




ShadowRefiner: Towards Mask-free Shadow Removal via Fast Fourier Transformer
摘要
受阴影影响的图像通常在颜色和光照方面存在明显的空间差异,这会降低包括目标检测和分割系统在内的各种视觉应用的性能。为了在保留复杂细节并产生视觉效果出色的结果的同时,有效去除真实世界图像中的阴影,我们通过快速傅里叶变换器引入了一种无掩码的阴影去除和细化网络(ShadowRefiner)。具体来说,我们方法中的阴影去除模块旨在通过空间和频率表示学习,在受阴影影响的图像和无阴影图像之间建立有效的映射。为了减轻像素错位并进一步提高图像质量,我们提出了一种新颖的基于快速傅里叶注意力的变换器(FFAT)架构,其中设计了一种创新的注意力机制来进行细致的细化。我们的方法在NTIRE 2024图像阴影去除挑战赛的感知赛道中获得冠军,在保真度赛道中获得第二名。此外,全面的实验结果也证明了我们所提方法的显著有效性。代码可在https://github.com/movingforward100/Shadow_R上公开获取。

1. 引言
受阴影影响的图像通常出现在光源部分或完全被遮挡的场景中,这会导致颜色的空间变化和光照失真。阴影去除的目标是提高阴影区域的可见性,实现阴影和非阴影区域的光照一致性,同时保留自然细节的完整性。这种增强对于提高众多下游应用的性能至关重要,如目标检测、跟踪和分割系统[7, 15, 34, 44]。
许多针对图像阴影去除提出的传统方法,主要是围绕基于物理的光照模型设计的[12, 17]。尽管这些方法有理论基础,但它们在去除真实世界中受阴影影响图像的阴影时,通常效果有限。这一局限性主要源于难以在阴影区域和无瑕疵区域之间建立准确的物理关联,使得这些传统技术在实际场景中效果不佳。
最近,基于学习的方法已成为阴影去除领域的主流,利用了深度学习框架强大的建模能力[23, 24, 41, 46]。这些方法可根据是否依赖阴影掩码作为指导,分为基于掩码和无掩码的阴影去除策略。与无掩码方法相比,基于掩码的阴影去除策略不仅使用受阴影影响和无阴影的图像对,还将基准数据集提供的或通过预训练的掩码预测模型生成的阴影区域位置信息,作为学习指导。精确的阴影位置信息的引入,使这些模型能够专注于揭示阴影区域和其干净对应区域之间的复杂映射,从而在阴影去除方面取得出色的性能。
然而,对掩码信息的依赖给基于掩码的方法带来了严峻挑战。首先,获取精确的阴影掩码非常困难[27]。公共数据集中提供的准确阴影掩码,通常是在简单场景下获得的,比如一个人站在开阔的广场上。相比之下,对于复杂场景,如WSRD和WSRD+数据集[36],用合适的掩码标注图像或使用预训练模型预测准确的掩码并不可行。其次,精确阴影掩码的缺失会显著降低基于掩码模型的性能,严重阻碍其在复杂真实世界数据中的应用。
无掩码阴影去除方法的最新进展,通常利用生成策略[48]来学习受阴影影响和无阴影图像之间的映射。然而,在阴影去除研究领域,频域分析的应用在很大程度上仍未得到充分探索。值得注意的是,一些结合空间和频率表示的创新工作,在更广泛的图像恢复领域,如去雾和低光照图像增强任务中,已经显示出有前景的结果[19, 51],这为阴影去除的未来探索指明了一个潜在方向。
在本文中,我们引入了一种新颖的无掩码模型,该模型结合了空间和频域表示来进行图像阴影去除。如图1所示,该模型在NTIRE 2024图像阴影去除挑战赛中取得了出色的性能。具体来说,我们提出了一种名为ShadowRefiner的阴影去除和细化架构,它包含两个特定模块:阴影去除模块和细化模块。在阴影去除模块中,我们设计了一个以ConvNext[28]块为骨干的阴影去除U-Net[32]分支。此外,我们的阴影去除模块还利用了一个类似于[51]的频率分支,该分支配备了高频、低频表示和大感受野。然而,初步实验结果表明,阴影去除模块的输出与真实情况之间存在明显的像素错位,表现为细节明显恶化和颜色一致性受损。为此,我们引入了一种基于快速傅里叶注意力的变换器(FFAT)作为细化模块,其创新的注意力机制显著增强了模型去除阴影的能力,同时产生的结果既具有高保真度又在视觉上吸引人。
我们的贡献主要有三个方面:
- 我们引入了一种创新的无掩码阴影去除方法,该方法首先通过空间和频率表示学习清除阴影,然后通过我们提出的基于频率注意力的变换器架构进一步细化。
- 为了减轻像素错位,我们引入了一个具有新颖频率注意力机制的快速傅里叶变换器网络,在恢复纹理细节和保持颜色一致性方面实现了卓越的性能。
- 我们在多个阴影去除基准测试中进行了广泛的实验,并且在NTIRE 2024图像阴影去除挑战赛中取得了极具竞争力的成绩(在感知赛道中排名第一,在保真度赛道中排名第二),这突出了我们提出的ShadowRefiner模型的卓越性能。
2. 相关工作
基于掩码的图像阴影去除
基于掩码的方法可分为两种主要类型:基于特征的方法和基于深度学习的方法。基于特征的方法依赖于颜色恒常性[50]、纹理分析和边缘检测[2, 43]等技术。Gryka等人[14]首次引入了一种基于学习的方法,使用监督回归算法自动去除本影和半影阴影。Wang等人[40]提出了ST-CGAN,这是一个端到端的框架,使用两个堆叠的条件生成对抗网络(CGAN)集成了阴影检测和去除功能。Bao等人[3]提出了S2Net,该方法强调语义指导和细化以保证图像完整性。这种方法使用阴影掩码来指导阴影去除,通过语义引导块将数据从非阴影区域转移到阴影区域,有效地消除阴影的同时保留干净区域。He等人[18]设计了Mask-ShadowNet,通过掩码自适应实例归一化(MAdaIN)确保全局光照一致性,并使用对齐模块自适应地细化特征。此外,Fu等人[11]引入了FusionNet,它生成融合权重图,使用边界感知的RefineNet进一步消除阴影痕迹。然而,这些方法严重依赖输入阴影掩码的准确性。现实场景的复杂性和可变性,可能会在生成精确阴影掩码方面带来挑战,这可能会影响这些方法在实际应用中的性能。
无掩码的图像阴影去除
Fan等人[9]引入了一个端到端的深度卷积神经网络,该网络由一个用于预测阴影比例因子的编码器 - 解码器网络和一个用于增强边缘细节的小型细化网络组成。Chen等人[5]设计了CANet,它采用两阶段过程进行阴影去除,使用上下文补丁匹配(CPM)模块识别阴影和非阴影补丁之间的匹配对,并使用上下文特征转移(CFT)机制转移上下文信息,有效地消除阴影影响。Vasluianu等人[37]引入了环境光归一化(ALN)来改善复杂光照下的图像恢复,并提出了IFBlend,它通过最大化图像 - 频率联合熵来增强图像,而不依赖于阴影定位。Liu等人[25]提出了一个阴影感知分解网络,用于分离光照和反射层,然后使用双边校正网络进行光照调整和纹理恢复。
基于变换器的图像恢复
基于变换器的网络通常采用自注意力机制来理解不同组件之间的关系,在处理长距离依赖方面表现出很高的优越性,在图像恢复方面展现出了最先进的性能。SwinIR[22]是一种著名的图像恢复骨干网络,它是基于几个残差Swin变换器[26]块设计的。以视觉变换器[39]为骨干,DehazeFormer[35]被提出用于去雾任务。最近,基于Retinex理论提出了一种轻量级变换器架构[4],用于低光照图像增强。
3. 方法
3.1 基于ConvNext的U-Net用于阴影去除
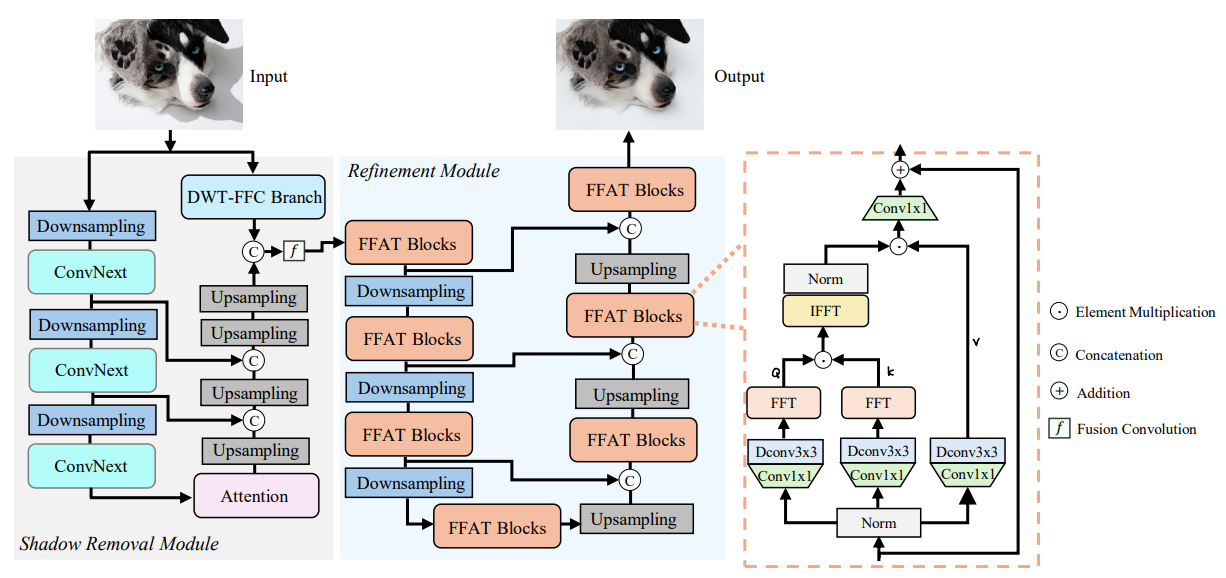
为了实现令人满意的阴影去除性能,强大的深度学习网络对于从受阴影影响的图像中提取重要特征,以及对受阴影影响和干净图像之间的映射进行建模至关重要。在这项工作中,我们引入了一种基于ConvNext的U-Net架构,其中多尺度ConvNext块作为强大的编码器,用于稳健的潜在特征学习。
如图2所示,基于ConvNext的U-Net是阴影去除模块的主要组成部分,DWT-FFC分支[8, 51]作为辅助分支被纳入其中。每个分支的贡献将在4.4节中介绍。
具体来说,我们的基于ConvNext的U-Net包含三个下采样层,每个下采样操作之后都有几个ConvNext块用于特征提取。给定一个潜在特征 F i n F_{in} Fin,ConvNext块首先采用一个 7 × 7 7×7 7×7的深度卷积,其功能类似于变换器中的自注意力机制。然后在两个 1 × 1 1×1 1×1卷积之前应用层归一化(LN),这两个 1 × 1 1×1 1×1卷积相当于变换器中的MLP块。此外,受变换器MLP块仅包含一个激活函数这一事实的启发,在两个 1 × 1 1×1 1×1卷积之间仅使用一个GELU函数。
在解码过程中,潜在特征使用一个注意力块[30]进行聚合,并使用几个上采样操作将潜在特征恢复到原始分辨率。在每个上采样层中,都有一个像素混洗操作和一个注意力块。此外,编码器特征通过跳跃连接转移到解码过程中。
在第一阶段,我们仅优化阴影去除模块,训练目标如下所示:
L l o s s = L 1 + α L S S I M + β L P e r c e p + γ L a d v
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











