






马化腾曾经表示过:“我们最开始认为AI是互联网十年不遇的机会,但是现在越想越觉得,这是百年不遇的,类似发明电的工业革命一样的机遇”
真心建议大家未来冲一冲新兴领域,特别是AIGC方向,因为AIGC是未来10-30年最大的机遇和风口。
首先:岗位多。
ChatGPT爆火之后,对于整个人工智能行业有非常大的推动作用。
大量的资本进入这个领域,催生了大量的新公司,各个大厂为了抢占先机,纷纷在这个领域重金投入。随之而来的就是大量的人才需求,但是这一波浪潮来的如此之迅捷,整个市场上人才供应是严重不足的。跟行业内的从业者聊起来,也是一样的直观感受。

其次,薪资比较高。
以上就会导致一个问题:公司想要找到经验丰富的人比较难,要么花大价钱抢人,要么降低招聘要求抢人,整体给到的薪资水平就会比较高,大多在40K左右。以下图片来自boss直聘的招聘数据。
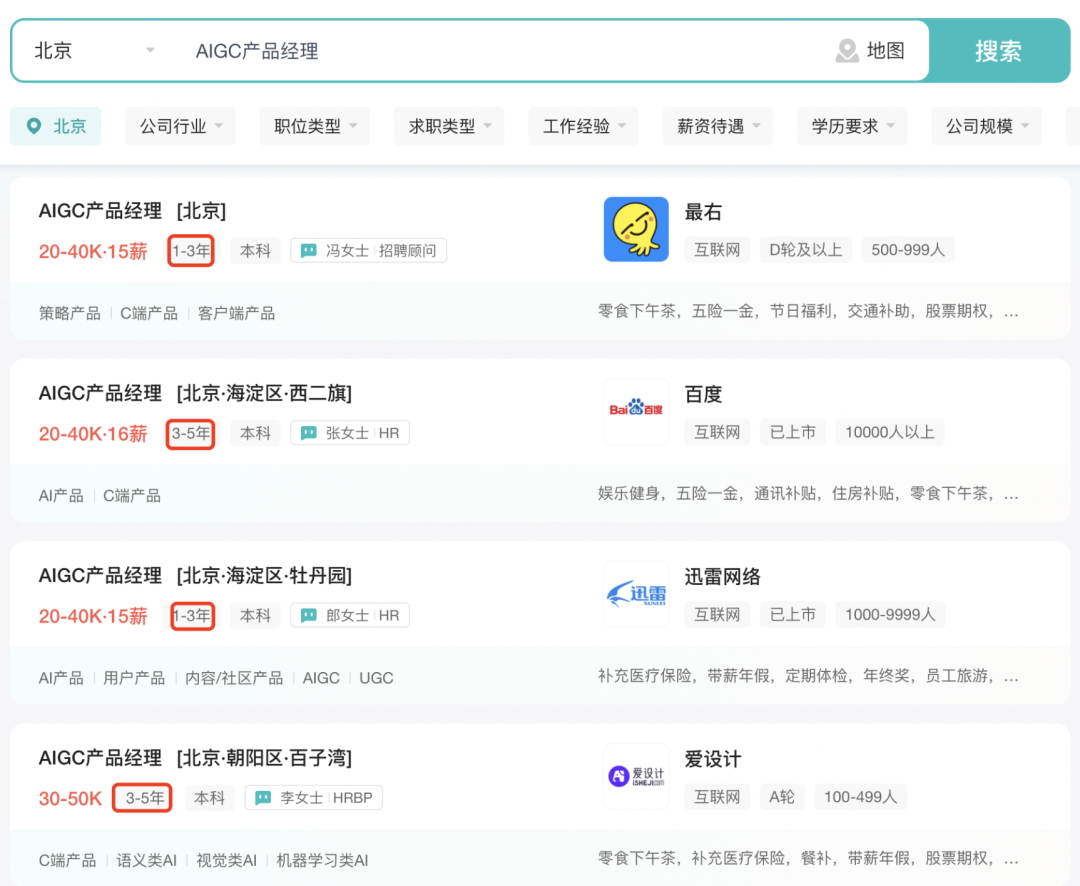
最后,要求相对比较低,非常适合入局。
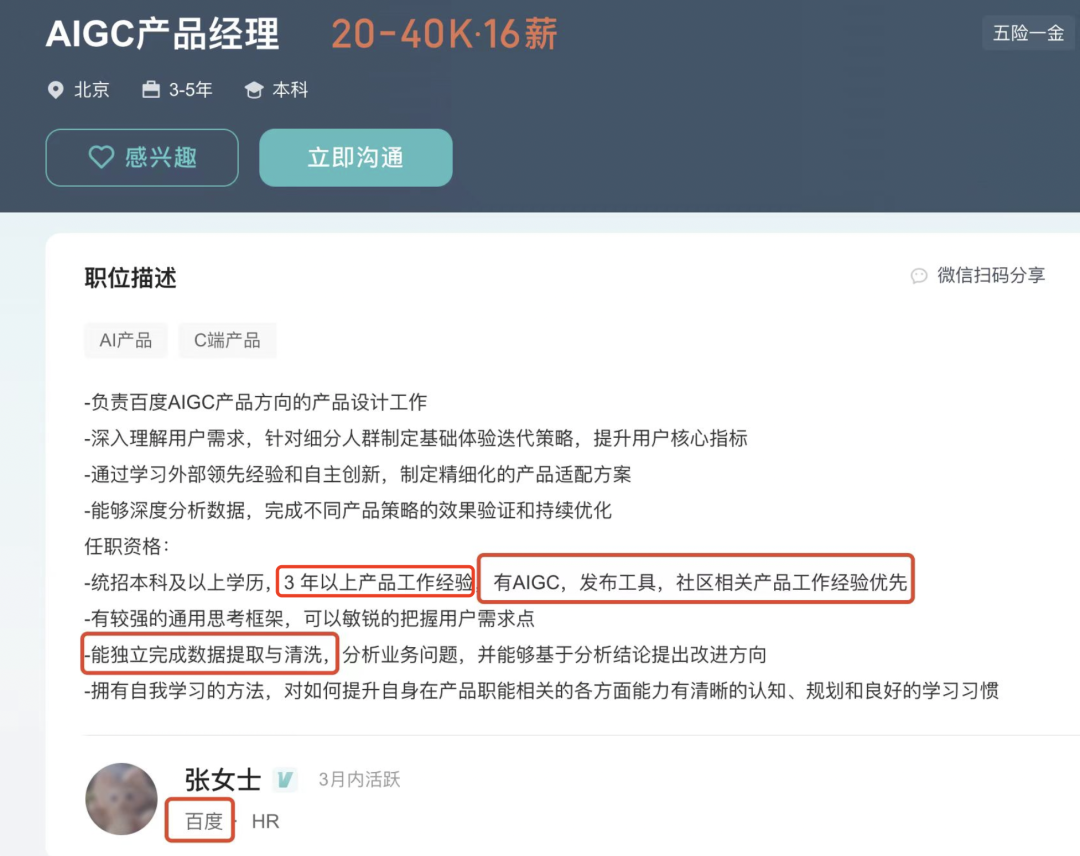
要注意: 上图里面1-3年或者3-5年的经验要求,是指产品经理的经验(从下图百度的招聘要求也可以看出来),而非AIGC的工作经验,因为AIGC是今年才大火的。
这样就导致只要之前是做产品经理的,然后要AIGC相关的项目经验,外加一些对于技术的理解,就可以拿到面试机会。
一、AIGC是什么?
生成式AI,即由人工智能来生成内容。比如AI通过训练后可以学习生成图像、文字、音频、视频等,未来会广泛应用在各个领域。
二、AIGC产品经理的未来发展怎么样?
仅2023年一季度就新增17万家人工智能相关企业,总计已有267万家。说明AIGC产业正在高速发展中,但由于领域较新,行业人才还存在大量缺口,所以现在正是入局的好时机
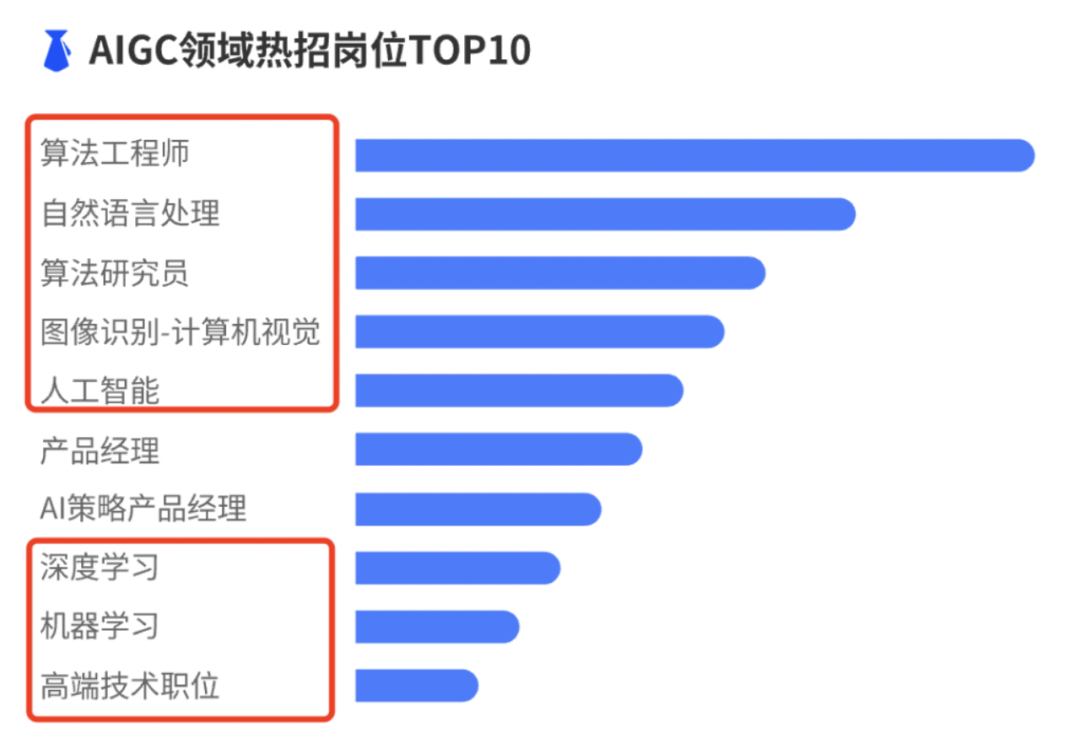
三、AIGC岗位的方向有哪些?
不仅是产品经理,开发、算法、测试都有岗位需求。
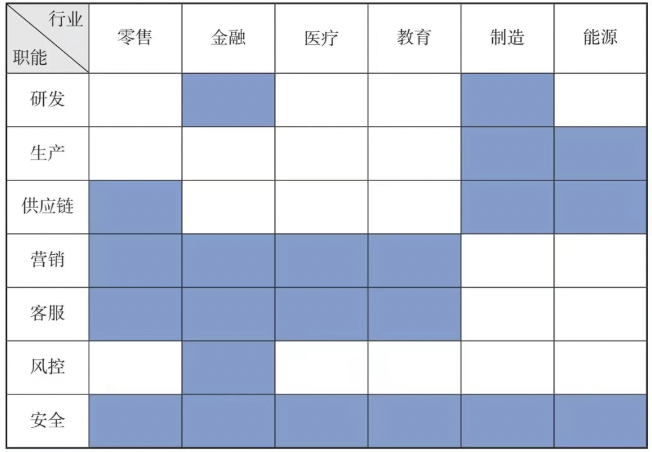
3.1 行业大模型,通过海量行业数据的训练,能对行业中的各种现象进行预测、分析、辅助决策,还能通过深度学习生成内容,比如金融、营销、医疗、内容、教育等行业。下图是人工智能的部分行业应用版图。
3.2 语言大模型,比如chatGPT、文心一言等,通过学习可以辅助生成文本类任务,应用于医疗、广告、内容电商等领域
3.3 图像大模型,通过学习自主生成图像类任务,比如AI绘画、广告创意、海报配图等,在应用层展示绘画和设计能力
四、传统互联网产品经理转型AIGC产品经理需要具备哪些能力?
工作内容上是差不多的,都需要进行需求分析、竞品调研、产品规划设计等过程。

区别在于:
1)要有AIGC相关的项目经验,大家可以自己多分析几个岗位JD,这算是硬性要求。如果想做AIGC产品经理,但是缺乏AIGC项目经验的。
2)需要掌握AI算法知识,了解如何用AI能力来达到想要的效果,还要能了解算法背后的原理和应用场景。
大家如果想做AI产品经理,以下内容需要对照学习补充。
当然,以下内容我们的公众号已输出大量的文章供大家免费学习,后续会持续输出更多新的内容,没有关注公众号的务必关注。
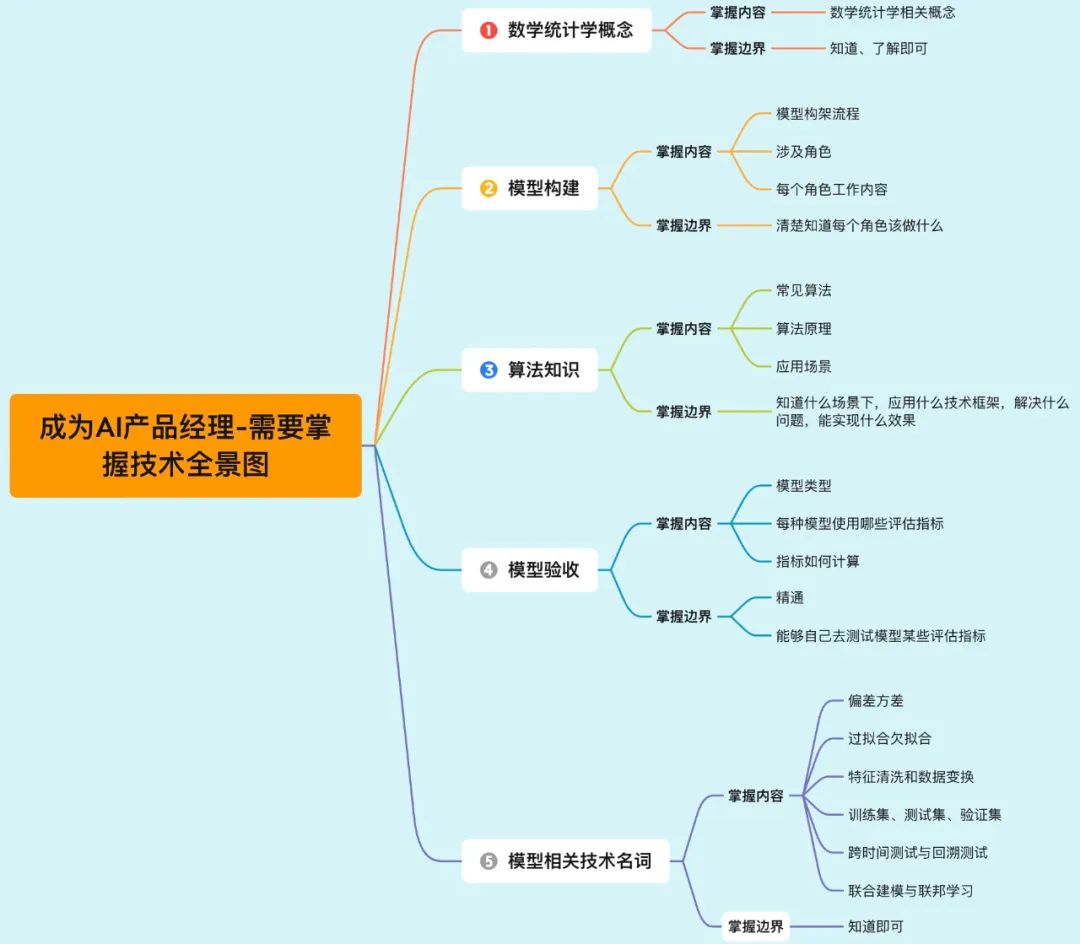
为了更好的帮助大家入门AI行业,接下来重磅给大家推荐99个AI领域专业术语:
1、人工智能(AI):一种能够执行智能任务的计算机系统或程序。
2、监督学习(Supervised learning):训练模型时提供输入数据和输出结果,以便模型能够进行预测和分类。
3、非监督学习(Unsupervised learning):训练模型时只提供输入数据,模型需要自己发现数据的结构和模式。
4、机器学习(ML):从数据中自动提取模式的一种方法,用于训练计算机模型,以便能够进行预测和决策。
5、深度学习(DL):一种机器学习方法,它利用深层神经网络来执行复杂的学习任务。
6、神经网络(NN):一种模仿人类大脑神经元组织的计算模型。
7、自然语言处理(NLP):计算机对自然语言的处理,包括语音识别、自然语言理解和生成等任务。
8、计算机视觉(CV):计算机对图像和视频的处理,包括对象检测、图像分割、场景理解等任务。
9、偏差-方差权衡(Bias-variance tradeoff):在机器学习中,通过控制模型的偏差和方差来实现
10、过拟合(Overfitting):机器学习模型在训练数据上表现很好,但在新数据上表现不佳的情况。
11、欠拟合(Underfitting):机器学习模型无法捕捉到数据中的模式和关系的情况。
12、正则化(Regularization):一种方法,用于减少模型过度拟合的程度。
13、数据挖掘(DM):从大量数据中提取知识和信息的过程。
14、数据科学(DS):使用数学、统计学和计算机科学等工具来分析和解决现实世界中的数据问题。
15、数据预处理(Data preprocessing):在进行机器学习或数据挖掘之前,对原始数据进行处理,包括数据清洗、特征选择等。
16、特征提取(Feature extraction):从原始数据中提取有意义的特征。
17、特征选择(Feature selection):选择最相关的特征以提高模型的准确性和泛化能力。
18、数据集(Dataset):一组用于训练和测试机器学习模型的数据。
19、强化学习(Reinforcement learning):一种通过试错学习的机器学习方法,它基于奖励和惩罚来指导模型的行为。
20、模型评估(Model evaluation):评估机器学习模型的性能,以便决定是否需要进行调整或改进。
21、模型选择(Model selection):在多个机器学习模型中选择最合适的模型以解决特定的问题。
22、卷积神经网络(Convolutional neural network):一种用于图像和视频处理的神经网络模型
23、循环神经网络(Recurrent neural network):一种用于序列数据处理的神经网络模型。
24、Dropout:在深度学习中,随机地将一些神经元从神经网络中删除,以避免过度拟合的方法。
25、梯度下降(Gradient descent):优化算法,用于调整模型参数以最小化损失函数。
26、损失函数(Loss function):用于衡量机器学习模型预测结果与真实结果之间的差异。
27、学习率(Learning rate):控制梯度下降算法中参数调整的速度。
28、批量梯度下降(Batch gradient descent):一种梯度下降方法,它在每个训练步骤中使用全部训练集。
29、生成对抗网络(Generative adversarial network):一种由两个神经网络组成的模型,一个生成器和一个判别器,用于生成逼真的假数据。
30、支持向量机(Support vector machine):一种用于分类和回归的机器学习模型。
31、随机梯度下降(Stochastic gradient descent):一种梯度下降方法,它在每个训练步骤中仅使用一个样本。
32、小批量梯度下降(Mini-batch gradient descent):一种梯度下降方法,它在每个训练步骤中使用一小批量的样本。
33、长短期记忆(Long short-term memory):一种循环神经网络的变体,用于处理长序列数据。
34、自编码器(Autoencoder):一种无监督学习模型,用于学习数据的低维表示。
35、随机森林(Random forest):一种用于分类和回归的集成学习模型。
36、K最近邻算法(K-nearest neighbor):一种用于分类和回归的非参数算法。
37、贝叶斯网络(Bayesian network):一种基于贝叶斯定理的概率图模型。
38、马尔可夫链(Markovchain):一种用于建模状态转移过程的随机过程。
39、马尔可夫决策过程(Markovdecision process):一种用于建模决策过程的马尔可夫链。
40、Q学习(Q-learning):一种无模型的强化学习算法,用于学习最优策略。
41、AdaGrad:一种梯度下降算法,用于自适应地调整每个参数的学习率。
42、RMSProp:一种梯度下降算法,用于自适应地调整每个参数的学习率。
43、Adam:一种梯度下降算法,结合了AdaGrad和RMSProp的优点。
44、深度强化学习(Deep reinforcement learning):一种强化学习方法,使用深度神经网络来学习最优策略。
45、策略梯度(Policygradient):一种强化学习算法,用于直接优化策略函数。
46、序列到序列模型(Sequence-to-sequence model):一种用于序列到序列的自然语言处理任务的神经网络模型。
47、反向传播(Backpropagation):一种用于计算神经网络中参数梯度的算法。
48、AlphaGo:由Google DeepMind开发的人工智能计算机程序,用于下围棋。
49、AlphaZero:由Google DeepMind开发的人工智能计算机程序,能够在没有任何人类知识指导的情况下学会玩国际象棋、围棋和日本将棋等游戏。
50、词向量(Wordembedding):一种将单词映射到实数向量的技术,用于自然语言处理任务。
51、优化器(Optimizer):一种用于调整神经网络参数以最小化损失函数的算法。
52、异常检测(Anomaly detection):一种用于检测异常数据的技术。
53、主成分分析(Principal component analysis):一种用于降维的无监督学习方法。
54、聚类(Clustering):一种将数据分组为相似类别的无监督学习方法。
55、交叉验证(Cross-validation):一种用于评估机器学习模型性能的技术。
56、超参数调整(Hyperparameter tuning):一种通过调整模型超参数来提高模型性能的技术。
57、特征工程(Feature engineering):一种将原始数据转换为有意义的特
58、对抗样本(Adversarial examples):一种人工制造的输入数据,目的是欺骗机器学习模型。
59、对抗训练(Adversarial training):一种训练机器学习模型以抵御对抗样本的方法。
60、可解释性机器学习(Explainable machine learning):一种机器学习方法,可以解释模型的决策过程和预测结果。
61、机器学习管道(Machine learning pipeline):一种处理原始数据并构建模型的自动化流程。
62、卷积神经网络(Convolutional neural network):一种特殊类型的神经网络,处理图像和视频数据。
63、循环神经网络(Recurrent neuralnetwork):一种特殊类型的神经网络,可以处理序列数据。
64、神经网络架构搜索(Neural architecture search):一种自动寻找神经网络架构的技术。
65、神经元(Neuron):神经网络中的基本单位,接收输入并生成输出。
66、激活函数(Activationfunction):神经网络中的一种函数,用于在神经元之间传递信息。
67、LSTM(Long short-term memory):一种循环神经网络架构,可以有效地处理长序列数据。
68、GRU(Gated recurrent unit):一种循环神经网络架构,比LSTM更简单且计算成本更低。
69、自注意力机制(Self-attention mechanism):一种用于处理序列数据的注意力机制。
70、梯度下降(Gradientdescent):一种优化算法,用于调整神经网络中的权重,使损失函数最小化。
71、随机梯度下降(Stochastic gradient descent):一种梯度下降的变体,每次更新权重时使用随机的小批量样本。
72、批量归一化(Batch normalization):一种神经网络层技术,加速模型的训练提高模型的泛化能力。
73、参数初始化(Parameter initialization):在神经网络训练之前初始化权重和偏差的过程。
74、正则化(Regularization):一种防止过拟合的技术,包括L1、L2正则化、Dropout等。
75、语义分割(Semantic segmentation):一种将图像分割成语义区域的计算机视觉任务。
76、实例分割( Instance segmentation):一种将图像中的不同实例分割成不同区域的计算机视觉任务。
77、目标检测(Object detection):一种在图像或视频中识别和定位多个物体的计算机视觉任务。
78、GAN(Generative Adversarial Network):一种无监督学习方法,用于生成与训练数据相似的新数据。
79、CGAN(ConditionalGAN):一种生成对抗网络,根据给定的条件生成新的数据。
80、VAE(Variational Autoencoder):一种自编码器,使用概率编码和解码,生成可控制的新数据。
81、单阶段目标检测(One-stage object detection):一种用于目标检测的神经网络架构,不需要先预测物体的位置和大小。
82、两阶段目标检测(Two-stage object detection):一种用于目标检测的神经网络架构,需要先预测物体的位置和大小,然后进行分类。
83、数据增强(Data augmentation):通过对训练数据进行旋转、平移、缩放等变换,扩充训练数据集的大小,从而提高模型的泛化能力。
84、超参数(Hyperparameter):在训练模型之前需要手动设置的参数,例如学习率、正则化强度等。
85、网格搜索(Gridsearch):一种调节超参数的方法,遍历给定的超参数空间,找到最佳超参数组合。
86、随机搜索(Random search):一种调节超参数的方法,随机选择超参数组合进行训练,找到最佳的超参数组合。
87、模型微调(Fine-tuning):在一个预训练模型的基础上,使用新的数据集重新训练模型的过程。
88、迁移学习(Transfer leaning):利用一个训练好的模型参数来初始化另一个模型,解决新的任务。
89、多任务学习(Multi-task learning):在一个神经网络中训练多个相关任务的技术。
90、无监督学习(Unsupervised learning):一种机器学习的范畴,不需要标注数据作为输入,算法能够自己发现数据中的结构。
91、自监督学习(Self-supervised leaning):一种利用数据本身内在结构进行无监督的学习方法。
92、对抗生成网络(Generative Adversarial Network,GAN):一种无监督学习的神经网络,通过训练一个生成器和一个鉴别器来生成逼真的假数据。
93、长短时记忆网络(Long Short-Term Memory, LSTM):一种循环神经网络,能够有效地处理序列数据,具有记忆单元和遗忘门等特性。
94、强化学习(Reinforcement leaning):一种通过智能体与环境的交互学习最优策略的机器学习方法。
95、奖赏(Reward):在强化学习中,智能体从环境中接收到的信号,用于评估其行为的好坏。
96、Actor-Critic:一种使用值函数和策略函数的强化学习算法。
97、强化学习环境(Reinforcement learning environment):用于训练强化学习算法的模拟环境。
98、策略(Policy):在强化学习中,智能体采取的动作的规则。
99、Q-learning:一种基于动作值函数的强化学习算法,可以学习最优的行为策略。
大模型岗位需求
大模型时代,企业对人才的需求变了,AIGC相关岗位人才难求,薪资持续走高,AI运营薪资平均值约18457元,AI工程师薪资平均值约37336元,大模型算法薪资平均值约39607元。

掌握大模型技术你还能拥有更多可能性:
• 成为一名全栈大模型工程师,包括Prompt,LangChain,LoRA等技术开发、运营、产品等方向全栈工程;
• 能够拥有模型二次训练和微调能力,带领大家完成智能对话、文生图等热门应用;
• 薪资上浮10%-20%,覆盖更多高薪岗位,这是一个高需求、高待遇的热门方向和领域;
• 更优质的项目可以为未来创新创业提供基石。
可能大家都想学习AI大模型技术,也想通过这项技能真正达到升职加薪,就业或是副业的目的,但是不知道该如何开始学习,因为网上的资料太多太杂乱了,如果不能系统的学习就相当于是白学。为了让大家少走弯路,少碰壁,这里我直接把全套AI技术和大模型入门资料、操作变现玩法都打包整理好,希望能够真正帮助到大家。
-END-
👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。


👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









