







文章目录
大数据组件之Flink

一.Flink简介
Flink是什么?
Apache Flink is a framework and distributed processing engine for stateful computations over unbounded and bounded data streams. Flink has been designed to run in all common cluster environments, perform computations at in-memory speed and at any scale.
Apache Flink是一个框架和分布式处理引擎,用于在无界和有界数据流上进行有状态计算。Flink被设计为在所有常见的集群环境中运行,以内存速度和任何规模执行计算。
Flink官网:https://flink.apache.org
Flink的特点
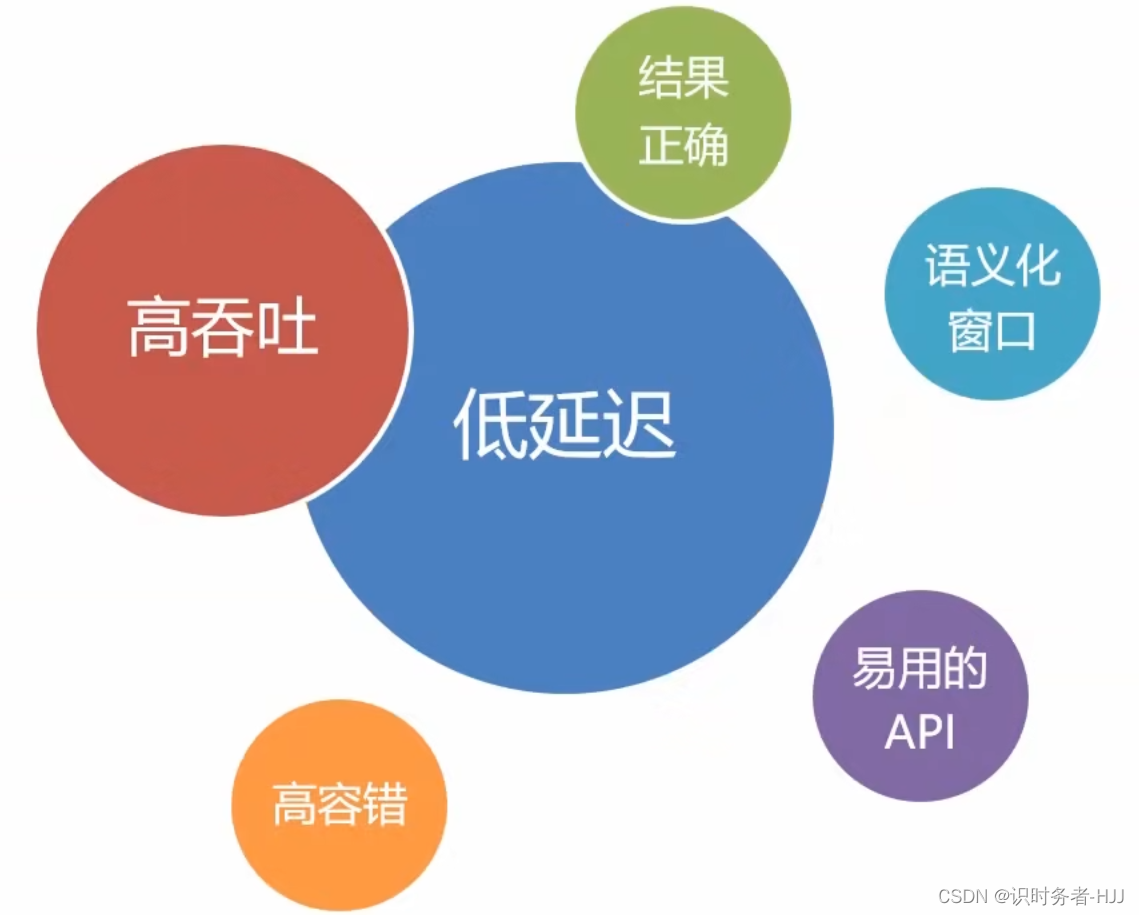
Flink框架处理流程

Flink发展时间线

Flink在企业中的应用

Flink的应用场景
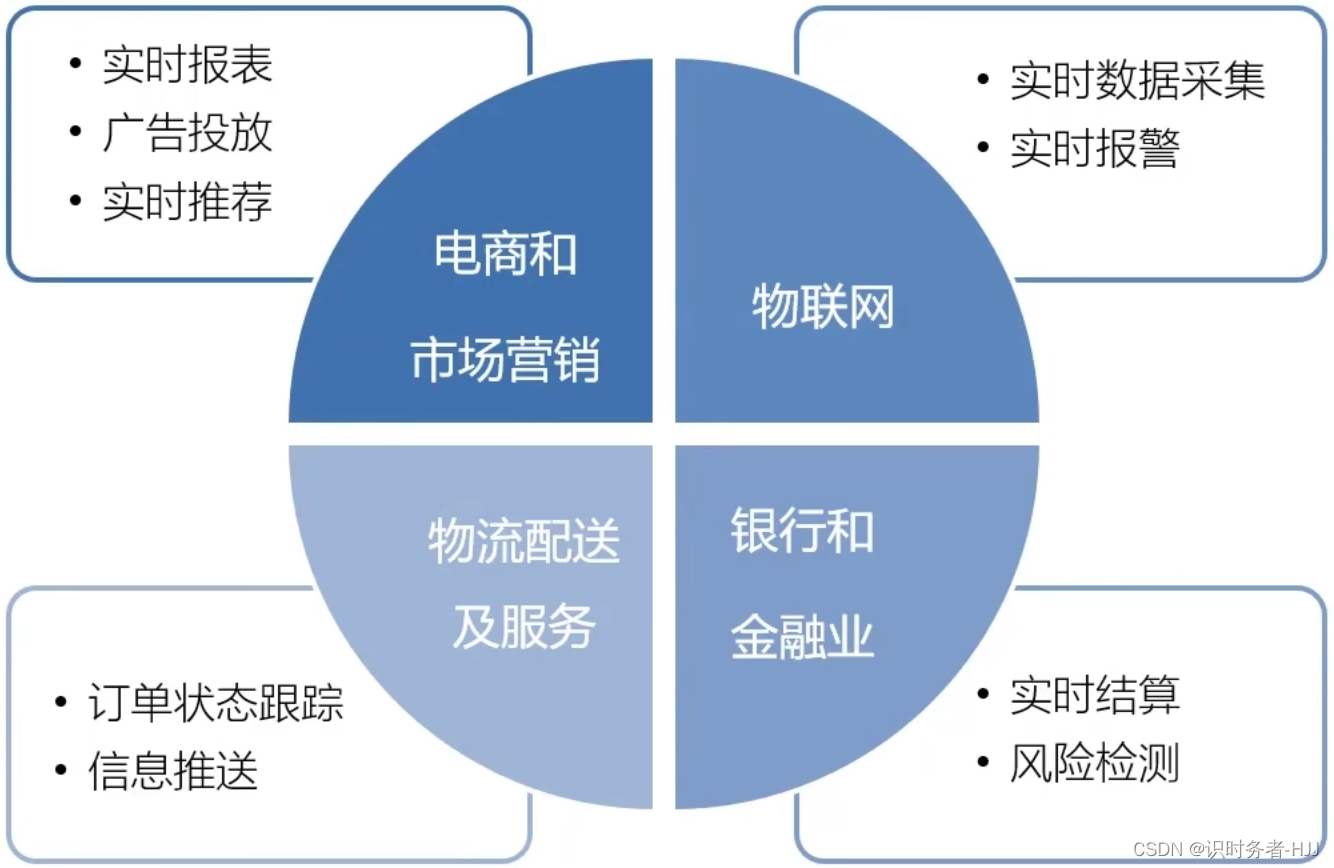
为什么选择Flink?

传统数据处理架构
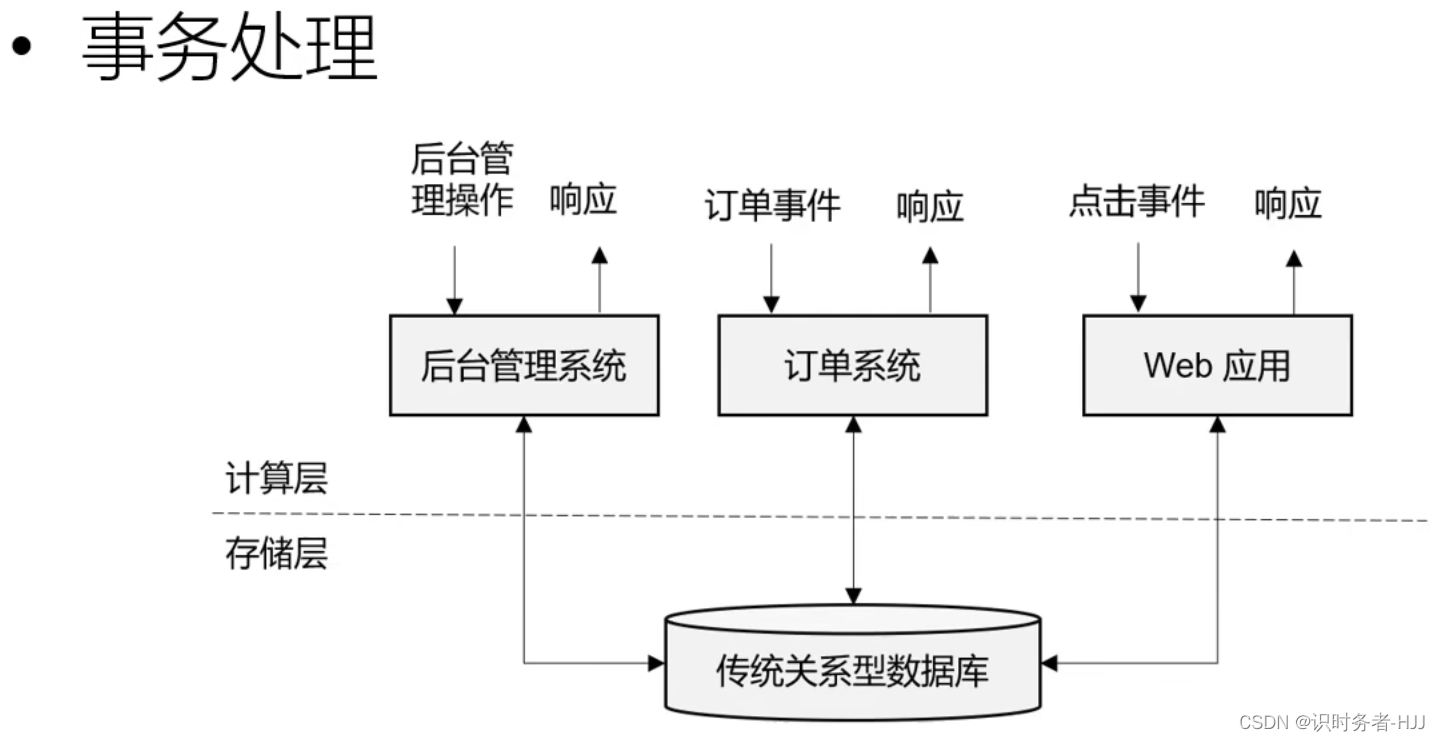
关系型数据库的性能瓶颈,无法支撑大数据下的数据计算。
有状态的流式处理(第一代流式处理架构)
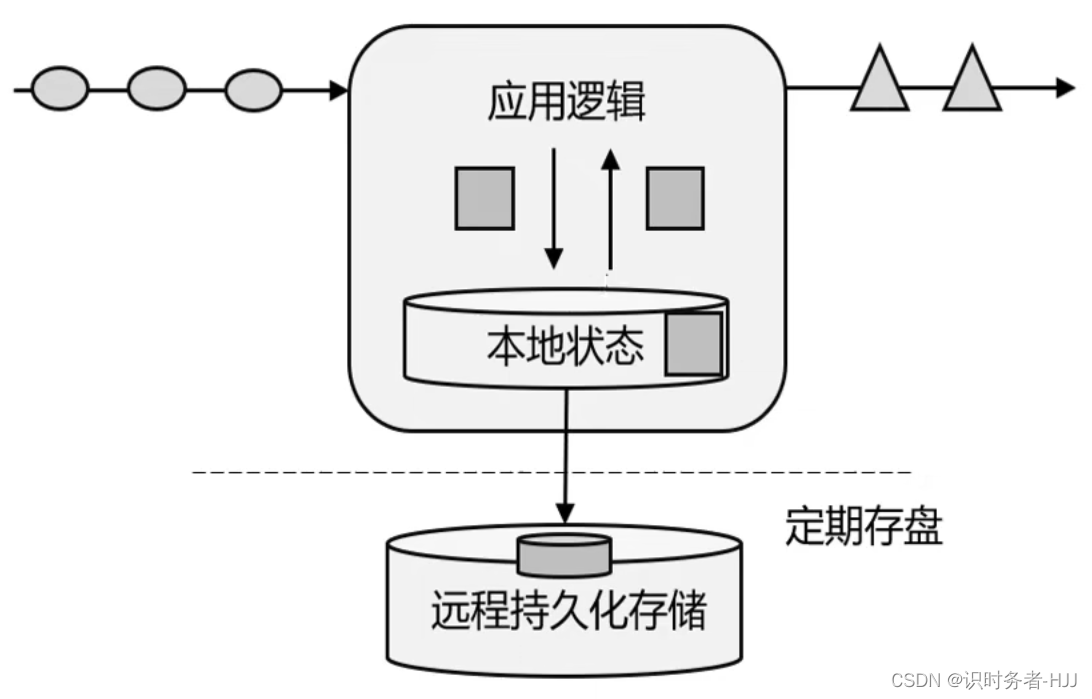 基于传统数据处理架构,使用本地状态存在内存中,定期存盘,发生故障可以从持久化存储中恢复数据。
基于传统数据处理架构,使用本地状态存在内存中,定期存盘,发生故障可以从持久化存储中恢复数据。
但当数据量很大时,使用集群模式,不同的应用有不同的本地状态,各自处理各自的数据,互不干扰。在分布式处理架构中,数据在传输和处理的过程中,时间是不确定的,数据可能会产生乱序,当需要进行数据汇总时,无法保证之前数据处理的顺序,导致结果不准确。
流处理的演变(第二代流式处理架构)
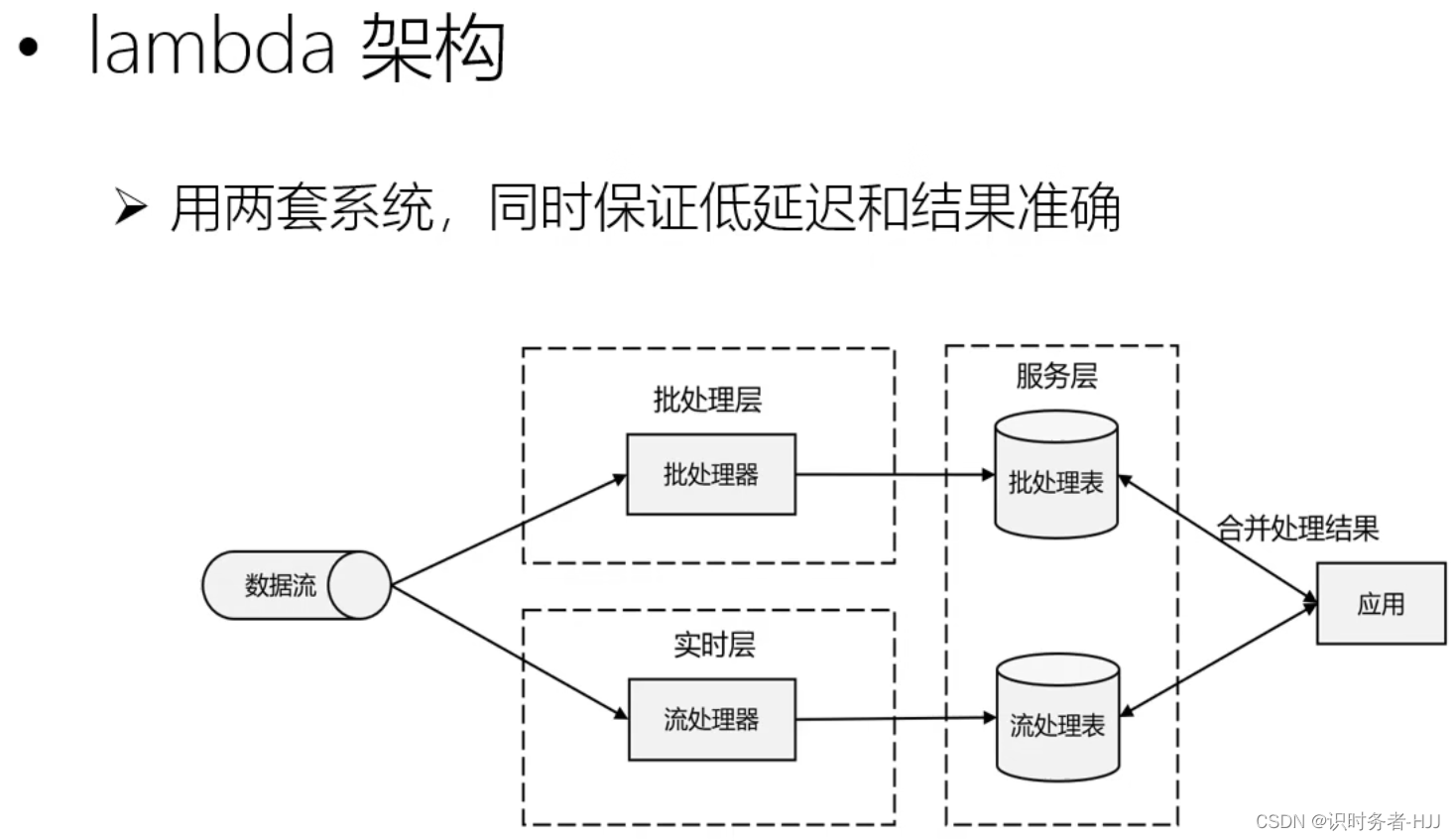 流处理器确保数据处理的低延迟,批处理器确保数据处理的准确性。但系统过于复杂,实现一个需求,同时要维护两套系统,开发及维护成本过高。
流处理器确保数据处理的低延迟,批处理器确保数据处理的准确性。但系统过于复杂,实现一个需求,同时要维护两套系统,开发及维护成本过高。
新一代流处理器——Flink(第三代分布式流处理器)
 Flink使用一套系统实现 lambda 架构中的两套功能,对于Flink而言,每秒钟能处理百万个事件,毫秒级的延迟并且可以保证结果的准确性。
Flink使用一套系统实现 lambda 架构中的两套功能,对于Flink而言,每秒钟能处理百万个事件,毫秒级的延迟并且可以保证结果的准确性。
流处理的应用场景
Flink的分层 API
Flink vs Spark
Flink数据处理架构:
Spark数据处理架构:
 数据模型:
数据模型:
 运行时架构:
运行时架构:

二.快速上手Flink
API 简介
Flink底层是以Java编写的,并为开发人员同时提供了完整的Java和Scala API,在具体项目应用中,可以根据需要选择合适语言的 API 进行开发。
环境准备
- Win 11
- JDK 1.8
- Maven
- IDEA
- Git
导入依赖
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<java.version>1.8</java.version>
<flink.version>1.13.0</flink.version>
<scala.binary.version>2.12</scala.binary.version>
<slf4j.version>1.7.30</slf4j.version>
</properties>
<!-- 引入 Flink 相关依赖-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- 引入日志管理相关依赖 -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>${slf4j.version}</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>${slf4j.version}</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-to-slf4j</artifactId>
<version>2.14.0</version>
</dependency>
<!-- 打包插件 -->
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.0.0</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
日志配置
在 resources 下创建 log4j.properties 文件
log4j.rootLogger=error, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%-4r [%t] %-5p %c %x - %m%n
提供数据
在项目下创建 input 文件夹,在此文件夹下创建 words.txt 文件,内容为:
hello world
hello flink
hello java
批处理 Word Count
新建 BatchWordCount.java
package com.handsome.wordcount;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.AggregateOperator;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.operators.FlatMapOperator;
import org.apache.flink.api.java.operators.UnsortedGrouping;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;
/**
* @ClassName BatchWordCount
* @Author Handsome
* @Date 2022/12/19 14:37
* @Description 批处理 Word Count
*/
public class BatchWordCount {
public static void main(String[] args) throws Exception {
// 1.创建执行环境
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// 2.从文件读取数据(使用的是 DataSet API)
DataSource<String> lineDataSource = env.readTextFile("input/words.txt");
// 3.将每行数据进行分词,转换成二元组类型(line 行数据 Collector 收集器)
FlatMapOperator<String, Tuple2<String, Long>> wordAndOneTuple = lineDataSource.flatMap((String line, Collector<Tuple2<String, Long>> out) -> {
// 将一行文本进行分词
String[] words = line.split(" ");
// 将每个单词转换成二元组输出
for (String word : words) {
out.collect(Tuple2.of(word, 1L));
}
}).returns(Types.TUPLE(Types.STRING, Types.LONG));
// 4.按照 word 进行分组
UnsortedGrouping<Tuple2<String, Long>> wordAndOneGroup = wordAndOneTuple.groupBy(0);
// 5.分组内进行聚合统计
AggregateOperator<Tuple2<String, Long>> sum = wordAndOneGroup.sum(1);
// 6.打印结果
sum.print();
}
}
打印结果
(flink,1)
(world,1)
(hello,3)
(java,1)
匿名函数( Lambda 表达式 )是 Java 8 引入的新特性,方便我们更加快速清晰地写代码。
Lambda 表达式允许以简洁的方式实现函数,以及将函数作为参数来进行传递,而不必声明额外的(匿名)类。Flink 的所有算子都可以使用 Lambda 表达式的方式来进行编码。但是,当 Lambda 表达式使用 Java 的泛型时,我们需要显式的声明类型信息。
对于像 flatMap() 这样的函数,它的函数签名 void flatMap(IN value, Collector out) 被 Java 编译器编译成了 void flatMap(IN value, Collector out) ,也就是说将 Collector 的泛 型信息擦除掉了,这样 Flink 就无法自动推断输出的类型信息了。
当使用 map() 函数返回 Flink 自定义的元组类型时也会发生类似的问题,下例中的函数签名 Tuple2<String, Long> map(Event value) 被类型擦除为 Tuple2 map(Event value) 。
因此我们需要显式地指定类型信息 .returns(Types.TUPLE(Types.STRING, Types.LONG));
流处理 Word Count
新建 BoundedStreamWordCount.java
package com.handsome.wordcount;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
/**
* @ClassName BoundedStreamWordCount
* @Author Handsome
* @Date 2022/12/19 15:26
* @Description 流处理 Word Count
*/
public class BoundedStreamWordCount {
public static void main(String[] args) throws Exception {
// 1.创建流式执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 2.从文件读取数据(使用的是 DataStream API)
DataStreamSource<String> lineDataStreamSource = env.readTextFile("input/words.txt");
// 3.将每行数据进行分词,转换成二元组类型(line 行数据 Collector 收集器)
SingleOutputStreamOperator<Tuple2<String, Long>> wordAndOneTuple = lineDataStreamSource.flatMap((String line, Collector<Tuple2<String, Long>> out) -> {
// 将一行文本进行分词
String[] words = line.split(" ");
// 将每个单词转换成二元组输出
for (String word : words) {
out.collect(Tuple2.of(word, 1L));
}
}).returns(Types.TUPLE(Types.STRING, Types.LONG));
// 4.按照 word 进行分组
KeyedStream<Tuple2<String, Long>, String> wordAndOneKeyedStream = wordAndOneTuple.keyBy(data -> data.f0);
// 5.分组内进行聚合统计
SingleOutputStreamOperator<Tuple2<String, Long>> sum = wordAndOneKeyedStream.sum(1);
// 6.打印结果
sum.print();
// 7.启动执行
env.execute();
}
}
打印结果
9> (world,1)
3> (java,1)
13> (flink,1)
5> (hello,1)
5> (hello,2)
5> (hello,3)
IDEA使用多线程模拟了Flink集群,因此每次输出的结果可能都不相同,前面的数字为线程的编号,未设置并行度则默认为电脑最大核数。
与批处理程序 BatchWordCount 的不同:
1.创建执行环境的不同,流处理程序使用的是 StreamExecutionEnvironment 。
2.每一步处理转换之后,得到的数据对象类型不同。
3.分组操作调用的是 keyBy 方法,可以传入一个匿名函数作为键选择器(KeySelector ),指定当前分组的 key 是什么。
4.代码末尾需要调用 env 的 execute 方法,开始执行任务。
读取文本流 Work Count
新建 StreamWorkCount.java
package com.handsome.wordcount;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
/**
* @ClassName StreamWorkCount
* @Author Handsome
* @Date 2022/12/19 17:24
* @Description 读取文本流 Work Count
*/
public class StreamWorkCount {
public static void main(String[] args) throws Exception {
// 1.创建流式执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 从参数中提取主机名和端口号
//ParameterTool parameterTool = ParameterTool.fromArgs(args);
//String host = parameterTool.get("host");
//int port = parameterTool.getInt("port");
//DataStreamSource<String> lineDataStream = env.socketTextStream(host, port);
// 2.读取文本流
DataStreamSource<String> lineDataStream = env.socketTextStream("8.142.157.59", 6666);
// 3.将每行数据进行分词,转换成二元组类型(line 行数据 Collector 收集器)
SingleOutputStreamOperator<Tuple2<String, Long>> wordAndOneTuple = lineDataStream.flatMap((String line, Collector<Tuple2<String, Long>> out) -> {
// 将一行文本进行分词
String[] words = line.split(" ");
// 将每个单词转换成二元组输出
for (String word : words) {
out.collect(Tuple2.of(word, 1L));
}
}).returns(Types.TUPLE(Types.STRING, Types.LONG));
// 4.按照 word 进行分组
KeyedStream<Tuple2<String, Long>, String> wordAndOneKeyedStream = wordAndOneTuple.keyBy(data -> data.f0);
// 5.分组内进行聚合统计
SingleOutputStreamOperator<Tuple2<String, Long>> sum = wordAndOneKeyedStream.sum(1);
// 6.打印结果
sum.print();
// 7.启动执行
env.execute();
}
}
8.142.157.59 为 Linux 服务器 IP 地址,需要根据不同的 Linux 服务器,填写不同的 IP 地址,6666 为 Linux 服务监听的端口号。
在 Linux 中执行 nc -lk 6666 监听 6666 端口
启动 StreamWorkCount.java
在 Linux 中输入要计算的数据
 打印结果
打印结果
5> (hello,1)
11> (handsome,1)
9> (world,1)
5> (hello,2)
13> (flink,1)
5> (hello,3)
3> (java,1)
5> (hello,4)
三.部署Flink
本地启动
直接本地启动,最简单的启动方式。本地部署非常简单,直接解压安装包就可以使用,不用进行任何配置,一般用来做一些简单的测试。
启动成功后,访问 http://IP:8081,IP 为 Linux 对应的 IP 地址,可以对 flink 集群和任务进行监控管理。
集群启动
如果想要扩展成集群,其实启动命令是不变的,主要是需要指定节点之间的主从关系。Flink 是典型的 Master-Slave 架构的分布式数据处理框架,其中 Master 角色对应着 JobManager,Slave 角色则对应 TaskManager。操作如下:
1.进入 conf 目录下,修改 flink-conf.yaml 文件,修改 jobmanager.rpc.address 参数为主节点 Linux 的 IP 地址。
2.修改 workers 文件,将另外两台节点服务器添加为本 Flink 集群的 TaskManager 节点。
3.配置修改完毕后,将 Flink 安装目录发给另外两个节点服务器。
4.在主节点服务器上执行 start-cluster.sh 启动 Flink 集群: ./bin/start-cluster.sh。
向集群提交作业的两种方式方式
第一种:打包程序,在 Web UI 上提交作业
第二种:命令行提交作业
$ ./bin/flink run -m IP:8081 -c
com.handsome.workcount.StreamWordCount ./FlinkDemo-2022.12.19.jar
这里的参数 –m 指定了提交到的 JobManager,-c 指定了入口类
部署模式
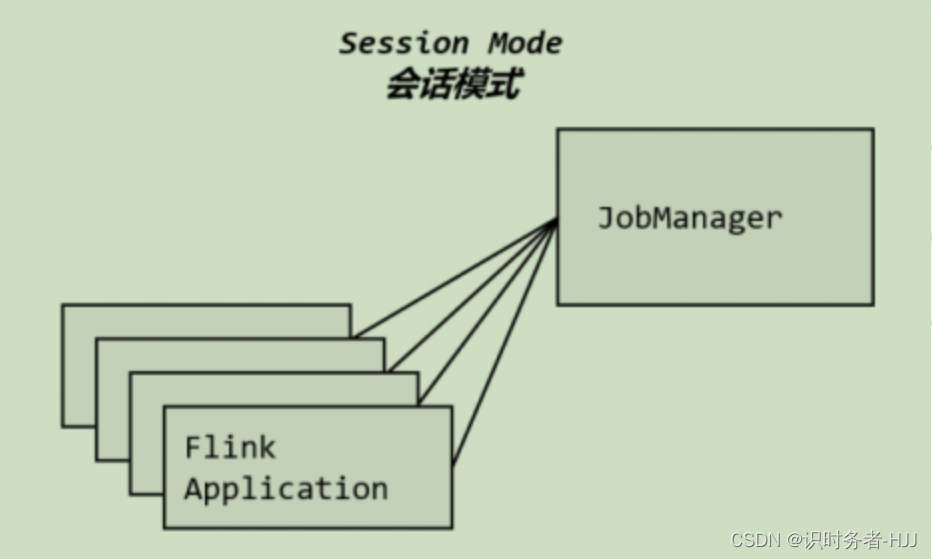
1.会话模式(Session Mode)
先启动集群,保持一个会话。集群只有一个,所有作业争夺资源。
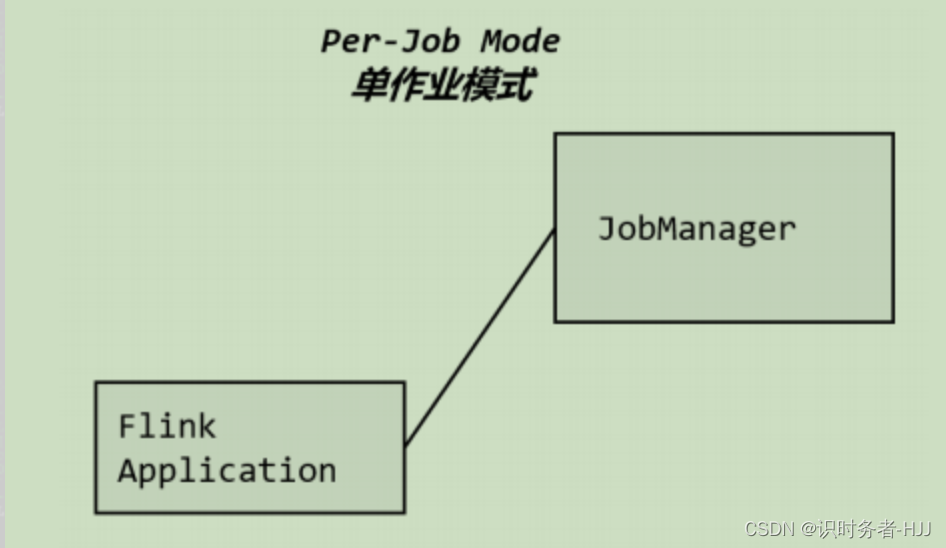
2.单作业模式(Per-Job Mode)
客户端运行程序,运行作业时再启动集群 ,一个作业启动一个集群,需要借助第三方资源调度器。这些特性使得单作业模式在生产环境运行更加稳定,所以是实际应用的首选模式。
3.应用模式(Application Mode)
直接把应用提交到 JobManger 上运行,需为每一个提交的应用单独启动一个 JobManager,也就是创建一个集群。这个 JobManager 只为执行这一个应用而存在,执行结束之后 JobManager 也就关闭了。
Standalone 模式 & Yarn 模式
1.Standalone 模式
资源调度由 Flink 自己负责,所需要的所有 Flink 组件,都只是操作系统上运行的一个 JVM 进程。
支持会话模式和应用模式,唯独不支持单作业模式,因为单作业模式需要其他资源调度器的参与。
2.Yarn 模式
动态分配资源,支持会话模式、单作业模式和应用模式。
3.高可用
YARN 模式的高可用和独立模式( Standalone )的高可用原理不一样。
Standalone 模式中,同时启动多个 JobManager,一个为“领导者”( leader ),其他为“后备” (standby ),当 leader 挂了,才会有其它的一个成为 leader 。
而 YARN 的高可用是只启动一个 Jobmanager,当这个 Jobmanager 挂了之后,YARN 会再次启动一个,所以其实是利用的 YARN 的重试次数来实现的高可用。
四.Flink运行时架构
系统架构
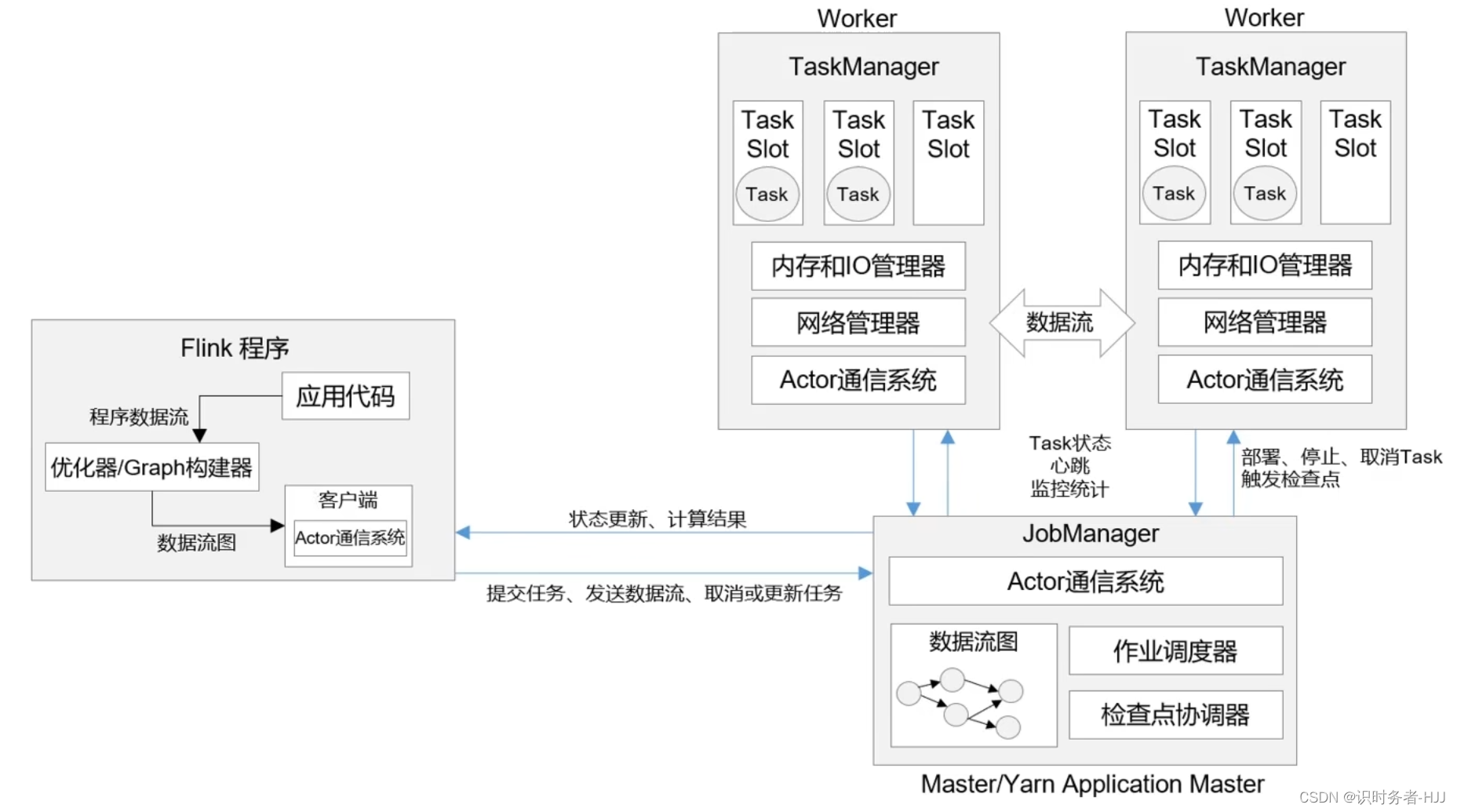
作业管理器(JobManager)


任务管理器(TaskManager)

作业提交流程
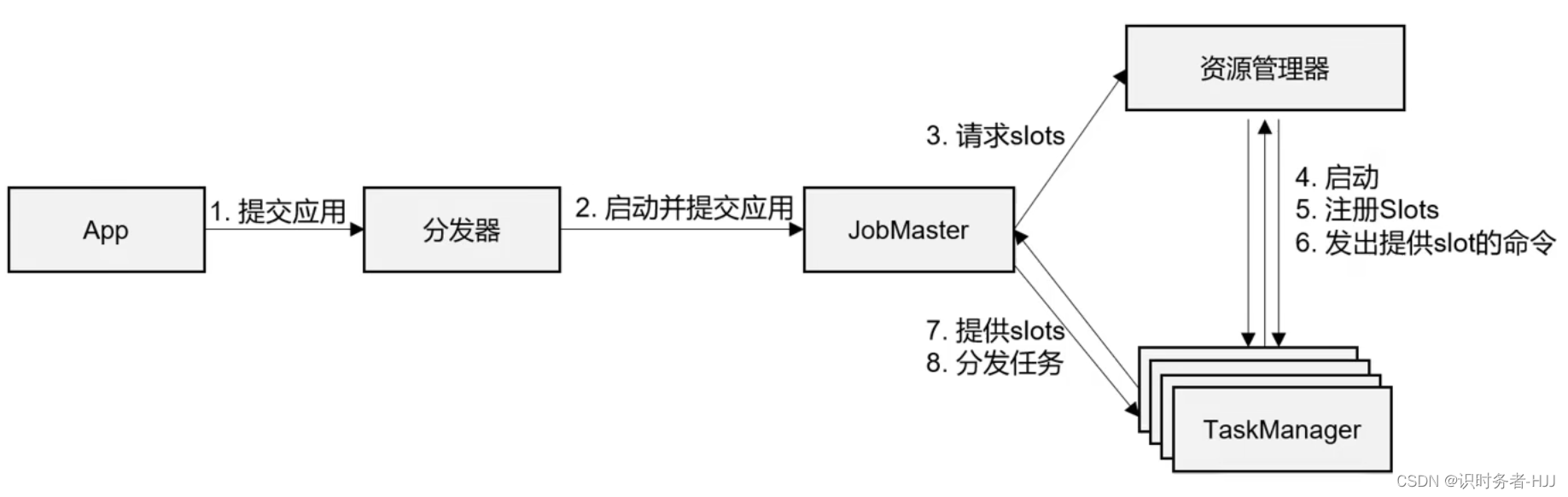
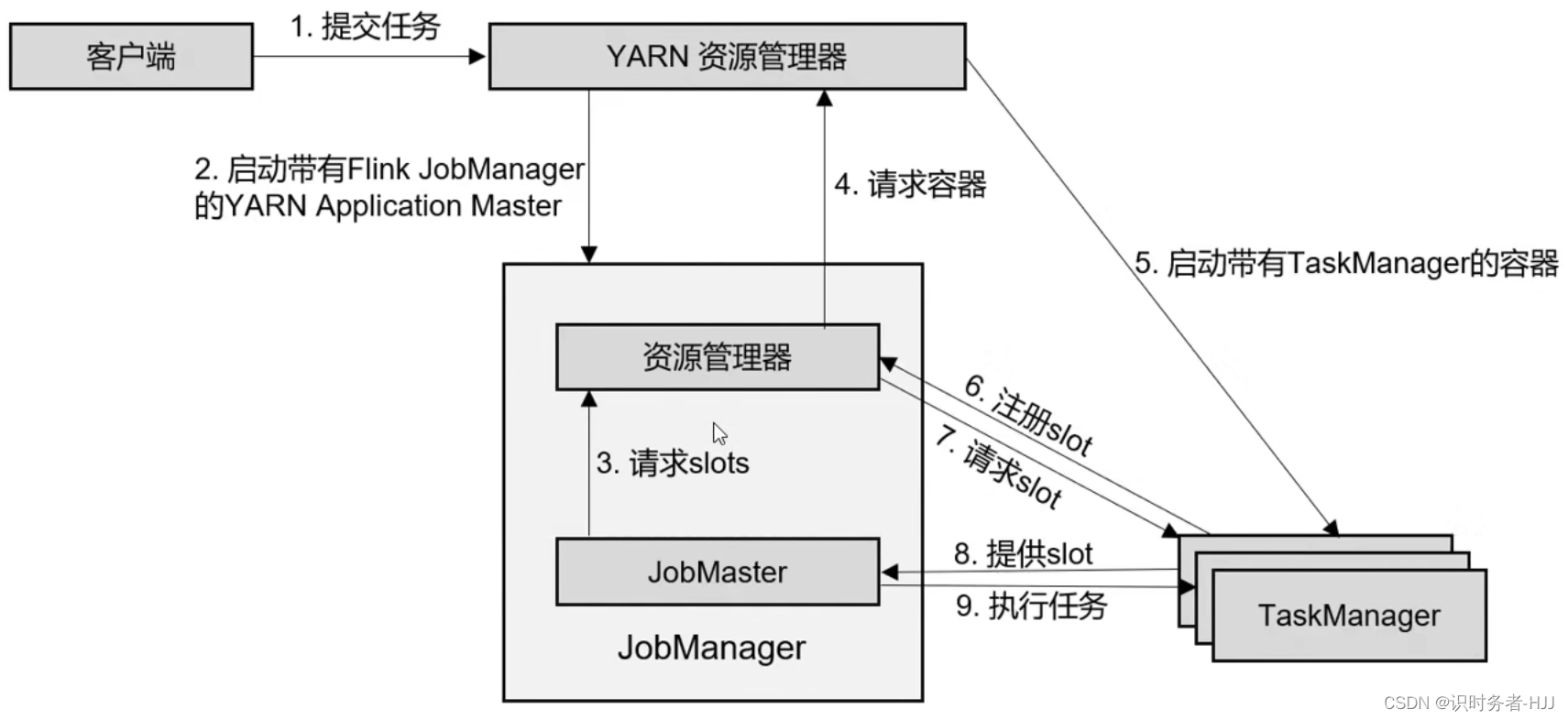
Standalone模式作业提交流程
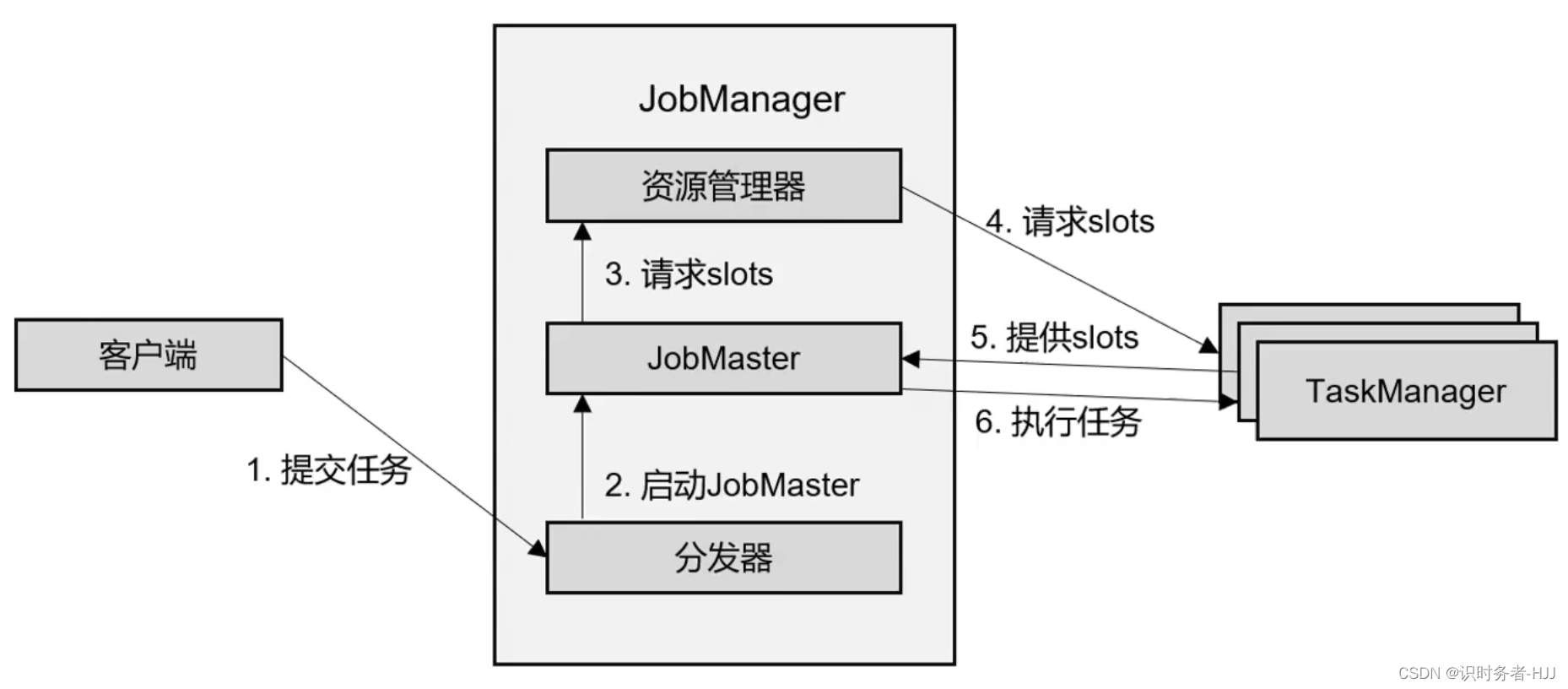
YARN会话模式作业提交流程
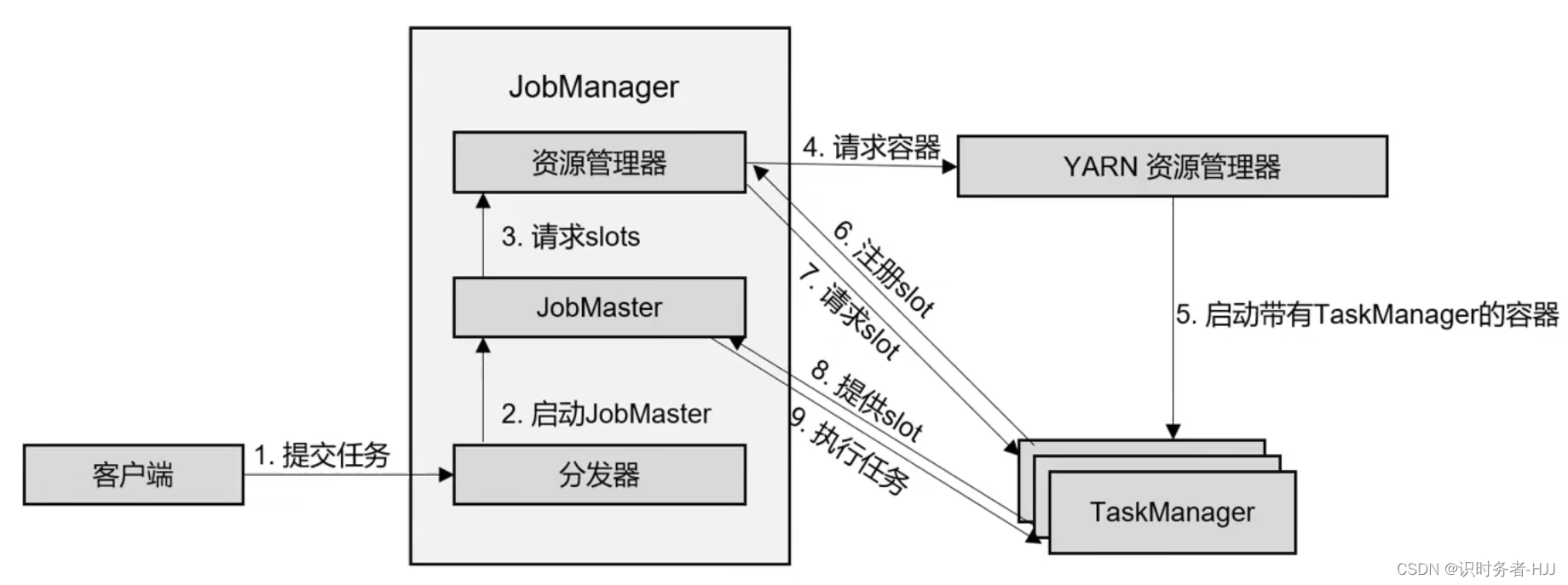
YARN单作业模式任务提交流程
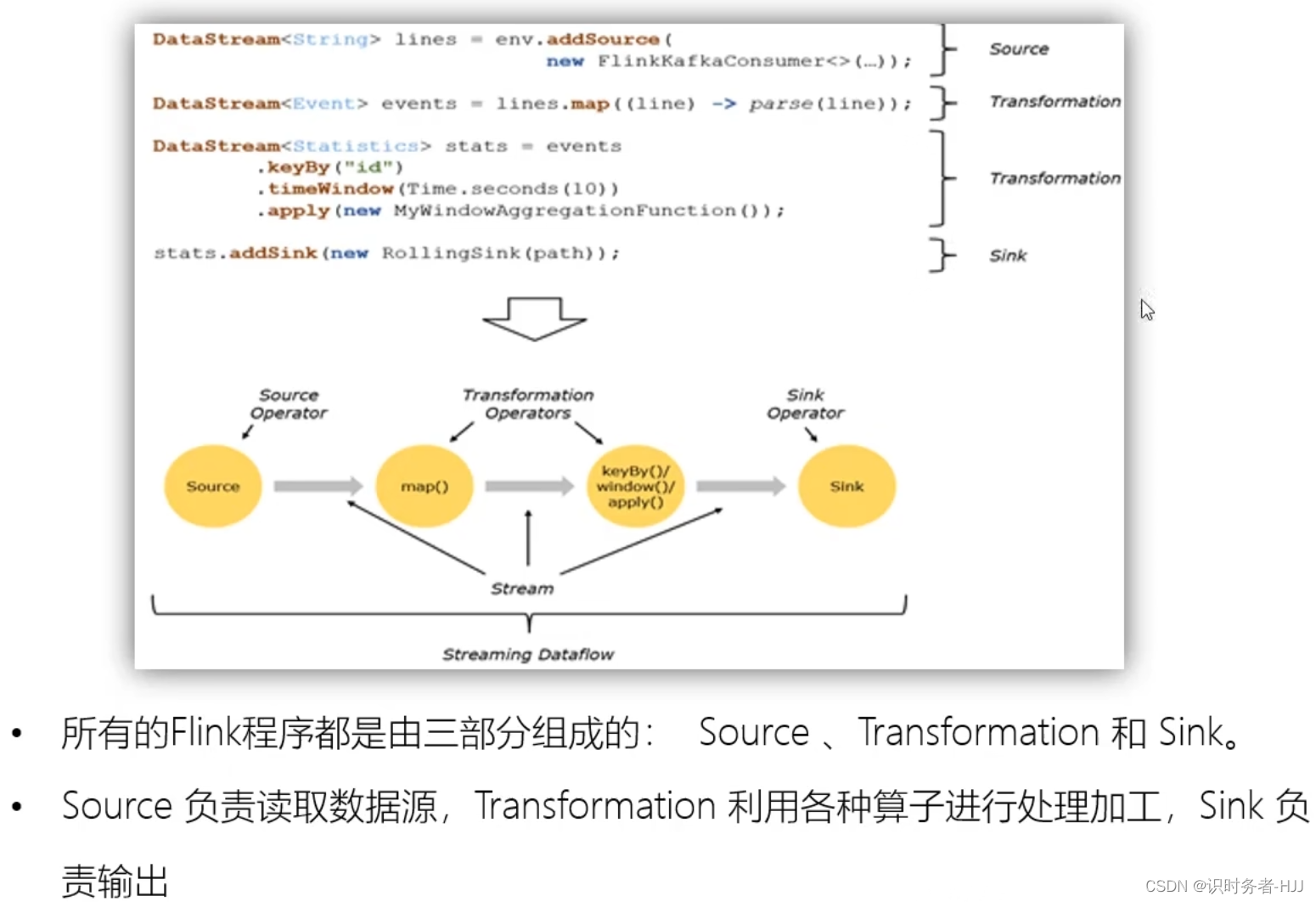
程序与数据流(DataFlow)
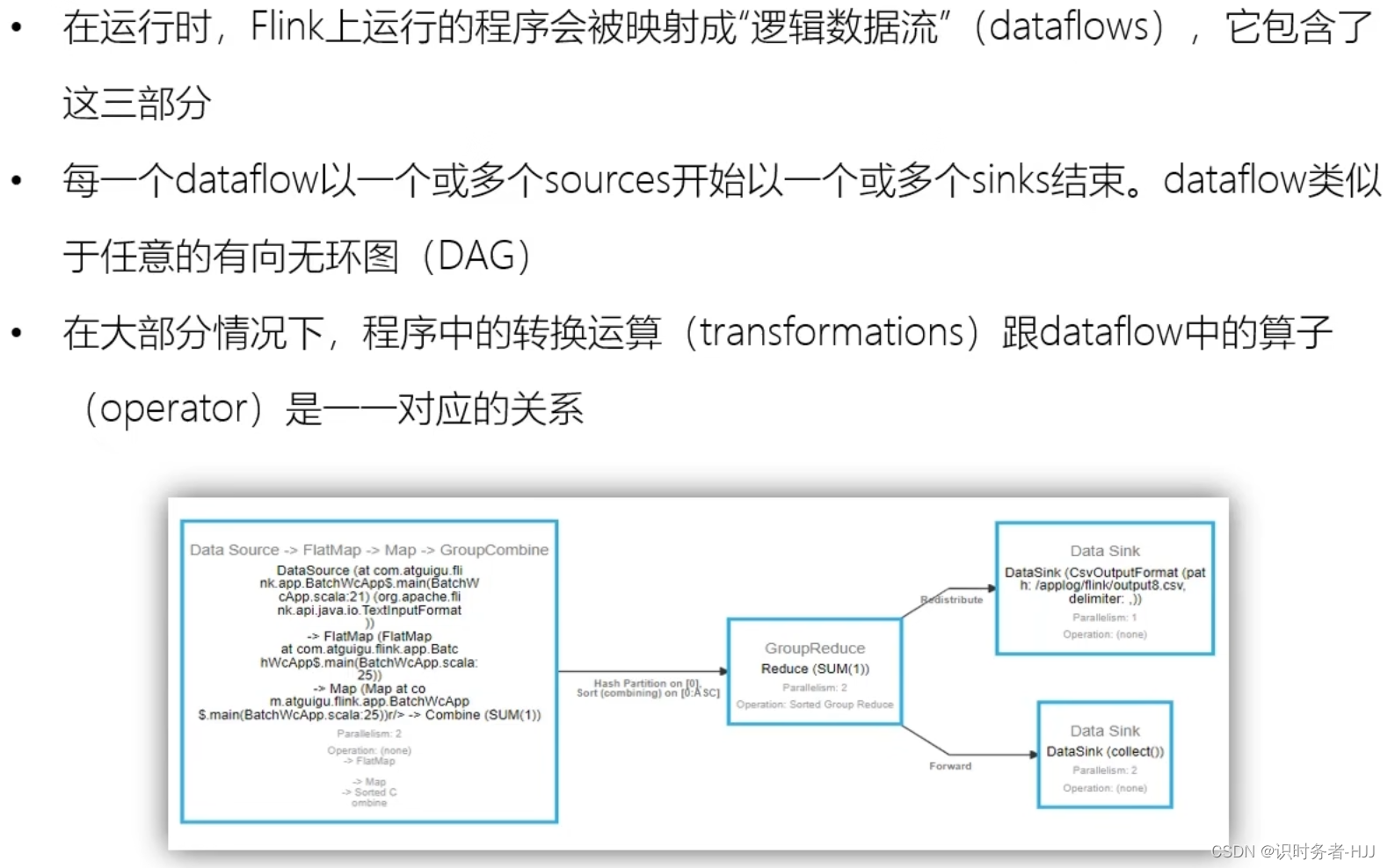
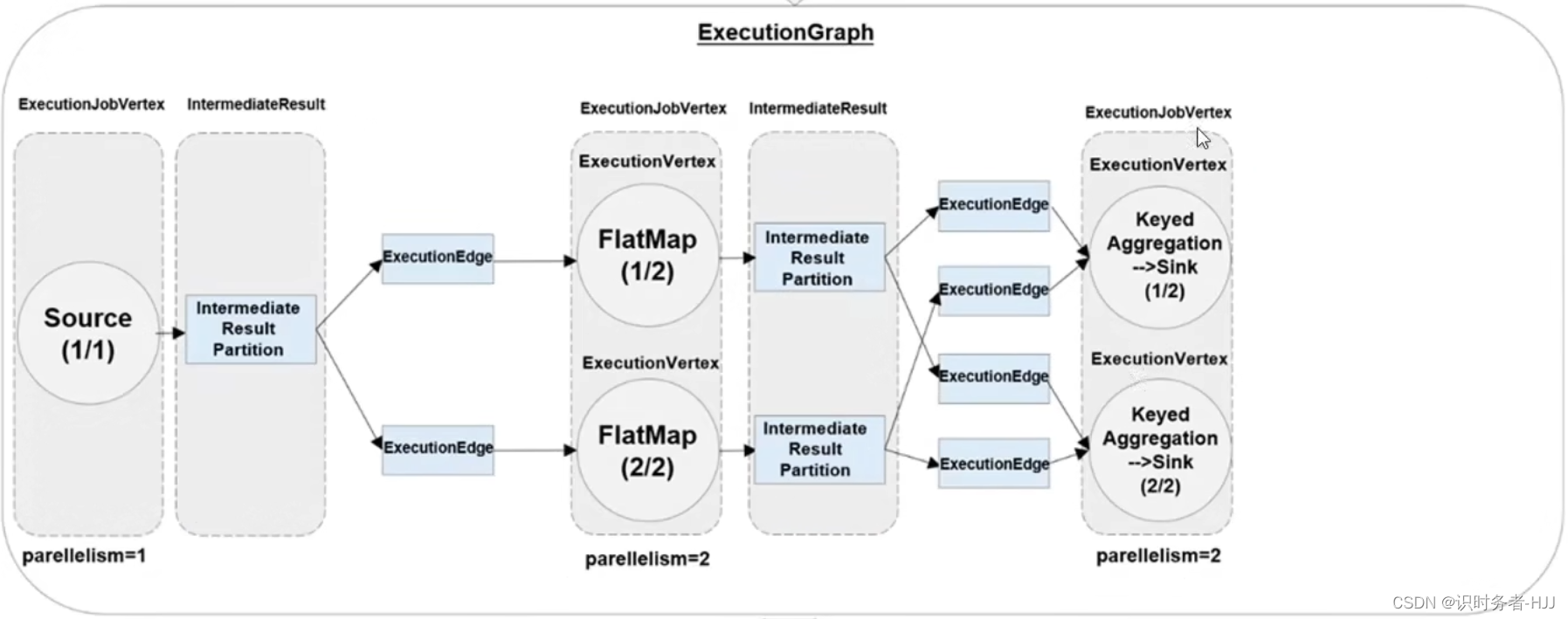
并行度(Parallelism)
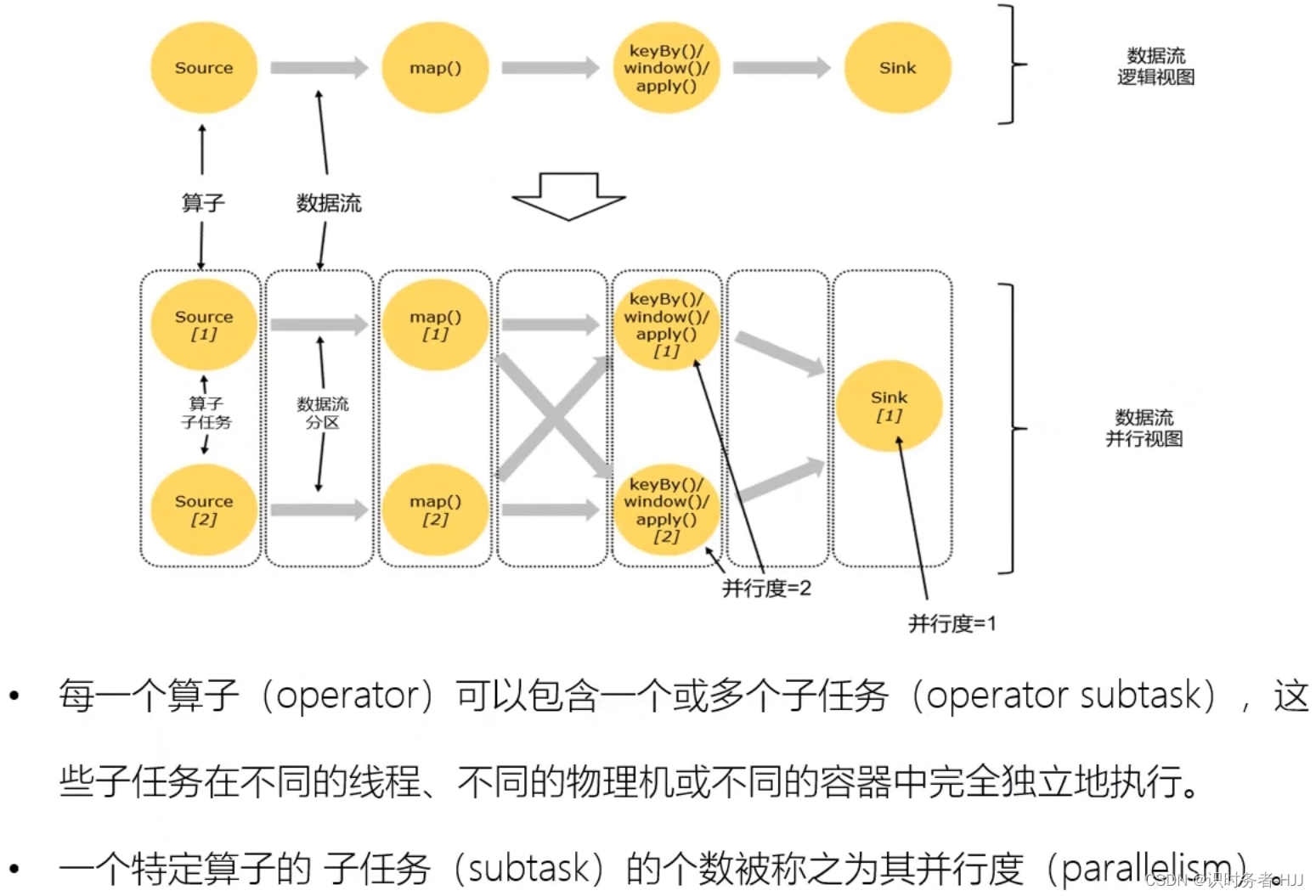
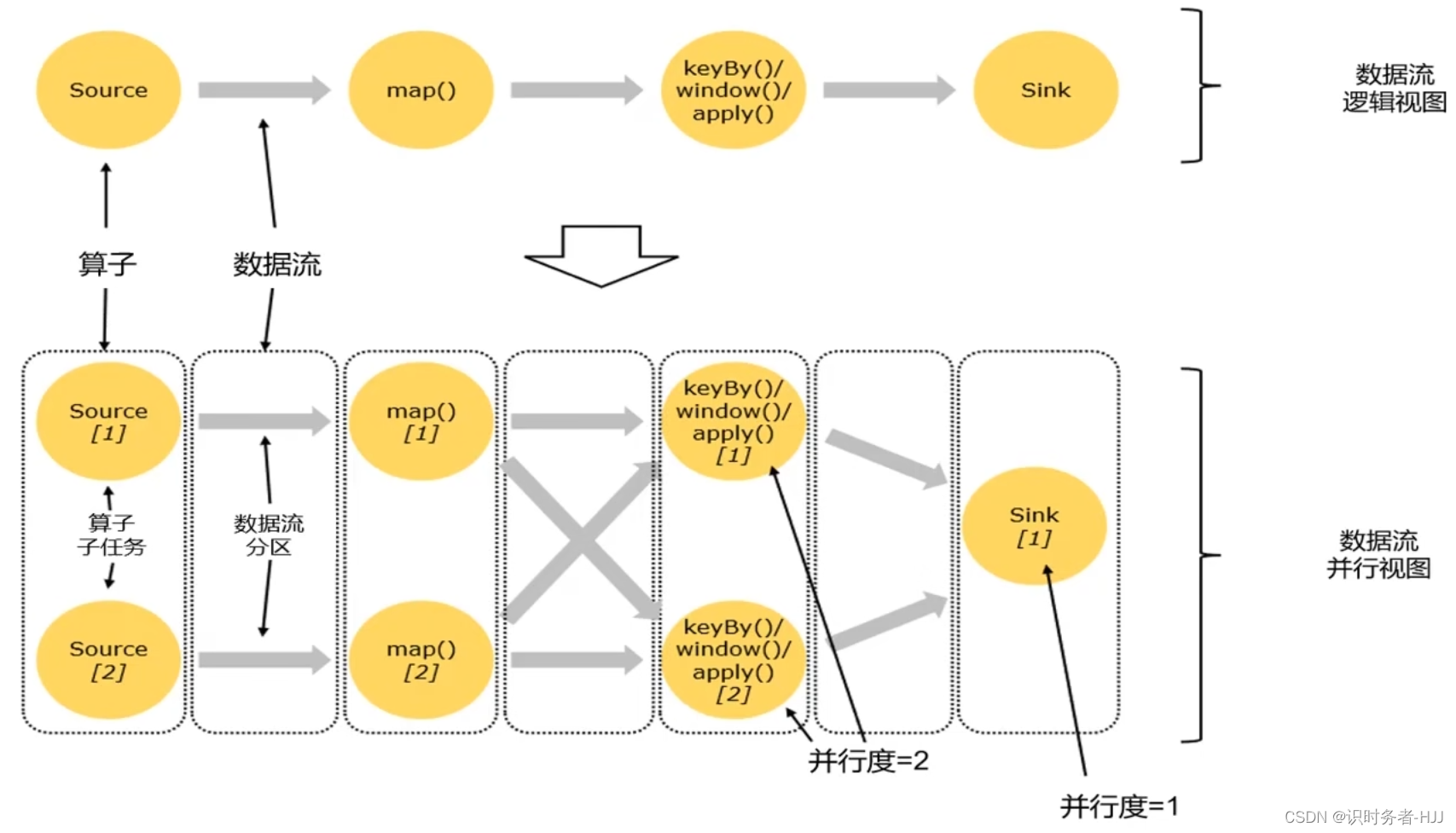
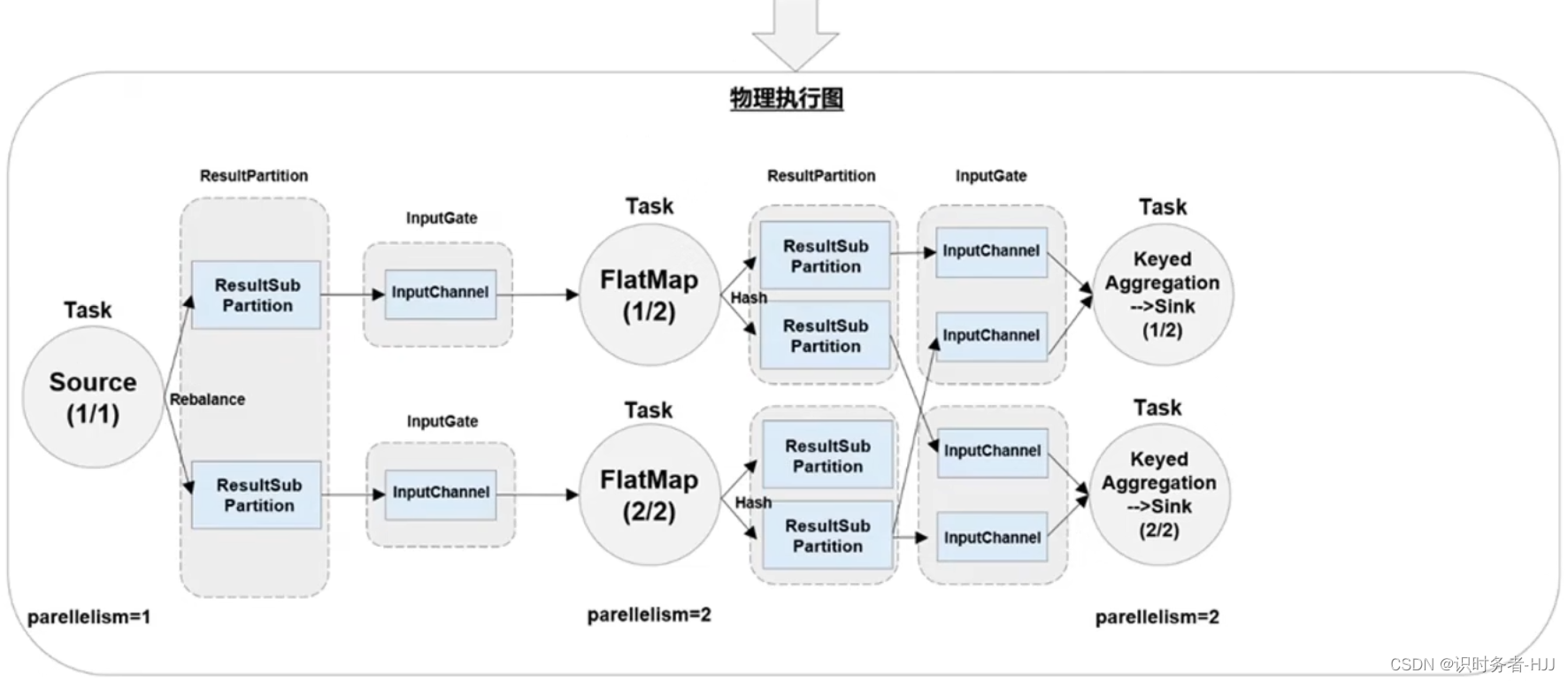
数据传输形式

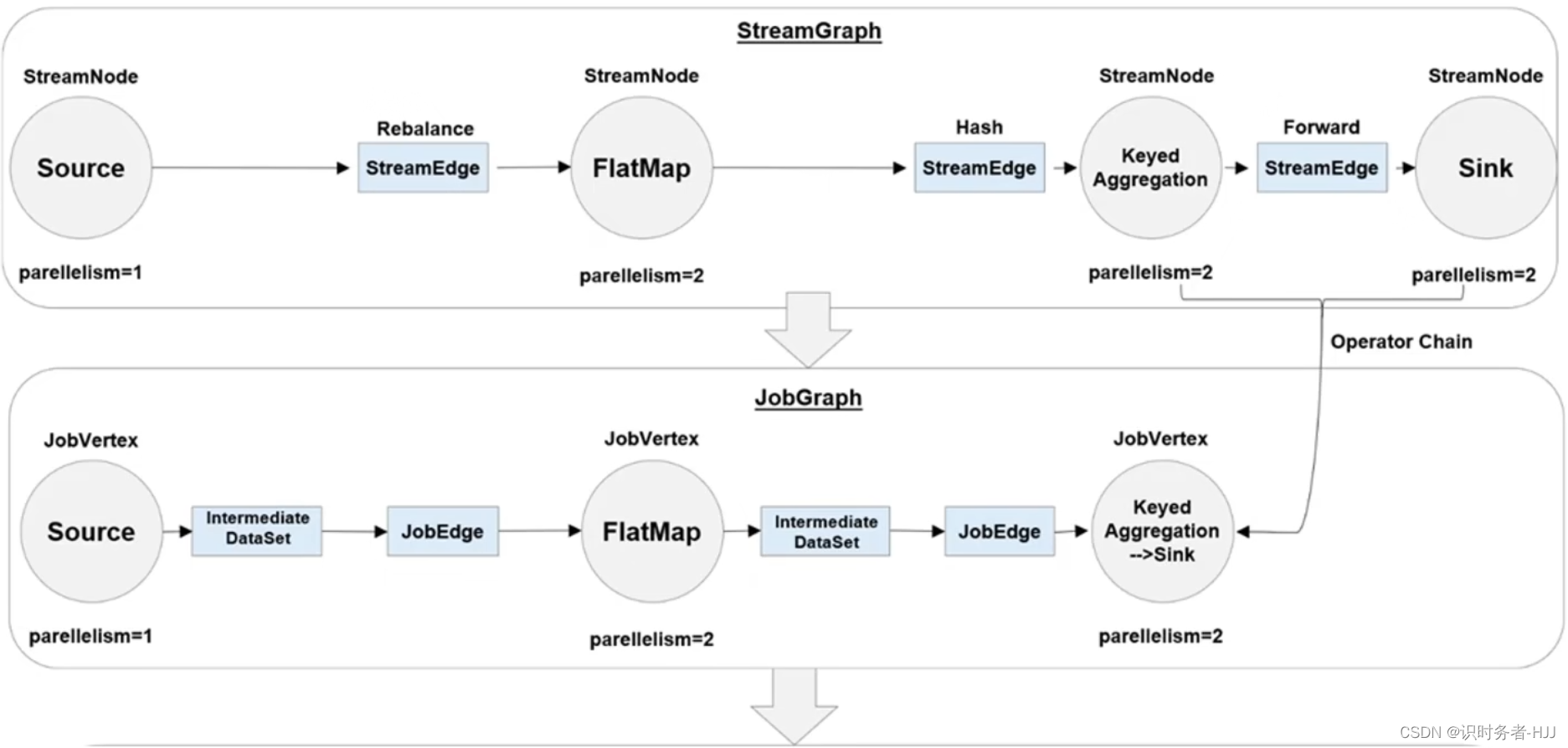
算子链(Operator Chains)

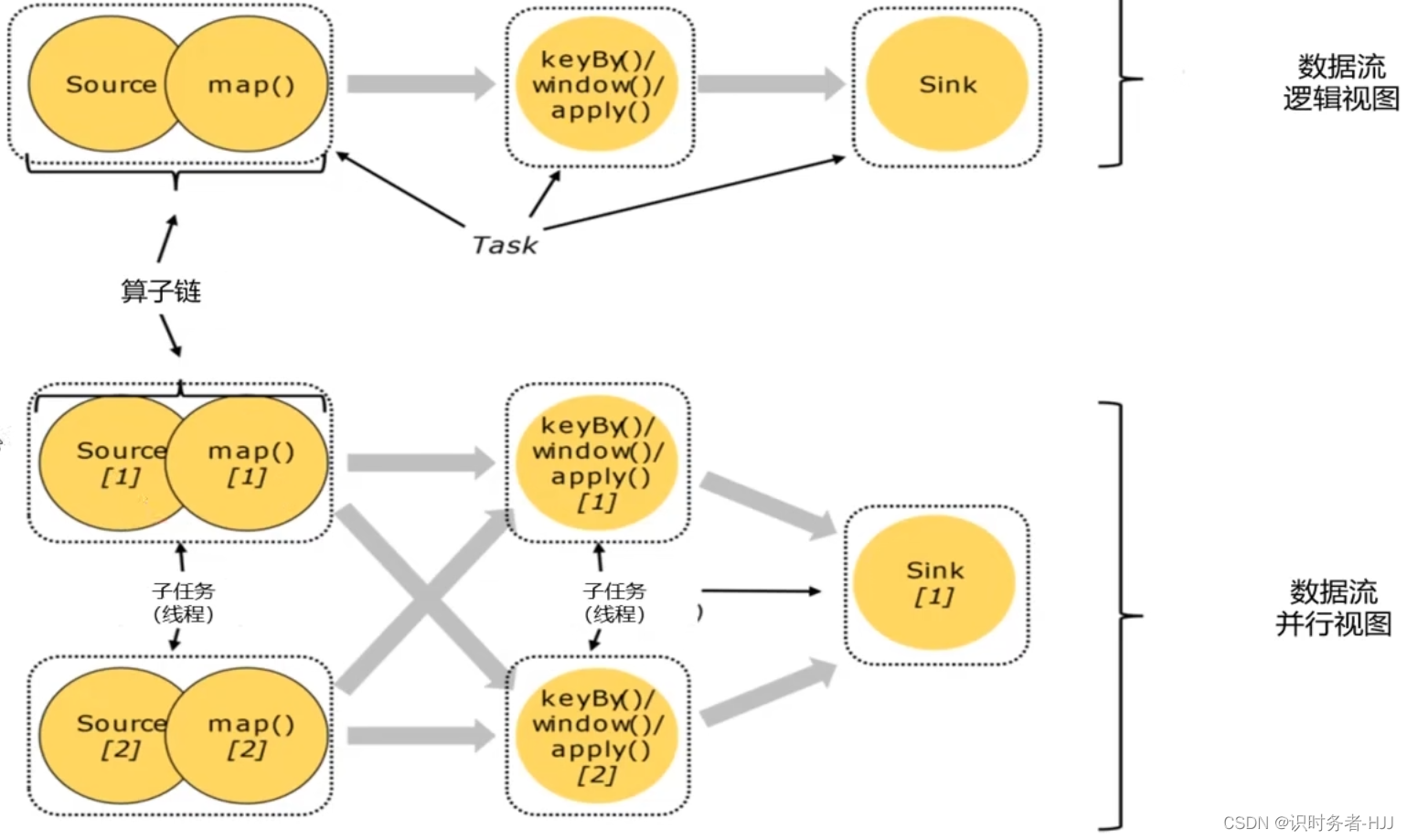
执行图(ExecutionGraph)

四层执行图
任务(Task)和任务槽(Task Slots)
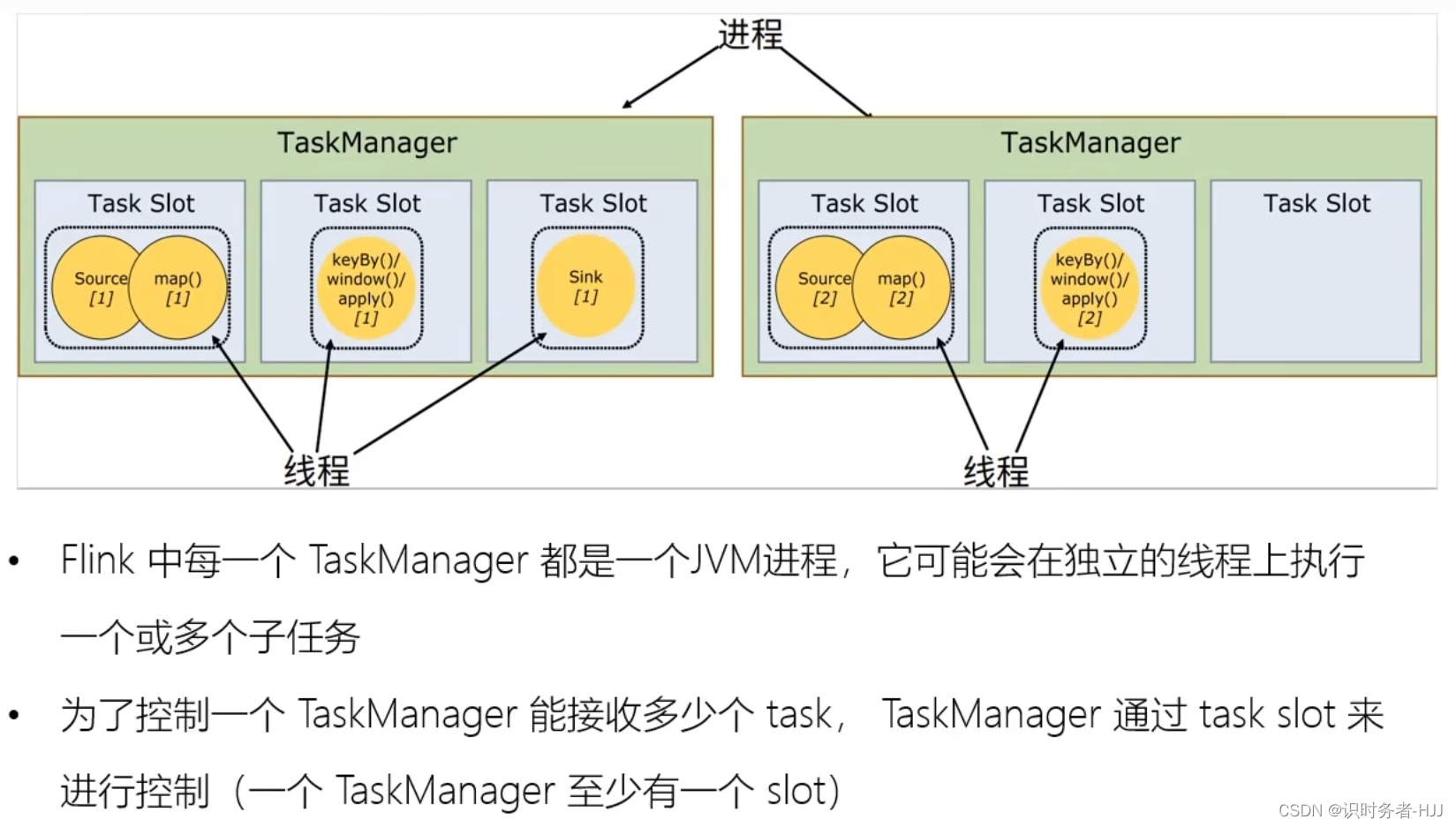
任务共享 Slot
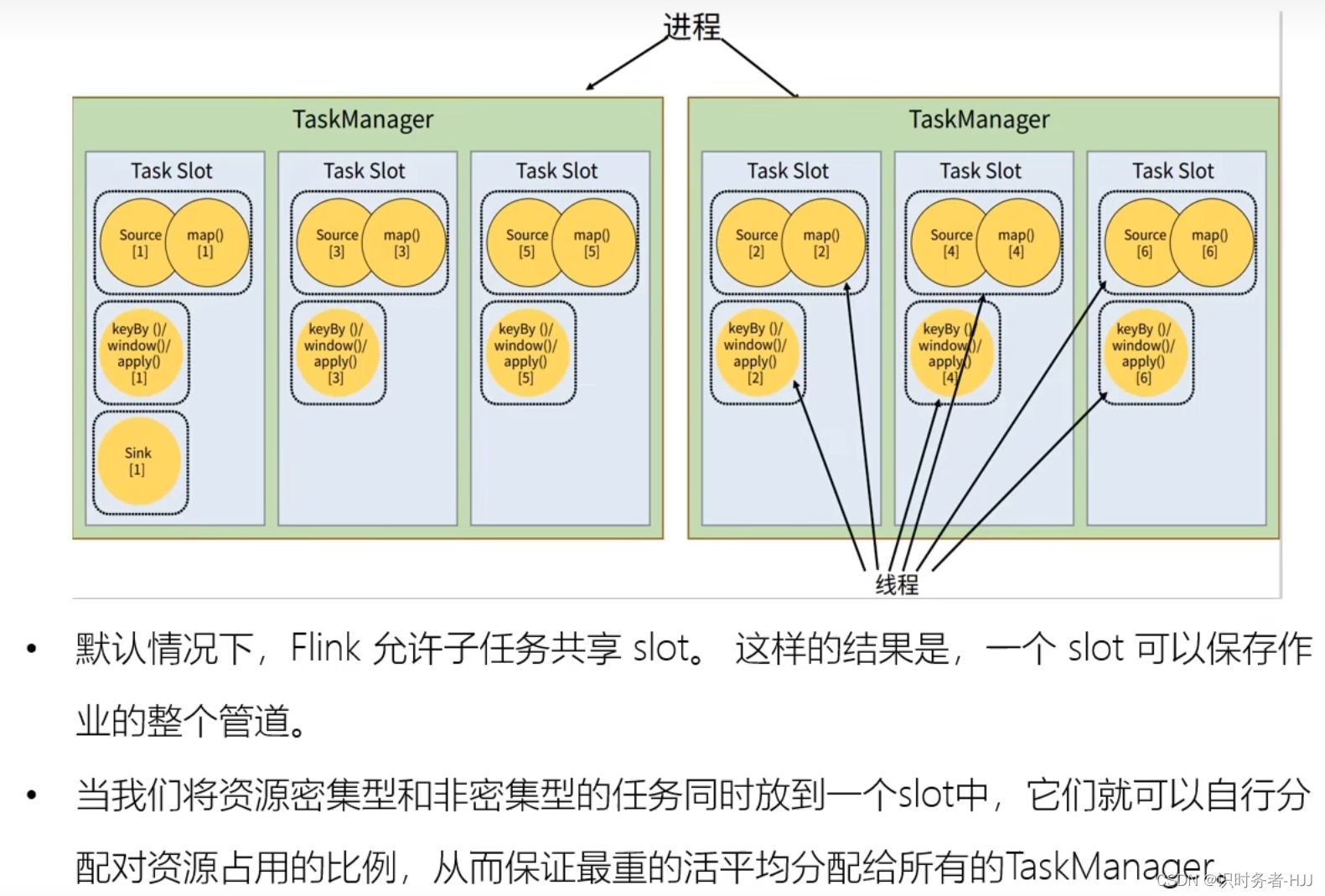
Slot 和并行度

五.DataStream API
执行环境
1.创建执行环境
(1)getExecutionEnvironment
最简单的方式,就是直接调用 getExecutionEnvironment 方法。它会根据当前运行的上下文
直接得到正确的结果:如果程序是独立运行的,就返回一个本地执行环境。如果是创建了 jar
包,然后从命令行调用它并提交到集群执行,那么就返回集群的执行环境。
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
(2)createLocalEnvironment
这个方法返回一个本地执行环境,可以在调用时传入一个参数,指定默认的并行度。如果
不传入,则默认并行度就是本地的 CPU 核心数。
StreamExecutionEnvironment localEnv =
StreamExecutionEnvironment.createLocalEnvironment();
(3)createRemoteEnvironment
这个方法返回集群执行环境,需要在调用时指定 JobManager 的主机名和端口号,并指定
要在集群中运行的 Jar 包。
StreamExecutionEnvironment remoteEnv = StreamExecutionEnvironment
.createRemoteEnvironment(
"host", // JobManager 主机名
6666, // JobManager 进程端口号
"path/to/jarFile.jar" // 提交给 JobManager 的 JAR 包
);
执行模式(Execution Mode)
从 1.12.0 版本起, Flink 实现了 API 上的流批统一。 DataStream API 新增了一个重要特
性:可以支持不同的“执行模式”( execution mode ),通过简单的设置就可以让一段 Flink 程序
在流处理和批处理之间切换。这样一来, DataSet API 也就没有存在的必要了。
- 流执行模式(STREAMING)
- 批执行模式(BATCH)
- 自动模式(AUTOMATIC)
设置方式
(1)通过命令行配置
bin/flink run -Dexecution.runtime-mode=BATCH …
(2)通过代码配置
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.BATCH);
不建议在代码中配置,而是使用命令行。这同设置并行度是类似的:在提交作业时指定参数可以更加灵活,同一段应用程序写好之后,既可以用于批处理也可以用于流处理,而在代码中硬编码(hard code )的方式可扩展性比较差,一般都不推荐。
触发执行
Flink 是由事件驱动的,只有等到数据到来了才会触发真正的计算, 这也被称为“延迟执行”或“懒执行”(lazy execution ),所以我们需要显式地调用执行环境的 execute() 方法来触发程序执行。 execute() 方法将一直等待作业完成,然后返回一个执行结果(JobExecutionResult )。
源算子(Source)
读取数据的算子就是源算子
Flink 代码中通用的添加 source 的方式,是调用执行环境的 addSource() 方法
DataStream<String> stream = env.addSource(...);
该方法传入一个对象参数,需要实现 SourceFunction 接口。返回 DataStreamSource ,这里的DataStreamSource 类继承自SingleOutputStreamOperator 类,又进一步继承自 DataStream 。所以很明显,读取数据的 source 操作是一个算子,得到的是一个数据流( DataStream )。
POJO:一个简单的Java类,这个类没有实现/继承任何特殊的java接口或者类,不遵循任何主要java模型,约定或者框架的java对象。在理想情况下,POJO不应该有注解,方便数据的解析和序列化。
从 Kafka 读取数据
Kafka 和 Flink 天生一对,是当前处理流式数据的双子星。在如今的实时流处理应用中,由 Kafka 进行数据的收集和传输, Flink 进行分析计算,这样的架构已经成为众多企业的首选。
引入 Kafka 连接器的依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.12</artifactId>
<version>1.13.0</version>
</dependency>
然后调用 env.addSource() ,传入 FlinkKafkaConsumer 的对象实例
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "IP:9092");
properties.setProperty("group.id", "consumer-group");
properties.setProperty("key.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer");
properties.setProperty("value.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer");
properties.setProperty("auto.offset.reset", "latest");
DataStreamSource<String> stream = env.addSource(new FlinkKafkaConsumer<String>(
"clicks",
new SimpleStringSchema(),
properties
));
自定义 Source
创建一个自定义的数据源,实现 SourceFunction 接口。
主要重写两个关键方法: run()和 cancel() 。
- run()方法:使用运行时上下文对象(SourceContext)向下游发送数据;
- cancel()方法:通过标识位控制退出循环,来达到中断数据源的效果。
数据输出
输出到 Redis
Redis 是一个开源的内存式的数据存储,提供了像字符串( string )、哈希表( hash )、列表( list )、集合( set )、排序集合( sorted set )、位图( bitmap )、地理索引和流( stream )等一系 列常用的数据结构。因为它运行速度快、支持的数据类型丰富,在实际项目中已经成为了架构优化必不可少的一员,一般用作数据库、缓存,也可以作为消息代理。
输出到 Elasticsearch
ElasticSearch 是一个分布式的开源搜索和分析引擎,适用于所有类型的数据。ElasticSearch 有着简洁的 REST 风格的 API,以良好的分布式特性、速度和可扩展性而闻名,在大数据领域 应用非常广泛。
输出到 MySQL(JDBC)
尽管在大数据处理中直接与 MySQL 交互的场景不多,但最终处理的计算结果是要给外部应用消费使用的,而外部应用读取的数据存储往往就是 MySQL
六.Flink中的时间和窗口
Flink中的时间语义
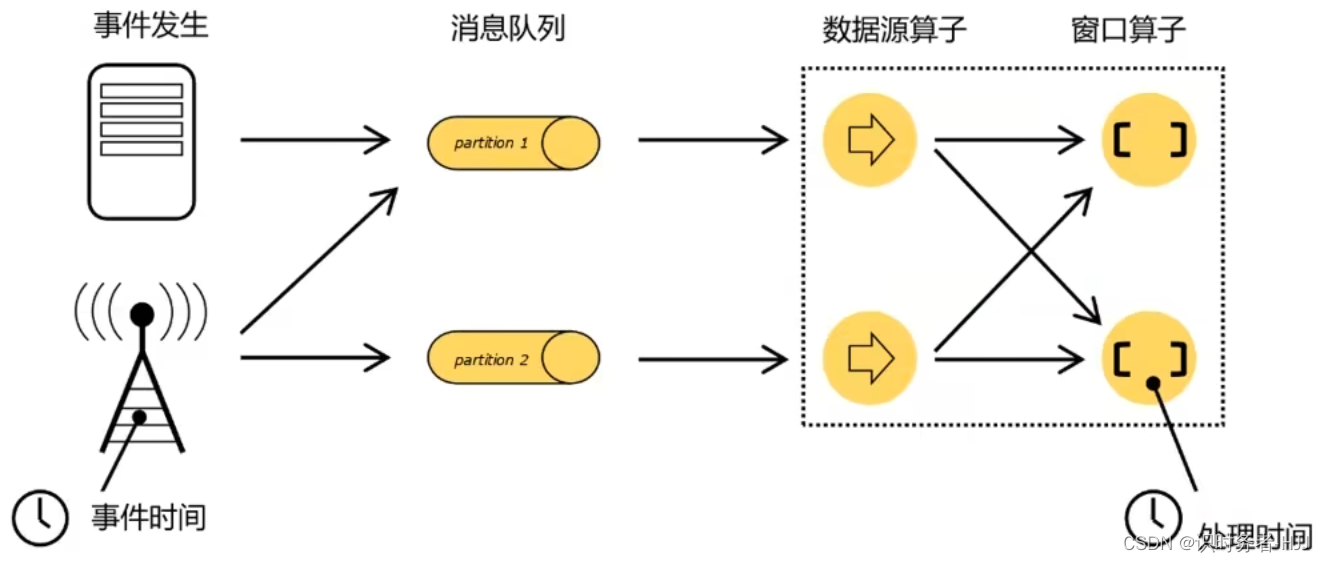
水位线(Watermark)
事件时间和窗口
 水位线,就是基于事件时间提出的概念。
水位线,就是基于事件时间提出的概念。
在事件时间语义下的窗口,其实是基于数据的时间戳,自定义了一个“逻辑时钟”。这个时钟的时间不会自动流逝。它的时间进展,就是靠着新到数据的时间戳来推动的。这样的好处在于,计算的过程可以完全不依赖处理时间(系统时间),不论什么时候进行统计处理,得到的结果都是正确的。
水位线的概念
在事件时间语义下,我们不依赖系统时间,而是基于数据自带的时间戳去定义了一个时钟, 用来表示当前时间的进展。于是每个并行子任务都会有一个自己的逻辑时钟,它的前进是靠数据的时间戳来驱动的。我们应该把时钟也以数据的形式传递出去,告诉下游任务当前时间的进展。而且这个时钟的传递不会因为窗口聚合之类的运算而停滞。在 Flink 中,这种用来衡量事件时间(Event Time )进展的标记,就被称作“水位线” 。水位线可以看作一条特殊的数据记录,它是插入到数据流中的一个标记点,主要内容就是一个时间戳,用来指示当前的事件时间。而它插入流中的位置,就应该是在某个数据到来之后;这样就可以从这个数据中提取时间戳,作为当前水位线的时间戳了。
水位线的特性
- 水位线是插入到数据流中的一个标记,可以认为是一个特殊的数据
- 水位线主要的内容是一个时间戳,用来表示当前事件时间的进展
- 水位线是基于数据的时间戳生成的
- 水位线的时间戳必须单调递增,以确保任务的事件时间时钟一直向前推进
- 水位线可以通过设置延迟,来保证正确处理乱序数据
- 一个水位线 Watermark(t),表示在当前流中事件时间已经达到了时间戳 t,这代表 t 之前的所有数据都到齐了,之后流中不会出现时间戳 t’ ≤ t 的数据
- 水位线是 Flink 流处理中保证结果正确性的核心机制,它往往会跟窗口一起配合,完成对乱序数据的正确处理。
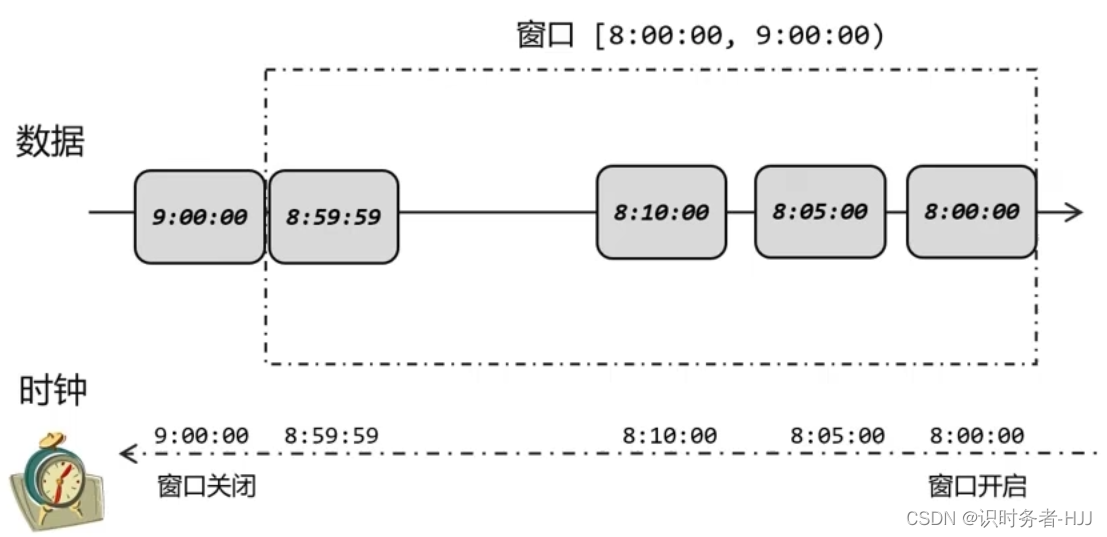
窗口的概念
在流处理中,我们往往需要面对的是连续不断、无休无止的无界流,不可能等到所有所有数据都到齐了才开始处理。更加高效的做法是,把无界流进行切分,每一段数据分别进行聚合,结果只输出一次。这就相当于将无界流的聚合转化为了有界数据集的聚合,这就是所谓的“ 窗口”(Window)聚合操作,窗口聚合其实是对实时性和处理效率的一个权衡。
在 Flink 中 窗口就是用来处理无界流的核心,我们很容易把窗口想象成一个固定位置的“框”,数据源源不断地流过来,到某个时间点窗口该关闭了,就停止收集数据、触发计算并输出结果。
我们为了正确处理迟到数据,结果把早到的数据划分到了错误的窗口——最终结果都是错误的。所以在 Flink 中, 窗口其实并不是一个“框”,流进来的数据被框住了就只能进这一个窗口。相比之下,我们应该 把窗口理解成一个“桶”。在 Flink 中,窗口可以把流切割成有限大小的多个“存储桶”(bucket)。每个数据都会分发到对应的桶中,当到达窗口结束时间时,就对每个桶中收集的数据进行计算处理。
Flink 中窗口并不是静态准备好的,而是动态创建——当有落在这个窗口区间范围的数据达到时,才创建对应的窗口。
窗口的分类
(1)按照驱动类型分类——时间窗口和计数窗口
按照时间段去截取数据,这种窗口就叫作“时间窗口”( TimeWindow)。
按照固定的个数,来截取一段数据集,这种窗口叫作“计数窗口”(Count Window)
Flink 中有一个专门的类来表示时间窗口,名称就叫作 TimeWindow。这个类只有两个私有属性:start 和 end,表示窗口的开始和结束的时间戳,单位为毫秒。
在 Flink 内部也并没有对应的类来表示计数窗口,底层是通过“全局窗口”(Global Window)来实现的。
2)按照窗口分配数据的规则分类
-
滚动窗口(Tumbling Windows)
滚动窗口有固定的大小,是一种对数据进行“均匀切片”的划分方式。窗口之间没有重叠,也不会有间隔,是“首尾相接”的状态。滚动窗口可以基于时间定义,也可以基于数据个数定义。需要的参数只有一个,就是窗口的大小(window size)。 -
滑动窗口(Sliding Windows)
与滚动窗口类似,滑动窗口的大小也是固定的。区别在于,窗口之间并不是首尾相接的,而是可以“错开”一定的位置。如果看作一个窗口的运动,那么就像是向前小步“滑动”一样。 定义滑动窗口的参数有两个:除去 窗口大小(window size)之外,还有一个“ 滑动步长”(window slide)。 滑动窗口可以基于时间定义,也可以基于数据个数定义。 -
会话窗口(Session Windows)
就是数据来了之后就开启一个会话窗口,如果接下来还有数据陆续到来,那么就一直保持会话。如果一段时间一直没收到数据,那就认为会话超时失效,窗口自动关闭。 会话窗口只能基于时间来定义,“会话”终止的标志就是“隔一段时间没有数据来”, 对于会话窗口而言,最重要的参数就是这段时间的长度(size ),它表示会话的超时时间,也就是两个会话窗口之间的最小距离。
在 Flink 底层,对会话窗口的处理会比较特殊:每来一个新的数据,都会创建一个新的会话窗口。然后判断已有窗口之间的距离,如果小于给定的 size ,就对它们进行合并( merge ) 操作。在 Window 算子中,对会话窗口会有单独的处理逻辑。 -
全局窗口(Global Windows)
这种窗口全局有效,会把相同 key 的所有数据都分配到同一个窗口中。说直白一点,就跟没分窗口一样。无界流的数据永无止尽,所以这种窗口也没有结束的时候,默认是不会做触发计算的。如果希望它能对数据进行计算处理,还需要自定义“触发器”(Trigger)。
全局窗口没有结束的时间点,所以一般在希望做更加灵活的窗口处理时自定义使用。Flink 中的计数窗口( Count Window ),底层就是用全局窗口实现的。
窗口的生命周期
(1) 窗口的创建
窗口的类型和基本信息由窗口分配器( window assigners )指定,但窗口不会预先创建好,而是由数据驱动创建。当第一个应该属于这个窗口的数据元素到达时,就会创建对应的窗口。
(2)窗口计算的触发
除了窗口分配器,每个窗口还会有自己的窗口函数( window functions )和触发器( trigger )。窗口函数可以分为增量聚合函数和全窗口函数,主要定义了窗口中计算的逻辑;而触发器则是指定调用窗口函数的条件。
(3)窗口的销毁
一般情况下,当时间达到了结束点,就会直接触发计算输出结果、进而清除状态销毁窗口。这时窗口的销毁可以认为和触发计算是同一时刻。这里需要注意,Flink 中只对时间窗口 有销毁机制。由于计数窗口是基于全局窗口实现的,而全局窗口不会清除状态,所以就不会被销毁。
迟到数据的处理
所谓的“迟到数据”( late data ),是指某个水位线之后到来的数据,它的时间戳其实是在水位线之前的。所以只有在事件时间语义下,讨论迟到数据的处理才是有意义的。
1、设置水位线延迟时间
水位线是事件时间的进展,它是我们整个应用的全局逻辑时钟。水位线生成之后,会随着数据在任务间流动,从而给每个任务指明当前的事件时间。
那一般情况就不应该把它的延迟设置得太大,否则流处理的实时性就会大大降低。因为水位线的延迟主要是用来对付分布式网络传输导致的数据乱序,而网络传输的乱序程度一般并不会很大,大多集中在几毫秒至几百毫秒。所以实际应用中,我们往往会给水位线设置一个“能够处理大多数乱序数据的小延迟”,视需求一般设在毫秒~ 秒级。
当我们设置了水位线延迟时间后,所有定时器就都会按照延迟后的水位线来触发。如果一个数据所包含的时间戳,小于当前的水位线,那么它就是所谓的“迟到数据”。
2、允许窗口处理迟到数据
水位线延迟设置的比较小,那之后如果仍有数据迟到该怎么办?对于窗口计算而言,如果水位线已经到了窗口结束时间,默认窗口就会关闭,那么之后再来的数据就要被丢弃了。
在水位线到达窗口结束时间时,先快速地输出一个近似正确的计算结果。然后保持窗口继续等到延迟数据,每来一条数据,窗口就会再次计算,并将更新后的结果输出。这样就可以逐步修正计算结果,最终得到准确的统计值了。
将水位线的延迟和窗口的允许延迟数据结合起来,最后的效果就是先快速实时地输出一个近似的结果,而后再不断调整,最终得到正确的计算结果。回想流处理的发展过程,这不就是著名的 Lambda 架构吗?原先需要两套独立的系统来同时保证实时性和结果的最终正确性,如今 Flink 一套系统就全部搞定了。
3、将迟到数据放入窗口侧输出流
即使我们有了前面的双重保证,可窗口不能一直等下去,最后总要真正关闭。窗口一旦关闭,后续的数据就都要被丢弃了。那如果真的还有漏网之鱼又该怎么办呢?
那就要用到最后一招了:用窗口的侧输出流来收集关窗以后的迟到数据。这种方式是最后“兜底”的方法,只能保证数据不丢失。因为窗口已经真正关闭,所以是无法基于之前窗口的结果直接做更新的。我们只能将之前的窗口计算结果保存下来,然后获取侧输出流中的迟到数据,判断数据所属的窗口,手动对结果进行合并更新。尽管有些烦琐,实时性也不够强,但能够保证最终结果一定是正确的。
所以总结起来, Flink 处理迟到数据,对于结果的正确性有三重保障:水位线的延迟,窗口允许迟到数据,以及将迟到数据放入窗口侧输出流。
七.处理函数(ProcessFunction)
处理函数的概念
在更底层,可以不定义任何具体的算子(比如 map, filter ,或者 window ),而只是提 炼出一个统一的“处理”(process )操作——它是所有转换算子的一个概括性的表达,可以自 定义处理逻辑,所以这一层接口就被叫作“处理函数”(process function )。
在处理函数中,我们直面的就是数据流中最基本的元素:数据事件(event )、状态( state )以及时间(time )。这就相当于对流有了完全的控制权。
但是无论那种算子,如果我们想要访问事件的时间戳,或者当前的水位线信息,都是完全做不到的。跟时间相关的操作,目前我们只会用窗口来处理。而在很多应用需求中,要求我们对时间有更精细的控制,需要能够获取水位线,甚至要“把控时间”、定义什么时候做什么事,这就不是基本的时间窗口能够实现的了。
处理函数提供了一个“ 定时服务” (TimerService),我们可以通过它访问流中的事件、时间戳、水位线 ,甚至可以注册“定时事件”。而且处理函数 继承了 AbstractRichFunction 抽象类, 所以拥有富函数类的所有特性,同样可以访问状态(state)和其他运行时信息。此外,处理函数还可以直接将数据输出到侧输出流(side output )中。所以, 处理函数是最为灵活的处理方法,可以实现各种自定义的业务逻辑。同时也是整个 DataStream API 的底层础。
处理函数的分类
对于不同类型的流,其实都可以直接调用 .process() 方法进行自定义处理,这时传入的参数就都叫作处理函数。Flink 提供了 8 个不同的处理函数:
(1)ProcessFunction
最基本的处理函数,基于 DataStream 直接调用 .process() 时作为参数传入。
(2)KeyedProcessFunction
对流按键分区后的处理函数,基于 KeyedStream 调用 .process() 时作为参数传入。要想使用定时器,比如基于 KeyedStream。KeyedProcessFunction 的一个特色,就是可以灵活地使用定时器。
Flink 的定时器同样具有容错性,它和状态一起都会被保存到一致性检查点( checkpoint )中。当发生故障时,Flink 会重启并读取检查点中的状态,恢复定时器。如果是处理时间的定时器,有可能会出现已经“过期”的情况,这时它们会在重启时被立刻触发。
(3)ProcessWindowFunction
开窗之后的处理函数,也是全窗口函数的代表。基于 WindowedStream 调用 .process()时作为参数传入。ProcessWindowFunction 既是处理函数又是全窗口函数。从名字上也可以推测出,它的本质似乎更倾向于“窗口函数”一些。ProcessWindowFunction 中除了 .process()方法外,并没有.onTimer()方法, 而是多出1个.clear() 方法。从名字就可以看出,这主要是方便我们进行窗口的清理工作。如果我们自定义了窗口状态,那么必须在.clear() 方法中进行显式地清除,避免内存溢出。
(4)ProcessAllWindowFunction
同样是开窗之后的处理函数,基于 AllWindowedStream 调用 .process() 时作为参数传入。
(5)CoProcessFunction
合并( connect )两条流之后的处理函数,基于 ConnectedStreams 调用 .process() 时作为参数传入。关于流的连接合并操作,我们会在后续章节详细介绍。
(6)ProcessJoinFunction
间隔连接( interval join )两条流之后的处理函数,基于 IntervalJoined 调用 .process() 时作为参数传入。
(7)BroadcastProcessFunction
广播连接流处理函数,基于 BroadcastConnectedStream 调用 .process()时作为参数传入。
(8)KeyedBroadcastProcessFunction
按键分区的广播连接流处理函数,同样是基于 BroadcastConnectedStream 调用 .process() 时作为参数传入。
八.Flink的多流转换
多流转换可以分为“分流”和“合流”两大类。目前分流的操作一般是通过侧输出流(side output)来实现,而合流的算子比较丰富,根据不同的需求可以调用 union 、connect、 join 以及 coGroup 等接口进行连接合并操作。
分流
所谓“分流”,就是将一条数据流拆分成完全独立的两条、甚至多条流。
在早期的版本中,DataStream API 中提供了一个 .split() 方法,专门用来将一条流“切分” 成多个。在 Flink 1.13 版本中,已经弃用了.split()方法,取而代之的是直接用处理函数(processfunction)的侧输出流(side output)。
1、简单实现
只要针对同一条流多次独立调用.filter() 方法进行筛选,就可以得到拆分之后的流了。
2、使用侧输出流
侧输出流则不受限制,可以任意自定义输出数据,它们就像从“主流”上分叉出的“支流”。尽管看起来主流和支流有所区别,不过实际上它们都是某种类型的 DataStream,所以本质上还是平等的。利用侧输出流就可以很方便地实现分流操作,而且得到的多条 DataStream 类型可以不同,这就给我们的应用带来了极大的便利。
合流
1、联合(Union)
最简单的合流操作,就是直接将多条流合在一起。联合操作要求必须 流中的数据类型必须相同,合并之后的新流会包括所有流中的元素,数据类型不变。对于合流之后的水位线,也是要 以最小的那个为准,这样才可以保证所有流都不会再传来之前的数据。(类似木桶效应)
2、连接(Connect)
连接得到的并不是 DataStream ,而是一个“连接流” 。连接流可以看成是两条流形式上的“统一”,被放在了一个同一个流中; 事实上内部仍保持各自的数据形式不变,彼此之间是相互独立的。要想得到新的 DataStream , 还需要进一步定义一个“同处理”(co-process )转换操作,用来说明对于不同来源、不同类型的数据,怎样分别进行处理转换、得到统一的输出类型。
两条流的连接( connect ),与联合( union )操作相比,最大的优势就是可以处理不同类型的流的合并,使用更灵活、应用更广泛。当然它也有限制,就是合并流的数量只能是 2 ,而 union 可以同时进行多条流的合并。
(1)CoProcessFunction
对于连接流 ConnectedStreams 的处理操作,需要分别定义对两条流的处理转换,因此接口中就会有两个相同的方法需要实现,用数字“ 1 ”“2”区分,在两条流中的数据到来时分别调用。我们把这种接口叫作“协同处理函数”(co-process function )。与 CoMapFunction 类似,如
果是调用 .flatMap() 就需要传入一个 CoFlatMapFunction ,需要实现 flatMap1() 、 flatMap2() 两个方法;而调用.process() 时,传入的则是一个 CoProcessFunction 。
(2)广播连接流(BroadcastConnectedStream)
关于两条流的连接,还有一种比较特殊的用法: DataStream 调用 .connect() 方法时,传入的参数也可以不是一个 DataStream ,而是一个“广播流”( BroadcastStream ),这时合并两条流得到的就变成了一个“广播连接流”(BroadcastConnectedStream )。这种连接方式往往用在需要动态定义某些规则或配置的场景。因为规则是实时变动的,所以我们可以用一个单独的流来获取规则数据;而这些规则或配置是对整个应用全局有效的,所以不能只把这数据传递给一个下游并行子任务处理,而是要“广播”( broadcast )给所有的并行子任务。而下游子任务收到广播出来的规则,会把它保存成一个状态,这就是所谓的“广播状态”( broadcast state )。
基于时间的合流——双流联结(Join)
对于两条流的合并,很多情况我们并不是简单地将所有数据放在一起,而是希望根据某个字段的值将它们联结起来,“配对”去做处理。
1、窗口联结(Window Join)
窗口联结在代码中的实现,首先需要调用 DataStream 的 .join() 方法来合并两条流,得到一个 JoinedStreams。接着通过 .where() 和 .equalTo() 方法指定两条流中联结的 key,然后通过 .window() 开窗口,并调用 .apply() 传入联结窗口函数进行处理计算。
处理流程:
两条流的数据到来之后,首先会按照 key 分组、进入对应的窗口中存储。当到达窗口结束时间时,算子会先统计出窗口内两条流的数据的所有组合,也就是对两条流中的数据做一个笛卡尔积(相当于表的交叉连接,cross join),然后进行遍历,把每一对匹配的数据,作为参数(first,second)传入 JoinFunction 的.join()方法进行计算处理,得到的结果直接输出。所以窗口中每有一对数据成功联结匹配,JoinFunction 的.join()方法就会被调用一次,并输出一个结果。
2、间隔联结(Interval Join)
间隔联结的思路就是针对一条流的每个数据,开辟出其时间戳前后的一段时间间隔,看这期间是否有来自另一条流的数据匹配。
间隔联结具体的定义方式是:我们给定两个时间点,分别叫作间隔的“上界”( upperBound )和“下界”( lowerBound )。于是对于一条流(不妨叫作 A )中的任意一个数据元素 a,就可以 开辟一段时间间隔:[a.timestamp + lowerBound, a.timestamp + upperBound]。我们就把这段时间作为可以匹配另一条流数据的“窗口”范围。所以对于另一条流(不妨叫 B)中的数据元素 b,如果它的时间戳落在了这个区间范围内,a 和 b 就可以成功配对,进而进行计算输出结果。
3、窗口同组联结(Window CoGroup)
它的用法跟 window join 非常类似,也是将两条流合并之后开窗处理匹配的元素,调用时只需要将.join()换为.coGroup()就可以了。
九.状态编程
按键分区状态(Keyed State)
1、值状态(ValueState)
定义一个用来保存定时器时间戳的值状态变量。当定时器触发并向下游发送数据以后,便清空储存定时器时间戳的状态变量,这样当新的数据到来时,发现并没有定时器存在,就可以注册新的定时器了, 注册完定时器之后将定时器的时间戳继续保存在状态变量中。
2.列表状态(ListState)
在 Flink SQL 中,支持两条流的全量 Join ,语法如下:SELECT * FROM A INNER JOIN B WHERE A.id = B.id ;这样一条 SQL 语句要慎用,因为 Flink 会将 A 流和 B 流的所有数据都保存下来,然后进行 Join 。不过在这里我们可以用列表状态变量来实现一下这个 SQL 语句的功能。
3.映射状态(MapState)
可以通过 MapState 的使用来探索一下窗口的底层实现,也就是我们要用映射状态来完整模拟窗口的功能。
4.聚合状态(AggregatingState)
对用户点击事件流每 5 个数据统计一次平均时间戳。这是一个类似计数窗口 求平均值的计算,这里我们可以使用一个有聚合状态的 RichFlatMapFunction 来实现。
算子状态(Operator State)
状态从本质上来说就是算子并行子任务实例上的一个特殊本地变量。它的特殊之处就在于 Flink 会提供完整的管理机制,来保证它的持久化保存,以便发生故障时进行状态恢复;另外还可以针对不同的 key 保存独立的状态实例。按键分区状态( Keyed State )对这两个功能都要考虑;而算子状态(Operator State )并不考虑 key 的影响,所以主要任务就是要让 Flink 了解状态的信息、将状态数据持久化后保存到外部存储空间。
并行度可能发生了调整,不论是按键(key )的哈希值分区,还是直接轮询(round-robin )分区,数据分配到的分区都会发生变化。这很好理解,当打牌的人数从 3 个增加到 4 个时,即使牌的次序不变,轮流发到每个人手里的牌也会不同。数据分区发生变化,带来的问题就是,怎么保证原先的状态跟故障恢复后数据的对应关系呢?
对于 Keyed State 这个问题很好解决:状态都是跟 key 相关的,而相同 key 的数据不管发往哪个分区,总是会全部进入一个分区的;于是只要将状态也按照 key 的哈希值计算出对应的分区,进行重组分配就可以了。恢复状态后继续处理数据,就总能按照 key 找到对应之前的状态,就保证了结果的一致性。所以 Flink 对 Keyed State 进行了非常完善的包装,我们不需实现任何接口就可以直接使用。
而对于 Operator State 来说就会有所不同。因为不存在 key ,所有数据发往哪个分区是不可预测的;也就是说,当发生故障重启之后,我们不能保证某个数据跟之前一样,进入到同一个并行子任务、访问同一个状态。所以 Flink 无法直接判断该怎样保存和恢复状态,而是提供了接口,让我们根据业务需求自行设计状态的快照保存(snapshot )和恢复( restore )逻辑。
CheckpointedFunction 接口
自定义的 SinkFunction 会在 CheckpointedFunction 中进行数据缓存,然后统一发送到下游。这个例子演示了列表状态的平均分割重组(event-split redistribution )。
广播状态(Broadcast State)
什么时候会用到这样的广播状态呢?一个最为普遍的应用,就是“动态配置”或者“动态规则”。我们在处理流数据时,有时会基于一些配置(configuration)或者规则( rule )。简单的配置当然可以直接读取配置文件,一次加载,永久有效;但数据流是连续不断的,如果这配置随着时间推移还会动态变化,那又该怎么办呢?
一个简单的想法是,定期扫描配置文件,发现改变就立即更新。但这样就需要另外启动一个扫描进程,如果扫描周期太长,配置更新不及时就会导致结果错误;如果扫描周期太短,又会耗费大量资源做无用功。解决的办法,还是流处理的“事件驱动”思路——我们可以将这动态的配置数据看作一条流,将这条流和本身要处理的数据流进行连接(connect ),就可以实时地更新配置进行计算了。
由于配置或者规则数据是全局有效的,我们需要把它广播给所有的并行子任务。而子任务需要把它作为一个算子状态保存起来,以保证故障恢复后处理结果是一致的。这时的状态,就是一个典型的广播状态。广播状态与其他算子状态的列表(list )结构不同,底层是以键值对(key-value )形式描述的,所以其实就是一个映射状态( MapState )。
在电商应用中,往往需要判断用户先后发生的行为的“组合模式”,比如“登录- 下单”或者“登录 - 支付”,检测出这些连续的行为进行统计,就可以了解平台的运用状况以及用户的行为习惯。
十.容错机制
容错性
流式计算分为有状态和无状态两种情况,所谓状态就是计算过程中的中间值。对于无状态计算,会独立观察每个独立事件,并根据最后一个事件输出结果。什么意思?举例:对于一个流式系统,接受到一系列的数字,当数字大于N则输出,这时候在此之前的数字的值、和等情况,压根不关心,只和最后这个大于N的数字相关,这就是无状态计算。什么是有状态计算了?想求过去一分钟内所有数字的和或者平均数等,这种需要保存中间结果的情况是有状态的计算。
当分布式计算系统中引入状态计算时,就无可避免一致性的问题。为什么呢?因为若是计算过程中出现故障,中间数据怎么办?若是不保存,那就只能重新从头计算了,不然怎么保证计算结果的正确性,这就是要求系统具有容错性了。
一致性
谈到容错性,就没法避免一致性这个概念。所谓一致性就是:成功处理故障并恢复之后得到的结果与没有发生任何故障是得到的结果相比,前者的正确性。就是故障的发生是否影响得到的结果。在流处理过程,一致性分为3个级别:
- at-most-once:至多一次。故障发生之后,计算结果可能丢失,就是无法保证结果的正确性
- at-least-once:至少一次。计算结果可能大于正确值,但绝不会小于正确值,就是计算程序发生故障后可能多算,但是绝不可能少算
- exactly-once:精确一次。系统保证发生故障后得到的计算结果的值和正确值一致
Flink的容错机制保证了exactly-once,也可以选择at-least-once。Flink的容错机制是通过对数据流不停的做快照(snapshot)实现的。针对FLink的容错机制需要注意的是:要完全保证exactly-once,Flink的数据源系统需要有“重放”功能。
检查点(Checkpoint)
Flink做快照的过程是基于“轻量级异步快照”的算法,其核心思想就是在计算过程中保存中间状态和在数据流中对应的位置。这些保存的信息(快照)就相当于是系统的检查点(checkpoint)(类似于window系统发生死机等问题时恢复系统到某个时间点的恢复点),做snapshot也是做一个checkpoint。在系统故障恢复时,系统会从最新的一个checkpoint开始重新计算,对应的数据源也会在对应的位置“重放“。这里的“重放”可能会导致数据的二次输出。
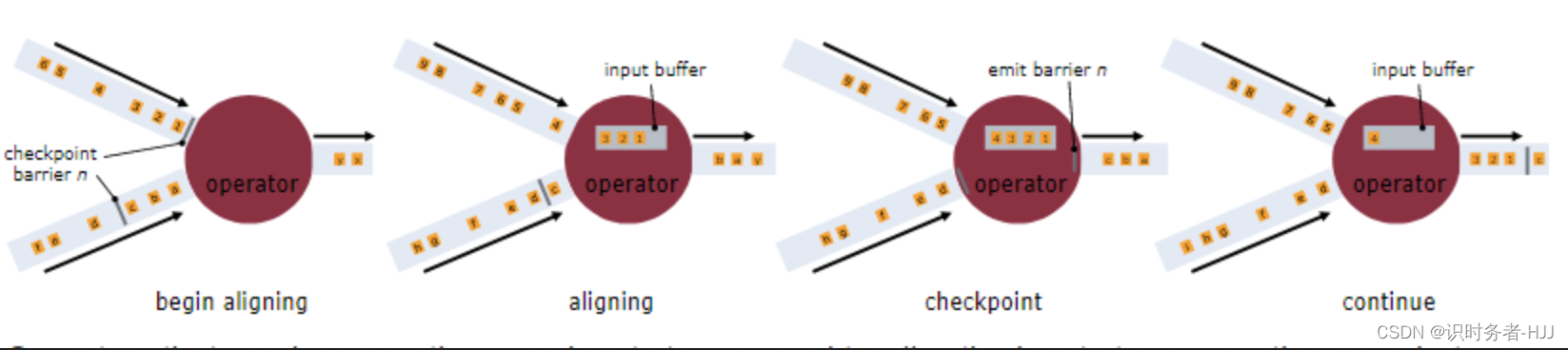
屏障(Barriers)
在Flink做分布式快照过程中核心一个元素Barriers的使用。这些Barriers是在数据接入到Flink之初就注入到数据流中,并随着数据流向每个算子(operator,这里所说的算子不是指类似map()等具体意义上个的,指在JobGraph中优化后的“顶点”),这里需要说明的有两点:
- 算子对Barriers是免疫的,即Barriers是不参与计算的
- Barriers和数据的相对位置是保持不变的,而且Barriers之间是线性递增的
如下图所示,Barriers将将数据流分成了一个个数据集。值得提醒的是,当barriers流经算子时,会触发与checkpoint相关的行为,保存的barriers的位置和状态(中间计算结果)。
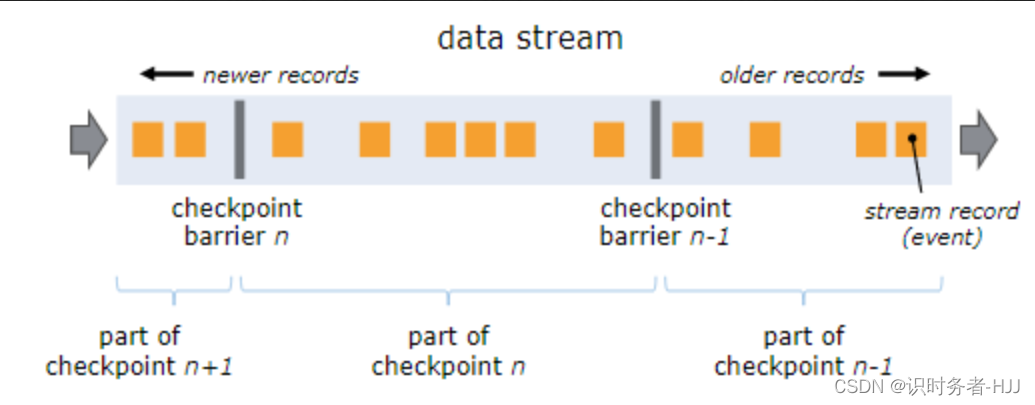 checkpoint是由JobManager中的CheckpointCoordinator周期性触发,然后在Task侧生成barrier,具体为:在Source task(TaskManager中)中barrier会根据命令周期性的在原始数据中注入barrier,而对非source task则是遇到barrier做checkpoint,即非source task其做checkpoint的时间间隔也许不是周期的,影响因素较多。此外,每个算子做checkpoint的方式也许不同。
checkpoint是由JobManager中的CheckpointCoordinator周期性触发,然后在Task侧生成barrier,具体为:在Source task(TaskManager中)中barrier会根据命令周期性的在原始数据中注入barrier,而对非source task则是遇到barrier做checkpoint,即非source task其做checkpoint的时间间隔也许不是周期的,影响因素较多。此外,每个算子做checkpoint的方式也许不同。
当一个算子有多个数据源时,又如何做checkpoint了?
如下图,从左往右一共4副图。当算子收到其中一个数据源的barriers,而未收到另一个数据源的barriers时(如左1图),会将先到barriers的数据源中的数据先缓冲起来,等待另一个barriers(如左2图),当收到两个barriers(如左3图)即接收到全部数据源的barrier时,会做checkpoint,保存barriers位置和状态,发射缓冲中的数据,释放一个对应的barriers。这里需要注意是,当缓存中数据没有被发射完时,是不会处理后续数据的,这样是为了保证数据的有序性。
 这里其实有一点需要注意的是,因为系统设置checkpoint的方式是通过时间间隔的形式(enableCheckpointing(intervalTime)),所以会导致一个问题:当一个checkpoint所需时间远大于两次checkpoint之间的时间间隔时,就很有可能会导致后续的checkpoint会失败,若是这样情况比较严重时会导致任务失败,这样Flink系统的容错性的优势就等不到保证了,所以需要合理设计checkpoint间隔时间。
这里其实有一点需要注意的是,因为系统设置checkpoint的方式是通过时间间隔的形式(enableCheckpointing(intervalTime)),所以会导致一个问题:当一个checkpoint所需时间远大于两次checkpoint之间的时间间隔时,就很有可能会导致后续的checkpoint会失败,若是这样情况比较严重时会导致任务失败,这样Flink系统的容错性的优势就等不到保证了,所以需要合理设计checkpoint间隔时间。
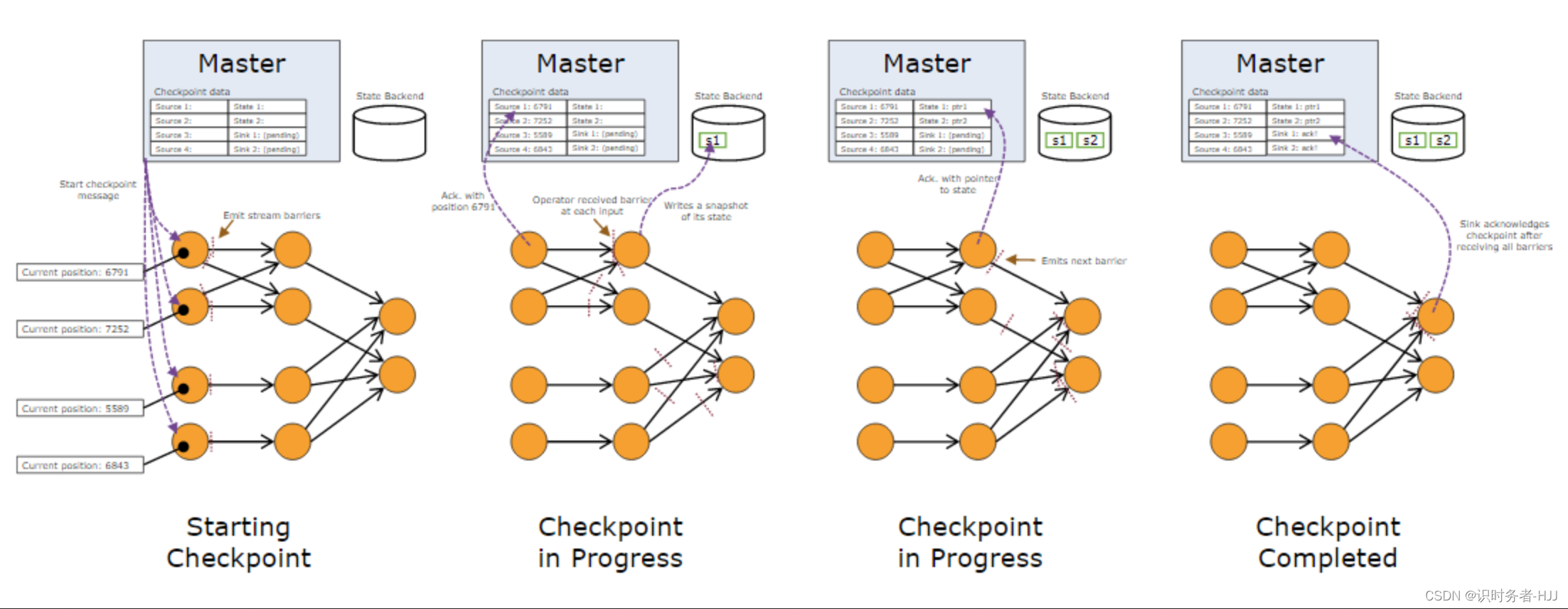
状态(State)
如下图所示,在一次snapshot中,算子会在接受到其数据源的所有barriers的以后snapshot它们的状态,然后在发射barriers到输出流中,直到最后所有的sink算子都完成snapshot才算完成一次snapshot。其中,在准备发射的barriers形成之前,state 形式是可以改变的,之后就不可以了。state的存贮方式是可以配置的,如HDFS,默认是在JobManager的内存中。
异步快照(asynchronous state snapshot)
上述描述中,需要等待算子接收到所有barriers后,开始做snapshot,存储对应的状态后,再进行下一次snapshot,其状态的存储是同步的,这样可能会造成因snapshot引起较大延时。可以让算子在存储快照时继续处理数据,让快照存储异步在后台运行。为此,算子必须能生成一个 state 对象,保证后续状态的修改不会改变这个 state 对象。例如 RocksDB 中使用的 copy-on-write(写时复制)类型的数据结构,即异步状态快照。对异步状态快照,其可以让算子接受到barriers后开始在后台异步拷贝其状态,而不必等待所有的barriers的到来。一旦后台的拷贝完成,将会通知JobManager。只有当所有的sink接收到这个barriers,和所有的有状态的算子都确认完成状态的备份时,一次snapshot才算完成。
十一.Table API 和 SQL
简单示例
public static void main(String[] args) throws Exception {
// 获取流执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 1. 读取数据源
SingleOutputStreamOperator<Event> eventStream = env
.fromElements(
new Event("Alice", "./home", 1000L),
new Event("Bob", "./cart", 1000L),
new Event("Alice", "./prod?id=1", 5 * 1000L),
new Event("Cary", "./home", 60 * 1000L),
new Event("Bob", "./prod?id=3", 90 * 1000L),
new Event("Alice", "./prod?id=7", 105 * 1000L)
);
// 2. 获取表环境
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// 3. 将数据流转换成表
Table eventTable = tableEnv.fromDataStream(eventStream);
// 4. 用执行SQL 的方式提取数据
Table resultTable1 = tableEnv.sqlQuery("select url, user from " + eventTable);
// 5. 基于Table直接转换
Table resultTable2 = eventTable.select($("user"), $("url"))
.where($("user").isEqual("Alice"));
// 6. 将表转换成数据流,打印输出
tableEnv.toDataStream(resultTable1).print("result1");
tableEnv.toDataStream(resultTable2).print("result2");
// 执行程序
env.execute();
}
程序架构
public static void main(String[] args) {
// 创建表环境
TableEnvironment tableEnv = ...;
// 创建输入表,连接外部系统读取数据
tableEnv.executeSql("CREATE TEMPORARY TABLE inputTable ... WITH ( 'connector'
= ... )");
// 注册一个表,连接到外部系统,用于输出
tableEnv.executeSql("CREATE TEMPORARY TABLE outputTable ... WITH ( 'connector'
= ... )");
// 执行 SQL 对表进行查询转换,得到一个新的表
Table table1 = tableEnv.sqlQuery("SELECT ... FROM inputTable... ");
// 使用 Table API 对表进行查询转换,得到一个新的表
Table table2 = tableEnv.from("inputTable").select(...);
// 将得到的结果写入输出表
TableResult tableResult = table1.executeInsert("outputTable");
}
分组聚合
// 1. 分组聚合
Table aggTable = tableEnv.sqlQuery("SELECT user_name, COUNT(1) FROM clickTable GROUP BY user_name");
// 2. 分组窗口聚合
Table groupWindowResultTable = tableEnv.sqlQuery("SELECT " +
"user_name, " +
"COUNT(1) AS cnt, " +
"TUMBLE_END(et, INTERVAL '10' SECOND) as endT " +
"FROM clickTable " +
"GROUP BY " + // 使用窗口和用户名进行分组
" user_name, " +
" TUMBLE(et, INTERVAL '10' SECOND)" // 定义1小时滚动窗口
);
窗口聚合
在 Flink 的 Table API 和 SQL 中,窗口的计算是通过“窗口聚合”( window aggregation )来实现的。与分组聚合类似,窗口聚合也需要调用 SUM() 、 MAX() 、 MIN() 、 COUNT() 一类的聚合函数,通过 GROUP BY 子句来指定分组的字段。只不过窗口聚合时,需要将窗口信息作
为分组 key 的一部分定义出来。1.13 版本开始使用了“窗口表值函数”(Windowing TVF),窗口本身返回的是就是一个表,所以窗口会出现在 FROM后面,GROUP BY 后面的则是窗口新增的字段 window_start 和 window_end。
// 3. 窗口聚合
// 3.1 滚动窗口
Table tumbleWindowResultTable = tableEnv.sqlQuery("SELECT user_name, COUNT(url) AS cnt, " +
" window_end AS endT " +
"FROM TABLE( " +
" TUMBLE( TABLE clickTable, DESCRIPTOR(et), INTERVAL '10' SECOND)" +
") " +
"GROUP BY user_name, window_start, window_end "
);
// 3.2 滑动窗口
Table hopWindowResultTable = tableEnv.sqlQuery("SELECT user_name, COUNT(url) AS cnt, " +
" window_end AS endT " +
"FROM TABLE( " +
" HOP( TABLE clickTable, DESCRIPTOR(et), INTERVAL '5' SECOND, INTERVAL '10' SECOND)" +
") " +
"GROUP BY user_name, window_start, window_end "
);
// 3.3 累积窗口
Table cumulateWindowResultTable = tableEnv.sqlQuery("SELECT user_name, COUNT(url) AS cnt, " +
" window_end AS endT " +
"FROM TABLE( " +
" CUMULATE( TABLE clickTable, DESCRIPTOR(et), INTERVAL '5' SECOND, INTERVAL '10' SECOND)" +
") " +
"GROUP BY user_name, window_start, window_end "
);
开窗(Over)聚合
// 4. 开窗聚合
Table overWindowResultTable = tableEnv.sqlQuery("SELECT user_name, " +
" avg(ts) OVER (" +
" PARTITION BY user_name " +
" ORDER BY et " +
" ROWS BETWEEN 3 PRECEDING AND CURRENT ROW" +
") AS avg_ts " +
"FROM clickTable");
SELECT user, ts,
COUNT(url) OVER (
PARTITION BY user
ORDER BY ts
RANGE BETWEEN INTERVAL '1' HOUR PRECEDING AND CURRENT ROW
) AS cnt
FROM EventTable
这里我们以 ts 作为时间属性字段,对 EventTable 中的每行数据都选取它之前 1 小时的所有数据进行聚合,统计每个用户访问 url 的总次数,并重命名为 cnt 。最终将表中每行的 user ,ts 以及扩展出 cnt 提取出来。
普通TopN
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// 1. 在创建表的DDL中直接定义时间属性
String createDDL = "CREATE TABLE clickTable (" +
" `user` STRING, " +
" url STRING, " +
" ts BIGINT, " +
" et AS TO_TIMESTAMP( FROM_UNIXTIME(ts / 1000) ), " +
" WATERMARK FOR et AS et - INTERVAL '1' SECOND " +
") WITH (" +
" 'connector' = 'filesystem', " +
" 'path' = 'input/clicks.csv', " +
" 'format' = 'csv' " +
")";
tableEnv.executeSql(createDDL);
// 普通Top N,选取当前所有用户中浏览量最大的2个
Table topNResultTable = tableEnv.sqlQuery("SELECT user, cnt, row_num " +
"FROM (" +
" SELECT *, ROW_NUMBER() OVER (" +
" ORDER BY cnt DESC" +
" ) AS row_num " +
" FROM (SELECT user, COUNT(url) AS cnt FROM clickTable GROUP BY user)" +
") WHERE row_num <= 2");
tableEnv.toChangelogStream(topNResultTable).print("top 2: ");
env.execute();
}
窗口TopN
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 读取数据源,并分配时间戳、生成水位线
SingleOutputStreamOperator<Event> eventStream = env
.fromElements(
new Event("Alice", "./home", 1000L),
new Event("Bob", "./cart", 1000L),
new Event("Alice", "./prod?id=1", 25 * 60 * 1000L),
new Event("Alice", "./prod?id=4", 55 * 60 * 1000L),
new Event("Bob", "./prod?id=5", 3600 * 1000L + 60 * 1000L),
new Event("Cary", "./home", 3600 * 1000L + 30 * 60 * 1000L),
new Event("Cary", "./prod?id=7", 3600 * 1000L + 59 * 60 * 1000L)
)
.assignTimestampsAndWatermarks(
WatermarkStrategy.<Event>forMonotonousTimestamps()
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event element, long recordTimestamp) {
return element.timestamp;
}
})
);
// 创建表环境
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// 将数据流转换成表,并指定时间属性
Table eventTable = tableEnv.fromDataStream(
eventStream,
$("user"),
$("url"),
$("timestamp").rowtime().as("ts")
// 将timestamp指定为事件时间,并命名为ts
);
// 为方便在SQL中引用,在环境中注册表EventTable
tableEnv.createTemporaryView("EventTable", eventTable);
// 定义子查询,进行窗口聚合,得到包含窗口信息、用户以及访问次数的结果表
String subQuery =
"SELECT window_start, window_end, user, COUNT(url) as cnt " +
"FROM TABLE ( " +
"TUMBLE( TABLE EventTable, DESCRIPTOR(ts), INTERVAL '1' HOUR )) " +
"GROUP BY window_start, window_end, user ";
// 定义Top N的外层查询
String topNQuery =
"SELECT * " +
"FROM (" +
"SELECT *, " +
"ROW_NUMBER() OVER ( " +
"PARTITION BY window_start, window_end " +
"ORDER BY cnt desc " +
") AS row_num " +
"FROM (" + subQuery + ")) " +
"WHERE row_num <= 2";
// 执行SQL得到结果表
Table result = tableEnv.sqlQuery(topNQuery);
tableEnv.toDataStream(result).print();
env.execute();
}
十二.Flink CEP
CEP 是什么?
1.复杂事件处理(Complex Event Processing,CEP)
2.Flink CEP是在Flink中实现的复杂事件处理(CEP)库
3.CEP允许在无休止的事件流中检测事件模式,让我们有机会掌握数据中重要的部分
4.一个或多个由简单事件构成的事件流通过一定的规则匹配,然后输出用户想得到的数据——满足规则的复杂事件
CEP的特点
1.目标:从有序的简单事件流中发现一些高阶特征
2.输入:一个或多个由简单事件构成的事件流
3.处理:识别简单事件之间的内在联系,多个符合一定规则的简单事件构成复杂事件
4.输出:满足规则的复杂事件
Pattern API
处理时间的规则,被叫做“模式”(Pattern)
Flink CEP提供了Pattern API,由于对输入流数据进行复杂事件规则定义,用来提取符合规则的事件序列
个体模式(Individual Patterns)——组成复杂规则的每一个单独的模式定义,就是“个体模式”
组合模式(Combining Patterns,也叫模式序列)
—— 很多个体模式组合起来,就形成了整个的模式序列
—— 模式序列必须以一个“初始模式”开始
模式组(Groups of patterns)—— 将一个模式序列作为条件嵌套在个体模式里,成为一组模式
个体模式(Individual Patterns)
个体模式可以包括“单例(singleton)模式”和“循环(looping)模式”
单例模式只接收一个事件,而循环模式可以接收多个
个体模式的条件
—— 每个模式都需要指定触发条件,作为模式是否接收事件进入的判断依据;
—— CEP中的个体模式主要通过调用.where() .or() 和 .until()来指定条件;
—— 按不同的调用方式,可以分成以下几类:
1)简单条件(Simple Condition)
—— 通过.where()方法对事件中的字段进行判断筛选,决定是否接受该事件
2)组合条件(Combining Condition)
—— 将简单条件进行合并; .or()方法表示或逻辑相连,where的直接组合就是AND
3)终止条件(Stop Condition)
—— 如果使用了oneOrMore 或者 oneOrMore.optional,建议使用.until()作为终止条件,以便清理状态;
4)迭代条件(Iterative Condition)
—— 能够对模式之前所有接收的事件进行处理;
—— 调用.where((value, ctx)=>{…}),可以调用ctx.getEventsForPattern(“name”)
模式序列
1)不同的“近邻”模式
2)严格近邻(Strict Contiguity)
—— 所有事件按照严格的顺序出现,中间没有任何不匹配的事件,由.next()指定
—— 例如对于模式“a next b”,事件序列[a,c,b1,b2]没有匹配
3)宽松近邻(Relaxed Contiguity)
—— 允许中间出现不匹配的事件,由.followedBy()指定
—— 例如对于模式“a followedBy b”,事件序列[a, c, b1, b2]匹配为{a, b1}
4)非确定性宽松近邻(Non-Deterministic Relaxed Contiguity)
—— 进一步放宽条件,之前已经匹配过的事件也可以再次使用,由.followedByAny()指定
—— 例如对于模式“a followedByAny b”,事件序列[a, c, b1, b2]匹配为{a, b1},{a, b2}
5)除以上模式序列外,还可以定义“不希望出现某种近邻关系”:
—— .notNext() —— 不想让某个事件严格紧邻前一个事件发生
—— .notFollowedBy() —— 不想让某个事件在两个事件之间发生
6)需要注意:
—— 所有模式序列必须以.begin()开始;
—— 模式序列不能以.notFollowedBy()结束;
—— “not”类型的模式不能被optional所修饰;
—— 此外,还可以为模式指定时间约束,用来要求在多长时间内匹配有效
模式的检测
1)指定要查找的模式序列后,就可以将其应用于输入流已检测潜在匹配
2)调用CEP.pattern(),给定输入流和模式,就能得到一个PatternStream
匹配事件的提取
1)创建PatternStream之后,就可以应用select或者flatselect方法,从检测到的事件序列中提取事件了
2)select()方法需要输入一个select function作为参数,每个成功匹配的事件序列都会调用它
3)select()以一个Map[String, Iterable[IN]]来接收匹配到的事件序列,其中key就是每个模式的名称,而value就是所有接收到的事件的Iterable类型
超时事件的提取
1)当一个模式通过within关键字定义了检测窗口时间时,部分事件序列可能因为超过窗口长度而被丢弃;为了能够处理这些超时的部分匹配,select和flatSelect API调用允许指定超时处理程序
2)超时处理程序会接收到目前为止由模式匹配到的所有事件,由一个OutputTag定义接收到的超时事件序列
CEP常用场景
Flink CEP能够利用的场景较多,在实际业务场景中也有了广泛的使用案例与经验积累。CEP常用与网络攻击检测、风控模型、信用卡欺诈等。
网络攻击检测
基于实时的数据流来进行网络攻击检测。例如常见的拖库行为产生的突发SQL扫描或网络带宽突增均能通过CEP来进行判定。
例如常见规则:当带宽突增、数据库资源用量突然变高时直接进行预警。
网络信贷
基于CEP构建的信用卡欺诈或当前的互联网贷款等。之前的贷款审批流程都是天级,当前的互联网贷款都是小时级甚至分钟级放款。而基于此基本都是通过CEP来实现用户的信用评分。例如实时导入用户的相关信息, 年龄,身份证号,芝麻信用分等等。规则或为: 年龄 < 65 ,有房产 ,无不良债务等
Flink 中文学习网:https://flink-learning.org.cn/
学习视频链接:https://www.bilibili.com/video/BV133411s7Sa
参考资料链接:https://blog.csdn.net/m0_65025800/category_11704269.html















 980
980











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











