






使用下面这种方式,解压出来都是乱码,显示不出正确的中文字符
import zipfile
with zipfile.ZipFile('../zip/归档.zip', 'r') as zip_ref:
temp_dir = 'temp_datas'
zip_ref.extractall(temp_dir)
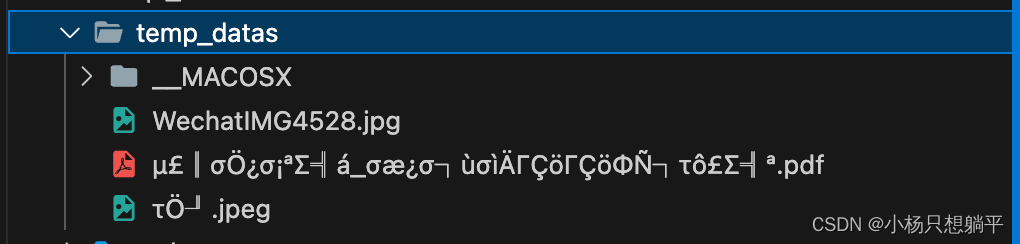
使用decode方法,解码目标使用
utf-8,使用ignore忽略无法解码的字符
import zipfile
import os
def unzip(zip_path, extract_path):
with zipfile.ZipFile(zip_path, 'r') as zip_ref:
for file_info in zip_ref.infolist():
# 使用原始的文件名
filename_raw = file_info.filename
# 使用 UTF-8 编解码文件名
filename_decoded = filename_raw.encode('cp437').decode('utf-8', 'ignore')
# 构建解压路径
extract_filepath = os.path.join(extract_path, filename_decoded)
# 创建目录(如果不存在)
os.makedirs(os.path.dirname(extract_filepath), exist_ok=True)
# 解压文件
with zip_ref.open(file_info, 'r') as file_in_zip, open(extract_filepath, 'wb') as extracted_file:
extracted_file.write(file_in_zip.read())
zip_path = '../zip/归档.zip'
extract_path = '../temp_datas'
unzip(zip_path, extract_path)
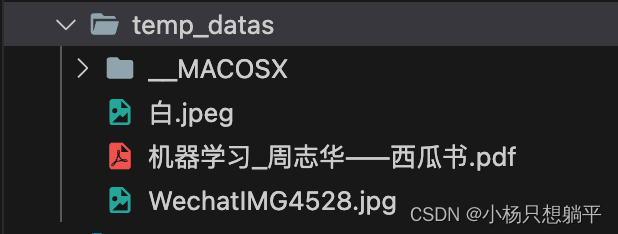
以下是我的需求逻辑:解压用户上传的文件,并进行分类存储。供参考
get_file_dir这个方法看用户上传的是什么类型的文件,返回一个目录文件名
import os
import shutil
from pathlib import Path
import zipfile
import streamlit as st
def zip_fiels_upload(zip_file):
# 获取脚本所在目录
script_dir = os.path.dirname(os.path.abspath(__file__))
temp_dir = os.path.join(script_dir, 'temp_datas')
with zipfile.ZipFile(zip_file, 'r') as zip_ref:
# 排除特殊系统文件夹
valid_files = [info for info in zip_ref.infolist() if '__MACOSX/' not in info.filename]
# 是否含有文件夹
nested_directories = any('/' in file_info.filename for file_info in valid_files)
if nested_directories:
st.warning(':red[压缩包文件格式错误,请将所有文件都放在一级目录下]')
else:
for file_info in valid_files:
# 使用原始的文件名
filename_raw = file_info.filename
# 使用 UTF-8 编解码文件名
filename_decoded = filename_raw.encode('cp437').decode('utf-8', 'ignore')
# 构建解压路径
extract_filepath = os.path.join(temp_dir, filename_decoded)
# 创建目录(如果不存在)
os.makedirs(os.path.dirname(extract_filepath), exist_ok=True)
# 解压文件
with zip_ref.open(file_info, 'r') as file_in_zip, open(extract_filepath, 'wb') as extracted_file:
extracted_file.write(file_in_zip.read())
get_files_content(temp_dir)
# 根据临时目录,移动文件到对应的目录下
def get_files_content(temp_dir):
for file_name in os.listdir(temp_dir):
file_path = os.path.join(temp_dir, file_name) # 要移动的文件路径
file_type = Path(file_name).suffix.lower()
target_subdir = get_file_dir(file_type) # 要保存在哪个目录下
if target_subdir:
target_full_path = os.path.join(project_dir, target_subdir, file_name) # 完整的存储目录
shutil.move(file_path, target_full_path) # 移动文件
shutil.rmtree(temp_dir) # 删除临时目录
# 将分类好的列表保存起来
if file_name not in st.session_state.files_list[target_subdir]:
st.session_state.files_list[target_subdir].append(file_name)
else:
st.warning(f'无法识别文件 "{file_name}" 的类型或没有对应的子目录。')
这里我忽略了系统文件夹,不需要解压















 3030
3030











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









