







目录
算法
算法(Algorithm)是指解题方案的准确而完整的描述,是一系列解决问题的清晰指令,代表着用系统的方法描述解决问题的策略机制。它能对一定规范的输入,在有限时间内获得所要求的输出。算法的优劣可以用空间复杂度与时间复杂度来衡量。
各个领域其对应的算法应用场景:
- 金融领域:算法在风险评估、投资组合优化、交易策略以及反欺诈等方面有广泛应用。例如,机器学习算法可以通过分析大量数据来进行风险评估和信用评分,帮助金融机构做出更准确的决策。
- 医疗领域:算法在疾病诊断、药物研发、患者健康管理等方面发挥重要作用。例如,机器学习算法可以通过分析医疗图像和患者数据来进行疾病诊断和预测,辅助医生制定治疗方案。
- 交通领域:算法用于交通流量优化、路径规划、交通信号控制等。交通流量预测算法通过分析历史数据和实时数据,帮助交通管理部门预测交通拥堵情况,制定交通调度策略。
- 电子商务领域:算法用于个性化推荐、广告投放、价格优化等,提升用户体验和购物效率。
- 数学领域:上学时候所学的勾股定理,三角函数,等腰等边三角形等等都是属于算法一种体现。以及我们的加减乘除运算法则。
算法的优点主要包括:
- 高效性:算法能够自动执行复杂的计算任务,提高了解决问题的效率。
- 准确性:算法通过精确的计算和推理,能够提供准确的结果。
- 通用性:算法可以应用于各种领域和问题,具有广泛的适用性。
算法也存在一些缺点:
(这些算吗)
- 偏见和歧视:如果算法所训练的数据包含偏见或反映现有的不平等,算法可能会延续并放大这些偏见,导致歧视性结果。
- 缺乏透明度:一些算法作为黑箱运行,用户难以理解其决策过程,可能导致不信任和隐私担忧。
- 工作替代风险:算法的自动化可能导致某些职业被替代,引发就业和经济问题。
空间复杂度和时间复杂度是衡量算法性能的两个重要指标。
空间复杂度
空间复杂度是指执行一个算法所需要的内存空间。它主要关注算法在运行过程中临时占用存储空间的大小。一个算法的空间复杂度越低,意味着它所需的额外空间越小,对内存的使用越高效。
时间复杂度
时间复杂度是指执行算法所需要的计算工作量,它主要描述算法运行时间随输入规模增长而变化的趋势。时间复杂度越低,算法执行速度越快,效率越高。
在评判一个算法的优劣时,通常会综合考虑空间复杂度和时间复杂度。一个优秀的算法应该既能在合理的时间内完成计算,又能有效地控制内存使用。例如,当我们面对一个排序问题时,可以使用多种不同的算法,如冒泡排序、插入排序、快速排序等。这些算法的空间复杂度和时间复杂度各不相同。
以冒泡排序为例,其空间复杂度为O(1),表示它只需要常量级别的额外空间。然而,其时间复杂度为O(n^2),表示随着输入规模的增加,算法的执行时间会急剧上升。这意味着冒泡排序在处理大规模数据时可能会非常低效。
相比之下,快速排序算法的空间复杂度为O(logn)至O(n),而平均时间复杂度为O(nlogn)。在多数情况下,快速排序的性能优于冒泡排序,因为它在保持较低空间复杂度的同时,显著降低了时间复杂度。
图片来源于网络,侵权可联系删除

在算法分析中,O(n), O(n^2), O(logn), O(nlogn) 等是表示算法复杂度的大O表示法(Big O notation)。它描述了算法执行时间或所需空间随输入规模n增长的趋势。
- O(n):表示算法的执行时间或空间与输入规模n成正比。
- O(n^2):表示算法的执行时间或空间与输入规模的平方成正比。
- O(logn):表示算法的执行时间或空间与输入规模n的对数成正比。
- O(nlogn):表示算法的执行时间或空间与输入规模n和n的对数的乘积成正比。
举例分析复杂度(快速排序)
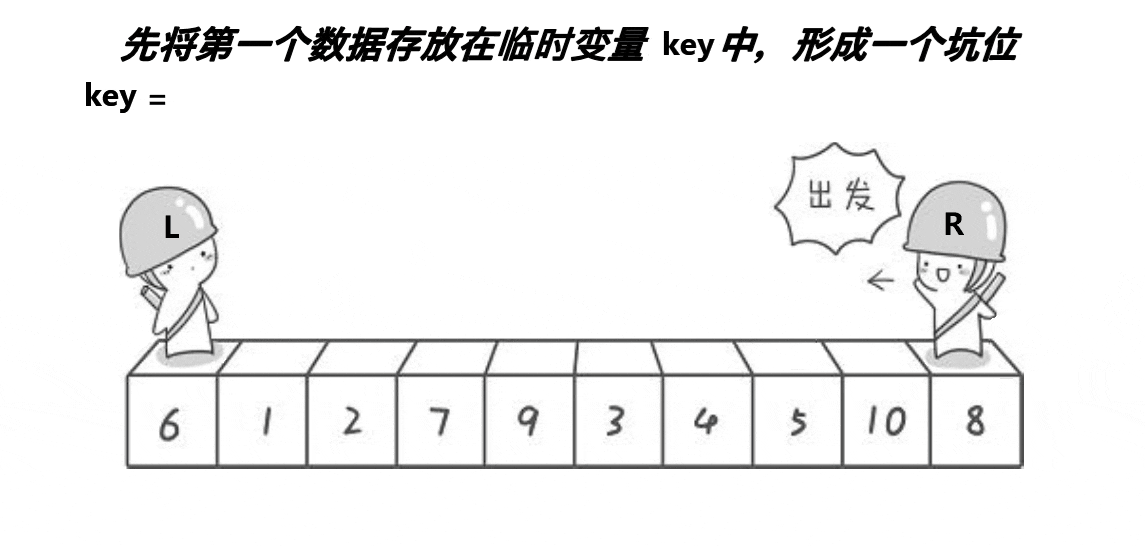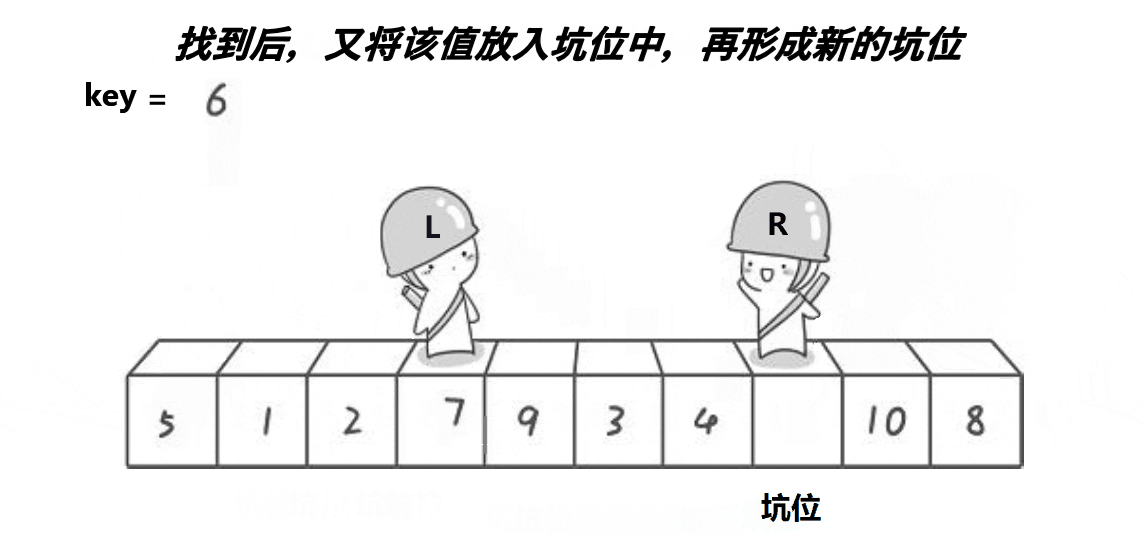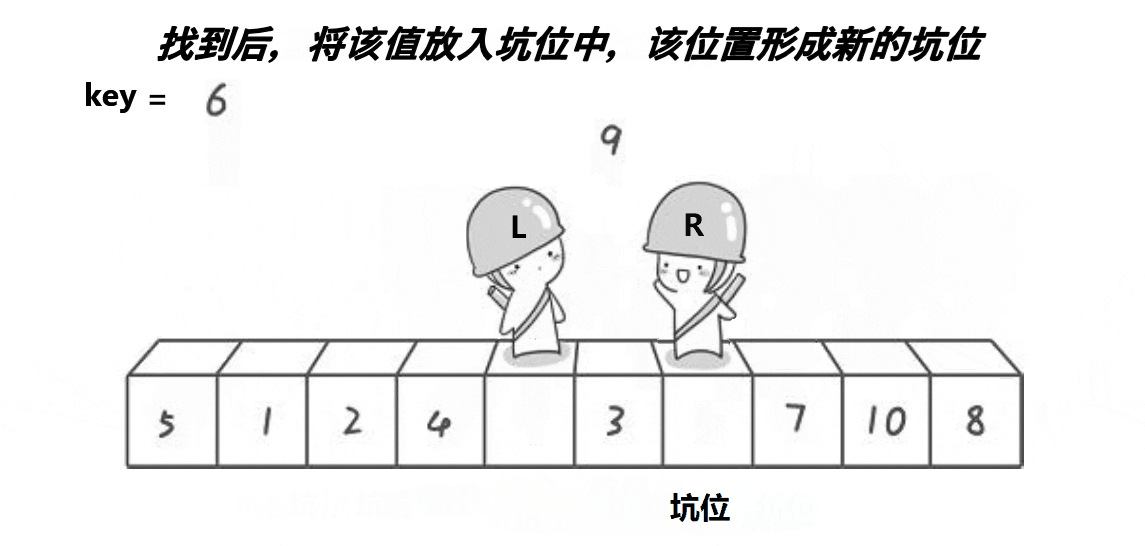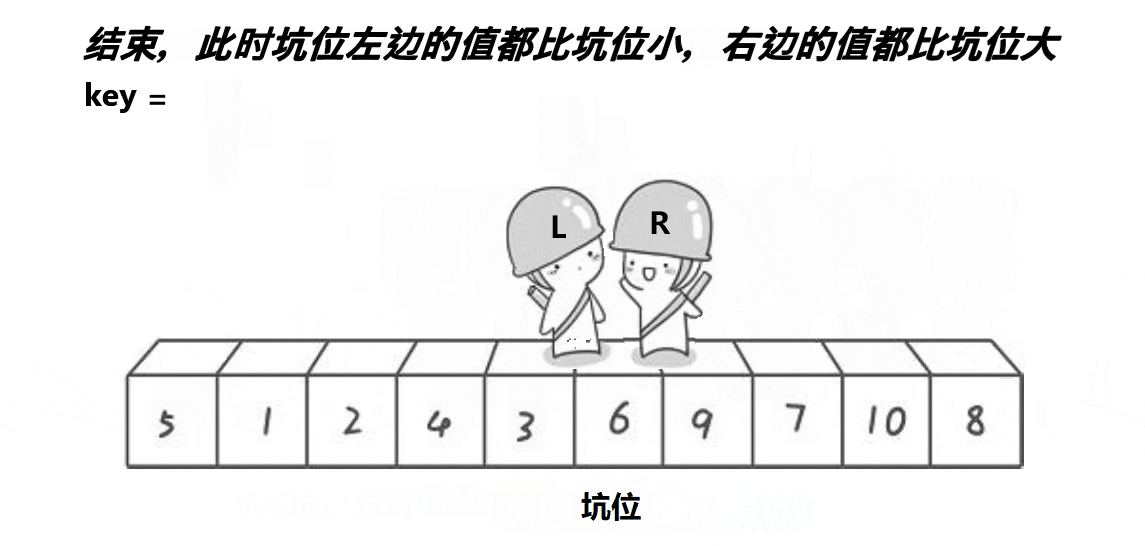
开始之前先了解一下挖坑法
挖坑法
挖坑法是一种在快速排序算法中使用的技术,用于优化排序过程。在快速排序中,选择一个基准元素,然后将数组分为两部分,使得一部分的元素都小于基准,另一部分的元素都大于基准。挖坑法是对这个过程的一种具体实现。
1、首先选择一个基准元素(通常选择第一个元素、最后一个元素或随机选择一个元素),并将其视为“坑”或“洞”
2、遍历数组的其他元素,将比基准小的元素移动到基准的左边,比基准大的元素移动到基准的右边
当遍历到某个元素时,如果它比基准小,我们就将其放到基准原来的位置(即“坑”的位置),然后更新“坑”的位置为该元素原来的位置,继续遍历。这样,每次遍历到一个新元素时,我们都在寻找一个合适的位置来放置它,就像是在“挖坑”并填充一样。
这种方法的优势在于,它允许我们在原地进行排序,不需要额外的存储空间。同时,通过合理地选择基准元素和使用一些优化策略(如随机化选择基准或使用“三数取中”法),可以有效地避免最坏情况的发生,提高排序的效率。
图片来源于网络,侵权可联系删除
快速排序
public class QuickSort {
/**
* 快速排序主方法,用于对数组进行排序
*
* @param arr 要排序的数组
* @param low 数组的最低索引
* @param high 数组的最高索引
*/
public static void quickSort(int[] arr, int low, int high) {
if (low < high) {
// 选择一个基准元素,并重新排列数组,使得比基准小的元素在左边,比基准大的元素在右边
int pivotIndex = partition(arr, low, high);
// 递归地对基准左边的子数组进行快速排序
quickSort(arr, low, pivotIndex - 1);
// 递归地对基准右边的子数组进行快速排序
quickSort(arr, pivotIndex + 1, high);
}
}
/**
* 划分操作,将数组分为两部分,一部分元素比基准小,另一部分元素比基准大
*
* @param arr 要划分的数组
* @param low 数组的最低索引
* @param high 数组的最高索引
* @return 基准元素在排序后数组中的索引位置
*/
private static int partition(int[] arr, int low, int high) {
// 选择最右边的元素作为基准
int pivot = arr[high];
int i = low - 1; // 指向小于基准的元素的最后一位
// 遍历数组,将小于基准的元素移动到左边,大于基准的元素保持不动
for (int j = low; j < high; j++) {
if (arr[j] <= pivot) {
i++;
// 交换arr[i]和arr[j]
swap(arr, i, j);
}
}
// 将基准元素放到最终位置
swap(arr, i + 1, high);
return i + 1; // 返回基准元素的索引位置
}
/**
* 交换数组中两个元素的位置
*
* @param arr 要交换元素的数组
* @param i 第一个元素的索引
* @param j 第二个元素的索引
*/
private static void swap(int[] arr, int i, int j) {
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
/**
* 测试QuickSort算法
*
* @param args 命令行参数
*/
public static void main(String[] args) {
int[] arr = {10, 7, 8, 9, 1, 5};
quickSort(arr, 0, arr.length - 1);
// 输出排序后的数组
for (int i : arr) {
System.out.print(i + " ");
}
}
}图片来源于网络,侵权可联系删除
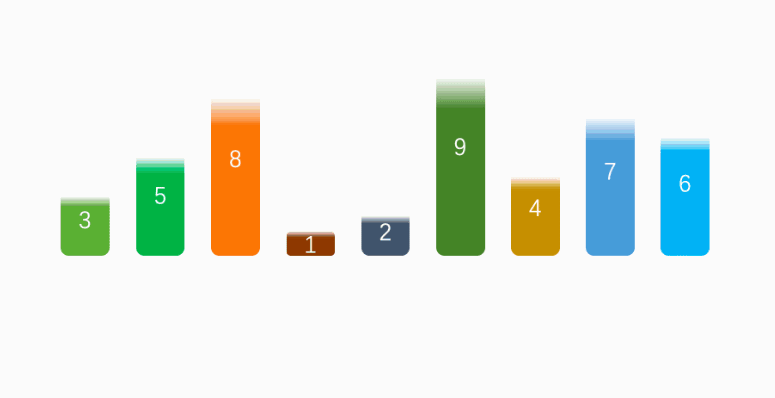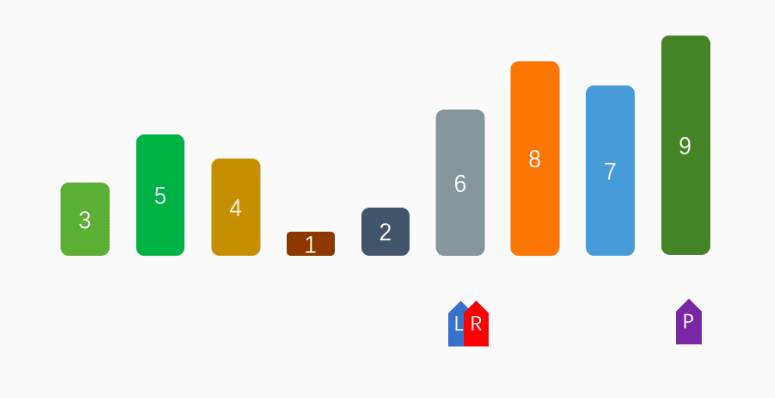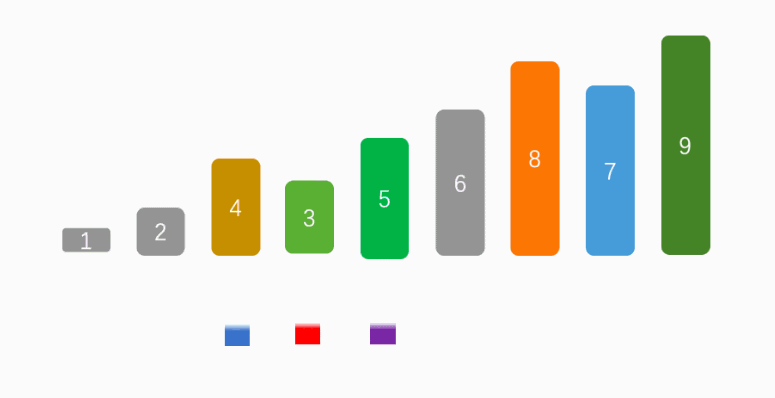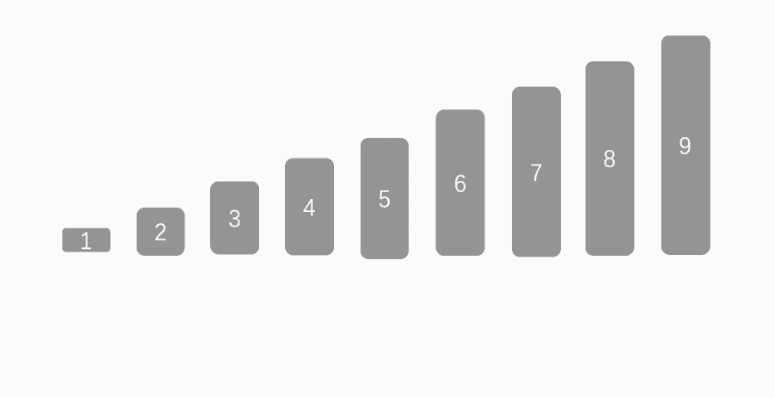
实现理念:
快速排序是一种高效的排序算法,它的实现基于分而治之(Divide and Conquer)的策略,实现理念如下:
-
选择一个基准(Pivot):
快速排序选择一个元素作为基准,通常选择第一个元素、最后一个元素或随机选择一个元素。这个基准在排序过程中起到参照点的作用。 -
划分操作(Partition):
通过一趟排序,将待排序的数据分割成独立的两部分,其中一部分的所有数据都比另一部分的所有数据都要小。这个操作是通过比较每个元素与基准的大小,将比基准小的元素放在基准的左边,比基准大的元素放在基准的右边来完成的。 -
递归排序:
递归地对基准左边和右边的两个子数组进行快速排序。由于这两个子数组是独立且互不重叠的,因此可以对它们分别进行排序。 -
合并结果:
因为快速排序是原地排序算法(in-place),它不需要额外的数组来存储结果。当递归调用返回时,数组已经按升序或降序排列好了。
快速排序的关键在于“分而治之”的思想,即将一个大问题划分为几个小问题,然后分别解决这些小问题,最后将小问题的解合并成原问题的解。这种思想使得快速排序在处理大数据集时具有出色的性能。
快速排序的平均时间复杂度为O(nlogn),其中n是待排序元素的数量。
时间复杂度分析:
- 最优情况(Best Case):
- 当每次划分操作都能将数组几乎均匀地分成两个子数组时,快速排序的性能最好。这种情况下,算法会形成一棵平衡的二叉树,其深度为O(logn)。因此,最优情况下快速排序的时间复杂度为O(nlogn)。
- 平均情况(Average Case):
- 在平均情况下,即输入数据的分布是随机的,快速排序的性能仍然相当好。尽管算法形成的二叉树可能不是完全平衡的,但树的高度仍然保持在O(logn)范围内。因此,平均情况下的时间复杂度也是O(nlogn)。
- 最坏情况(Worst Case):
- 最坏情况发生在输入数组已经部分或完全有序时。在这种情况下,划分操作可能会产生不平衡的子数组,其中一个子数组的大小可能接近于0,而另一个子数组的大小接近于n-1。这会导致递归树的高度达到n,算法退化为类似于冒泡排序的性能。因此,最坏情况下的时间复杂度为O(n^2)。
空间复杂度分析:
- 快速排序的空间复杂度主要取决于递归调用栈的深度。在最优和平均情况下,递归树的高度为O(logn),因此空间复杂度为O(logn)。但在最坏情况下,递归树高度为O(n),空间复杂度为O(n)。
然而,需要注意的是,快速排序的空间复杂度并不包括存储输入数组本身的空间,因为这部分空间与算法本身的实现无关。在实际应用中,我们通常更关心算法执行所需的额外空间。
由于使用了递归,快速排序的空间复杂度在最坏情况下是O(n),当递归栈的深度达到n时。在平均情况下,空间复杂度较低,但仍然取决于递归的深度。需要注意的是,这里的空间复杂度不包括存储输入数组本身的空间。















 1155
1155











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











