






先上代码
后面有解释
import requests
from lxml import etree
import csv
import time
header = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:104.0) Gecko/20100101 Firefox/104.0"}
def download(url):
html = requests.get(url, headers=header)
time.sleep(2)
return etree.HTML(html.text)
def data_save(item):
with open(r'C:/Users/Administrator/Desktop/lianjia.csv','a',encoding="GB18030",newline="") as f:
w = csv.writer(f)
w.writerow(item)
def spyder(url):
selector = download(url)
h_list = selector.xpath('//*[@id="content"]/div[1]/ul/li')
for house in h_list:
name = house.xpath("div[1]/div[2]/div/a[1]/text()")[0]
layout = house.xpath("div[1]/div[2]/div/a[2]/text()")[0]
area = house.xpath("div[1]/div[3]/div/text()")[0]
# area = house.xpath("div[1]/div[3]/div/text()")[0].split()[1]
price = house.xpath("div[1]/div[6]/div[2]/span/text()")[0]
total = house.xpath("div[1]/div[6]/div[1]/span/text()")[0]
item = [name, layout, area, price, total]
data_save(item)
print(name, "抓取成功")
if __name__ == '__main__':
pre = 'https://zz.lianjia.com/ershoufang/pg'
for x in range(1,10):
h_url = pre +str(x)
spyder(h_url)
1、安装模块
如果没安装模块,可以详细看看这个
(安装好的可以跳过)
最好使用国内源(清华,阿里,豆瓣,中科大等等。)
以清华源为例:
Terminal(pycharm终端窗口),或者进入Powershell,或者自己的pip位置
查看源
pip config list如果没有更改源,可以运行以下代码进行更改为清华源
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple然后进行pip下载会比国外的默认源快
pip install +需要安装的名字
pip install requests
pip install lxml代码解释
2、导入
import requests
from lxml import etree
import csv
import time3、伪装浏览器
header = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:104.0) Gecko/20100101 Firefox/104.0"}
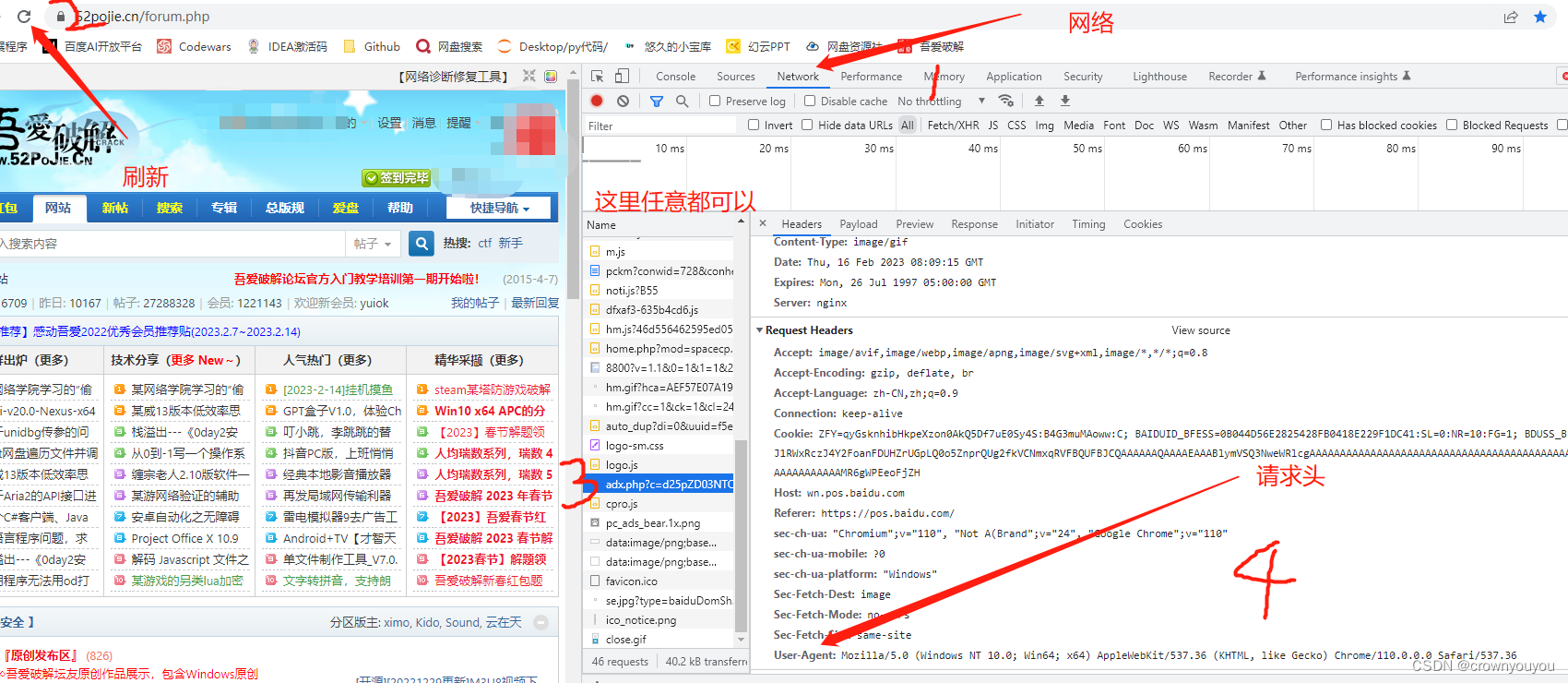
请求头查看方法:打开浏览器,打开一个网站A,按F12(或者右键单击,然后选择检查),在弹出的窗口最上边选择Network(网络),然后刷新网页A,选择Name,然后右边往下滑动。
def
1、解析网站
def download(url):
# 定义一个download的函数,传入一个参数名称为url的参数 html = requests.get(url, headers=header)
# 将爬虫模拟get请求访问的信息传递给html(url是参数:访问网站)headers是伪装浏览器请求头 time.sleep(2) # 让全局暂停2秒
return etree.HTML(html.text)
# 调用lxml中的etree函数的HTML部分,参数是上个代码段中的html的文本(html.text)2、保存数据
def data_save(item): # 定义一个名叫data_save的函数
with open(r'C:/Users/Administrator/Desktop/lianjia.csv','a',encoding="GB18030",newline="") as f:
# with open是打开的函数,参数:第一个参数是保存位置,r是不转义字符,a是读取方式,encoding是解码方式,newline是换行方式,最后的as f是把with open(参数)简称为f
w = csv.writer(f) #调用csv中的writer()方法
w.writerow(item) # 调用w并写入item3、爬取数据
def spyder(url):
selector = download(url) # 调用download函数,赋值给selector
# 选取路径
h_list = selector.xpath('//*[@id="content"]/div[1]/ul/li')
for house in h_list:
name = house.xpath("div[1]/div[2]/div/a[1]/text()")[0]
layout = house.xpath("div[1]/div[2]/div/a[2]/text()")[0]
area = house.xpath("div[1]/div[3]/div/text()")[0]
# area = house.xpath("div[1]/div[3]/div/text()")[0].split()[1]
price = house.xpath("div[1]/div[6]/div[2]/span/text()")[0]
total = house.xpath("div[1]/div[6]/div[1]/span/text()")[0]
item = [name, layout, area, price, total]
data_save(item) # 给data_save传递参数
print(name, "抓取成功")
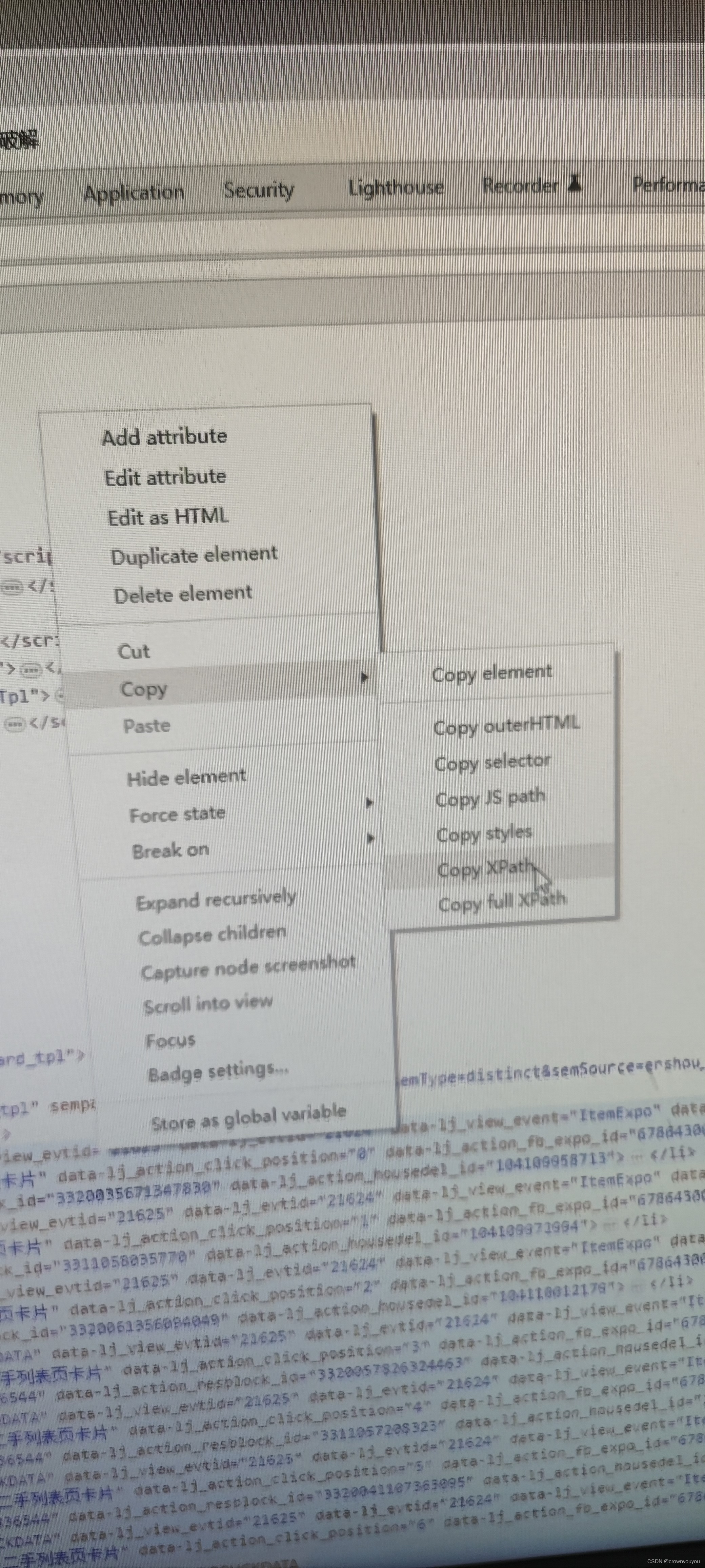
选取路径方法: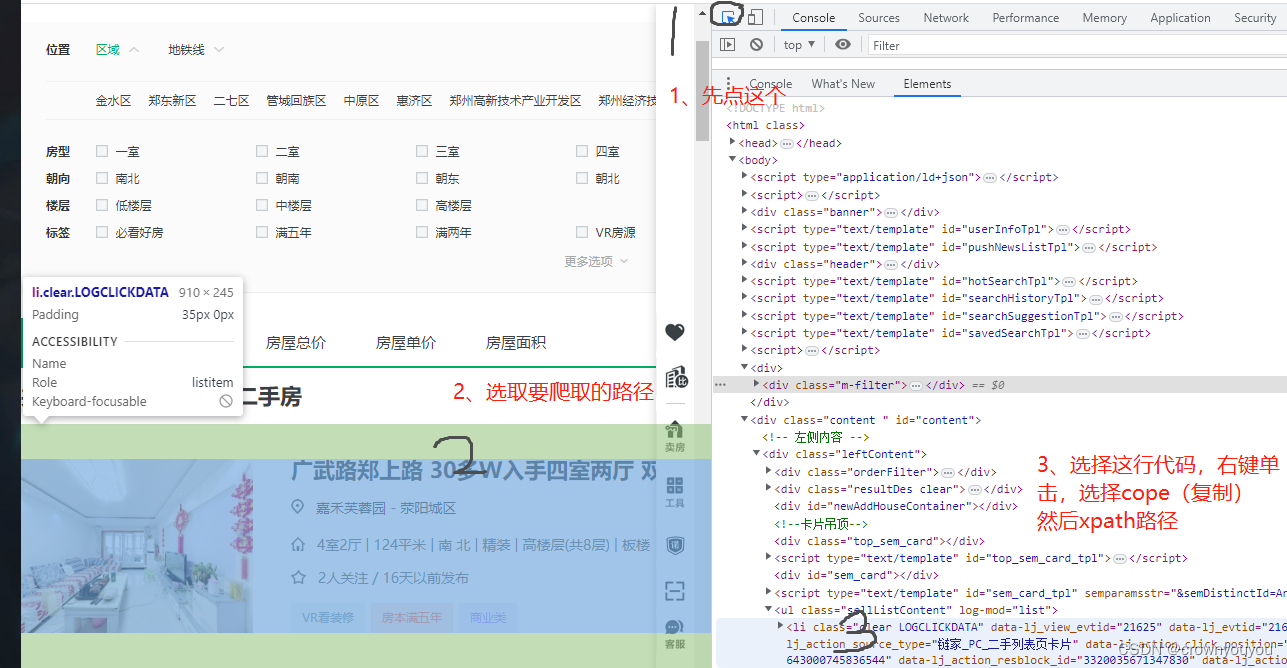


















 227
227

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











