






- **🍨 本文为[🔗365天深度学习训练营](https://mp.weixin.qq.com/s/rnFa-IeY93EpjVu0yzzjkw) 中的学习记录博客**
- **🍖 原作者:[K同学啊](https://mtyjkh.blog.csdn.net/)**
语⾔环境:Python 3.9
开发⼯具: Jupyter Lab
深度学习环境:TensorFlow version 2.18.0
from tensorflow import keras
from tensorflow.keras import layers,models
import os, PIL, pathlib
import matplotlib.pyplot as plt
import tensorflow as tf
import numpy as npdata_dir ="/Users/eleanorzhang/Downloads/48-data"
data_dir = pathlib.Path(data_dir)image_count = len(list(data_dir.glob('*/*.jpg')))
print("图片总数为:",image_count)图片总数为: 1800
roses = list(data_dir.glob('Jennifer Lawrence/*.jpg'))
PIL.Image.open(str(roses[0]))
batch_size = 32
img_height = 224
img_width = 224train_ds = tf.keras.preprocessing.image_dataset_from_directory(
data_dir,
validation_split=0.1,
subset="training",
label_mode = "categorical",
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)Found 1800 files belonging to 17 classes. Using 1620 files for training.
val_ds = tf.keras.preprocessing.image_dataset_from_directory(
data_dir,
validation_split=0.1,
subset="validation",
label_mode = "categorical",
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)Found 1800 files belonging to 17 classes. Using 180 files for validation.
class_names = train_ds.class_names
print(class_names)['Angelina Jolie', 'Brad Pitt', 'Denzel Washington', 'Hugh Jackman', 'Jennifer Lawrence', 'Johnny Depp', 'Kate Winslet', 'Leonardo DiCaprio', 'Megan Fox', 'Natalie Portman', 'Nicole Kidman', 'Robert Downey Jr', 'Sandra Bullock', 'Scarlett Johansson', 'Tom Cruise', 'Tom Hanks', 'Will Smith']
plt.figure(figsize=(20, 10))
for images, labels in train_ds.take(1):
for i in range(20):
ax = plt.subplot(5, 10, i + 1)
plt.imshow(images[i].numpy().astype("uint8"))
plt.title(class_names[np.argmax(labels[i])])
plt.axis("off")
for image_batch, labels_batch in train_ds:
print(image_batch.shape)
print(labels_batch.shape)
break(32, 224, 224, 3) (32, 17)
AUTOTUNE = tf.data.AUTOTUNE
train_ds = train_ds.cache().shuffle(1000).prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)model = models.Sequential([
layers.Input(shape=(img_height, img_width, 3)),
layers.Rescaling(1./255),
layers.Conv2D(16, (3, 3), activation='relu'),
layers.AveragePooling2D((2, 2)),
layers.Conv2D(32, (3, 3), activation='relu'),
layers.AveragePooling2D((2, 2)),
layers.Dropout(0.5),
layers.Conv2D(64, (3, 3), activation='relu'),
layers.AveragePooling2D((2, 2)),
layers.Dropout(0.5),
layers.Conv2D(128, (3, 3), activation='relu'),
layers.Dropout(0.5),
layers.Flatten(),
layers.Dense(128, activation='relu'),
layers.Dense(len(class_names))
])
model.summary() Model: "sequential_2"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━┓ ┃ Layer (type) ┃ Output Shape ┃ Param # ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━┩ │ rescaling_2 (Rescaling) │ (None, 224, 224, 3) │ 0 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ conv2d_8 (Conv2D) │ (None, 222, 222, 16) │ 448 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ average_pooling2d_6 │ (None, 111, 111, 16) │ 0 │ │ (AveragePooling2D) │ │ │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ conv2d_9 (Conv2D) │ (None, 109, 109, 32) │ 4,640 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ average_pooling2d_7 │ (None, 54, 54, 32) │ 0 │ │ (AveragePooling2D) │ │ │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ dropout_6 (Dropout) │ (None, 54, 54, 32) │ 0 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ conv2d_10 (Conv2D) │ (None, 52, 52, 64) │ 18,496 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ average_pooling2d_8 │ (None, 26, 26, 64) │ 0 │ │ (AveragePooling2D) │ │ │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ dropout_7 (Dropout) │ (None, 26, 26, 64) │ 0 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ conv2d_11 (Conv2D) │ (None, 24, 24, 128) │ 73,856 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ dropout_8 (Dropout) │ (None, 24, 24, 128) │ 0 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ flatten_2 (Flatten) │ (None, 73728) │ 0 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ dense_4 (Dense) │ (None, 128) │ 9,437,312 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ dense_5 (Dense) │ (None, 17) │ 2,193 │ └─────────────────────────────────┴────────────────────────┴───────────────┘
Total params: 9,536,945 (36.38 MB)
Trainable params: 9,536,945 (36.38 MB)
Non-trainable params: 0 (0.00 B)
# 设置初始学习率
initial_learning_rate = 1e-4
lr_schedule = tf.keras.optimizers.schedules.ExponentialDecay(
initial_learning_rate,
decay_steps=60,
decay_rate=0.96,
staircase=True)
# 将指数衰减学习率送入优化器
optimizer = tf.keras.optimizers.Adam(learning_rate=lr_schedule)
model.compile(optimizer=optimizer,
loss=tf.keras.losses.CategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])history = model.fit(train_ds,
validation_data=val_ds,
epochs=epochs,
callbacks=[checkpointer, earlystopper])Epoch 1/100 51/51 ━━━━━━━━━━━━━━━━━━━━ 0s 253ms/step - accuracy: 0.0708 - loss: 25.7558 Epoch 1: val_accuracy improved from 0.06667 to 0.17778, saving model to best_model.weights.h5 51/51 ━━━━━━━━━━━━━━━━━━━━ 14s 264ms/step - accuracy: 0.0712 - loss: 25.5645 - val_accuracy: 0.1778 - val_loss: 4.2205 Epoch 2/100 51/51 ━━━━━━━━━━━━━━━━━━━━ 0s 248ms/step - accuracy: 0.1320 - loss: 4.2774 Epoch 2: val_accuracy did not improve from 0.17778 51/51 ━━━━━━━━━━━━━━━━━━━━ 13s 255ms/step - accuracy: 0.1319 - loss: 4.2648 - val_accuracy: 0.1389 - val_loss: 2.8320 Epoch 3/100 51/51 ━━━━━━━━━━━━━━━━━━━━ 0s 234ms/step - accuracy: 0.1083 - loss: 2.8260 Epoch 3: val_accuracy did not improve from 0.17778 51/51 ━━━━━━━━━━━━━━━━━━━━ 12s 241ms/step - accuracy: 0.1082 - loss: 2.8261 - val_accuracy: 0.0333 - val_loss: 2.8332 Epoch 4/100 51/51 ━━━━━━━━━━━━━━━━━━━━ 0s 232ms/step - accuracy: 0.1161 - loss: 2.8246 Epoch 4: val_accuracy did not improve from 0.17778 51/51 ━━━━━━━━━━━━━━━━━━━━ 12s 239ms/step - accuracy: 0.1160 - loss: 2.8246 - val_accuracy: 0.1389 - val_loss: 2.8225 Epoch 5/100 51/51 ━━━━━━━━━━━━━━━━━━━━ 0s 230ms/step - accuracy: 0.0929 - loss: 2.8204 Epoch 5: val_accuracy did not improve from 0.17778 51/51 ━━━━━━━━━━━━━━━━━━━━ 12s 237ms/step - accuracy: 0.0932 - loss: 2.8202 - val_accuracy: 0.1389 - val_loss: 2.7813 Epoch 6/100 51/51 ━━━━━━━━━━━━━━━━━━━━ 0s 229ms/step - accuracy: 0.1098 - loss: 2.7953 Epoch 6: val_accuracy did not improve from 0.17778 51/51 ━━━━━━━━━━━━━━━━━━━━ 12s 236ms/step - accuracy: 0.1098 - loss: 2.7952 - val_accuracy: 0.1389 - val_loss: 2.7722 Epoch 7/100 51/51 ━━━━━━━━━━━━━━━━━━━━ 0s 237ms/step - accuracy: 0.1115 - loss: 2.7761 Epoch 7: val_accuracy did not improve from 0.17778 51/51 ━━━━━━━━━━━━━━━━━━━━ 12s 245ms/step - accuracy: 0.1114 - loss: 2.7762 - val_accuracy: 0.1444 - val_loss: 2.7614 Epoch 8/100 51/51 ━━━━━━━━━━━━━━━━━━━━ 0s 249ms/step - accuracy: 0.1031 - loss: 2.7705 Epoch 8: val_accuracy did not improve from 0.17778 51/51 ━━━━━━━━━━━━━━━━━━━━ 13s 256ms/step - accuracy: 0.1032 - loss: 2.7703 - val_accuracy: 0.1444 - val_loss: 2.7321 Epoch 9/100 51/51 ━━━━━━━━━━━━━━━━━━━━ 0s 232ms/step - accuracy: 0.1091 - loss: 2.7378 Epoch 9: val_accuracy did not improve from 0.17778 51/51 ━━━━━━━━━━━━━━━━━━━━ 12s 239ms/step - accuracy: 0.1092 - loss: 2.7377 - val_accuracy: 0.1500 - val_loss: 2.7120 Epoch 10/100 51/51 ━━━━━━━━━━━━━━━━━━━━ 0s 230ms/step - accuracy: 0.1143 - loss: 2.7163 Epoch 10: val_accuracy did not improve from 0.17778 51/51 ━━━━━━━━━━━━━━━━━━━━ 12s 237ms/step - accuracy: 0.1146 - loss: 2.7159 - val_accuracy: 0.1611 - val_loss: 2.6781 Epoch 11/100 51/51 ━━━━━━━━━━━━━━━━━━━━ 0s 235ms/step - accuracy: 0.1492 - loss: 2.6592 Epoch 11: val_accuracy did not improve from 0.17778 51/51 ━━━━━━━━━━━━━━━━━━━━ 12s 242ms/step - accuracy: 0.1491 - loss: 2.6591 - val_accuracy: 0.1500 - val_loss: 2.6439 Epoch 12/100 51/51 ━━━━━━━━━━━━━━━━━━━━ 0s 235ms/step - accuracy: 0.1626 - loss: 2.6155 Epoch 12: val_accuracy improved from 0.17778 to 0.18889, saving model to best_model.weights.h5 51/51 ━━━━━━━━━━━━━━━━━━━━ 12s 245ms/step - accuracy: 0.1626 - loss: 2.6154 - val_accuracy: 0.1889 - val_loss: 2.6035 Epoch 13/100 51/51 ━━━━━━━━━━━━━━━━━━━━ 0s 231ms/step - accuracy: 0.1643 - loss: 2.5819 Epoch 13: val_accuracy did not improve from 0.18889 51/51 ━━━━━━━━━━━━━━━━━━━━ 12s 238ms/step - accuracy: 0.1645 - loss: 2.5813 - val_accuracy: 0.1778 - val_loss: 2.5535 Epoch 14/100 51/51 ━━━━━━━━━━━━━━━━━━━━ 0s 234ms/step - accuracy: 0.1871 - loss: 2.4949 Epoch 14: val_accuracy improved from 0.18889 to 0.19444, saving model to best_model.weights.h5 51/51 ━━━━━━━━━━━━━━━━━━━━ 12s 243ms/step - accuracy: 0.1873 - loss: 2.4949 - val_accuracy: 0.1944 - val_loss: 2.5187 Epoch 15/100 51/51 ━━━━━━━━━━━━━━━━━━━━ 0s 232ms/step - accuracy: 0.2264 - loss: 2.4217 Epoch 15: val_accuracy improved from 0.19444 to 0.22222, saving model to best_model.weights.h5 51/51 ━━━━━━━━━━━━━━━━━━━━ 12s 241ms/step - accuracy: 0.2265 - loss: 2.4217 - val_accuracy: 0.2222 - val_loss: 2.4918 Epoch 16/100 51/51 ━━━━━━━━━━━━━━━━━━━━ 0s 234ms/step - accuracy: 0.2466 - loss: 2.3612 Epoch 16: val_accuracy did not improve from 0.22222 51/51 ━━━━━━━━━━━━━━━━━━━━ 12s 241ms/step - accuracy: 0.2464 - loss: 2.3616 - val_accuracy: 0.2056 - val_loss: 2.4734 Epoch 17/100 51/51 ━━━━━━━━━━━━━━━━━━━━ 0s 257ms/step - accuracy: 0.2434 - loss: 2.3478 Epoch 17: val_accuracy did not improve from 0.22222 51/51 ━━━━━━━━━━━━━━━━━━━━ 13s 265ms/step - accuracy: 0.2433 - loss: 2.3475 - val_accuracy: 0.2167 - val_loss: 2.4563 Epoch 18/100 51/51 ━━━━━━━━━━━━━━━━━━━━ 0s 233ms/step - accuracy: 0.2577 - loss: 2.3213 Epoch 18: val_accuracy did not improve from 0.22222 51/51 ━━━━━━━━━━━━━━━━━━━━ 12s 240ms/step - accuracy: 0.2579 - loss: 2.3210 - val_accuracy: 0.1944 - val_loss: 2.4675 Epoch 19/100 51/51 ━━━━━━━━━━━━━━━━━━━━ 0s 232ms/step - accuracy: 0.2850 - loss: 2.2352 Epoch 19: val_accuracy did not improve from 0.22222 51/51 ━━━━━━━━━━━━━━━━━━━━ 12s 239ms/step - accuracy: 0.2847 - loss: 2.2357 - val_accuracy: 0.2056 - val_loss: 2.4397 Epoch 20/100 51/51 ━━━━━━━━━━━━━━━━━━━━ 0s 233ms/step - accuracy: 0.2604 - loss: 2.2457 Epoch 20: val_accuracy improved from 0.22222 to 0.23889, saving model to best_model.weights.h5 51/51 ━━━━━━━━━━━━━━━━━━━━ 12s 241ms/step - accuracy: 0.2603 - loss: 2.2458 - val_accuracy: 0.2389 - val_loss: 2.4424 Epoch 21/100 51/51 ━━━━━━━━━━━━━━━━━━━━ 0s 253ms/step - accuracy: 0.2917 - loss: 2.1719 Epoch 21: val_accuracy did not improve from 0.23889 51/51 ━━━━━━━━━━━━━━━━━━━━ 13s 262ms/step - accuracy: 0.2917 - loss: 2.1724 - val_accuracy: 0.2389 - val_loss: 2.4397 Epoch 22/100 51/51 ━━━━━━━━━━━━━━━━━━━━ 0s 245ms/step - accuracy: 0.2938 - loss: 2.1678 Epoch 22: val_accuracy did not improve from 0.23889 51/51 ━━━━━━━━━━━━━━━━━━━━ 13s 252ms/step - accuracy: 0.2938 - loss: 2.1678 - val_accuracy: 0.2111 - val_loss: 2.4844 Epoch 23/100 51/51 ━━━━━━━━━━━━━━━━━━━━ 0s 237ms/step - accuracy: 0.3147 - loss: 2.0991 Epoch 23: val_accuracy did not improve from 0.23889 51/51 ━━━━━━━━━━━━━━━━━━━━ 12s 244ms/step - accuracy: 0.3146 - loss: 2.0997 - val_accuracy: 0.2056 - val_loss: 2.4475 Epoch 24/100 51/51 ━━━━━━━━━━━━━━━━━━━━ 0s 238ms/step - accuracy: 0.3112 - loss: 2.1336 Epoch 24: val_accuracy did not improve from 0.23889 51/51 ━━━━━━━━━━━━━━━━━━━━ 13s 246ms/step - accuracy: 0.3113 - loss: 2.1335 - val_accuracy: 0.2167 - val_loss: 2.4753 Epoch 25/100 51/51 ━━━━━━━━━━━━━━━━━━━━ 0s 250ms/step - accuracy: 0.3331 - loss: 2.0728 Epoch 25: val_accuracy did not improve from 0.23889 51/51 ━━━━━━━━━━━━━━━━━━━━ 13s 258ms/step - accuracy: 0.3330 - loss: 2.0731 - val_accuracy: 0.1944 - val_loss: 2.4913 Epoch 26/100 51/51 ━━━━━━━━━━━━━━━━━━━━ 0s 245ms/step - accuracy: 0.3269 - loss: 2.0983 Epoch 26: val_accuracy did not improve from 0.23889 51/51 ━━━━━━━━━━━━━━━━━━━━ 13s 253ms/step - accuracy: 0.3269 - loss: 2.0977 - val_accuracy: 0.2111 - val_loss: 2.4631 Epoch 27/100 51/51 ━━━━━━━━━━━━━━━━━━━━ 0s 248ms/step - accuracy: 0.3634 - loss: 2.0221 Epoch 27: val_accuracy did not improve from 0.23889 51/51 ━━━━━━━━━━━━━━━━━━━━ 13s 256ms/step - accuracy: 0.3632 - loss: 2.0223 - val_accuracy: 0.2111 - val_loss: 2.4825 Epoch 28/100 51/51 ━━━━━━━━━━━━━━━━━━━━ 0s 256ms/step - accuracy: 0.3508 - loss: 2.0024 Epoch 28: val_accuracy did not improve from 0.23889 51/51 ━━━━━━━━━━━━━━━━━━━━ 13s 263ms/step - accuracy: 0.3509 - loss: 2.0025 - val_accuracy: 0.2000 - val_loss: 2.4996 Epoch 29/100 51/51 ━━━━━━━━━━━━━━━━━━━━ 0s 234ms/step - accuracy: 0.3658 - loss: 1.9887 Epoch 29: val_accuracy did not improve from 0.23889 51/51 ━━━━━━━━━━━━━━━━━━━━ 12s 241ms/step - accuracy: 0.3657 - loss: 1.9887 - val_accuracy: 0.1833 - val_loss: 2.5364 Epoch 30/100 51/51 ━━━━━━━━━━━━━━━━━━━━ 0s 242ms/step - accuracy: 0.3817 - loss: 1.9563 Epoch 30: val_accuracy did not improve from 0.23889 51/51 ━━━━━━━━━━━━━━━━━━━━ 13s 250ms/step - accuracy: 0.3815 - loss: 1.9562 - val_accuracy: 0.2167 - val_loss: 2.5035 Epoch 31/100 51/51 ━━━━━━━━━━━━━━━━━━━━ 0s 242ms/step - accuracy: 0.3834 - loss: 1.8738 Epoch 31: val_accuracy did not improve from 0.23889 51/51 ━━━━━━━━━━━━━━━━━━━━ 13s 249ms/step - accuracy: 0.3832 - loss: 1.8748 - val_accuracy: 0.2222 - val_loss: 2.5464 Epoch 32/100 51/51 ━━━━━━━━━━━━━━━━━━━━ 0s 237ms/step - accuracy: 0.3772 - loss: 1.8888 Epoch 32: val_accuracy did not improve from 0.23889 51/51 ━━━━━━━━━━━━━━━━━━━━ 12s 245ms/step - accuracy: 0.3774 - loss: 1.8889 - val_accuracy: 0.2000 - val_loss: 2.6030 Epoch 33/100 51/51 ━━━━━━━━━━━━━━━━━━━━ 0s 239ms/step - accuracy: 0.3808 - loss: 1.9160 Epoch 33: val_accuracy did not improve from 0.23889 51/51 ━━━━━━━━━━━━━━━━━━━━ 13s 246ms/step - accuracy: 0.3813 - loss: 1.9153 - val_accuracy: 0.2056 - val_loss: 2.5533 Epoch 34/100 51/51 ━━━━━━━━━━━━━━━━━━━━ 0s 239ms/step - accuracy: 0.4032 - loss: 1.8132 Epoch 34: val_accuracy did not improve from 0.23889 51/51 ━━━━━━━━━━━━━━━━━━━━ 13s 246ms/step - accuracy: 0.4032 - loss: 1.8135 - val_accuracy: 0.2000 - val_loss: 2.5865 Epoch 35/100 51/51 ━━━━━━━━━━━━━━━━━━━━ 0s 245ms/step - accuracy: 0.4223 - loss: 1.8315 Epoch 35: val_accuracy did not improve from 0.23889 51/51 ━━━━━━━━━━━━━━━━━━━━ 13s 252ms/step - accuracy: 0.4222 - loss: 1.8315 - val_accuracy: 0.2111 - val_loss: 2.5424 Epoch 36/100 51/51 ━━━━━━━━━━━━━━━━━━━━ 0s 249ms/step - accuracy: 0.4341 - loss: 1.8065 Epoch 36: val_accuracy did not improve from 0.23889 51/51 ━━━━━━━━━━━━━━━━━━━━ 13s 256ms/step - accuracy: 0.4342 - loss: 1.8060 - val_accuracy: 0.1667 - val_loss: 2.6543 Epoch 37/100 51/51 ━━━━━━━━━━━━━━━━━━━━ 0s 239ms/step - accuracy: 0.4138 - loss: 1.7475 Epoch 37: val_accuracy did not improve from 0.23889 51/51 ━━━━━━━━━━━━━━━━━━━━ 13s 247ms/step - accuracy: 0.4140 - loss: 1.7479 - val_accuracy: 0.2222 - val_loss: 2.6179 Epoch 38/100 51/51 ━━━━━━━━━━━━━━━━━━━━ 0s 238ms/step - accuracy: 0.4498 - loss: 1.7417 Epoch 38: val_accuracy did not improve from 0.23889 51/51 ━━━━━━━━━━━━━━━━━━━━ 13s 246ms/step - accuracy: 0.4495 - loss: 1.7420 - val_accuracy: 0.2278 - val_loss: 2.6206 Epoch 39/100 51/51 ━━━━━━━━━━━━━━━━━━━━ 0s 253ms/step - accuracy: 0.4541 - loss: 1.6876 Epoch 39: val_accuracy did not improve from 0.23889 51/51 ━━━━━━━━━━━━━━━━━━━━ 13s 261ms/step - accuracy: 0.4540 - loss: 1.6879 - val_accuracy: 0.2222 - val_loss: 2.6067 Epoch 40/100 51/51 ━━━━━━━━━━━━━━━━━━━━ 0s 240ms/step - accuracy: 0.4312 - loss: 1.7638 Epoch 40: val_accuracy did not improve from 0.23889 51/51 ━━━━━━━━━━━━━━━━━━━━ 13s 247ms/step - accuracy: 0.4316 - loss: 1.7625 - val_accuracy: 0.2222 - val_loss: 2.6200 Epoch 40: early stopping
model.save_weights('best_model.weights.h5')from datetime import datetime
current_time = datetime.now() # 获取当前时间
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs_range = range(len(loss))
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.xlabel(current_time) # 打卡请带上时间戳,否则代码截图无效
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()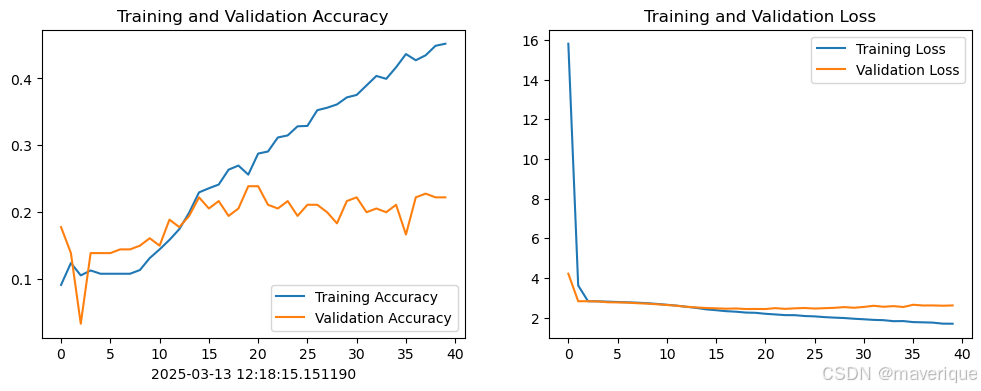
from PIL import Image
import numpy as np
import os
path = os.path.join("/Users/eleanorzhang/Downloads/48-data", "Tom Cruise", "031_df3204d3.jpg")
#这里选择你需要预测的图片
image = tf.image.resize(img, [img_height, img_width])
img_array = tf.expand_dims(image, 0)
# 加载效果最好的模型权重
model.load_weights('best_model.weights.h5')
predictions = model.predict(img_array) # 这里选用你已经训练好的模型
print("预测结果为:",class_names[np.argmax(predictions)])1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 123ms/step 预测结果为: Tom Cruise


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









