






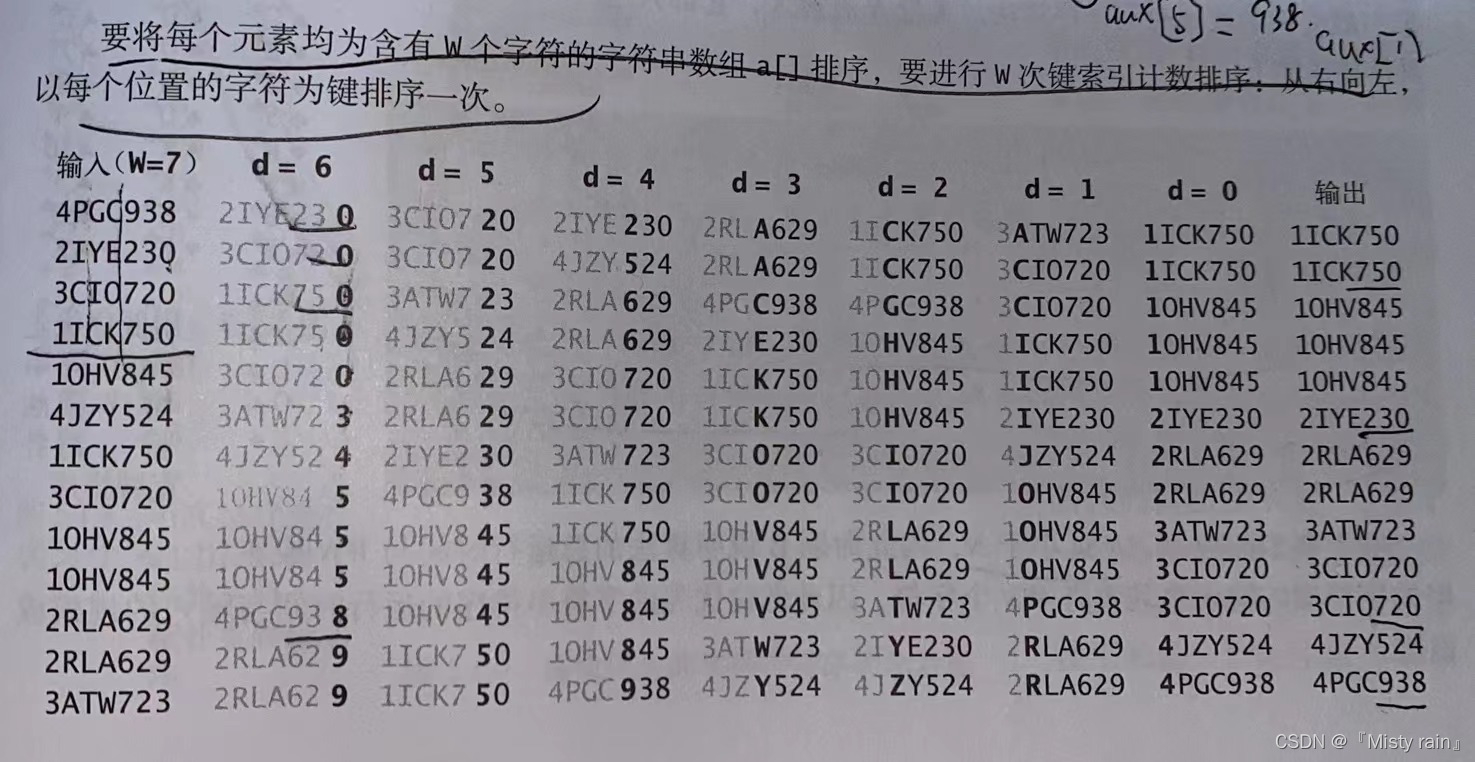
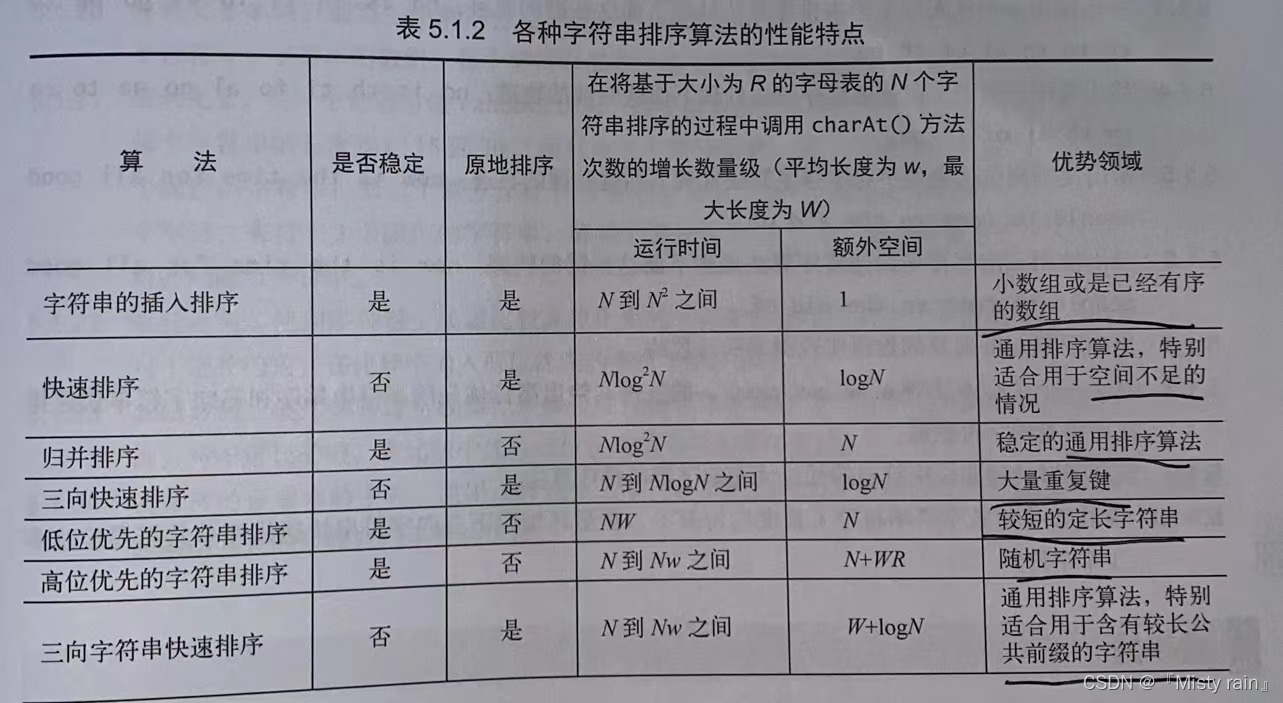
一:低位优先的字符串排序
低位优先算法会从右到左检查键(字符串)中的字符来完成字符串排序。这种算法适合用于键(字符串)的长度都相同的字符串排序,而且也是稳定的(依赖键索引计数法的实现)。
//基于键索引基数法的低位优先的字符串排序 public class LSD { public static void sort(String[] a, int w) { //通过前W个字符串a[]排序 int N = a.length; int R = 256; String[] aux = new String[N]; //从右向左开始遍历 for (int d = w - 1; d >= 0; d--) { //根据第d个字符用索引计数法排序 int[] count = new int[R + 1]; //计算出频率,每个字符出现的次数 for (int i = 0; i < N; i++) { count[a[i].charAt(d) + 1]++; } System.out.println(count); //将频率转化为索引 for (int r = 0; r < R; r++) { count[r + 1] += count[r]; } System.out.println(count); //将元素分类排序 for (int i = 0; i < N; i++) { aux[count[a[i].charAt(d)]++] = a[i]; } System.out.println(aux); //写回 for (int i = 0; i < N; i++) { a[i] = aux[i]; } System.out.println(a); } } }
二:高位优先的字符串排序
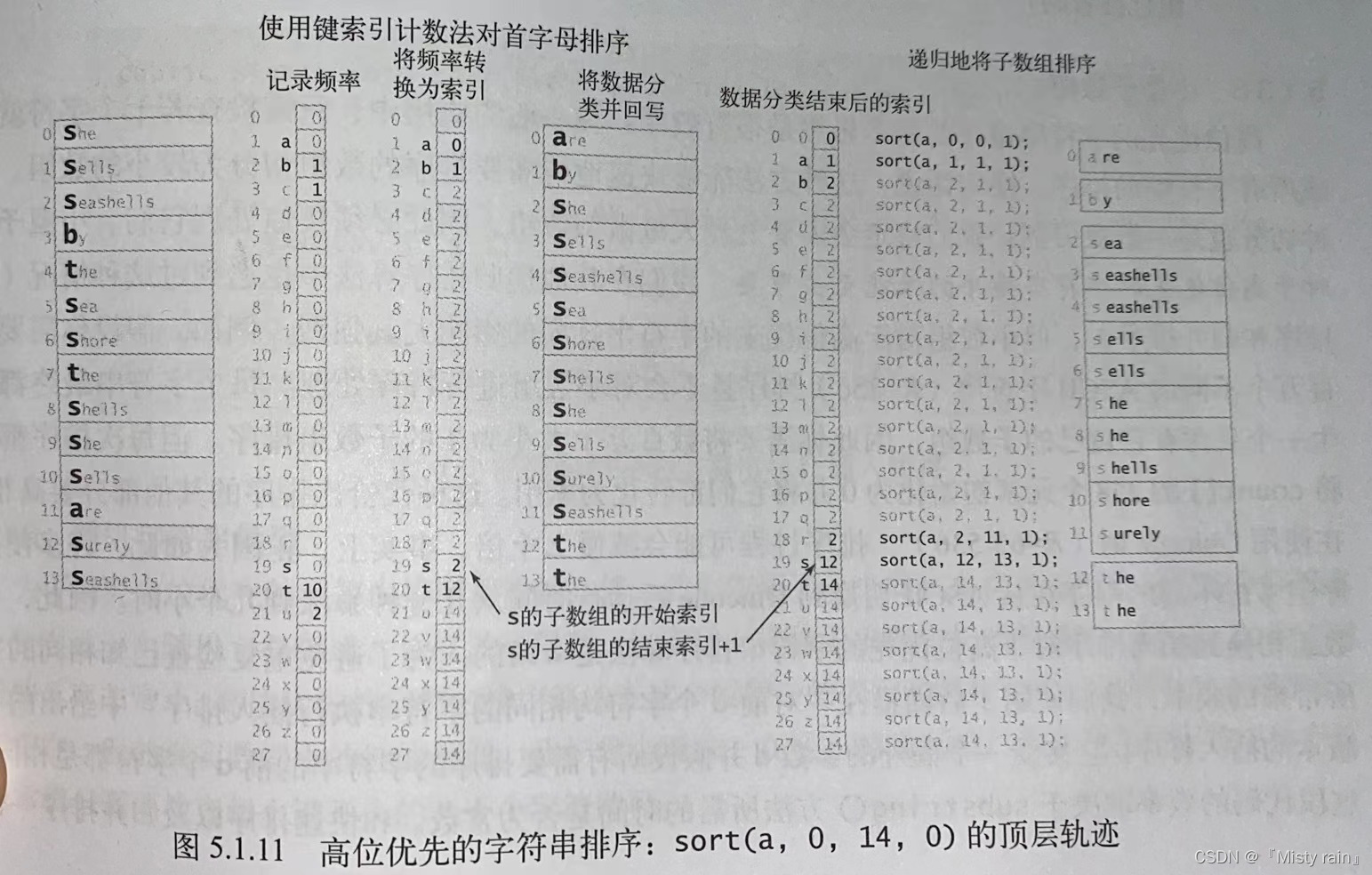
高位优先算法会从左到右检查键(字符串)中的字符来完成字符串排序。这种算法不一定需要检查所有的输入就能完成排序,而且是一个通用的排序算法,但不适合等值键较多的子数组且需要更多的额外空间。
将一个字符串数组a[ ]排序时,首先根据它们的首字母用键索引计数法进行排序,然后递归地根据子数组中的字符串的首字母将子数组排序。
//高位优先的字符串排序 public class MSD { private static int R = 256;//基数 private static final int M = 15;//小数组的切换阈值 private static String[] aux;//数据分类的辅助数组 private static int charAt(String s, int d) { if (d < s.length()) { return s.charAt(d); } else { return -1; } } public static void sort(String[] a) { int N = a.length; aux = new String[N]; sort(a, 0, N - 1, 0); } private static void sort(String[] a, int lo, int hi, int d) { //以第d个字符为键键a[lo]至a[hi]排序 if (hi <= lo + M) { //小数组进行插入排序,待实现,减少运行时间 Insertion.sort(a,lo,hi,d); return; } int[] count = new int[R + 2]; //计算频率 for (int i = lo; i <= hi; i++) { count[charAt(a[i], d) + 2]++; } //将频率转换为索引 for (int r = 0; r < R + 2; r++) { count[r + 1] = count[r]; } //数据分类排序 for (int i = lo; i < hi; i++) { aux[count[charAt(a[i], d) + 1]++] = a[i]; } //写回 for (int i = lo; i < hi; i++) { a[i] = aux[i - lo]; } //递归的以每个字符为键进行排序 for (int r = 0; r < R; r++) { sort(a, lo + count[r], lo + count[r + 1] - 1, d + 1); } } }三:三向字符串快速排序
三向字符串快速排序只将数组切分为三部分,它能够很好地处理等值键、有较长公共前缀的键、取值范围较小的键和小数组,这些都是高位优先算法存在的问题,同时它也不需要额外的空间。
//三向字符串快速排序 public class Quick3string { private static int charAt(String s, int d) { if (d < s.length()) { return s.charAt(d); } else { return -1; } } public static void sort(String[] a) { sort(a, 0, a.length - 1, 0); } private static void sort(String[] a, int lo, int hi, int d) { if (hi <= lo) { return; } int lt = lo; int gt = hi; int v = charAt(a[lo], d); int i = lo + 1; while (i <= gt) { int t = charAt(a[i], d); if (t < v) { exch(a, lt++, i++); } else if (t > v) { exch(a, i, gt--); } else { i++; } } sort(a, lo, lt - 1, d); if (v >= 0) { sort(a, lt, gt, d + 1); } sort(a, gt + 1, hi, d); } //第i个和第j个交换 public static void exch(String[] a, int i, int j) { String t = a[i]; a[i] = a[j]; a[j] = t; } }四:总结
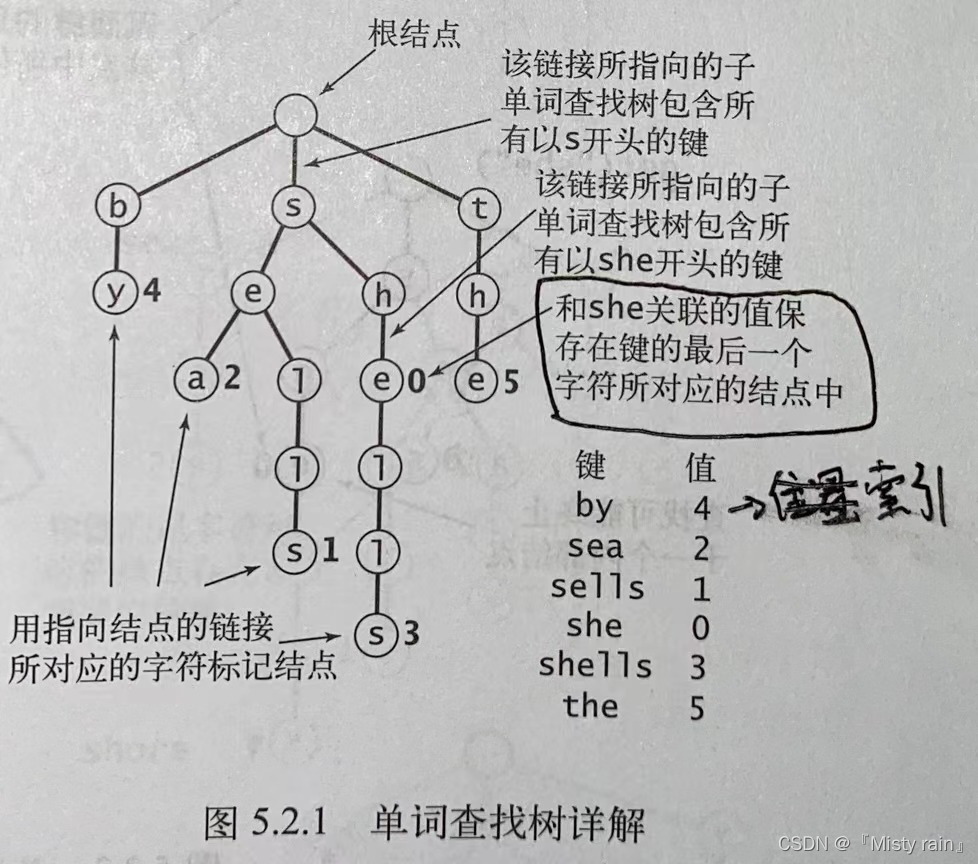
五:R向单词查找树
单词查找树是由链接的结点所组成的数据结构,每个结点最多有一个指向它的结点,称为它的父节点(除根结点外),每个结点含有R(字母表大小)条链接。
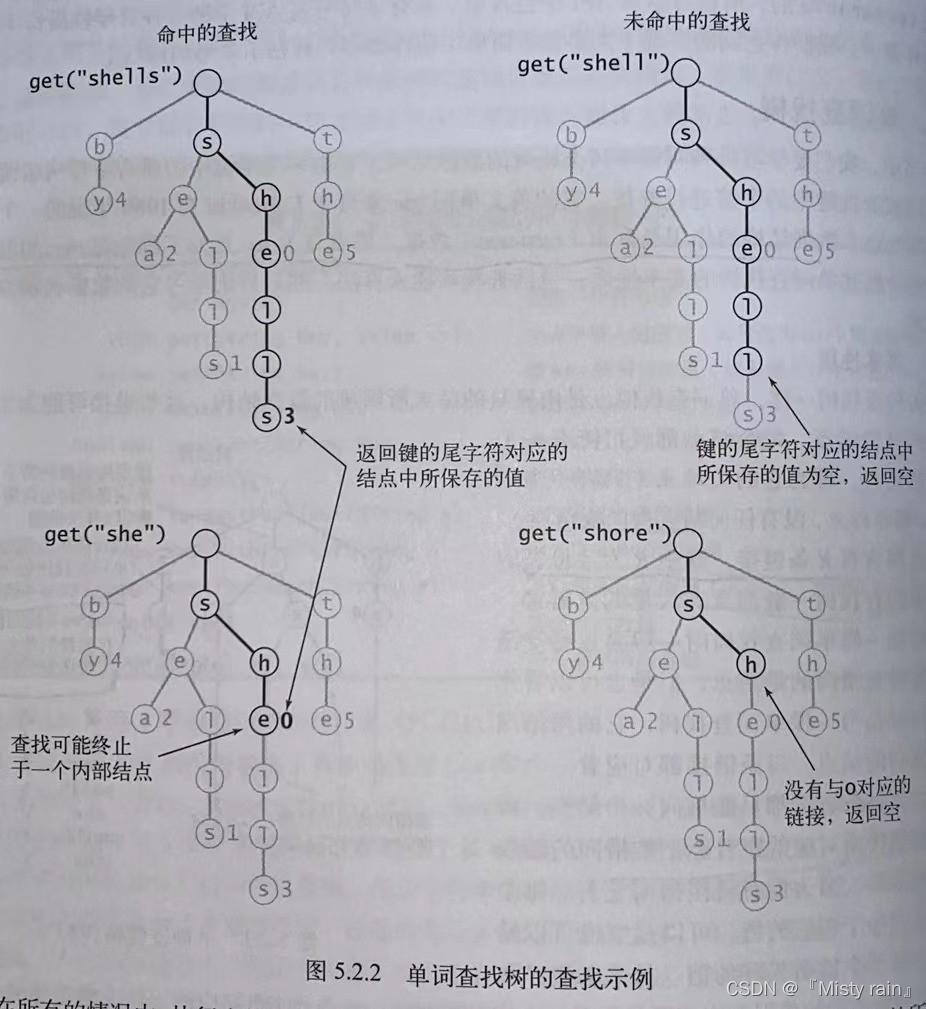
5.1 R向单词查找树中的查找操作
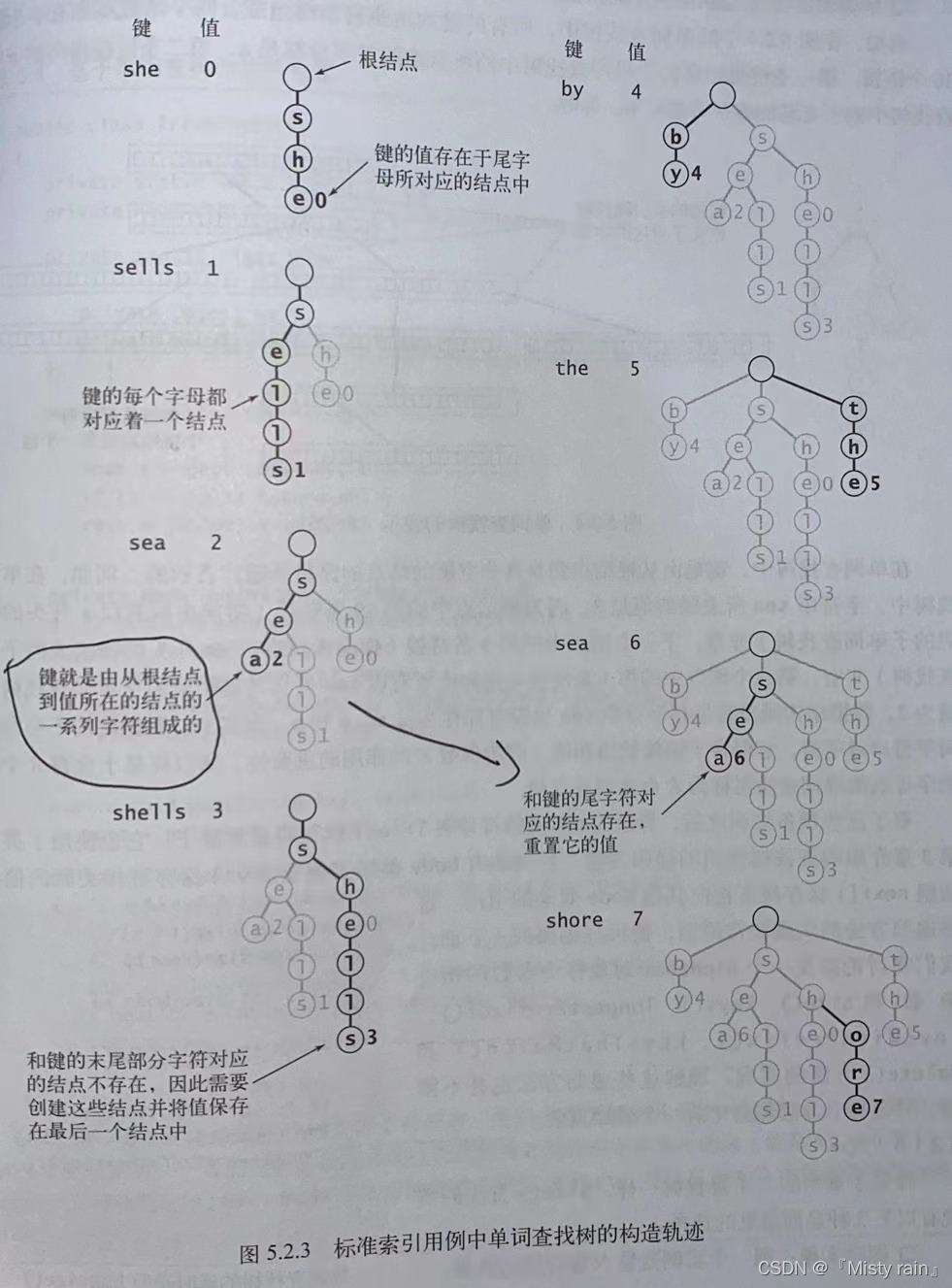
5.2 R向单词查找树中的插入操作
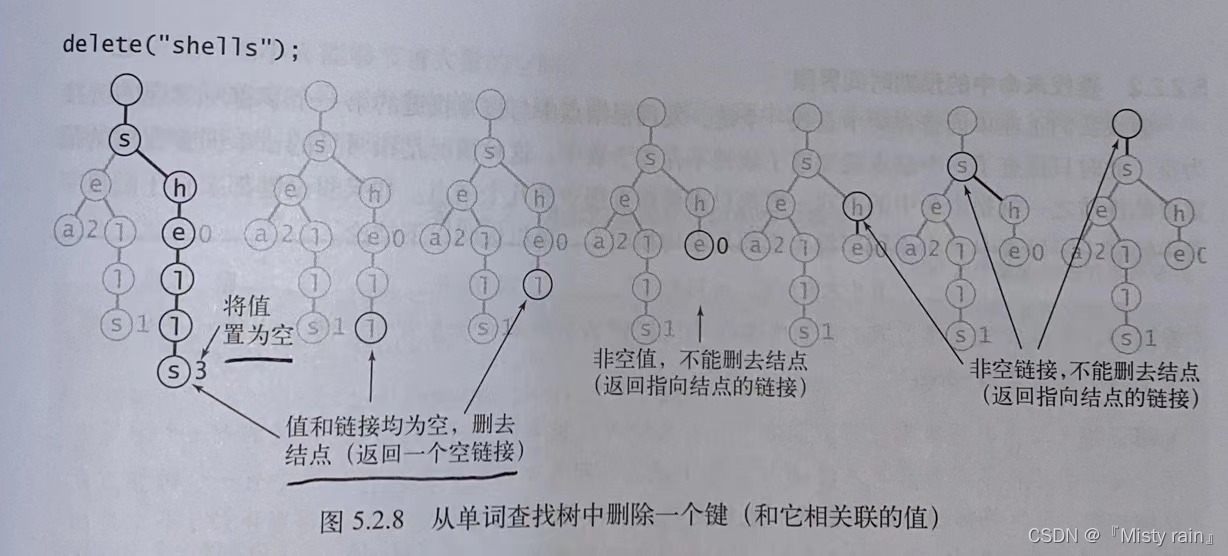
5.3 R向单词查找树中的删除操作
5.4 基于R向单词查找树的符号表的实现
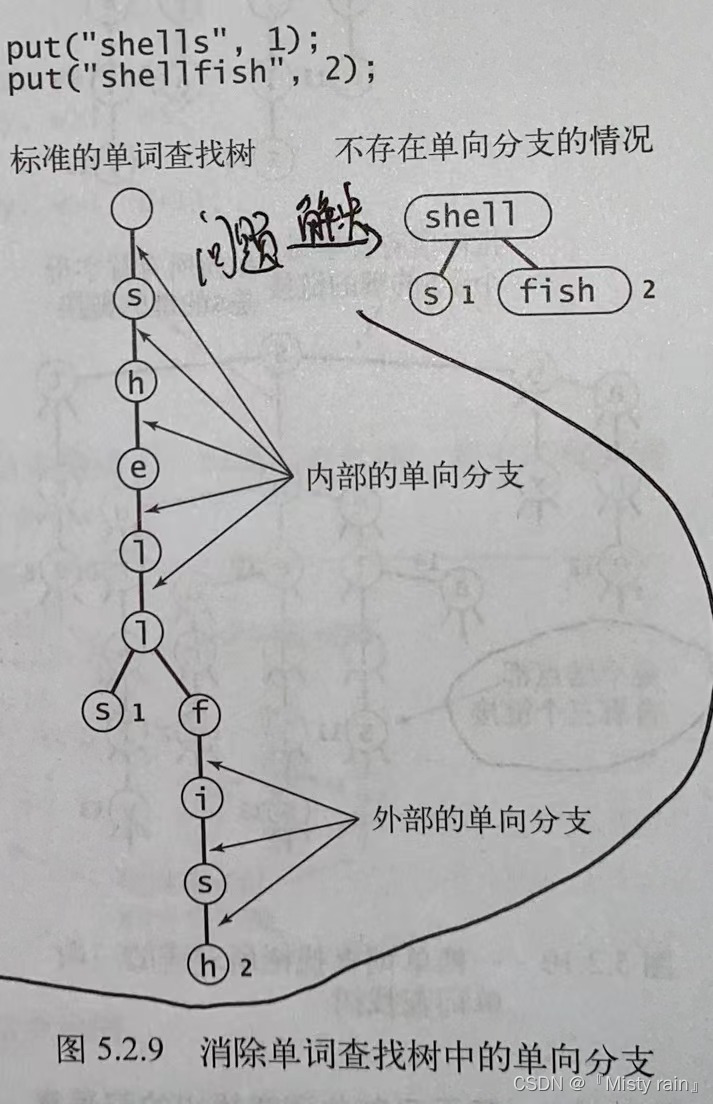
//基于单词查找树的符号表 public class TrieST<Value> { private static int R = 256;//基数 private Node root;//单词查找树的根结点 private static class Node { private Object val; private Node[] next = new Node[R]; } //键key所对应的值 public Value get(String key) { Node x = get(root, key, 0); if (x == null) { return null; } return (Value) x.val; } private Node get(Node x, String key, int d) { //返回以x作为根结点的子单词查找树中与key相关联的值 if (x == null) { return null; } if (d == key.length()) { return x; } char c = key.charAt(d);//找到第d个字符所对应的子单词查找树 return get(x.next[c], key, d + 1); } //向表中插入键值对 public void put(String key, Value val) { root = put(root, key, val, 0); } private Node put(Node x, String key, Value val, int d) { //如果key存在于以x为根结点的子单词查找树中则更新与它相关联的值 if (x == null) { return x = new Node(); } if (d == key.length()) { x.val = val; return x; } char c = key.charAt(d);//找到第d个字符所对应的子单词查找树 x.next[c] = put(x.next[c], key, val, d + 1); return x; } //键值对的数量 public int size() { return size(root); } private int size(Node x) { if (x == null) { return 0; } int cnt = 0; if (x.val != null) { cnt++; } for (char c = 0; c < R; c++) { cnt += size(x.next[c]); } return cnt; } //符号表中的所有键 public Iterable<String> keys() { return keysWithPrefix(""); } //所有以s为前缀的键 public Iterable<String> keysWithPrefix(String pre) { SynchronousQueue<String> q = new SynchronousQueue<>(); collect(get(root, pre, 0), pre, q); return q; } private void collect(Node x, String pre, SynchronousQueue<String> q) { if (x == null) { return; } if (x.val != null) { q.add(pre); } for (char c = 0; c < R; c++) { collect(x.next[c], pre + c, q); } } //所有和s匹配的键(其中.能够匹配任意字符) public Iterable<String> keysThatMatch(String s) { SynchronousQueue<String> q = new SynchronousQueue<>(); collect(root, "", s, q); return q; } private void collect(Node x, String pre, String s, SynchronousQueue<String> q) { int d = pre.length(); if (x == null) { return; } if (d == s.length() && x.val != null) { q.add(pre); } if (d == s.length()) { return; } char next = s.charAt(d); for (char c = 0; c < R; c++) { if (next == '.' || next == c) { collect(x.next[c], pre + c, s, q); } } } //s的前缀中最长的键 public String longestPrefixOf(String s){ int length = search(root,s,0,0); return s.substring(0,length); } private int search(Node x,String s,int d,int length){ if (x==null){return length;} if (x.val!=null){ length=d; } if (d==s.length()){ return length; } char c = s.charAt(d); return search(x.next[c],s,d+1,length); } //删除键key和它的值 public void delete(String key){ root = delete(root,key,0); } private Node delete(Node x,String key,int d){ if (x==null){return null;} if (d==key.length()){ x.val=null; }else { char c = key.charAt(d); x.next[c]=delete(x.next[c],key,d+1); } if (x.val!=null){return x;} for (char c = 0; c < R; c++) { if (x.next[c]!=null){return x;} } return null; } }5.4.1 解决单向分支问题:
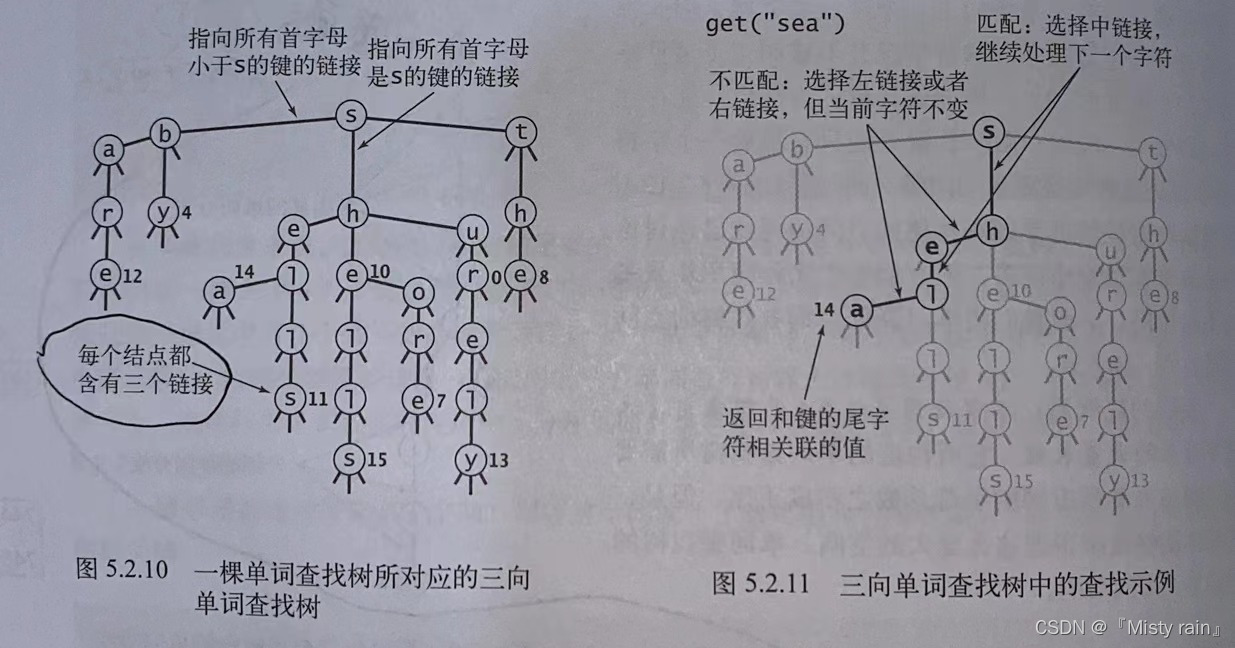
六:三向单词查找树
三向单词查找树避免了R向单词查找树过度的空间浪费,每个结点都含有一个字符、三条链接和一个值。这三条链接对应着小于、等于和大于当前字母的所有键。不必担心对特定应用场景的依赖,即使没有调优也可以有不错的性能。
6.1 基于三向单词查找树的符号表的实现
//基于三向单词查找树的符号表 public class TST<Value> { private Node root;//树的根结点 private class Node{ char c;//字符 Node left,mid,right;//左中右三向单词查找树 Value val;//和字符串相关联的值 } //键key所对应的值 public Value get(String key) { Node x = get(root, key, 0); if (x == null) { return null; } return (Value) x.val; } private Node get(Node x, String key, int d) { //返回以x作为根结点的子单词查找树中与key相关联的值 if (x == null) {return null;} char c = key.charAt(d); if (c<x.c){ return get(x.left,key,d); } else if (c>x.c) { return get(x.right,key,d); } else if (d<key.length()-1) { return get(x.mid,key,d+1); }else { return x; } } //插入键值对 public void put(String key,Value val){ root = put(root,key,val,0); } private Node put(Node x,String key,Value val,int d){ char c = key.charAt(d); if (x==null){ x = new Node(); x.c = c; } if (c<x.c){ x.left = put(x.left,key,val,d); }else if (c>x.c){ x.right=put(x.right,key,val,d); } else if (d<key.length()-1) { x.mid =put(x.mid,key,val,d+1); }else { x.val = val; } return x; } }七:如何选择字符串的符号表的实现
如果空间足够,R向单词查找树的速度最快。三向单词查找树是最佳选择。
八:子字符串查找
在这里暴露算法就不说了。
8.1 KMP子字符串查找算法
KMP算法不需要在输入中回退,适合在长度不确定的输入流中进行查找,下面的BM算法是对KMP的改进。
//KMP子字符串查找算法 public class KMP { private String pat;//子字符串 private int[][] dfa; public KMP(String pat){ //根据子字符串pat构造一个DFA this.pat = pat; int M = pat.length(); int R = 256; dfa = new int[R][M]; dfa[pat.charAt(0)][0] = 1; for (int X=0,j=1;j<M;j++){ //计算dfa[][j] for (int c = 0; c < R; c++) { dfa[c][j] = dfa[c][X];//复制匹配失败情况下的值 } dfa[pat.charAt(j)][j] = j+1;//设置匹配成功情况下的值 X = dfa[pat.charAt(j)][X];//更新重启状态 } } //在txt中查找pat字符串出现的位置 public int search(String txt){ //在txt上模拟DFA的运行 int i,j,N=txt.length(),M=pat.length(); for (i=0,j=0; i < N && j < M; i++){ j = dfa[txt.charAt(i)][j]; } //找到匹配 if (j==M){ return i-M; }else { //未找到匹配 return N; } } public static void main(String[] args) { Scanner scanner = new Scanner(System.in); String pat = scanner.nextLine(); String txt = scanner.nextLine(); KMP kmp = new KMP(pat); int offset = kmp.search(txt); for (int i = 0; i < offset; i++) { System.out.println(" "); } System.out.println(pat); } }8.2 BM子字符串查找算法
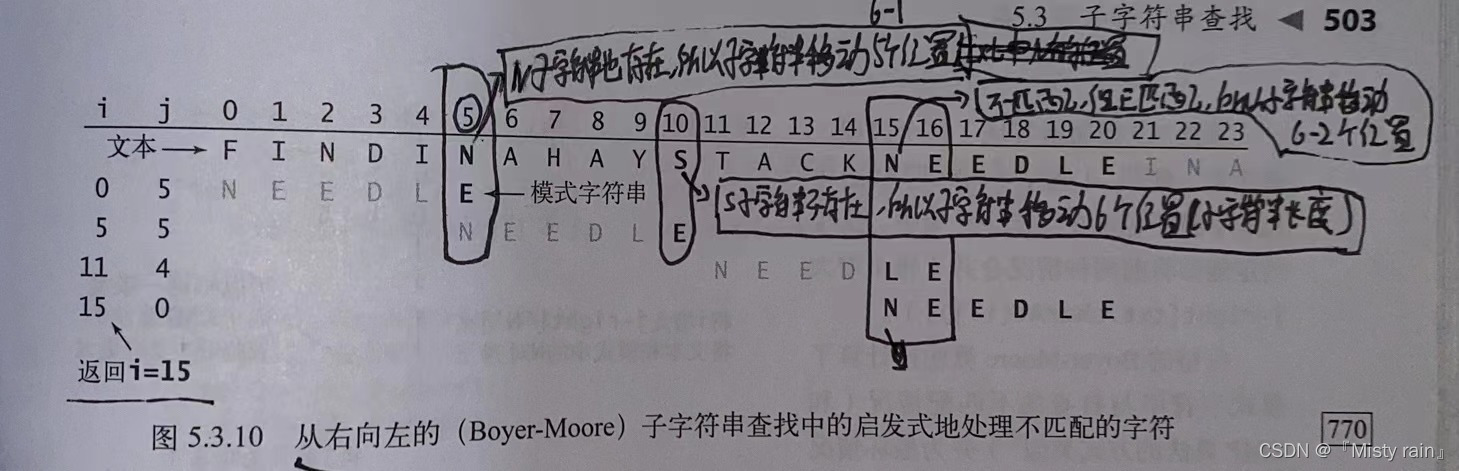
当可以在文本字符串中回退时,如果可以从右向左扫描子字符串并将它和文本匹配,那么性能就更好了。例如:在查找子字符串BAABBAA时,如果匹配了第七个和第六个字符,但是在第5个字符处匹配失败,那马上就可以将子字符串向右移动5个位置并继续检查文本中的第14个字符。BM算法就是会从右向开始扫描子字符串,并在匹配失败时通过跳跃将文本中的字符和它在子字符串中出现的最右位置对齐,
//BM子字符串查找 public class BM { private int[] right; private String pat;//子字符串 public BM(String pat) { //计算跳跃表 this.pat = pat; int M = pat.length(); int R = 256; right = new int[R]; for (int c = 0; c < R; c++) { right[c] = -1;//不包含在子字符串中的字符的值未为-1 } for (int j = 0; j < M; j++) { //包含在字符串中的字符的值为它在其中出现的最右位置 right[pat.charAt(j)] = j; } } public int search(String txt) { //在txt查找子字符串 int N = txt.length(); int M = pat.length(); int skip; for (int i = 0; i < N - M; i += skip) { //子字符串和文本在位置i匹配吗 skip = 0; for (int j = M - 1; j >= 0; j--) { if (pat.charAt(j) != txt.charAt(i + j)) { skip = j - right[txt.charAt(i + j)]; if (skip < 1) { skip = 1; } break; } } if (skip == 0) { return i;//找到匹配的了 } } return N;//为找到匹配的 } public static void main(String[] args) { Scanner scanner = new Scanner(System.in); String pat = scanner.nextLine(); String txt = scanner.nextLine(); BM bm = new BM(pat); int offset = bm.search(txt); for (int i = 0; i < offset; i++) { System.out.println(" "); } System.out.println(pat); } }8.3 RK指纹字符串查找算法
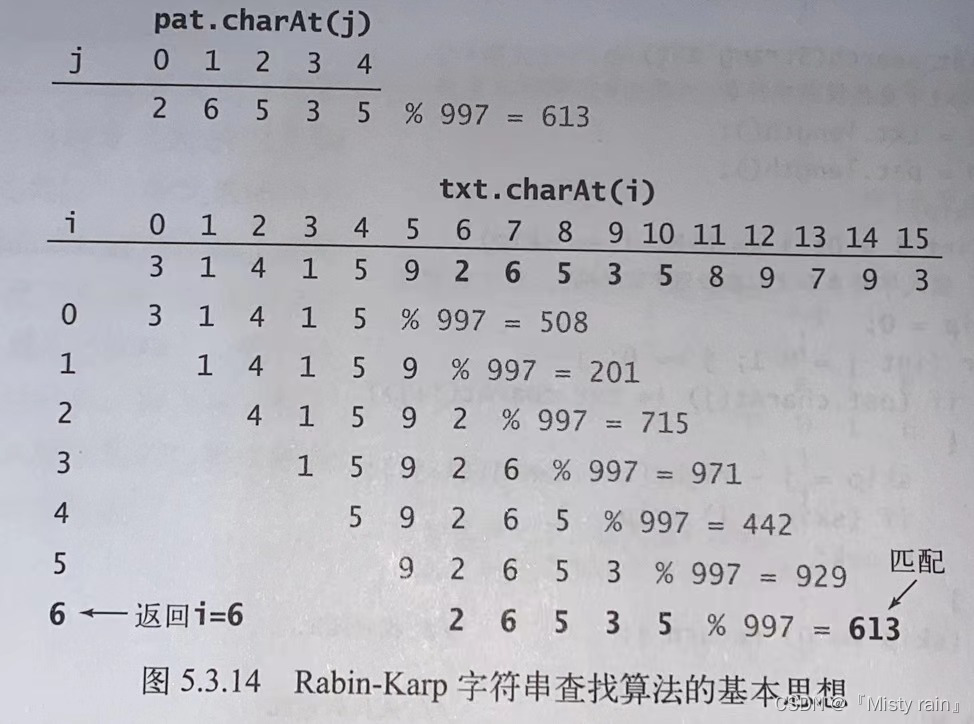
RK算法时一种基于散列(需预处理)的字符串查找算法。假设在文本314159265358中寻找26535,先确定散列表的大小997,子字符串来取余26535%997=613,然后计算文本所有长度为5的子字符串的散列值。
//RK指纹字符串查找算法 public class RK { private String pat;//子字符串(仅拉斯维加斯算法需要) private long patHash;//子字符串的散列值 private int M;//子字符串的长度 private long Q;//一个很大的素数 private int R = 256;//字母表大小 private long RM;//R^(M-1)%Q public RK(String pat) { this.pat = pat;//保存子字符串(仅拉斯维加斯算法需要) this.M = pat.length(); Q = 997; RM = 1; //计算R^(M-1)%Q for (int i = 1; i < M - 1; i++) { //用于减去第一个数字时的计算 RM = (R * RM) % Q; } patHash = hash(pat, M); } private long hash(String key, int M) { //计算key[0..M-1]的散列值 long h = 0; for (int i = 0; i < M; i++) { h = (R * h + key.charAt(i)) % Q; } return h; } private int search(String txt) { //在文本中查找相等的散列值 int N = txt.length(); long txtHash = hash(txt, M); if (patHash == txtHash) { return 0;//一开始就匹配成功 } for (int i = M; i < N; i++) { //减去第一个数字,加上最后一个数字,再次检查匹配 txtHash = (txtHash + Q - RM * txt.charAt(i - M) % Q) % Q; txtHash = (txtHash * R + txt.charAt(i)) % Q; if (patHash == txtHash) { return i - M + 1; } } return N; } }8.4 总结
暴力查找算法的实现简单且一般情况下良好。
KMP算法能够保证线性级别的性能且不需要在正文中回退。
BM算法的性能一般情况下都是亚线性级别。
RK算法是线性级别。
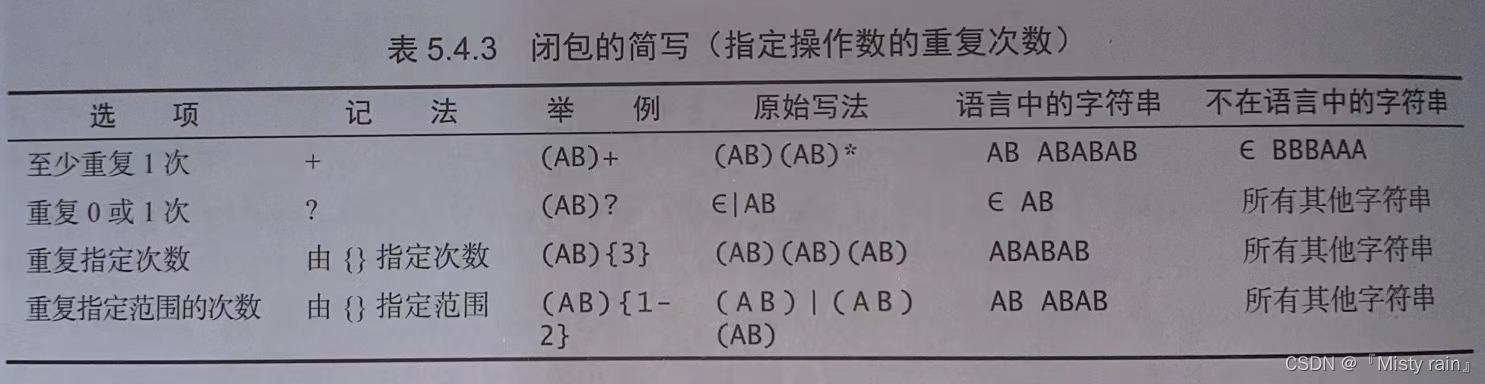
九:正则表达式
(A|B)*表示由A和B构成的所有字符串的集合,包括空、无A、无B。
.*表示任意字符任意次数。
9.1 正则表达式所对应的NFA实现:
//正则表达式的子字符串匹配 public class NFA { private char[] re;//匹配转换(正则表达式) private Digraph G; private int M;//状态数量(正则表达式长度) //构造NFA public NFA(String regexp) { //根据给定的正则表达式regexp构造NFA Stack<Integer> ops = new Stack<>(); re = regexp.toCharArray(); M = re.length; G = new Digraph(M + 1); for (int i = 0; i < M; i++) { int lp = i; if (re[i] == '(' || re[i] == '|') { ops.push(i); } else if (re[i] == ')') { int or = ops.pop(); if (re[or] == '|') { lp = ops.pop(); G.addEdge(lp, or + 1); G.addEdge(or, i); } else { lp = or; } } if (i < M - 1 && re[i + 1] == '*') { //查看下一个字符 G.addEdge(lp, i++); G.addEdge(i + 1, lp); } if (re[i] == '(' || re[i] == '*' || re[i] == ')') { G.addEdge(i, i + 1); } } } //NFA的正则表达式匹配 public boolean recognizes(String txt) { //NFA是否能识别文本txt Fundamental.Bag<Integer> pc = new Fundamental.Bag<>(); DirectedDFS dfs = new DirectedDFS(G, 0); for (int v = 0; v < G.V(); v++) { if (dfs.marked(v)) { pc.add(v); } } for (int i = 0; i < txt.length(); i++) { //计算txt[i+1]可能达到的所有NFA状态 Fundamental.Bag<Integer> match = new Fundamental.Bag<>(); for (Integer v : pc) { if (v < M) { if (re[v] == txt.charAt(i) || re[v] == '.') { match.add(v + 1); } } } pc = new Fundamental.Bag<Integer>(); dfs = new DirectedDFS(G, match); for (int v = 0; v < G.V(); v++) { if (dfs.marked(v)) { pc.add(v); } } } for (Integer v : pc) { if (v == M) { return true; } } return false; } public static void main(String[] args) { Scanner scanner = new Scanner(System.in); String regexp = "(.*" + scanner.nextLine() + ".*)"; NFA nfa = new NFA(regexp); while (scanner.hasNextLine()){ String txt = scanner.nextLine(); if (nfa.recognizes(txt)){ System.out.println(txt); } } } }十:数据压缩
接下来学习的压缩算法适合拥有下面一种或多种特点的数据:
①小规模的字母表;
②较长的连续相同的位或字符;
③频繁使用的字符;
④较长的连续重复的位或字符;
10.1 双位编码压缩算法
10.2 游程编码压缩算法
10.3 霍夫曼压缩算法
霍夫曼算法思想是用较少的比特表示出现频率高的字符,用较多的比特表示出现频率低的字符,来节省空间。不适合对字符的频率均匀分布的、字符冗余的、数据规模小的、动态数据的压缩。为了满足算法要求,我们需要变长前缀码,使之所有字符编码都不会成为其他字符编码的前缀。
前缀码的单词查找树:
构造霍夫曼二叉树【最优的前缀码】的过程:
首先找到两个频率最小的结点,然后创建一个以二者为子结点的新结点(新结点的频率值为它的两个子结点的频率值之和),不断重复此过程。使用优先队列可轻易实现此过程。
//霍夫曼压缩算法 public class Huffman { private static class Node implements Comparable<Node> { //霍夫曼单词查找树中的结点 private char ch;//字符,内部结点不会使用该变量 private int freq;//字符频率,展开过程不会使用该变量 private Node left, right; Node(char ch, int freq, Node left, Node right) { this.ch = ch; this.freq = freq; this.left = left; this.right = right; } public boolean isLeaf() { return left == null && right == null; } @Override public int compareTo(Node that) { return this.freq - that.freq; } } private static int R = 256;//ASCII字母表 //前缀码的展开(解码) private static void expand() { Node root = readTrie(); Scanner scanner = new Scanner(System.in); int N = scanner.nextInt(); for (int i = 0; i < N; i++) { //展开第i个编码所对应的字母 Node x = root; while (!x.isLeaf()) { if (scanner.nextBoolean()) { x = x.right; } else { x = x.left; } } System.out.println(x.ch); } } //从比特流的前序表示中重建单词查找树 private static Node readTrie() { Scanner scanner = new Scanner(System.in); if (scanner.nextBoolean()) { return new Node(scanner.nextLine().charAt(0), 0, null, null); } return new Node('\0', 0, readTrie(), readTrie()); } //通过前缀码字典查找树构建编译表 private static String[] buildCode(Node root) { //使用单词查找树构造编译表 String[] st = new String[R]; buildCode(st, root, ""); return st; } private static void buildCode(String[] st, Node x, String s) { //递归 if (x.isLeaf()) { st[x.ch] = s; return; } buildCode(st, x.left, s + '0'); buildCode(st, x.right, s + '1'); } //构造一棵霍夫曼编码单词查找树 private static Node buildTrie(int[] freq) { //使用多棵单结点树初始化优先队列 MinHeapIndexPriorityQueue<Node> pq = new MinHeapIndexPriorityQueue<Node>(); for (char c = 0; c < R; c++) { if (freq[c] > 0) { pq.insert(pq.size(), new Node(c, freq[c], null, null)); } } while (pq.size() > 1) { //合并两棵频率最小的树 Node x = pq.deleteMin(); Node y = pq.deleteMin(); Node parent = new Node('\0', x.freq + y.freq, x, y); pq.insert(pq.size(), parent); } return (Node) pq.deleteMin(); } //使用前序遍历将单词查找树写为比特字符串 private static void writeTrie(Node x){ //输出单词查找树的比特字符串 if (x.isLeaf()){ System.out.println(true); System.out.println(x.ch); return; } System.out.println(false); writeTrie(x.left); writeTrie(x.right); } //压缩数据 public static void compress() { Scanner scanner = new Scanner(System.in); String s = scanner.nextLine(); char[] input = s.toCharArray(); //统计频率 int[] freq = new int[R]; for (int i = 0; i < input.length; i++) { freq[input[i]]++; } //构造霍夫曼编码树 Node root = buildTrie(freq); //递归构造编译表 String[] st = new String[R]; buildCode(st,root,""); //前序遍历递归打印编码用的单词查找树 writeTrie(root); //打印字符总数 System.out.println(input.length); //使用霍夫曼编码处理输入 for (int i = 0; i < input.length; i++) { String code = st[input[i]]; for (int j = 0; j < code.length(); j++) { if (code.charAt(j)=='1'){ System.out.println(true); }else { System.out.println(false); } } } } }10.4 LZW压缩算法
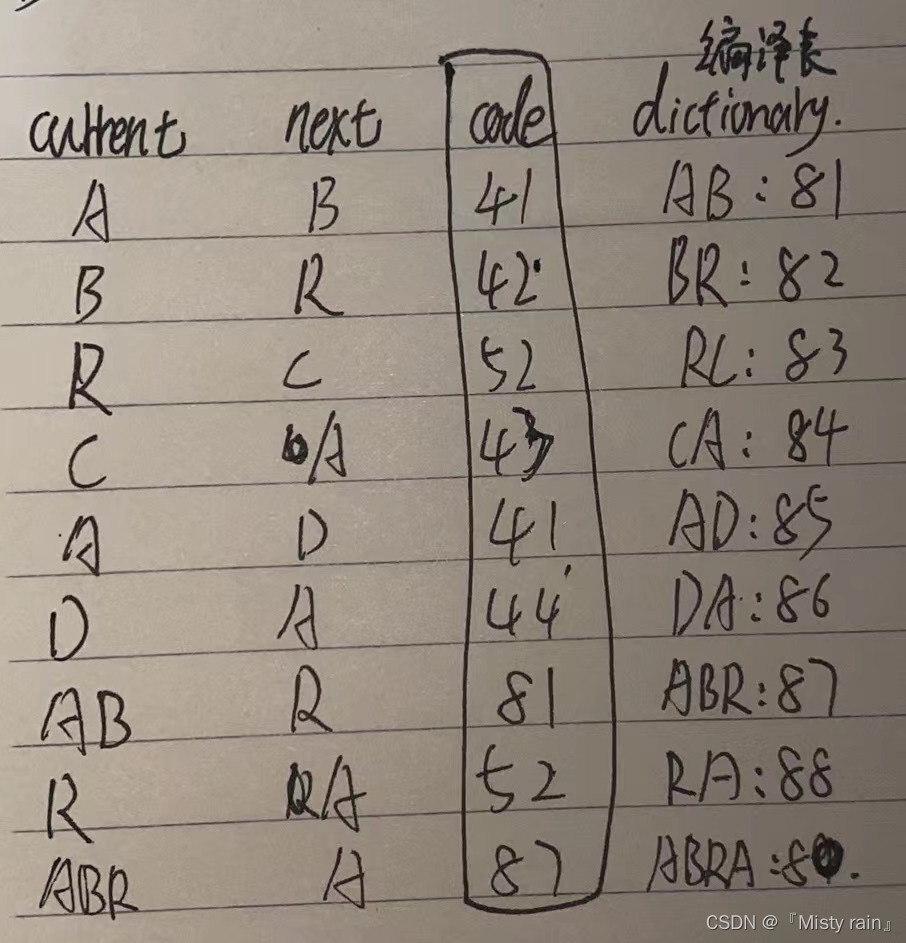
LZW算法维护一张字符串键和定长编码的编译表。举个列子:ASCII的A的编码为41,R的编码为52...,将80作为文件结束的标志并将其余编码值81--FF分配给其他子字符串。压缩ABRCADABRABRA。
//LZW算法 public class LZW { private static final int R = 256;//输入字符数 private static final int L = 4096;//编码总数2^12 private static final int W = 12;//编码宽度 public static void compress() { Scanner scanner = new Scanner(System.in); String input = scanner.nextLine(); //三向单词查找树 TST<Integer> st = new TST<>(); for (int i = 0; i < R; i++) { st.put("" + (char) i, i); } int code = R + 1;//R作为文件结束的编码 while (input.length() > 0) { String s = st.longestPrefixOf(input);//找到匹配的最长前缀 System.out.println(st.get(s) + ":" + W);//打印出s的编码 int t = s.length(); if (t<input.length()&&code<L){ //将s加入符号表 st.put(input.substring(0,t+1),code++); } input = input.substring(t);//从输入中读取s } System.out.println(R+":"+W);//输出文件结束标志 } public static void expand(){ String[] st = new String[L]; int i;//下一个待补全的编码值 //用字符初始化编译表 for ( i = 0; i < R; i++) { st[i] = "" +(char)i; } st[i++]=" ";//文件结束标准的前瞻字符 Scanner scanner = new Scanner(System.in); int codeword=scanner.nextInt(); String val = st[codeword]; while (true){ System.out.println(val);//输出当前字符串 codeword = scanner.nextInt(); if (codeword==R){ break; } String s = st[codeword];//获取下一个编码 if (i==codeword){//如果前瞻字符不可用 s=val+val.charAt(0);//根据上一个字符串的首字母得到编码的字符串 } if (i<L){ st[i++]=val+s.charAt(0);//为编译表添加新的条目 } val=s;//更新当前的编码值 } } }










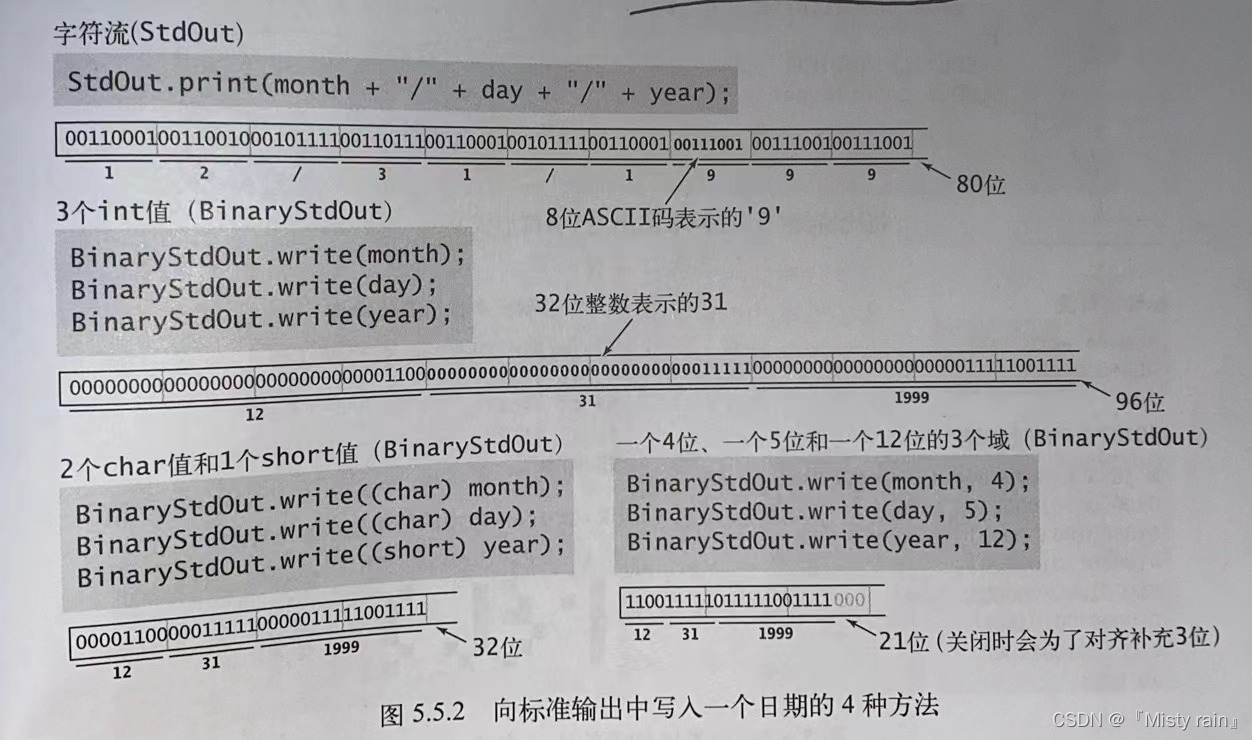




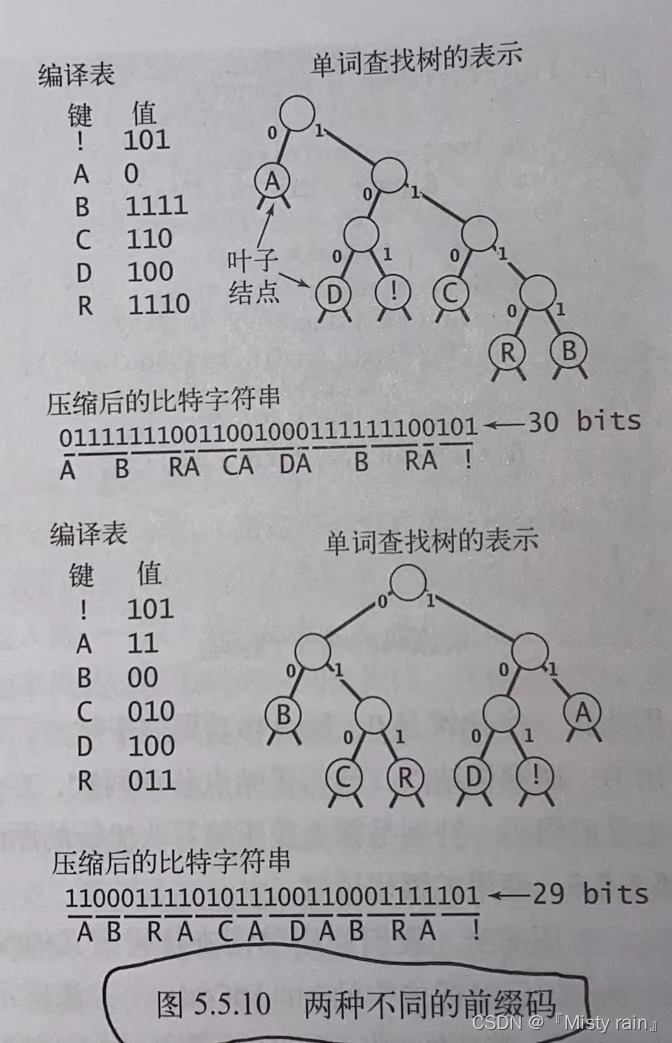
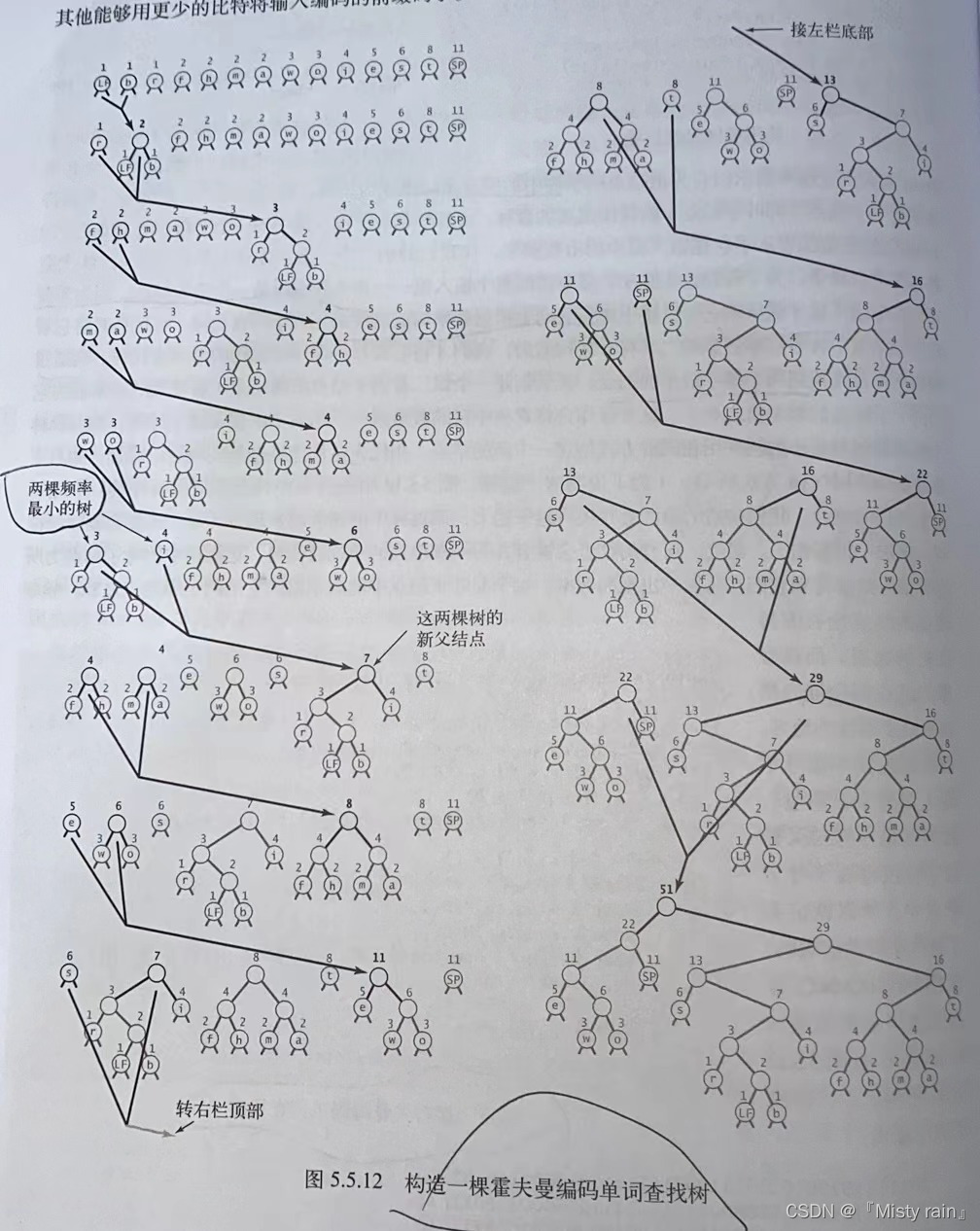
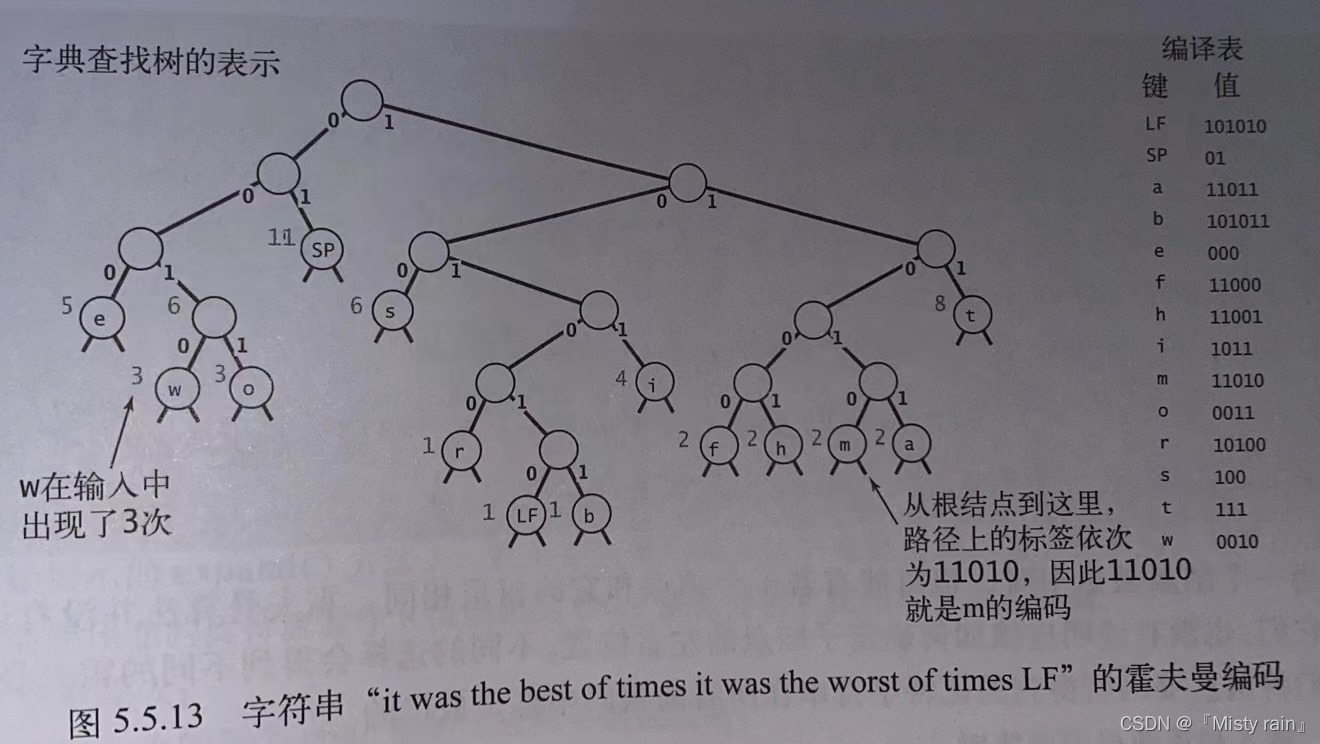















 8177
8177











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









