






一、初识C++
1.1 引用的概念
引用就是某一变量或常量的“别名”,对引用进行操作与直接操作变量或常量完全一样。引用本质也是通过指针实现的,但是在使用的过程中弱化了内存地址这一概念,因此除了C++以外的面向对象编程语言都保留了引用,哪怕这些编程语言剔除了指针这一概念。
1.2 引用的性质
1. 可以改变引用的变量的值,但是不能再次成为其它变量的引用。
2. 声明引用时,必须同时对其进行初始化。
3. 声明引用时,初始化的值不能是NULL。
4. 声明引用时,初始化的值可以是纯数值,此时需要使用const关键字修饰引用,表示常引用,其值不可变。
#include <iostream>
using namespace std;
int main()
{
// int& a = 123; 错误
const int& a = 123; // 常引用
cout << a << endl; // 123
// a++; 错误
return 0;
}
5. 可以将变量的引用地址赋值给一个指针,此时指针指向的还是原来的变量。
#include <iostream>
using namespace std;
int main()
{
int a = 10;
int& b = a; // b是a的引用
int* c = &b; // c指向b
cout << *c << endl; // 10
return 0;
}
6. 可以建立指针的引用。
#include <iostream>
using namespace std;
int main()
{
int a = 10;
int* b = &a; // b是a的指针
int*&c = b; //c是b的引用
cout << *c << " " << c << endl; // 10 0x61fe88
cout << *b << " " << b << endl; // 10 0x61fe88
return 0;
}
7. 可以用const对引用加以限定(常引用),这样的引用不可以改变引用的值,但是可以改变原变量的值。
int main()
{
int a = 10;
// b是a的常引用
const int& b = a;
// b++; 错误
a++;
cout << b << endl; // 11
return 0;
当大型的对象作为参数传递时,使用引用参数可以使传递的效率提高,因为引用参数不产生副本;相对指针而言,代码更加简洁。
引用参数应该在能被定义为const的情况下,尽量定义为const,以达到引用的安全性。
int c(a); // 相当于int c = a; //补充
二、略(废话)
三、字符串类型 string
string是C++中的字符串类型,它与int这种类型不同的是,string并不是C++本身的基本数据类型,实际上string是一个C++标准库中的字符串类。
在使用的时候需要引入头文件 #include <string>,而不是 #include <string.h>,原因是C++自带的头文件在引入时,不需要写.h
string用于在绝大多数情况下代替char*,不必担心内存是否足够、字符串长度等问题,string类内部集成了诸多字符串处理函数。
string使用的编码是ASCII,因此不支持中文。
string可以使用字符的下标来取出对应位置的字符,有两种方式:
- [ ]性能更强
- at函数更加安全
四、函数
4.1 内联函数
在C++中内联函数是为了取代C中的宏定义的函数,因为使用宏很容易出错。使用关键字inline放在函数定义(注意不是声明)的前面,可以将函数指定为内联函数。
内联函数在编译的时候,可以直接展开函数体到主函数中,因此运行效率极高,可以消除普通函数在运行期的额外开销。
一般将代码长度较小(5行以内 )且频繁使用的函数定义为内联函数。
inline void test1() // 再定义
{
cout << "test1" << endl;
}
4.2 函数重载
C++中允许同一个函数名定义多个函数,这种用法就是函数重载。
重载的函数通过参数来进行区分 ,即这些函数要求必须参数的个数或类型不同。
构造函数与成员函数也可以重载,但是析构函数不能重载。
4.3 函数的默认参数
C++允许给函数的参数设定默认值,调动函数时,如果传入参数,传入的参数会覆盖默认值。如果函数声明与定义分离,那么默认值只能在声明或定义处出现一次。
函数的默认值设定遵循“向右原则(向后原则)”,即当函数的某个参数设定了默认值后,其右边(后边)的所有参数都必须设定默认值。
void show(int a,int b,int c=3) //ok
void show(int a,int b=2,int c=3) //ok
void show(int a,int b=2,int c) //no在某些特殊情况下,默认参数与函数重载可能会出现二义性问题,不建议二者同时使用。
#include <iostream>
using namespace std;
void show(int a,int b=2,int c=3)
{
cout << a << " " << b << " " << c << endl;
}
void show(int a)
{
cout << "~" << a << endl;
}
int main()
{
// show(1); 错误:二义性
return 0;
}
4.4 哑元函数
一个函数的参数只有类型,没有名称,则这个参数被称为“哑元”,这个函数就是哑元函数。
void show(int)
{
cout << "这是一个哑元函数" << endl;
}
int main()
{
// 在调用的时候仍然要传递此参数
show(2343);
show(23);
return 0;
}
哑元函数的主要用途有:
1. 表达参数列表匹配更加严格。
2. 保持函数的向前兼容性。
3. 区分重载的同名函数。
------------------------------------------------------------------------------------------------------------------------
一、编程语言的发展历程
二、类与对象(重点)
2.1 概念
类:类是抽象的概念,规定了同一类对象拥有的属性和行为(成员=属性+行为)。
//属性也称为“成员变量”或“数据成员”
//行为也称为“成员函数”
对象:对象是具体的,是按照类的概念创建出来的实体。
有几个初学者容易混淆的点:
1. 一定先有一个类,再有这个类的对象。
2. 类仅仅表示一个抽象概念,并不是说很多对象聚集在一起就是一个类。
3. 在初学阶段,只有类没有这个类的对象没有意义。
2.2 类的定义
以“手机”为例,来说明类的定义。
手机的属性:
品牌、型号、重量
手机的行为:
播放音乐、运行游戏、通讯
2.3 对象实例化
C++有两种创建对象的方式:
1.栈内存对象
这种对象创建后,在其生命周期结束后(所在的花括号执行完成后),自动被销毁。
2.堆内存对象
堆内存对象的创建需要使用new关键字,并且使用指针来指向此对象。
堆内存的对象需要程序员手动使用delete关键字来销毁,如果没有delete,那么这个对象所在的花括号执行完成后,会持续占用内存且无法回收,这种现象被称为“内存泄漏”。轻微的内存泄漏并不会对程序运行有明显的影响,随着内存泄漏的累积,逐渐会导致程序卡顿,甚至无法正常运行。
因此对于堆内存对象,通常有new就一定有一个对应的delete。
已经delete的对象,有时候还可以正常使用其部分功能,但是请不要这要做!
栈内存对象不支持delete关键字。
三、封装
上面章节中的手机类看起来非常像结构体,实际上结构体可以被看成是一种完全开放的类。这样的类所有的数据都暴露在外面,实际上是比较危险的。因此需要对类中的内容进行封装。
封装指的是,先将类的一些属性和其它细节隐藏,根据业务需求重新提供给外部对应功能的调用接口。
外部的调用接口最基础的有两类:
- 读取属性值 getter
- 写入属性值 setter
封装前后的类,类似于测试中的白盒与黑盒的概念
class MobilePhone
{
private: // 私有权限:只能在类内部访问
string brand; // 只读:只添加getter接口
string model; // 只写:只添加setter接口
int weight; // 可读可写:同时添加getter和setter接口
public: // 重新对外部开放对应的功能接口
string get_brand()
{
return brand;
}
void set_model(string m)
{
model = m;
}
int get_weight()
{
return weight;
}
void set_weight(int w)
{
weight = w;
}
};
四、构造函数
4.1 构造函数的基本使用
构造函数用来创建一个类的对象,在创建对象时还可以给对象的属性赋予初始值。
构造函数不用写返回值类型,函数名称必须与类名完全一致。
当程序员没有手动编写构造函数时,编译器会自动添加一个没有参数的,函数体为空的构造函数。一旦程序员手动编写了任一一个构造函数,编译器不再自动添加构造函数。
构造函数也支持函数重载和函数参数默认值。
#include <iostream>
using namespace std;
class MobilePhone
{
private:
string brand;
string model;
int weight;
public:
// 编译器自动添加的构造函数
// MobilePhone(){}
// 手动添加一个构造函数,来给属性赋予初始值
MobilePhone(string b,string m,int w)
{
brand = b;
model = m;
weight = w;
}
// 函数重载
MobilePhone()
{
brand = "山寨";
model = "8848钛金手机";
weight = 666;
}
// 打印当前的属性值
void show()
{
cout << brand << " " << model << " " << weight << endl;
}
};
int main()
{
MobilePhone mp1("苹果","14 Pro",188);
mp1.show();
MobilePhone* mp2 = new MobilePhone("小米","12",199);
mp2->show();
delete mp2;
MobilePhone mp3;
mp3.show();
return 0;
}
4.2 构造初始化列表
是基于构造函数对属性赋予初始值的另一种简便写法,在现有阶段,可以根据实际情况来决定是否采用。
MobilePhone(string b,string m,int w)
:brand(b),model(m),weight(w){}
关于构造初始化列表,需要注意以下几点:
- 构造初始化列表的效率比构造函数函数体中赋值更高。
- 如果成员变量是常成员变量,则不能在构造函数的函数体中赋予初始值,可以通过构造初始化列表赋予初始值。
- 如果影响代码的可读写,可以不使用构造初始化列表。
另外,属性值也可以直接赋值,如下所示。
class MobilePhone
{
private:
// 设置属性的默认值
string brand = "山寨";
string model = "8848";
int weight = 188;
...
}4.3 拷贝构造函数
如果程序员不手动编写拷贝构造函数,编译器会为每个类增加一个默认的拷贝构造函数。
#include <iostream>
using namespace std;
class MobilePhone
{
...
};
int main()
{
MobilePhone mp1;
mp1.show();
// 调用默认的拷贝构造函数
MobilePhone mp2(mp1);
mp2.show();
cout << &mp1 << " " << &mp2 << endl;
return 0;
}
上面的例子中,mp1和mp2是两个数据相同的对象,每个对象的数据都是相互独立,只属于当前对象持有。
4.3.1 浅拷贝
当成员变量出现指针类型时,默认的拷贝构造函数是基于赋值操作的,因此在拷贝的过程中,会出现指针的拷贝,会造成多个对象的属性指向同一个内存区域的问题,这样的现象不符合面向对象的设计规范。
#include <iostream>
#include <string.h>
using namespace std;
class Dog
{
private:
char* name; // 故意使用char*
public:
Dog(char* n)
{
name = n;
}
// 编译器自动添加下面的拷贝构造函数
Dog(const Dog& d)
{
name = d.name; // 指针的拷贝!
}
void show_name()
{
cout << name << endl;
}
};
int main()
{
char c[20] = "WangCai";
Dog d1(c);
Dog d2(d1); // 拷贝构造函数
strcpy(c,"XiaoBai");
// 属性值无法对象独自持有
d1.show_name(); // XiaoBai
d2.show_name(); // XiaoBai
return 0;
}
4.3.2 深拷贝
默认的拷贝是浅拷贝,当属性出现指针类型,应该手写一个深拷贝构造函数。
#include <iostream>
#include <string.h>
using namespace std;
class Dog
{
private:
char* name;
public:
Dog(char* n)
{
// 创建堆内存对象
name = new char[20];
// 数据复制
strcpy(name,n);
}
Dog(const Dog& d)
{
// 创建堆内存对象
name = new char[20];
// 数据复制
strcpy(name,d.name);
}
void show_name()
{
cout << name << endl;
}
};
int main()
{
char c[20] = "WangCai";
Dog d1(c);
Dog d2(d1); // 拷贝构造函数
strcpy(c,"XiaoBai");
// 属性值无法对象独自持有
d1.show_name(); // WangCai
d2.show_name(); // WangCai
return 0;
}
在实际开发过程中,解决浅拷贝的问题可以通过一些简单粗暴的方式,例如直接把拷贝构造函数设置为私有权限,这样就屏蔽了外界对拷贝构造函数的调用。
4.4 隐式调用构造函数
int main()
{
string s1 = "AAA";
string s2 = "BBB";
// 显式调用构造函数
Test t1(s1);
cout << t1.get_name() << endl;
// 隐式调用构造函数
Test t2 = s2;
cout << t2.get_name() << endl;
return 0;
}
尽管隐式调用构造函数比较方便,但是可能会存在一个问题:在参数传递的过程中无意中创建了对象,这种情况可以使用explicit关键字修饰构造函数,来达到屏蔽使用构造函数的隐式调用。
五、析构函数(重点)
在4.3.2节中,深拷贝的示例代码虽然解决了指针作为成员变量拷贝对象的问题,但是在构造函数中开辟的内存区域,没有得到合理的释放,造成了内存泄漏的问题。要解决这个问题需要使用析构函数。
先来学习析构函数的基本使用,析构函数是与构造函数完全对立的函数。
| 构造函数 | 析构函数 |
| 调用时机:对象创建时 | 调用时机:销毁对象时 |
| 手动调用 | 自动调用 |
| 可以有参数,可以重载 | 不能有参数,不能重载 |
| 函数名是类名 | 函数名是~类名 |
| 通常用于对象数据的初始化 | 通常用于对象占用资源的释放 |
class Test
{
private:
string name;
public:
Test(string n):name(n){}
~Test()
{
cout << name << "析构函数" << endl;
}
};
六、作用域限定符::
6.1 名字空间
最常见的名字空间是std,也被称为标准名字空间,C++源代码中一些基础性的内容都在这个名字空间下,例如:std::cout、std::endl、std::string等。
之所以平常编程时不用写std名字空间是由于添加了using namespace std;
#include <iostream>
//using namespace std;
int main()
{
std::cout << "hello world!" << std::endl;
return 0;
}
同样,程序员也可以自己写名字空间。
#include <iostream>
using namespace std;
int a = 1;
// 自定义名字空间
namespace my_space {
int a = 3;
int b = 4;
}
// 使用自定义名字空间
using namespace my_space;
int main()
{
int a = 2;
cout << a << endl; // 2
cout << ::a << endl; // 1
cout << my_space::a << endl; // 3
cout << b << endl; // 4
return 0;
}
6.2 类内声明,类外定义
类中成员函数可以在类内声明,类外定义,这样可以把声明和定义分离。
七、命名规范(了解)
八、this指针
8.1 this指针的定义
this指针是一个特殊的指针,指向类在外部的对象。
#include <iostream>
using namespace std;
class Student
{
public:
void test_this()
{
cout << this << endl;
}
};
int main()
{
Student s1;
cout << &s1 << endl; // 0x61fe9f
s1.test_this(); // 0x61fe9f
Student s2;
cout << &s2 << endl; // 0x61fe9e
s2.test_this(); // 0x61fe9e
return 0;
}
判断this指针的指向,只需要查看this指针所在的函数被哪个对象调用,this指向的就是这个对象。
8.2 this指针的用法
this关键字只能在类内使用,用法如下。
8.2.1 区分重名的成员变量与局部变量
class Teacher
{
private:
string name;
public:
Teacher(string name) // 这种重名情况构造初始化列表也可以区分
{
// 区分成员变量与局部变量
this->name = name;
}
string get_name()
{
// 编译器自动补上this->
return name;
}
};
8.2.2 *this表示引用整个对象
当函数的返回值是当前类的引用时,*this表示的是this指向的对象本身,可以作为返回值,这样的函数支持“链式调用”。
#include <iostream>
using namespace std;
class Value
{
private:
int value;
public:
Value(int value):value(value){}
// 如果一个类的返回值是当前类的引用,表示该函数支持“链式调用”
Value& add(int i)
{
value += i;
return *this;
}
int get_value()
{
return value;
}
};
int main()
{
Value v(100);
// 链式调用
cout << v.add(6).add(-8).add(200).add(34).get_value() << endl; // 332
cout << v.get_value() << endl; // 332
return 0;
}
九、static关键字
9.1 静态局部变量
普通的局部变量加上static修饰就是静态局部变量。
9.2 静态成员变量
给普通的成员变量加上static修饰,就是静态成员变量。
静态成员变量往往都需要初始化,通常需要类内声明,类外初始化。
C++中所有的类中的静态变量(局部和成员)都是这个类的所有对象共用一份,这种静态变量不会伴随着对象的销毁而销毁。
静态成员变量在程序的一开始就开辟了,不需要对象就可以调用,而且更推荐这种调用方式,如下所示。
#include <iostream>
using namespace std;
class Test
{
public:
// 类内声明静态成员变量
static int a;
};
// 类外初始化静态成员变量
int Test::a = 1;
int main()
{
// 通过类名直接调用
cout << Test::a << " " << &Test::a << endl; // 1 0x408004
Test t1;
Test t2;
// t1和t2的a都是之前的a
cout << t1.a << " " << &t1.a << endl; // 1 0x408004
cout << t2.a << " " << &t2.a << endl; // 1 0x408004
return 0;
}
9.3 静态成员函数
给普通的成员函数加上static修饰,就是静态成员函数。
静态成员函数可以直接在类内定义,也可以类内声明类外定义,但是如果是后者,static关键字只写在声明处。
静态成员函数与静态成员变量相似,可以通过对象调用,也可以通过类名调用,更推荐后者,理由相同。
静态成员函数可以调用其它静态成员,但是不能调用本类的非静态成员,其原因在于静态成员函数没有this指针,而类中非静态成员的调用都是通过this完成的。
非静态的成员函数可以访问静态成员。
#include <iostream>
using namespace std;
class Test
{
public:
static string s1;
string s2 = "非静态成员";
static void test1() // 静态成员函数
{
cout << s1 << endl;
// cout << s2 << endl; 错误
}
void test2() // 成员函数
{
cout << s1 << endl;
cout << s2 << endl;
}
};
string Test::s1 = "静态成员";
int main()
{
Test::test1();
Test t1;
Test t2;
t1.test2();
return 0;
}
由于静态成员函数没有this指针,因此相比于非静态的成员函数执行速度有少许的增长。
9.4 单例模式(了解)
设计模式是一套被反复使用的、多数人知晓的、经过分类的代码设计经验总结。通常用在一些面向对象的编程语言中,比如C++、Java、C#等。
以设计模式中最基础的单例模式来说明static的应用,单例模式设计的类可以在全局仅创建同一个对象。
基于指针的单例模式:
#include <iostream>
using namespace std;
class Singleton
{
private:
// 屏蔽构造函数
Singleton(){}
Singleton(const Singleton&){}
~Singleton(){} // 析构函数
// 静态成员变量,保存单实例
static Singleton* instance;
public:
static Singleton* get_instance() // 静态成员函数获取对象
{
// 如果是第一次调用此函数,则创建对象
if(instance == NULL)
instance = new Singleton;
return instance;
}
static void delete_instance()
{
// 如果单实例已经创建,则销毁并重置
if(instance != NULL)
{
delete instance;
instance = NULL;
}
}
};
Singleton* Singleton::instance = NULL;
int main()
{
Singleton* s1 = Singleton::get_instance();
Singleton* s2 = Singleton::get_instance();
cout << s1 << " " << s2 << endl; // 0x880fe0 0x880fe0
Singleton::delete_instance();
return 0;
}
基于引用的单例模式:
#include <iostream>
using namespace std;
class Singleton
{
private:
// 屏蔽构造函数
Singleton(){}
Singleton(const Singleton&){}
~Singleton(){} // 析构函数
public:
static Singleton& get_instance()
{
// 静态局部变量,单实例对象会一直存在到程序结束
static Singleton instance;
return instance;
}
};
int main()
{
Singleton& s1 = Singleton::get_instance();
Singleton& s2 = Singleton::get_instance();
cout << &s1 << " " << &s2 << endl; // 0x408050 0x408050
return 0;
}
十、const关键字
const关键字通常被认为是常量,但是这种说法并不严谨,准确地说,应该是运行期常量或运行期只读,即const关键字在编译期并不生效。
const能修饰很多变量或函数等,用法如下。
10.1 常成员函数(掌握)
const修饰成员函数,表示常成员函数,这样的函数特点是:
- 可以调用非const的成员变量,但是不能修改其数值
- 不能调用非const的成员函数
#include <iostream>
using namespace std;
class Test
{
private:
int a = 1;
public:
void test1() const // 常成员函数
{
cout << a << endl;
// a++; 错误
// set_a(2); 错误
cout << get_a() << endl;
}
int get_a() const
{
return a;
}
void set_a(int a)
{
this->a = a;
}
};
int main()
{
Test t;
t.test1();
return 0;
}
建议只要类的成员函数不修改属性值就写成常成员函数,例如getter。
10.2 常量对象
const可以修饰对象,表示该对象为常量对象。
常量对象的特点有:
- 常量对象中任何成员变量都不能被修改
- 常量对象不能调用任何非const的成员函数
#include <iostream>
using namespace std;
class Test
{
public:
string s = "你好";
void test1() const
{
cout << "常成员函数" << endl;
}
void test2()
{
cout << "非const的成员函数" << endl;
}
};
int main()
{
Test t1;
t1.s = "再见";
cout << t1.s << endl;
t1.test1();
t1.test2();
// 常量对象(两种写法)
Test const t2;
const Test t3;
// t2.s = "哈哈"; 错误
cout << t2.s << endl;
t3.test1();
// t3.test2(); 错误
return 0;
}
10.3 常成员变量
const修饰成员变量时,表示常成员变量。
常成员变量的特点是:
- 数值在运行期不能被修改
- 数值在编译期可以被修改
- 必须赋予初始值,可以在声明后立刻赋值,也可以使用构造初始化列表赋值。
二者都使用时,可以发现构造初始化列表的赋值生效,其原因是构造初始化列表与声明都是在编译期间确定的,构造初始化列表编译顺序靠后。
#include <iostream>
using namespace std;
class Test
{
private:
const int a = 1; // 赋予初始值
public:
Test():a(2){} // 构造初始化类表赋值
// void set_a(int a)
// {
// this->a = a; 错误:不能修改
// }
int get_a() const
{
return a;
}
};
int main()
{
Test t1;
// t1.set_a(2); 错误
cout << t1.get_a() << endl;
return 0;
}
10.4 const修饰局部变量
const修饰的局部变量数值不可变,如果是对象属性值不可变。
10.5 constexpr常量表达式
在C++11中引入constexpr关键字,可以修饰对象或者函数。例如,修饰静态的成员变量,表示在编译期就确定好了静态成员变量的值;修饰函数表示函数返回值可能是编译器常量。
#include <iostream>
#include <array>
using namespace std;
class Test
{
public:
// 在编译期就确定了静态成员变量的值
constexpr static int a = 1;
};
constexpr int value(int i)
{
return i+1;
}
int main()
{
cout << Test::a << endl;
// value(3)可以在编译期间确定其结果是4
array<int,value(3)> arr1; // 相当于array<int,4>
int i = 1; // i在运行期间才可以确定数值
// array<int,value(i)> arr2; 错误
return 0;
}
------------------------------------------------------------------------------------------------------------------------------------------
一、友元
类实现了数据的隐藏与封装,类中成员变量一般定义为私有成员,通过公开的接口才能进行读写。如果把成员变量定义为公有的,则又破坏了封装性。
在某些情况下,需要频繁读写类的成员变量,成员函数在调用时,由于参数传递、类型检查和安全性检查等需要时间上的开销,从而影响程序运行的效率。
友元使用关键字friend,可以让类外部的函数能够访问类内部的所有成员,可以提高程序的运行效率和灵活性。但是,它破坏了类的隐藏性和封装性,滥用会导致程序的可维护性变差,因此使用友元要慎重。
友元主要有以下用法:
- 友元函数
- 友元类
- 友元成员函数
1.1 友元函数
友元函数是声明在类内的非成员函数,友元函数不属于成员函数,但是却可以访问所有成员。
#include <iostream>
using namespace std;
class Test
{
private:
int a;
public:
Test(int a):a(a){}
int get_a() const
{
return a;
}
// 友元关系声明
friend void test_friend(Test &t);
};
// 定义一个函数,此函数不属于Test类
void test_friend(Test& t)
{
t.a++; // 尝试操作Test类的私有成员变量
}
int main()
{
Test t(100);
test_friend(t);
cout << t.get_a() << endl; // 101
return 0;
}
(个人总结:友元函数的参数一定包含此类的成员)
1.2 友元类
当一个类B成为另一个类A的“朋友”时,那么类A的所有成员就可以被类B方位,我们就把类B叫做类A的友元类。
#include <iostream>
using namespace std;
class A
{
private:
string str;
public:
A(string str):str(str){}
string get_str() const
{
return str;
}
// 声明友元类
friend class B;
};
class B
{
public:
void test_friend(A& a)
{
a.str = "晴天";
}
};
int main()
{
A a("阴天");
B b;
b.test_friend(a);
cout << a.get_str() << endl; // 晴天
return 0;
}
1.3 友元成员函数
如果类B的某一个成员函数可以访问类A的所有成员,则这个成员函数就是类A的友元成员函数。
#include <iostream>
using namespace std;
// 3. 因为类B中用到了类A,因此在类B之前先声明类A
class A;
// 2. 由于类A中用到了类B,因此类B的代码写在类A之前
class B
{
public:
void test_friend(A& a); // 先只声明函数
};
class A
{
private:
string str;
public:
A(string str):str(str){}
string get_str() const
{
return str;
}
// 1. 确定友元成员函数的格式并进行友元声明
friend void B::test_friend(A& a);
};
// 4. 最后,完成友元成员函数的定义
void B::test_friend(A &a)
{
a.str = "多云";
}
int main()
{
A a("小雨");
B b;
b.test_friend(a);
cout << a.get_str() << endl; // 多云
return 0;
}
二、运算符重载
2.1 基本概念
函数可以重载,运算符也可以重载,可以把运算符看做是一个函数。
C++中运算符的操作对象默认情况下只能是基本数据类型,但实际上对于很多用户自定义的类型,也需要类似的运算操作,这时候可以在C++中重新定义这些运算符的功能,使其能够支持特定的新数据类型,完成特定的操作。
【可以被重载的运算符】
算术运算符:+、-、*、/、%、++、--
位操作运算符:&、|、~、^(位异或)、<<(左移)、>>(右移)
逻辑运算符:!、&&、||
比较运算符:<、>、>=、<=、==、!=
赋值运算符:=、+=、-=、*=、/=、%=、&=、|=、^=、<<=、>>=
其他运算符:[]、()、->、,、new、delete、new[]、delete[]
【不被重载的运算符】
成员运算符 .
指针运算符 *
三目运算符 ? :
sizeof
作用域 ::
运算符重载可以通过友元函数,也可以通过成员函数。
2.2 友元函数运算符重载
运算符作为函数,各部分的对应关系如下:

#include <iostream>
using namespace std;
/**
* @brief The Integer class 自定义整型类
*/
class Integer
{
public:
Integer(int value):value(value){}
int get_value() const
{
return value;
}
private:
int value;
// 友元声明
friend Integer operator +(Integer& i1,Integer& i2); // 双目
friend Integer operator ++(Integer& i); // 单目,前置
friend Integer operator ++(Integer& i,int); // 单目,后置
};
// 函数定义
Integer operator +(Integer& i1,Integer& i2)
{
return i1.value+i2.value; // 隐式调用构造函数
}
Integer operator ++(Integer& i)
{
return ++i.value;
}
Integer operator ++(Integer& i,int)
{
return i.value++;
}
int main()
{
Integer i1(1);
Integer i2(1);
Integer i3 = i1+i2;
cout << i3.get_value() << endl; // 2
cout << (++i3).get_value() << endl; // 3
cout << i3.get_value() << endl; // 3
cout << (i3++).get_value() << endl; // 3
cout << i3.get_value() << endl; // 4
return 0;
}
------------------------------------------------------------------------------------------------------------------------------------------
一、模板
C++中模板是支持参数化多态的工具,就是让类或函数支持一种通用的数据类型,写出与类型无关的代码。
模板主要有两种实现形式:
-
函数模板
-
类模板
1.1 函数模板
函数模板可以让一个函数的参数或返回值支持不同的数据类型,实例代码如下。
#include <iostream>
using namespace std;
template <class T> // T表示通用数据类型
T add(T a,T b)
{
return a+b;
}
class Dog
{
// 如果想让Dog类支持add函数,则需要重载+运算符
};
int main()
{
cout << add(2,3) << endl; // 5
cout << add(2.2,1.3) << endl; // 3.5
string s1 = "He";
string s2 = "llo";
cout << add(s1,s2) << endl; // Hello
Dog d1;
Dog d2;
// add(d1,d2); 错误
}
1.2 类模板
与函数模板类似,类模板是把通用数据类型的范围从一个函数扩展到了一个类中,可以实现一个与内部数据类型无关的自定义类,示例代码如下。
先写一个只在类中定义函数的类模板。
#include <iostream>
using namespace std;
template <typename T> // 除了使用class之外,使用typename也可以
class Test
{
private:
T value;
public:
Test(T v):value(v){}
T get_value() const
{
return value;
}
};
class Dog
{
public:
string name;
};
int main()
{
Test<int> t1(10); // 尖括号里说明当前使用的类中T的类型是什么
cout << t1.get_value() << endl;
Dog d1;
d1.name = "旺财";
Test<Dog> t2(d1);
cout << t2.get_value().name << endl;
}
上面的代码也可以把函数写成类内声明,类外定义的格式,示例代码如下。
#include <iostream>
using namespace std;
template <typename T> // 除了使用class之外,使用typename也可以
class Test
{
private:
T value;
public:
Test(T v);
T get_value() const;
};
// 类外定义
template <typename T>
Test<T>::Test(T v):value(v){}
template <typename T>
T Test<T>::get_value() const
{
return value;
}
class Dog
{
public:
string name;
};
int main()
{
Test<int> t1(10); // 尖括号里说明当前使用的类中T的类型是什么
cout << t1.get_value() << endl;
Dog d1;
d1.name = "旺财";
Test<Dog> t2(d1);
cout << t2.get_value().name << endl;
}
二、容器
在讲解容器之前,先来了解一些基础概念。
【泛型编程】
泛型编程最初提出的动机是:发明一种编程语言机制,能够实现一个通用的标准容器库,所谓通用的标准容器库,就是可以做到编写独立于数据类型之外的、可重复使用的算法。
【STL标准模板库】
标准模板库(Standard Template Library,STL)是惠普实验室开发一系列软件的统称,在被引入C++之前,该技术已经存在了很长时间。
STL的代码从广义上来讲分为三类:算法、容器、迭代器。STL中基本所有的代码都采用函数模板和类模板的方式,相比于传统函数和类提供了更好的代码重用的机会。
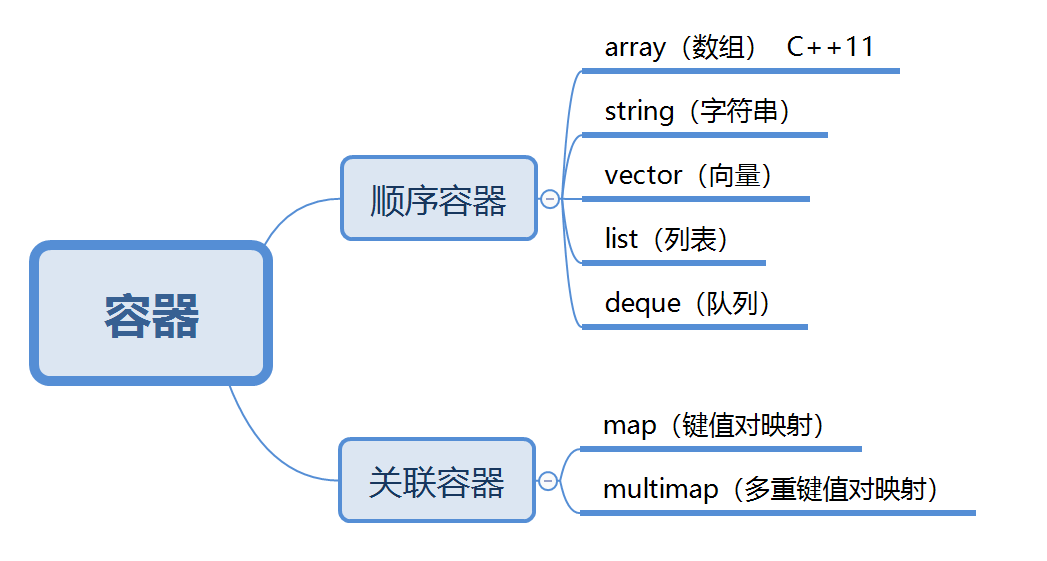
2.1 容器的分类(掌握)
容器是用来批量存储数据的集合,数据元素可以是用户自定义类型,也可以是C++预定义类型。容器类的对象自动申请和释放内存,无需new和delete操作。
所有容器类的使用都需要引入对应的容器名称的头文件,所有的容器类都在标准名字空间std下。
2.2 顺序容器
是一种各个元素之间有顺序关系的线性容器,每个元素都有自己的位置,通过下标或迭代器进行访问,除非用删除或者插入的操作改变元素的顺序。
本次学习的顺序容器有:array(数组)、string(字符串)、vector(向量)、list(列表)、deque(队列)。
2.2.1 array 数组
C++11新增的数组,符合容器的设计规范,使用起来更加方便。
#include <iostream>
// 引入头文件
#include <array>
using namespace std;
int main()
{
// 创建一个长度为5的int数组
array<int,5> arr = {1,2,4};
// 取出对应下标的元素值
cout << arr.at(0) << endl; // 1
cout << arr[1] << endl; // 2
cout << arr[4] << endl; // 0 (不同的编译环境可能有所区别)
// 更改第四个数据的值为886
arr[3] = 886;
cout << arr[3] << endl;
cout << "-------for-------" << endl;
for(int i=0;i<arr.size();i++)
{
cout << arr.at(i) << " ";
}
// 给所有元素填充一个固定值
arr.fill(521);
cout << endl << "-------for each-------" << endl;
for(int i:arr)
cout << i << " ";
cout << endl;
}
2.2.2 vector 向量
vector内部使用数组实现,是最常用的一种顺序容器,适合高效地进行随机存取,不适合插入和删除。
#include <iostream>
// 引入头文件
#include <vector>
using namespace std;
int main()
{
// 创建一个向量对象,长度为5
vector<int> vec(5);
cout << vec.size() << endl;
// 取出元素值
cout << vec.at(0) << " " << vec[1] << endl;
// 向后添加元素
vec.push_back(12);
cout << vec.size() << endl; // 此时长度为6 动态扩充
// 删除最后一个元素
vec.pop_back();
// 在第二个位置插入元素222
vec.insert(vec.begin()+1,222);
// 在倒数第二个位置插入元素4
vec.insert(vec.end()-1,4);
// 删除倒数第一个元素
vec.erase(vec.end()-1);
cout << "---------for---------" << endl;
for(int i=0;i<vec.size();i++)
{
cout << vec.at(i) << " ";
}
cout << endl;
// 清空元素
vec.clear();
// 判断是否为空
cout << vec.empty() << endl;
}
2.2.3 list 列表
list内部由双向链表实现,元素的内存空间不连续,因此适合高效地进行插入和删除操作,不适合使用下标操作元素(只能通过迭代器指针操作元素),也不适合大量的随机存取。
#include <iostream>
// 引入头文件
#include <list>
using namespace std;
int main()
{
// 创建一个长度为4的列表对象,每个元素的初始值为"hello"
list<string> lis1(4,"hello");
cout << lis1.empty() << endl;
// 向后追加
lis1.push_back("dhjs");
// 先前追加
lis1.push_front("qian");
cout << lis1.size() << endl; // 6
// 在第一个位置插入元素
lis1.insert(lis1.begin(),"first");
// 在最后一个位置插入元素
lis1.insert(lis1.end(),"finish");
// 获得第一个元素
cout << lis1.front() << endl;
// 获取最后一个元素
cout << lis1.back() << endl;
// 删除第一个元素
lis1.pop_front();
// 获得第一个元素
cout << lis1.front() << endl;
// 删除最后一个元素
lis1.pop_back();
cout << lis1.back() << endl;
// 第二个位置插入元素
// 【注意】list的迭代器指针不支持+,可以使用自增和自减
lis1.insert(++lis1.begin(),"222222");
// 在倒数第二个位置插入元素
lis1.insert(--lis1.end(),"f68b7s");
// 在第5个位置插入一个元素
// 1. 获得起始位置的迭代器指针
// const_iterator:只读
// iterator 读写
list<string>::const_iterator iter = lis1.begin();
// 2. 把迭代器指针向后移动4位
advance(iter,4);
// 3. 使用*取内容,即元素本身
cout << "list[4] = " << *iter << endl;
// 排序
lis1.sort();
// 不支持for循环遍历,但是支持for-each
for(string i:lis1)
{
cout << i << " ";
}
cout << endl;
lis1.clear(); // 清空
cout << lis1.size() << endl;
}
2.2.4 deque 队列
从API上基本同时兼容vector和list,随机存取和插入删除的性能都介于vector和list之间,算是一种比较均衡的顺序容器类型。相对而言,deque比较擅长首尾两端的存取。
2.3 关联容器
各个元素之间没有严格的物理顺序,但是在内部有排序特点(编程不要使用),因此可以使用迭代器遍历。
常见的关联容器有:map(键值对映射)、multimap(多重键值对映射)等。
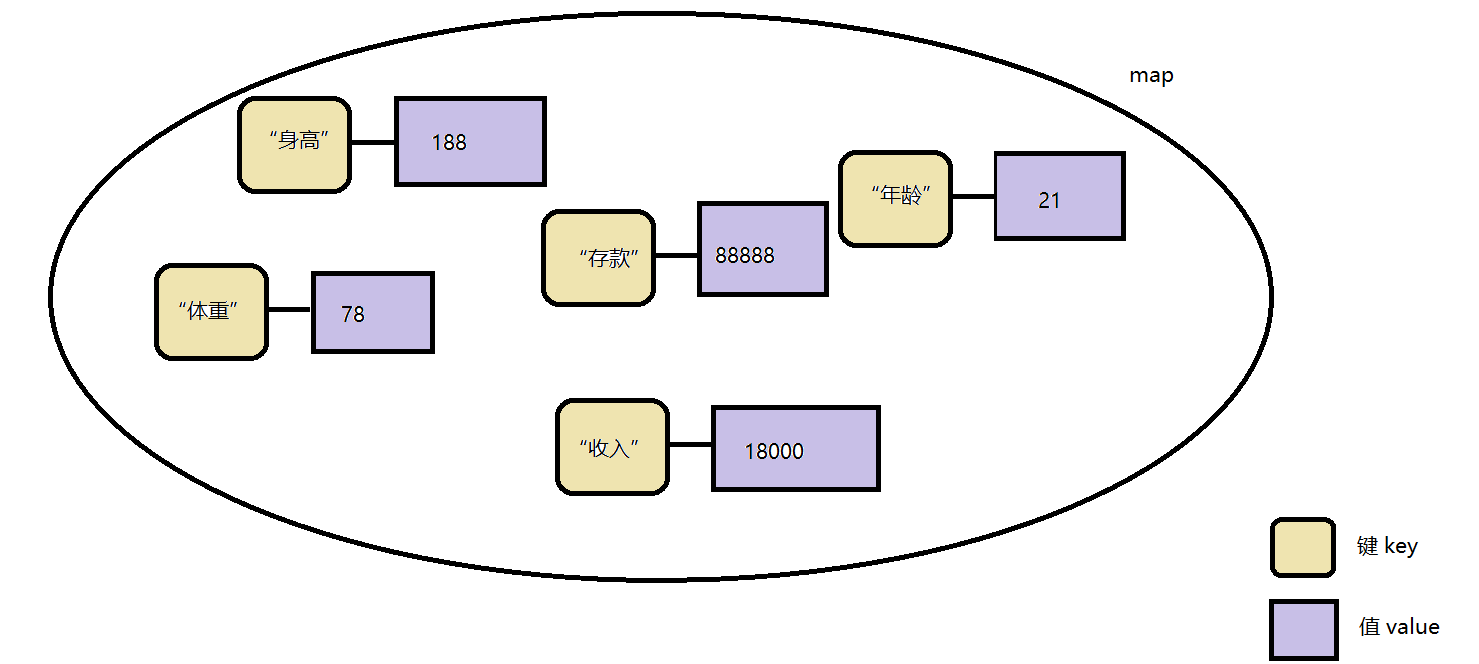
以map为例,来说明关联容器的使用。
map以键值对的方式来存储元素数据,map与multimap的区别仅仅在于一个键对应一个值还是一个键对应多个值,map更为常用。
键作为数据的名称,具有唯一性,而值则不必。
键通常为字符串类型,而值则根据存储的数据类型而定。
#include <iostream>
// 引入头文件
#include <map>
using namespace std;
int main()
{
// 创建一个元素为空的map对象
map<string,int> m;
// 插入元素
m["身高"] = 188;
m["体重"] = 78;
m["存款"] = 10000;
m["存款"] = 88888; // 如果这个键值对已经存在,则表示修改
m.insert(pair<string,int>("收入",18000));
m.insert(pair<string,int>("年龄",21));
// 判断一个键是否存在
if(m.find("存款") != m.end())
{
// 取出键对应的值
cout << m.find("存款")->second << endl;
}else
{
cout << "不存在存款键!" << endl;
}
if(m.find("住址") != m.end())
{
// 取出键对应的值
cout << m.find("住址")->second << endl;
}else
{
cout << "不存在住址键!" << endl;
}
// 删除键值对
bool result = m.erase("体重");
cout << m.size() << endl;
if(result)
cout << "删除体重成功!" << endl;
else
cout << "删除体重失败!" << endl;
result = m.erase("工龄");
cout << m.size() << endl;
if(result)
cout << "删除工龄成功!" << endl;
else
cout << "删除工龄失败!" << endl;
m.clear(); // 清空
cout << m.empty() << endl;
cout << "主函数结束" << endl;
return 0;
}
2.4 迭代器
C++中为每一个容器类都提供了对应的迭代器类型,用于遍历容器,迭代器是一种特殊的指针。
通常情况下,容器类型都可以通过begin或end函数来获得头部或尾部的迭代器,随后不断地移动迭代器来取出所有的元素。
迭代器遍历的效率是各种方式中最高的,如果只读使用const_iterator,如果读写使用iterator。
#include <iostream>
// 引入头文件
#include <string>
#include <array>
#include <vector>
#include <list>
#include <deque>
#include <map>
using namespace std;
int main()
{
string str = "Hello";
for(string::const_iterator iter = str.begin();iter != str.end();iter++)
cout << *iter << " ";
cout << endl;
array<string,5> arr = {"fsdhjk","gfd","das","gfd","adhj"};
for(array<string,5>::const_iterator iter = arr.begin();iter != arr.end();iter++)
cout << *iter << " ";
cout << endl;
vector<double> vec;
vec.push_back(3.14);
vec.push_back(6.14);
vec.push_back(4.14);
vec.push_back(4.44);
vec.push_back(8.84);
for(vector<double>::const_iterator iter = vec.begin();iter != vec.end();iter++)
cout << *iter << " ";
cout << endl;
list<string> lis;
lis.push_back("aaaaaa");
lis.push_back("aa");
lis.push_back("aaa");
lis.push_back("aaaa");
lis.push_back("aaaaa");
for(list<string>::const_iterator iter = lis.begin();iter != lis.end();iter++)
cout << *iter << " ";
cout << endl;
deque<int> deq;
deq.push_back(9);
deq.push_back(8);
deq.push_back(7);
for(deque<int>::const_iterator iter = deq.begin();iter != deq.end();iter++)
cout << *iter << " ";
cout << endl;
map<string,string> m;
m["name"] = "Jason";
m["gender"] = "male";
m["age"] = "88 years old";
m["car"] = "benz";
for(map<string,string>::const_iterator iter = m.begin();
iter != m.end();iter++)
cout << iter->first << "-" << iter->second << endl;
return 0;
}















 160
160











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









