







 本文介绍了一个简单的Python爬虫,用于抓取无反爬措施的网页图片。在疫情背景下,为方便查找所有网课课程群二维码,作者揭示了图片链接的构造规律,并使用requests库实现图片的下载。虽然课程号-课序号信息可从教务系统获取,但爬虫尚无法处理登录和验证码,作者期望未来能解决这个问题。
本文介绍了一个简单的Python爬虫,用于抓取无反爬措施的网页图片。在疫情背景下,为方便查找所有网课课程群二维码,作者揭示了图片链接的构造规律,并使用requests库实现图片的下载。虽然课程号-课序号信息可从教务系统获取,但爬虫尚无法处理登录和验证码,作者期望未来能解决这个问题。
这是一个最简单的、没有任何针对反爬措施的爬虫。走错门的施主可以绕道了~~~
一、问题
受疫情影响,所有学校课程采用网课教学,各种课程群应运而生。想一次性找到所有课程群二维码,以供查询,怎么办呢?
二、原理
1、探明网页图片链接格式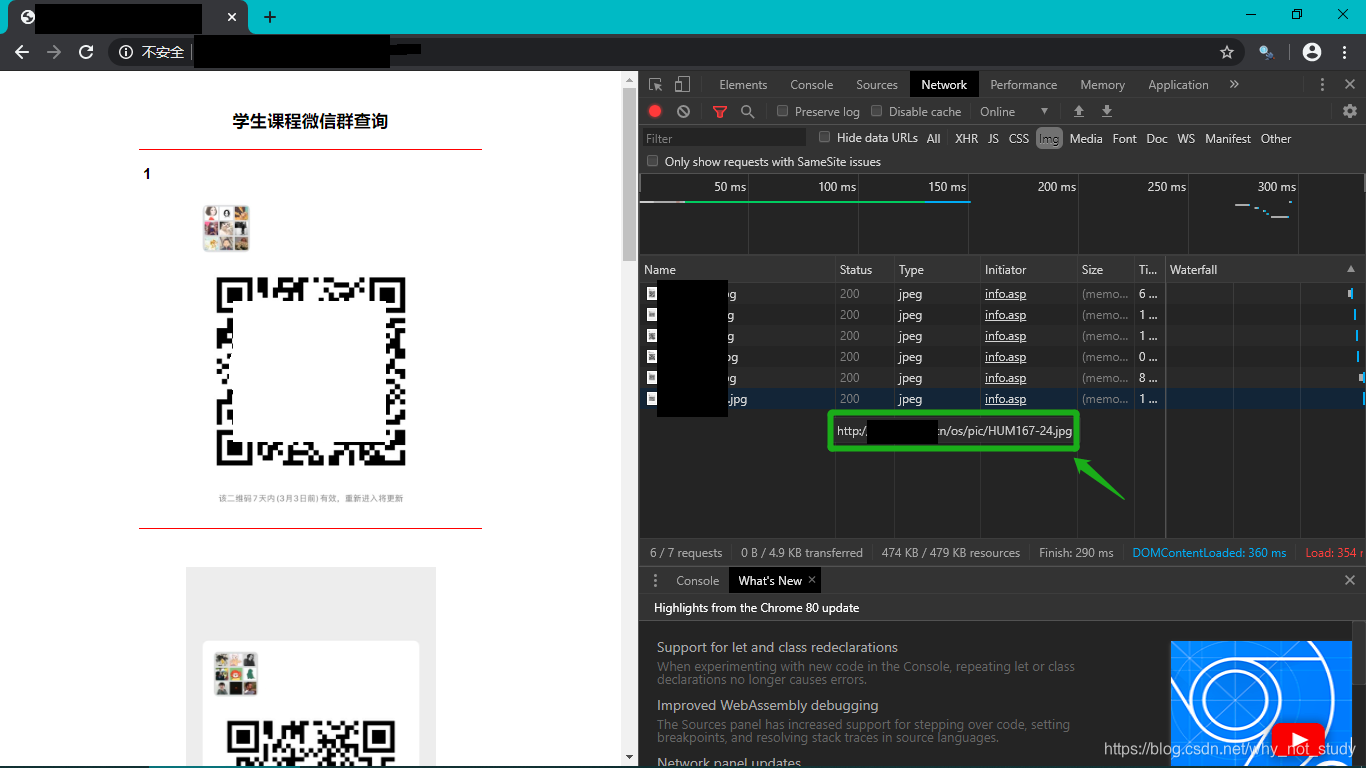
打开学校指定的查询课程二维码的网站,找到图片对应的http请求返回的图片链接,发现所有图片的链接都是http://xxx.cn/os/pic/+课程号-课序号+.jpg的格式。因此,只要将对应的课程号-课序号与之进行拼接即可完成爬取。
2、使用requests包爬取相关网页图片
requests包最简单的爬虫:
import requests
r = requests.get(url)之后进一步完成存储工作即可。
三、解决
#从csv读取所有课程号-课序号,并拼接成网页链接
import pandas as pd
csv_data = pd 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1209
1209

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









