的文献逐渐崭露头角,越来越多的研究者开始关注并应用这一方法,其应用范围逐步适用于区域经济学、发展经济学、环境经济学和企业金融等领域的政策评估。
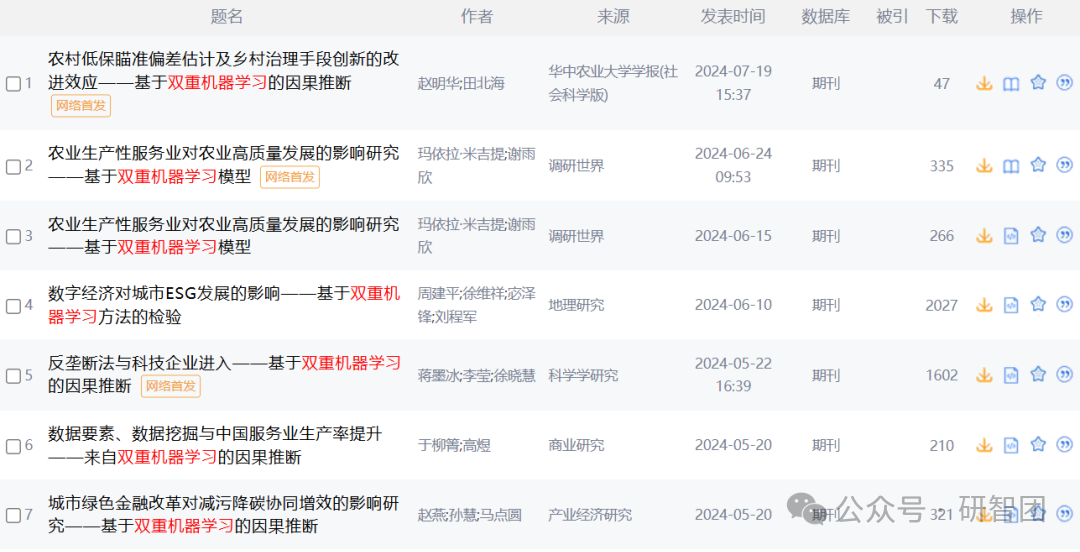
双重机器学习(Double/debiased Machine Learning, DDML)是一种专门用于因果推理的统计方法,它结合了传统回归分析和现代机器学习技术,以更准确地估计因果效应。其主要目的是在存在大量控制变量或高维数据的情况下,克服传统方法的局限性,提供更加稳健和无偏的因果效应估计。
双重机器学习的核心思想是将因果推理问题分解为两个独立的预测步骤,利用机器学习算法来提高因果效应估计的准确性和稳健性。首先,使用控制变量集预测结果变量(Y),得到预测残差,去除由控制变量解释的部分。接着,使用同样的控制变量集预测处理变量(X),得到其残差,去除控制变量的影响。最后,通过回归分析这两个残差来估计处理变量对结果变量的因果效应。这种方法在处理高维数据和复杂模型时,能够更好地拟合数据,减少由模型错误指定引入的偏差。
二、双重机器学习原理和模型
(1)双重机器学习估计原理
Y是被解释变量;T 是处置变量,即代表样本是否受到实验干预,通常是 0 或 1 的虚拟变量;X 是协变量,代表未被实验干预预测的个体特征,通常是高维向量。通常情况下,我们直接构建线性回归模型,即用 X 和 T 对 Y 回归,估计 T 的系数,这种方法假定了我们已知 X 的分布。
事实上,高维的 X 可能内部存在共线性,与 Y 是非线性关系,若单纯的用线性模型进行估计,会存在偏误。因此,我们应用机器学习模型估计 X 的分布,其中𝑓(⋅)和𝑔(⋅)为机器学习模型。
具体地,我们定义 ,即
,可以推导出
。所以估计
需要
和
。通过估计
和
,可以利用 Lasso、人工神经网络(ANN)、随机森林等机器学习方法拟合这两个期望函数。
(2)双重机器学习估计步骤
-
Step 1: 将数据集分为 K 个子样本
,即进行 K 折交叉验证。
-
Step 2: 在 K-1 个子集上训练
的函数形式,在剩余的子集上得到残差
。
-
Step 3: 在 K-1 个子集上训练
的函数形式,在剩余的子集上得到残差
。
-
Step 4: 重复 Step 2-3 K 次,然后运用 Frisch-Waugh-Lovell 定理,用
的估计。
三、双重机器学习stata代码
本文以双重机器学习方法的经典文献《网络基础设施、包容性绿色增长与地区差距——基于双重机器学习的因果推断》的附件代码为例,利用stata和python实现双重机器学习估计过程。
(1)python环境配置与scikit-learn库的安装
在 Stata 中使用 ddml 命令需要借助 Python 环境,因为许多机器学习模型都是使用 Python 中的 scikit-learn 库。因此,需要安装 Python 和 scikit-learn 包。大家可以自行安装这些软件包,参考网上的相关资料进行安装。安装完成后,在 Stata 中引入 Python 环境即可使用这些功能。
首先,进入python官网下载最新版本python,步骤如下所示:
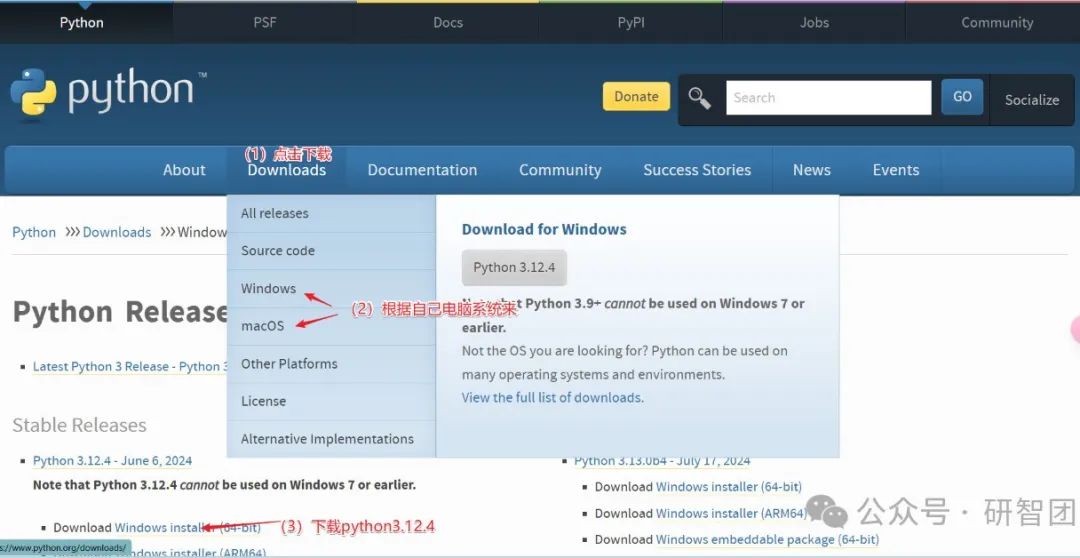
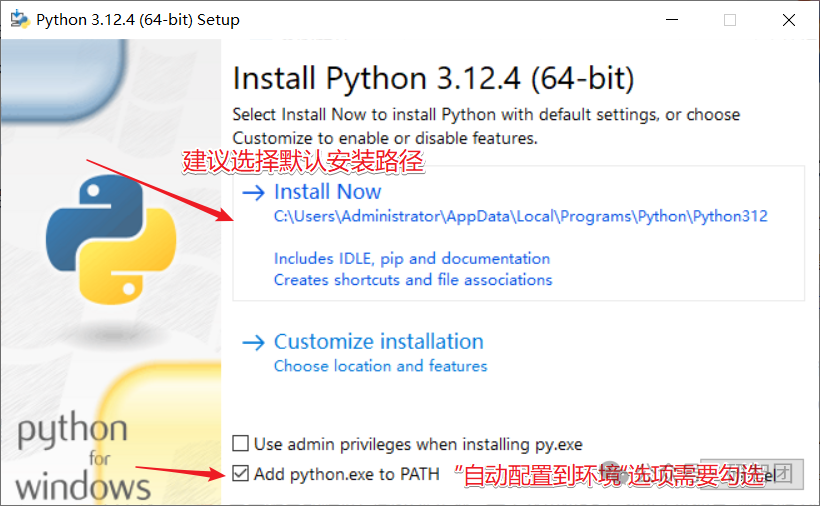
随后,安装python,选择默认路径安装,并勾选“Add Python to PATH”选项
进入终端进行python版本检查和库安装。
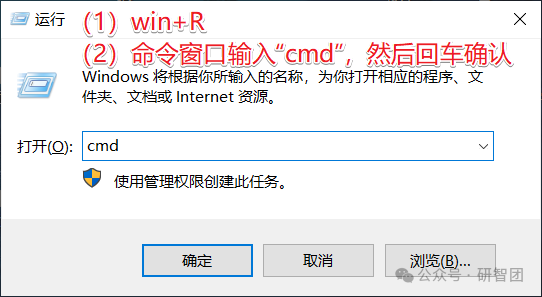
终端输入:输入“where python”检查python路径,并复制该路径。
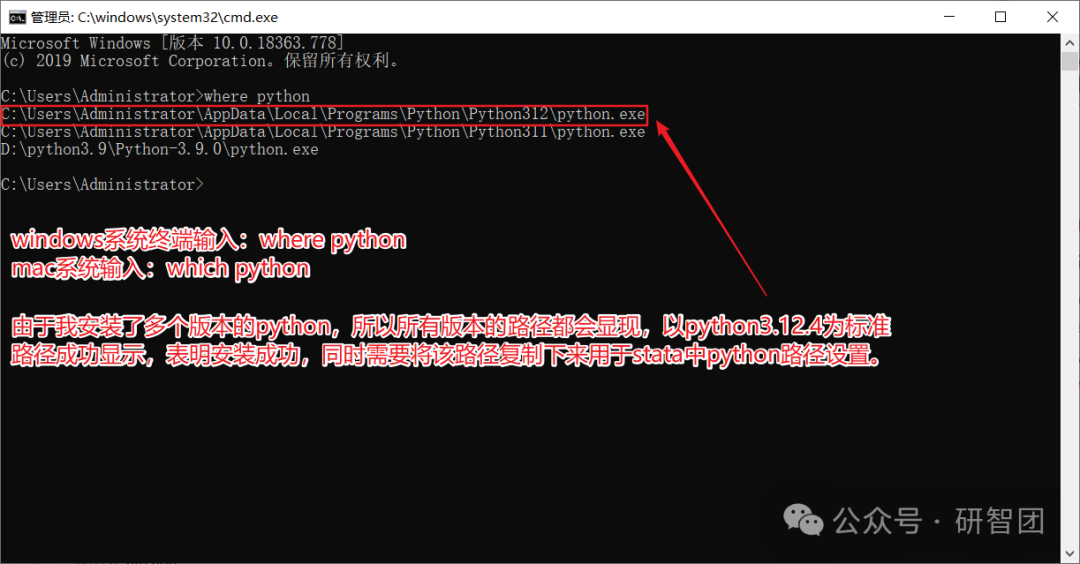
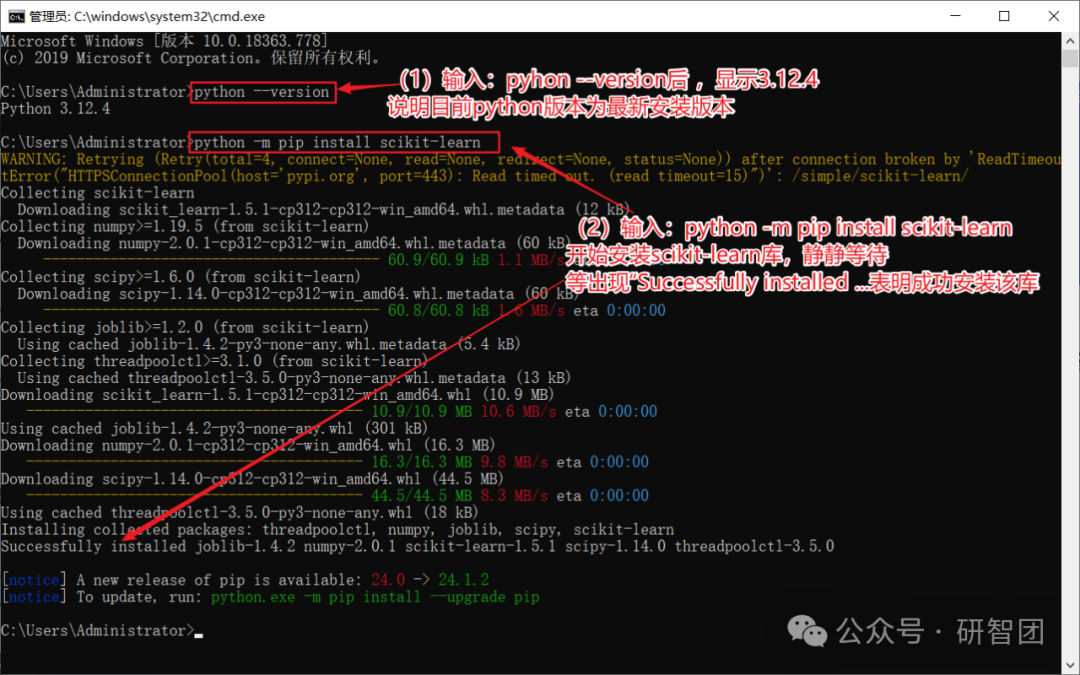
终端输入:输入“python3 --version”检查目前python版本号。
输入“python -m pip install scikit-learn”进行scikit-learn库的安装。
(2)stata相关命令安装
首先stata需要定义好python路径,这个路径就是刚刚复制下来的python路径
set python_exec C:\Users\Administrator\AppData\Local\Programs\Python\Python312\python.exe随后,安装双重机器学习的相关命令包
ssc install ddml,all replacessc install lassopack,all replacessc install rforest,all replacessc install pystacked,all replace
(3)双重机器学习—基准回归部分
为了节省篇幅,只展示基准回归中其中一个估计结果
global Y IGG //被解释变量global X Edu Constru Urban Pass Fre Inv Inter Fis Unemp Size Consump Sci Cap Edu2 Constru2 Urban2 Pass2 Fre2 Inv2 Inter2 Fis2 Unemp2 Size2 Consump2 Sci2 Cap2 i.year i.id //控制变量global D Broadband //处置变量&解释变量set seed 42 //设定随机种子数ddml init partial, kfolds(5) //采用五折交叉检验ddml E[D|X]: pystacked $D $X, type(reg) method(rf) //机器学习采用随机森林算法ddml E[Y|X]: pystacked $Y $X, type(reg) method(rf) //机器学习采用随机森林算法ddml crossfitddml estimate, robust
回归结果如下所示,汇报时主要关注回归系数和稳健标准误。
. ddml estimate, robustDDML estimation results:spec r Y learner D learner b SEopt 1 Y1_pystacked D1_pystacked 0.117 ( 0.025)opt = minimum MSE specification for that resample.Min MSE DDML modely-E[y|X] = Y1_pystacked_1 Number of obs = 2820D-E[D|X,Z]= D1_pystacked_1------------------------------------------------------------------------------| RobustIGG | Coef. Std. Err. z P>|z| [95% Conf. Interval]-------------+----------------------------------------------------------------Broadband | .1168334 .0251806 4.64 0.000 .0674803 .1661866_cons | -.0027353 .0054266 -0.50 0.614 -.0133713 .0079007------------------------------------------------------------------------------
(4)双重机器学习—稳健性检验部分
在双重机器学习方法中,可以通过改变机器学习方法或交叉检验比例的方法重设机器学习模型,从而进行稳健性检验。
//更换机器学习方法global Y IGGglobal X Edu Constru Urban Pass Fre Inv Inter Fis Unemp Size Consump Sci Cap Edu2 Constru2 Urban2 Pass2 Fre2 Inv2 Inter2 Fis2 Unemp2 Size2 Consump2 Sci2 Cap2 i.year i.idglobal D Broadbandset seed 42ddml init partial, kfolds(5)ddml E[D|X]: pystacked $D $X, type(reg) method(lassocv) //拉索回归ddml E[Y|X]: pystacked $Y $X, type(reg) method(lassocv) //拉索回归*ddml E[D|X]: pystacked $D $X, type(reg) method(gradboost) //梯度提升*ddml E[Y|X]: pystacked $Y $X, type(reg) method(gradboost) //梯度提升*ddml E[D|X]: pystacked $D $X, type(reg) method(nnet) //神经网络*ddml E[Y|X]: pystacked $Y $X, type(reg) method(nnet) //神经网络*ddml E[D|X]: pystacked $D $X, type(reg) method(svm) //支持向量机*ddml E[Y|X]: pystacked $Y $X, type(reg) method(svm) //支持向量机ddml crossfitddml estimate, robust
//改变交叉检验比例global Y IGGglobal X Edu Constru Urban Pass Fre Inv Inter Fis Unemp Size Consump Sci Cap Edu2 Constru2 Urban2 Pass2 Fre2 Inv2 Inter2 Fis2 Unemp2 Size2 Consump2 Sci2 Cap2 i.year i.idglobal D Broadbandset seed 42ddml init partial, kfolds(3) //三折交叉检验*ddml init partial, kfolds(8) //八折交叉检验ddml E[D|X]: pystacked $D $X, type(reg) method(rf)ddml E[Y|X]: pystacked $Y $X, type(reg) method(rf)ddml crossfitddml estimate, robust
(5)双重机器学习—内生性检验
双重机器学习同样可采用工具变量法进行内生性检验:
global Y IGGglobal X Edu Constru Urban Pass Fre Inv Inter Fis Unemp Size Consump Sci Cap Edu2 Constru2 Urban2 Pass2 Fre2 Inv2 Inter2 Fis2 Unemp2 Size2 Consump2 Sci2 Cap2 i.year i.idglobal Z z //工具变量global D Broadbandset seed 42ddml init iv, kfolds(5)ddml E[Y|X]: pystacked $Y $X, type(reg) method(rf)ddml E[D|X]: pystacked $D $X, type(reg) method(rf)ddml E[Z|X]: pystacked $Z $X, type(reg) method(rf)ddml crossfitddml estimate, robust
(6)双重机器学习—异质性分析
该文异质性分析采用分组回归,每次跑完一组需重新导入数据进行下一组回归。
keep if inlist(resource_city,1)*keep if inlist(resource_city,0)*keep if inlist(industrial_base,1)*keep if inlist(industrial_base,0)*keep if inlist(class,1)*keep if inlist(class,2)*keep if inlist(class,3)global Y IGGglobal X Edu Constru Urban Pass Fre Inv Inter Fis Unemp Size Consump Sci Cap Edu2 Constru2 Urban2 Pass2 Fre2 Inv2 Inter2 Fis2 Unemp2 Size2 Consump2 Sci2 Cap2 i.year i.idglobal D Broadbandset seed 42ddml init partial, kfolds(5)ddml E[D|X]: pystacked $D $X, type(reg) method(rf)ddml E[Y|X]: pystacked $Y $X, type(reg) method(rf)ddml crossfitddml estimate, robust
结果保存代码,利用outreg2命令即可批量导出,该命令需要ssc install进行安装,下面是基准回归的示例。
global Y IGG //被解释变量global X Edu Constru Urban Pass Fre Inv Inter Fis Unemp Size Consump Sci Cap Edu2 Constru2 Urban2 Pass2 Fre2 Inv2 Inter2 Fis2 Unemp2 Size2 Consump2 Sci2 Cap2 i.year i.id //控制变量global D Broadband //处置变量&解释变量set seed 42 //设定随机种子数ddml init partial, kfolds(5) //采用五折交叉检验ddml E[D|X]: pystacked $D $X, type(reg) method(rf) //机器学习采用随机森林算法ddml E[Y|X]: pystacked $Y $X, type(reg) method(rf) //机器学习采用随机森林算法ddml crossfitddml estimate, robustest store A1//只要在每个估计代码ddml estimate, robust 后添加est store 名称 ,然后在outreg2 [ A1 A2 .. ] 即可批量导出outreg2 [ A1 ] using 基准回归.xls , replace bdec(3) rdec(3) addtext(时间固定效应, YES,个体固定效应, YES)
————————————————END————————————————
文献福利
研智团将学界有关双重机器学习方法的全部核刊文献汇总,关注研智团公众号,后台回复“双重机器学习”即可获取!
















 971
971

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









