







Efficient Frequency Domain-based Transformers for High-Quality Image Deblurring
论文信息
题目:Efficient Frequency Domain-based Transformers for High-Quality Image Deblurring
基于频域的高效 Transformer 实现高质量图像去模糊
源码https://github.com/kkkls/FFTformer
论文创新点
基于频域的高效Transformer实现高质量图像去模糊
摘要
本文提出了一种高效的方法,利用Transformer在频域的特性实现高质量图像去模糊。该方法受卷积定理启发,即两个信号在空间域的相关性或卷积等同于它们在频域的逐元素相乘。基于此,我们开发了一种高效的频域自注意力求解器(FSAS),通过逐元素相乘操作而非空间域的矩阵乘法来估计缩放点积注意力。此外,我们发现简单使用Transformer中的前馈网络(FFN)无法获得良好的去模糊效果。为解决这一问题,我们提出了一种简单有效的基于频域的判别式前馈网络(DFFN),基于联合图像专家组(JPEG)压缩算法在前馈网络中引入门控机制,以判别式地确定特征中的低频和高频信息哪些应被保留,用于潜在清晰图像的恢复。我们将提出的FSAS和DFFN构建成一个基于编码器 - 解码器架构的非对称网络,其中FSAS仅用于解码器模块,以实现更好的图像去模糊效果。实验结果表明,该方法优于现有方法。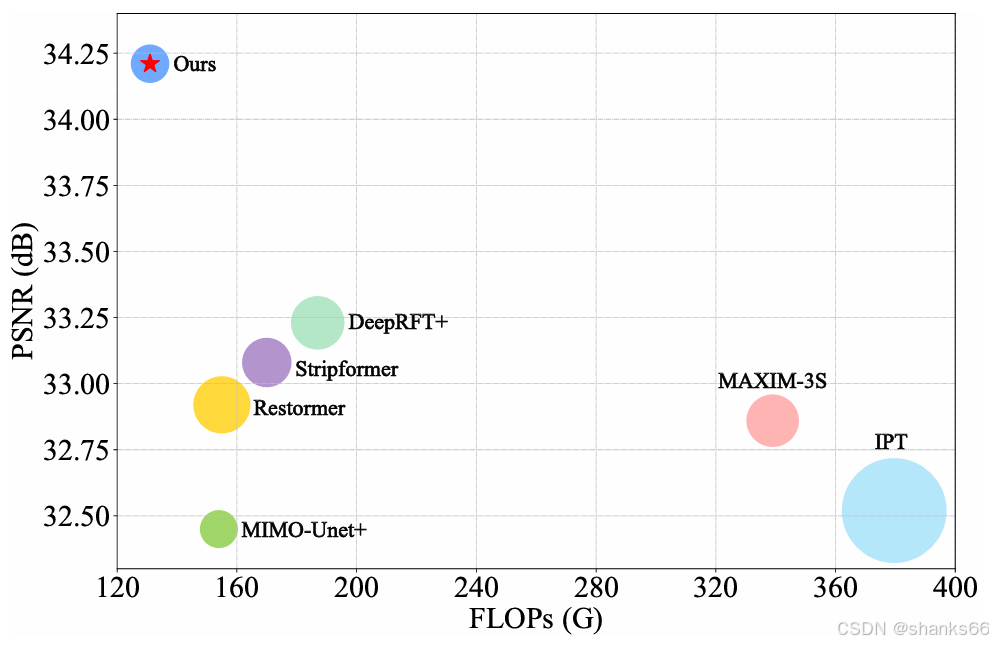
1. 引言
1.1 图像去模糊研究现状
图像去模糊旨在从模糊图像中恢复高质量图像。随着各种有效的深度模型以及大规模训练数据集的发展,这一问题取得了显著进展。目前,大多数最先进的图像去模糊方法主要基于深度卷积神经网络(CNNs)。这些方法的成功主要得益于各种网络架构设计,如多尺度或多阶段网络架构、生成对抗学习、受物理模型启发的网络结构等。然而,卷积操作作为这些网络的基本操作,是一种空间不变的局部操作,无法对图像内容的空间变化特性进行建模。因此,大多数方法通过使用更大更深的模型来弥补卷积的局限性,但简单增加深度模型的容量并不总是能带来更好的性能。
1.2 Transformer在图像去模糊中的应用与问题
与卷积操作不同,Transformer能够通过计算一个标记与所有其他标记的相关性来建模全局上下文。它在许多高级视觉任务中表现出色,并且有潜力替代深度CNN模型。在图像去模糊领域,基于Transformer的方法也取得了比基于CNN的方法更好的性能。然而,Transformer中缩放点积注意力的计算会导致与标记数量相关的二次空间和时间复杂度。尽管使用更小更少的标记可以降低空间和时间复杂度,但这种策略无法很好地建模特征的长距离信息,在处理高分辨率图像时通常会产生明显的伪影,从而限制了性能的提升。
1.3 本文的研究方法与贡献
为缓解上述问题,本文提出了一种高效的方法,利用Transformer的特性实现高质量图像去模糊。我们发现缩放点积注意力的计算实际上可以通过重新排列标记的排列后用卷积操作实现。基于这一观察和卷积定理,即空间域的卷积等同于频域的逐点乘法,我们开发了FSAS,通过逐元素相乘操作而非矩阵乘法来估计缩放点积注意力,从而将每个特征通道的空间和时间复杂度降低到 O ( N ) O(N) O(N)和 O ( N log N ) O(N \log N) O(NlogN) ,其中 N N N是像素数量。
此外,我们发现简单使用FFN无法产生良好的去模糊结果。因此,我们基于JPEG压缩算法开发了DFFN,通过引入门控机制来判别式地确定哪些低频和高频信息应被保留,以恢复潜在的清晰图像。
我们将FSAS和DFFN构建成一个基于编码器 - 解码器架构的端到端可训练网络来解决图像去模糊问题。考虑到浅层特征通常包含模糊效应,我们设计了一种非对称网络架构,仅在解码器模块中使用FSAS,以实现更好的图像去模糊效果。实验结果表明,该方法在准确性和效率方面优于现有方法。
本文的主要贡献如下:
- 开发了FSAS来估计缩放点积注意力,降低了空间和时间复杂度,且更高效。
- 基于JPEG压缩算法提出了DFFN,以判别式地确定用于恢复潜在清晰图像的低频和高频信息。
- 设计了基于编码器 - 解码器网络的非对称网络架构,仅在解码器模块中使用频域自注意力求解器,以实现更好的图像去模糊效果。
- 分析了Transformer在频域的特性有助于去除模糊,并证明了该方法优于现有方法。
2. 相关工作
2.1 基于深度CNN的图像去模糊方法
近年来,随着不同深度CNN模型的发展,图像去模糊取得了显著进展。Nah等人提出了基于多尺度框架的深度CNN,直接从模糊图像中估计清晰图像。为了更好地利用多尺度框架中每个尺度的信息,Tao等人开发了一种有效的尺度循环网络。Gao等人提出了选择性网络参数共享方法来改进现有方法。由于使用更多尺度并不能显著提高性能,Zhang等人开发了基于多补丁策略的有效网络,去模糊过程逐步实现。为了更好地探索不同阶段的特征,Zamir等人提出了跨阶段特征融合以提高性能。为了降低基于多尺度框架方法的计算成本,Cho等人提出了多输入多输出网络。Chen等人分析了基线模块并对其进行简化,以实现更好的图像恢复。然而,卷积操作是空间不变的,无法有效地为图像去模糊建模全局上下文。
2.2 Transformers及其在图像去模糊中的应用
Transformer能够建模全局上下文,在许多高级视觉任务中取得了显著进展,如图像分类、目标检测和语义分割等。它也被应用于解决图像超分辨率、图像去模糊和图像去噪等问题。为了降低Transformer的计算成本,Zamir等人提出了一种高效的Transformer模型,在特征深度域计算缩放点积注意力,该方法可以有效地探索通道维度上不同特征的信息,但未能充分探索对图像恢复至关重要的空间信息。Tsai等人通过构建内部和条带间标记来简化自注意力的计算,以替代全局注意力。Wang等人提出了一种基于UNet的Transformer,使用非重叠窗口自注意力进行单图像去模糊。尽管这些方法使用分割策略降低了计算成本,但粗略的分割并没有充分探索每个补丁的信息。此外,这些方法中的缩放点积注意力通常需要复杂的矩阵乘法,其空间和时间复杂度为二次方。
与这些方法不同,本文开发了一种基于Transformer的高效方法,利用频域特性避免了缩放点积注意力的复杂矩阵乘法。
3. 提出的方法
3.1 方法概述
本文的目标是提出一种高效的方法,利用Transformer的特性实现高质量图像去模糊。为此,我们首先开发了FSAS来估计缩放点积注意力。为了优化频域求解器估计的特征,我们进一步开发了DFFN。我们将上述方法构建成一个基于编码器 - 解码器架构的端到端可训练网络来解决图像去模糊问题,其中用于估计缩放点积注意力的FSAS用于解码器模块,以实现更好的特征表示。图2(a)展示了该方法的概述。接下来,将详细介绍每个组件。
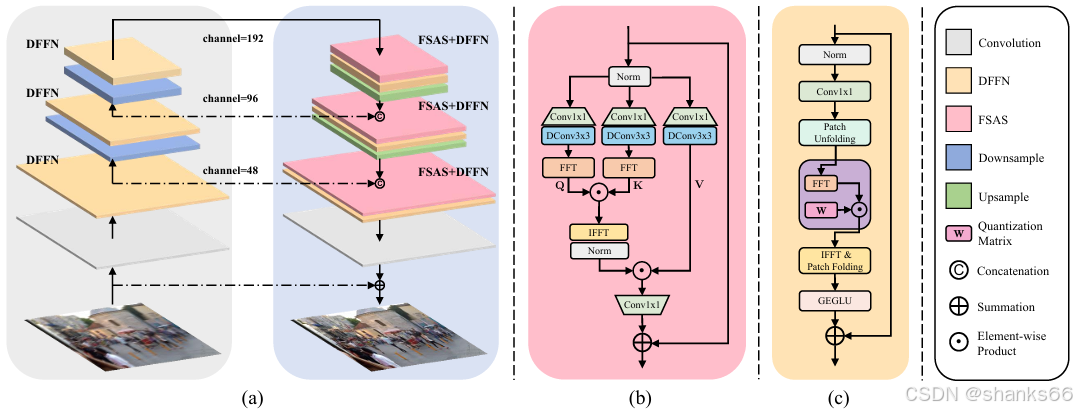
3.1.1 基于频域的自注意力求解器
给定空间分辨率为 H × W H×W H×W像素、 C C C通道的输入特征 X X X,现有的视觉Transformer通常首先通过对 X X X应用线性变换 W q W_{q} Wq、 W k W_{k} Wk和 W v W_{v} Wv来计算特征 F q F_{q} Fq、 F k F_{k} Fk和 F v F_{v} Fv 。然后,对特征 F q F_{q} Fq、 F k F_{k} Fk和 F v F_{v} Fv应用展开函数,提取图像补丁 { q i } i = 1 N \{q_{i}\}_{i = 1}^{N} {
qi}i=1N、 { k i } i = 1 N \{k_{i}\}_{i = 1}^{N} {
ki}i=1N和 { v i } i = 1 N \{v_{i}\}_{i = 1}^{N} {
vi}i=1N ,其中 N N N表示提取的补丁数量。通过对提取的补丁应用重塑操作,可以得到查询 Q Q Q、键 K K K和值 V V V:
Q = R ( { q i } i = 1 N ) , K = R ( { k i } i
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 448
448

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











