







人物交互检测是视觉关系检测任务中非常重要的一类任务,对于场景的深入理解至关重要,现在很多方法将其分解为目标定位与交互识别,尽管取得了一定的进展,但是这些方法仅仅依赖于人和物体的外观而忽略掉有效的上下文信息,但是这些信息对于捕获他们之间的细微交互是非常重要的。本文提出了一个用于人物交互检测的上下文注意力框架,该方法通过学习实例的上下文感知外观特征来利用上下文信息,然后使用注意力模块自适应的选择与实例相关的上下文信息,以突出可能包含人物交互的图像区域。该方法在V-COCO上获得了4.4%的mAProle的提高,达到47.3%.
论文地址:https://arxiv.org/pdf/1910.07721v1.pdf
研究背景
近年来,以实例为中心的识别任务取得巨大的进展,如目标检测和分割,其在机器人,自动驾驶,监控等领域有着很多的应用,然而这些应用需要对超过实例级任务的场景语义具有更加深入的理解,例如对目标对之间的视觉关系的推理,HOI(human-object interactions detection,人物交互检测)是视觉关系检测的一种,当给出一张图片,其目标不仅仅是定位出人和物体,并且需要识别出他们之间的交互关系,可以归结为检测<人,动作,物体>三元组。由于该问题需要关注带有细粒度动作的以人为中心的交互(如骑马与喂马)还需要关注多个动作同时发生的情况(坐在椅子上一边吃东西一边玩电脑),因此具有很大的挑战性。
以前的方法主要是将其分为为两个部分:目标定位与交互识别。在第一阶段使用两阶段的目标检测器对图像中的人体和物体实例进行定位,第二阶段,在一个多流网络结构中分别检测人体实例和物体实例以及他们之间的两两交互。一些方法通过将结构信息,目光,姿势等线索整合在一起获得了一定的性能提升,但是比起像目标检测实例分割这些视觉任务,HOI检测的效果还远不如人意。
目前的HOI 检测方法趋向于关注人物实例的外观特征,这些特征对于人物交互的评分至关重要,以此来识别三元组。然而一些在不同的图像粒度上容易获得的有效的辅助信息(如上下文信息)却被忽略了。上下文信息对于一些计算机视觉任务的性能提高具有很重要的作用,然而对于HOI检测人物,其探索仍然相对不足。被检测区域周围的上下文消息可能会对标准边界框的外观特征提供补充信息,全局的上下文信息能够对确定某个特定目标种类的存在或缺失提供有价值的图像级的信息。如当检测驾船时,人,船,水可能都出现在图片中,当检测驾车时,仍然存在驾驶的动作,但是上下文信息(水)发生了改变。除了全局的上下文信息,每个人/物实例附近的信息对于区分不同的交互也提供了一些线索。比如包含同一物体的各种交互,吃苹果的动作周围应该是一个脸,切苹果的动作可能是手的一部分。在本文中,将上下文信息利用到HOI 检测中。
相关工作
目标检测:目标检测的发展主要依赖于CNN网络,基于CNN的目标检测器可以分为两阶段和单阶段的方法。两阶段的方法会先使用目标建议框生成器生成感兴趣区域,然后再进行目标分类和边界框回归。对于单阶段的方法直接使用anchors进行目标分类和边界框回归,其预测的是边界框的偏离而不是坐标。相比单阶段的方法两阶段的方法通常更加精确,在之前的方法中通常使用两阶段的FPN去检测人/物实例。
人物交互检测:InteractNet、GPNN、ICAN、HORNN
视觉中的上下文线索:在目标检测、图像分割中取得了较成功的应用,但是在HOI检测的任务仍需要进一步探索。

研究内容
1.对于人/物实例引入富含上下文信息的外观表示特征,全局上下文提供辅助信息的同时,也产生了背景噪声,会影响交互识别的性能,因此提出了一个注意力模块在保留相关的上下文信息的同时抑制背景噪声,并且能够根据特定的人/物实例突出交互的区域(如踢球与扔球)。产生的人/物注意图用于将全局特征调整为可能包含人物交互的突出图像区域。
2.本文在V-COCO,HICO-DET,HCVRD数据集上进行验证,并进行消融研究,结果显示了基于上下文信息的方法相较于没有的方法获得了很重要的改进。并且在每个数据集上都获得了很先进的表现,在HOI-DET其mAP相较于GPNN获得了9.4%的提高。
研究方法
- 整体框架

该网络由两个阶段组成:定位和交互预测
定位:采用FPN对图像中所有可能的人物实例产生边界框
交互预测:融合了人体流、物体流、成对流三个流的分数,将人体流与物体流的分数加起来再将结果与成对流的分数相乘。
多流管道:
输入:通过FPN得到的边界框以及原始图像
输出:检测到的<人,动作,物体>三元组
多流管道组成:人体流、物体流、成对流三个独立的流
人体流、物体流:基于外观,利用CNN特征提取器产生关于被检测人体和物体边界框的分数
成对流:对人与物之间空间关系进行编码
人/物流
标准的多流结构在人体流与物体流中,对以实例为中心(边界框)的外观特征进行编码,但是忽略了相关的上下文信息,我们认为仅仅依靠边界框的外观特征并不充分,人与物体实例附近的上下文信息提供了有助于区分复杂的人物交互的补充信息。因此本文采用以下方法:
(对于人体流和物体流采用的是同样的结构,唯一的区别就是输入分别是人物边界框与物体边界框)
- 引入了上下文感知的外观特征fapp,使用上下文信息丰富人体流和物体流。
- fapp然后被送入到上下文注意力模块,注意力模块用于调整全局特征图A来获得可以调整的特征表示Fm。
- Fm在注意力细化区进一步细化之后能够获得一个细化的调整之后的特征Fr。
- Fr传到全局平均池化层获得进一步调整之后的向量fr。
- 将fr与fapp连接起来生成对于动作的预测。

(1)Contextually-Aware Appearance Features(上下文感知外观特征)
给出一个图片的CNN特征,以及一个人/物边界框,通过ROI pooling后接一个残差块和全局平均池化层提取标准的人/物外观特征。
尽管理论上,图像的CNN特征在构建标准的外观表示时应该覆盖整个图像空间,并且它们的感受野实际上也小很多。这意味着在这种标准外观特征构建中,忽略了更大的全局场景上下文先验,因此上下文感知外观模块用于捕获额外的上下文信息,由上下文聚合和局部编码块组成。
-
上下文聚合块
捕获更大的视野(field-of-view,FOV) 用于聚合实例外观特征的上下文信息,并且保留空间信息,可以通过全连接层或级联扩张卷积来捕获更大的视野,但是前者会压缩空间维度,后者会生成稀疏特征,因此上下文聚合模块使用一个之前用于语义分割的大卷积核(LK),我们是第一个将基于LK的上下文聚合模块引入到HOI检测问题中构建的上下文外观特征。
输入:hwcin的图片的CNN特征(cin表示通道数,h,w表示图像的维度)
输出:h×w×cout的上下文丰富的特征,通过对原始的CNN特征应用一个kk的LK
在本文中,我们将KL进行分解,相比与原来的kk的卷积,就能降低计算复杂度与参数的数量O(2/k)。 -
局部编码块
目前的HOI检测方法都是进行标准的ROI warping,其需要对被裁剪的ROI 区域进行最大池化操作。局部编码模块就是通过对相关的空间位置的位置信息进行编码在每个边界框ROI区域保留局部感知信息,我们基于上下文聚合块得到上下文化的CNN特征图对每个ROI区域的局部感知信息进行编码,并且同时使用了max-pooling与PSRoIAlign,PSRoIAlign通过双线性插值来减少PSRoIpooling带来的粗量化影响。下图显示了在输入特征图上基于PSRoIAlign进行局部编码的影响,最后局部编码模块的输出被展平,并被送入到全连接层以获得上下文外观特征fapp。

(2)上下文注意力模块(contextual Attention)
由于context-aware appearance是基于外观和全局上下文信息进行编码,但是并不是所有的背景信息都对HOI检测有用,有的甚至会产生噪声,降低检测的性能。因此需要仔细识别出有用的上下文信息,以区分很难处理很微妙的人-物交互。对于给出的任务通常使用注意力机制突出非常重要的具有一定辨别力的特征。contextual Attention模块由自底向上的注意力以及注意力细化组件。
自底向上注意力组件
利用场景来关注相关特征,计算图像级的注意力需要生成基于注意力的边界框,自底向上的注意图使用对外观和背景进行编码的上下文感知特征fapp生成的。首先构建一个上下文注意图,然后将其用于调整输入CNN特征图。使用1×1的卷积将输入特征图f投影到512维空间(用A表示),然后计算被投影的全局特征A和上下文外观特征fapp之间的点乘来得到注意图,用于调节A。Fm表示被调整之后的特征
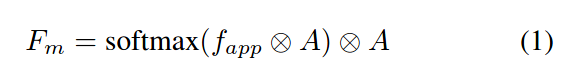
注意力细化模块
Fm的辨别能力进一步增强了注意力细化模块,它由空间和通道方面的注意力细化模块组成
-
空间细化模块
在Fm上使用一个1×1的卷积产生一个单通道的热图H,使用softmax进行规范化。再在规范后的热图H和Fm之间进行元素相乘,最终空间细化模块能够学到绝大多数相关的特征:
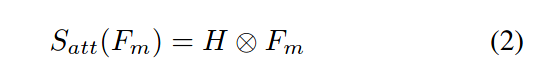
-
通道细化模块
受到(SENet)网络的启发,首先在Fm上使用全局平均池化将全局空间信息压缩到通道描述符z上,然后激发阶段是有两个全连接层组成的栈,对输入z使用一个sigmoid激活函数,过程如下所示:
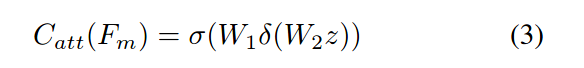
z表示压缩操作的输出,W1,W2表示全连接操作,δ和σ分别表示Relu和activation操作。最后Catt调节了Satt进一步突出人物交互的区域,以获得一个细化的调节的特征表示Fr:

最后,特征Fr通过全局平均池化传递得到一个细化的调节的向量fr,然后将fapp与fr结合起来产生最终的特征表示x,然后x通过两个全连接层,分别从人体/物体流中对动作进行估计。给出一个边界框,最终的预测结果是通过将人体流量/物体流/成对流结合起来产生的。
实验
在V-COCO数据集上使用mAProle作为评估度量,在HOI-DET中使用mAP进行评估,HCVRD上报告的是50和100次召回中top-1和top-3的结果。
实验细节
使用ResrNet-50-FPN部署Detectron,获得预测的人物边界框,在训练师,选择分数高于0.8的人物边界框,和分数高于0.4的物体边界框,对于交互预测,使用在ImageNet上预训练的ResNet-50作为特征提取主干,初始学习率设置为0.001,权重衰减为0.0001,动量为0.9。
实验结果(V-COCO)
评估上下文感知外观模块与上下文注意力模块对实验结果的影响(加入之后性能提高了2.8%mAProle)

评估上下文信息对于提高多流网络结构的分类能力,通过设置不同的IOU阈值

使用不同的主干对于网络性能的提升

和先进的方法比较

比较使用此方法与iCAN获得的注意图

下图显示了单个人物交互与多个人共同与一个物体进行交互

在HICO-DET上比较不同方法的性能

结论
本文提出了一个HOI 检测的深度上下文注意力网络,通过学习人/物的上下文感知的外观特征,为了消除背景噪声,模型能够自动的选择对于人物交互相关的很重要的上下文信息,在v-COCO上性能达到47.3%。该方法结合和人/物的外观特征和空间信息,相较于之前的方法,利用了上下文信息,使得性能有了一定的提升














 1309
1309











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









