






无处不在的缓存

今天我们来聊聊无处不在的缓存。
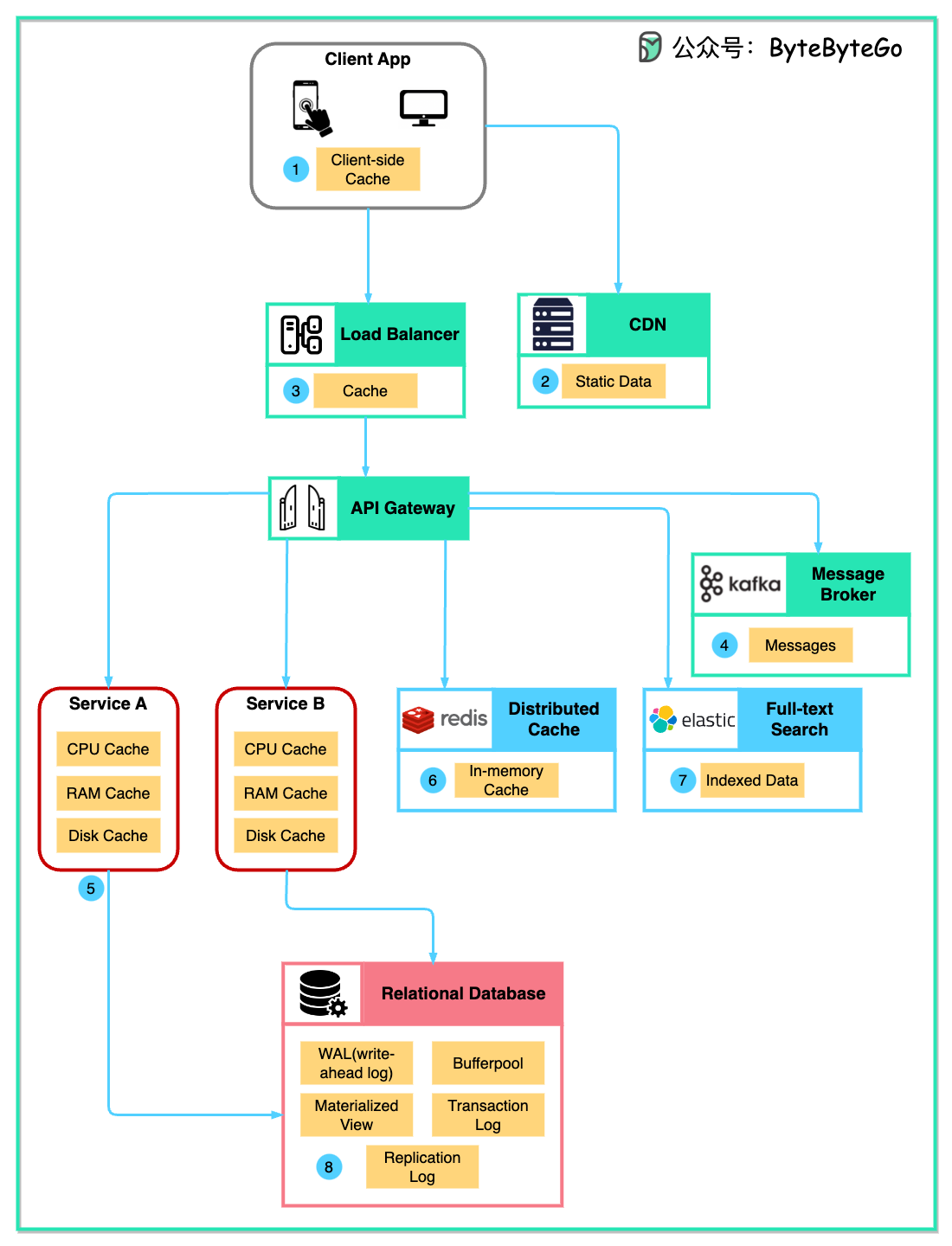
提到缓存,我们很容易联想到Redis这样的独立缓存系统。实际上,一个分布式系统中,缓存的应用比这个广泛得多。
下图列举了在一个典型架构中会用到缓存。
-
客户端
浏览器可以缓存 HTTP 响应。我们第一次通过 HTTP 请求数据时,HTTP 头会返回一个过期策略;我们再次请求数据时,客户端应用程序会尝试先从浏览器缓存中检索数据。
-
CDN(内容分发网络)
我们把网络资源分为动态和静态。与用户无关的资源是静态的,而与用户访问时间、设备、位置、用户配置等相关的资源是动态资源。
CDN 缓存静态网络资源。客户端可以从附近的 CDN 节点检索数据。比如,一个新闻网站的大部分网页内容都是静态的,可以缓存在CDN中。CDN也可以缓存部分动态内容,我们在CDN边缘节点上运行一些简单的函数来计算动态内容。
-
负载平衡器
负载平衡器也可以缓存资源。比如我们开启了Nginx的静态缓存后,就可以将一些静态文件(CSS,图片等)进行缓存。
-
消息中间件
消息中间件(Kafka)收到消息后,首先将消息存储在磁盘上,然后消费者按自己的节奏消费消息。数据会在 Kafka 集群中缓存一段时间。
-
服务
服务中有多层缓存。如果 CPU 缓存中没有命中,服务会尝试从内存中检索数据。
为了加快访问速度,服务有时会设计一个二级缓存,将部分数据存储在磁盘上。一般来说,内存中缓存的数据是二级缓存的子集。如果内存中找不到相应的数据,那么就可以在二级缓存中寻找。
-
分布式缓存
分布式缓存(如 Redis)在内存中为多个服务保存键值对。它的读/写性能比数据库好得多。在官方基准测试中可以达到10万QPS。
-
全文搜索
我们有时需要使用全文搜索(Elastic Search)来搜索文档或日志。搜索引擎也会索引数据副本。
-
数据库
即使在数据库中,我们也有不同级别的缓存:
-
WAL(Write Ahead Log):数据先写入 WAL,然后再建立 B 树索引 -
缓冲池(Buffer Pool): 分配给缓存查询结果的内存区域 -
Materialized View: 预先计算查询结果并将其存储在数据库表中,以提高查询性能 -
事务日志(Transaction Log):记录所有事务和数据库更新 -
复制日志(Replication Log):用于记录数据库集群中的数据复制状态
应用缓存的基本原则:
-
空间换时间
在高速设备中的存储一部分的冗余数据,来加快数据的访问速度。
-
距离换时间
在就近的存储设备中缓存一部分数据,用以加速数据访问。
我们介绍了这么多层次的缓存,那么你觉得从系统中完全清除用户敏感信息的难度是不是很大了呢?
【关注公众号ByteByteGo获取高清图】
















 239
239











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











