






多层前馈网络与误差反传算法
多层感知机
概念介绍
最简单的深度网络称为多层感知机。多层感知机由多层神经元组成,每一层与它的上一层相连,从中接收输入;同时每一层也与它的下一层相连,影响当前层的神经元。
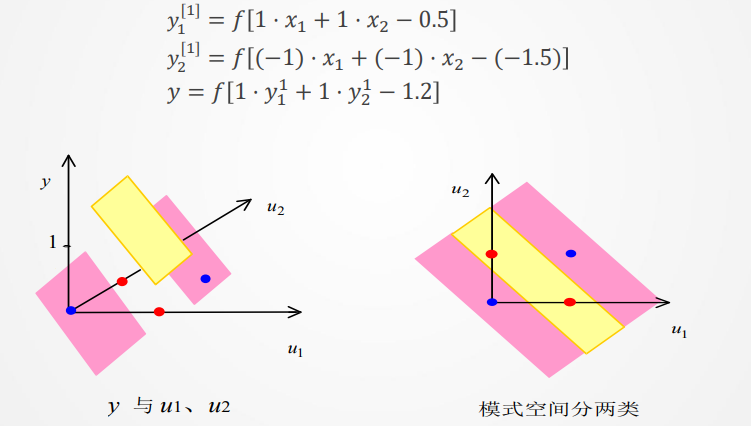
问题提出:明斯基1969年提出XOR问题,无法进行线性分类。
解决方法:使用多层感知机,在输入和输出层间加一或多层隐单元,构成多层感知器(多层前馈神经网络)。加一层隐节点(单元)为三层网络,可解决异或(XOR)问题由输入得到两个隐节点、一个输出层节点的输出。
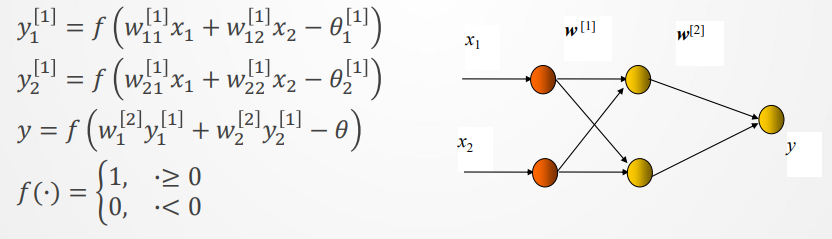
可得
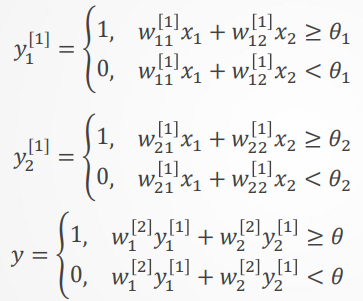
设网络有如下一组权值和阈值,可得各节点的输出:
多层感知器网络定理:
定理1:若隐层节点(单元)可任意设置,用三层阈值节点的网络,可以实现任意的二值逻辑函数。
定理2:若隐层节点(单元)可任意设置,用三层S型非线性特 性节点的网络,可以一致逼近紧集上的连续函数或按范数逼近紧集上的平方可积函数。
简单实现
使用Fashion‐MNIST图像分类数据集(摘自《动手学深度学习》4.2节 参考书链接见最后)
import torch
from torch import nn
from d2l import torch as d2l
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)初始化模型参数
Fashion‐MNIST中的每个图像由 28 × 28 = 784个灰度像素值组成。所有图像共分为10个类别。忽 略像素之间的空间结构,我们可以将每个图像视为具有784个输入特征和10个类的简单分类数据集。首先,我 们将实现一个具有单隐藏层的多层感知机,它包含256个隐藏单元。注意,我们可以将这两个变量都视为超参数。通常,我们选择2的若干次幂作为层的宽度。因为内存在硬件中的分配和寻址方式,这么做往往可以在计算上更高效。
用几个张量来表示我们的参数。对于每一层都记录一个权重矩阵和一个偏置向量。
num_inputs, num_outputs, num_hiddens = 784, 10, 256
W1 = nn.Parameter(torch.randn(
num_inputs, num_hiddens, requires_grad=True) * 0.01)
b1 = nn.Parameter(torch.zeros(num_hiddens, requires_grad=True))
W2 = nn.Parameter(torch.randn(
num_hiddens, num_outputs, requires_grad=True) * 0.01)
b2 = nn.Parameter(torch.zeros(num_outputs, requires_grad=True))
params = [W1, b1, W2, b2]激活函数
为了确保我们对模型的细节了如指掌,我们将实现ReLU激活函数,而不是直接调用内置的relu函数。
def relu(X):
a = torch.zeros_like(X)
return torch.max(X, a)模型
使用reshape将每个二维图像转换为一个长度为num_inputs的向量。
def net(X):
X = X.reshape((-1, num_inputs))
H = relu(X@W1 + b1) # 这里“@”代表矩阵乘法
return (H@W2 + b2)损失函数
直接使用高级API中的内置函数来计算softmax和交叉熵损失。
loss = nn.CrossEntropyLoss(reduction='none')训练
直接调用d2l包的train_ch3函数,将迭代周期数设置为10,并将学习率设置为0.1。
num_epochs, lr = 10, 0.1
updater = torch.optim.SGD(params, lr=lr)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, updater)结果
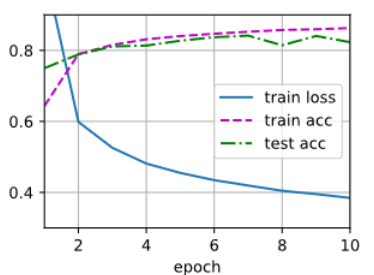
对学习到的模型进行评估,我们将在一些测试数据上应用这个模型。
d2l.predict_ch3(net, test_iter)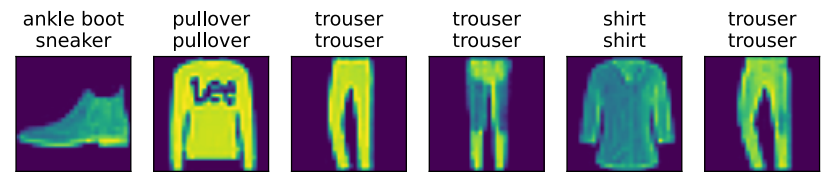
BP算法
概念介绍
多层感知机是一种多层前馈网络,由多层神经网络构成,每层网络将输出传递给下一层网络。神经元间的权值连接仅出现在相邻层之间,不出现在其他位置。如果每一个神经元都连接到上一层的所有神经元 (除输入层外),则成为全连接网络。下面讨论的都是此类网络。
多层前馈网络的反向传播 (BP)学习算法,简称BP算法,是有导师的学习,它是梯度下降法在多层前馈网中的应用。
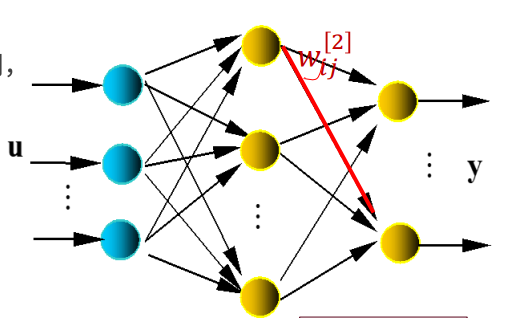
网络结构:𝐮(或𝐱 )、𝐲是网络的输入、输出向量,神经元用节点表示,网络由输入层、隐层和输出层节点组成,隐层可一层 ,也可多层(图中是单隐层),前层至后层节点通过权联接。由于用BP学习算法,所以常称BP神经网络。由正向传播和反向传播组成。已知网络的输入/输出样本,即导师信号。
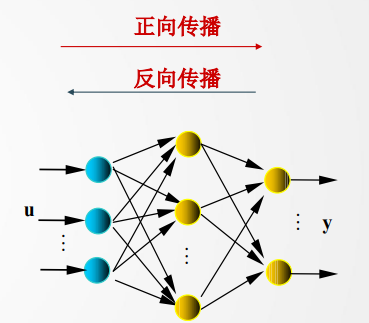
①正向传播是输入信号从输入层经隐层,传向输出层,若输出层得到了期望的输出, 则学习算法结束;否则,转至反向传播。
②反向传播是将误差(样本输出与网络输出之差)按原联接通路反向计算,由梯度下降法调整各层节点的权值和阈值,使误差减小。
基本思想:学习过程由信号的正向传播与误差的反向传播两个过程组成。正向传播时,输入样本从输入层传入,经各隐层逐层处理后,传向输出层。若输出层的实际输出与期望的输出(教师信号)不符,则转入误差的反向传播阶段。误差反传是将输出误差以某种形式通过隐层向输入层逐层反传,并将误差分摊给各层的所有单元,从而获得各层单元的误差信号,此误差信号即作为修正各单元权值的依据。这种信号正向传播与误差反向传播的各层权值调整过程,是周而复始地进行的。权值不断调整的过程,也就是网络的学习训练过程。此过程一直进行到网络输出的误差减少到可接受的程度,或进行到预先设定的学习次数为止。
计算过程:
①设置初始权系数为较小的随机非零值。
②给定输入/输出样本对,计算网络输出,完成前向传播。
③计算目标函数。如果
,则训练成功,退出;否则转入④
④反向传播计算由输出层,按梯度下降法将误差反向传播,逐层调整权值。
算法推导
前向传播
考虑二层神经网络(有一层隐含层)。对于当前样本,隐含层输出:对于第层第
个神经元,其输出:
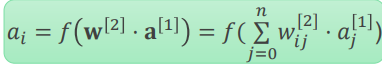
在输出端计算误差:
要计算:
误差反传——输出层
首先考虑输出层权值w。根据链式求导法则注意到仅和
有关,因此
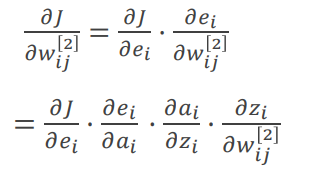
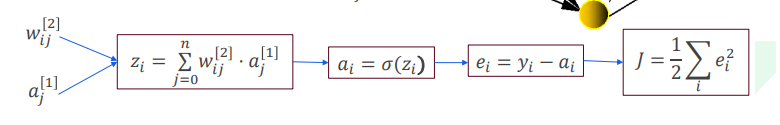

进一步有:
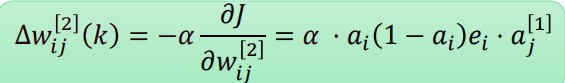
令,则有

误差反传——隐含层
注意到仅与
有关,因此
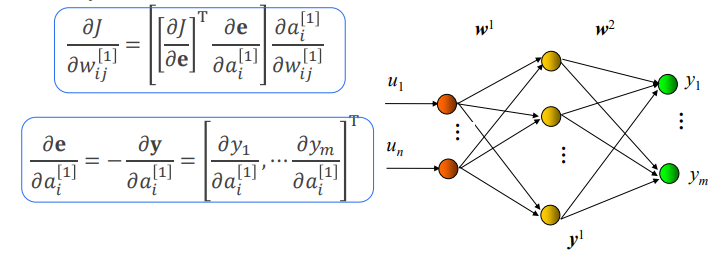
以为例说明求法。由
表达式(见前向传播),有:
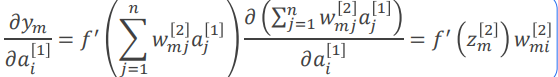
根据Sigmoid函数性质,同时利用,有:
![]()
因此
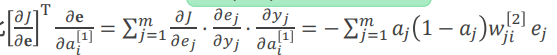
即误差进行反向传播。
综合上述结果,有:
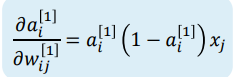
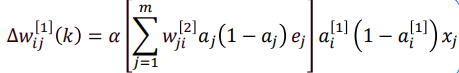
令:
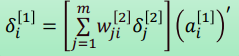
则:
![]()
算法评述
优点:学习完全自主;可逼近任意非线性函数。
缺点:算法非全局收敛;收敛速度慢;学习速率α选择;神经网络如何设计(几层、节点数)。
性能优化
常用技巧
模型初始化
简单考虑,把所有权值在[-1,1]区间内按均值或高斯分布进行初始化。
Xavier初始化:为了使得网络中信息更好的流动,每一层输出的方差应该尽量相等。因此需要实现下面的均匀分布:
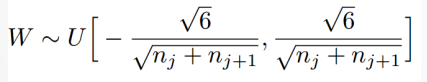
数据分类
数据包括:训练数据、验证数据、测试数据。
通常三者比例为70%,15%,15%或60%,20%,20%。 当数据很多时,训练和验证数据可适当减少。
𝐾折交叉验证:原始训练数据被分成 K个不重叠的子集。然后执行K次模型训练和验证,每次在 K−1 个子集上进行训练, 并在剩余的1个子集(在该轮中没有用于训练的子集)上进行验证。 最后, 通过对K次实验的结果取平均来估计训练和验证误差。
欠拟合与过拟合
欠拟合:误差一直比较大。
过拟合:在训练数据集上误差小而在测试数据集上误差大。
权重衰减(L2正则化)
为防止过拟合和权值震荡,加入新的指标函数项:

第二项约束了权值不能过大。在梯度下降时,导数容易计算:
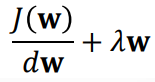
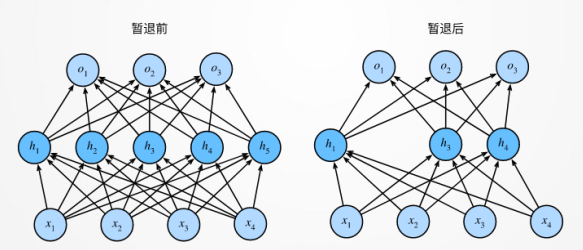
Dropout(暂退)
在整个训练过程的每一次迭代中,标准暂退法包括在计算下 一层之前将当前层中的一些节点置零。
动量法
病态曲率
图为损失函数轮廓。在进入以蓝色标记的山沟状区域之前随机开始。 颜色实际上表示损失函数在特定点 处的值有多大,红色表示最大值, 蓝色表示最小值。我们想要达到最小值点,为此但需要我们穿过山沟 。这个区域就是所谓的病态曲率。梯度下降沿着山沟的山脊反 弹,向极小的方向移动较慢 。这是因为脊的表面在W1方向上弯曲得更陡峭。
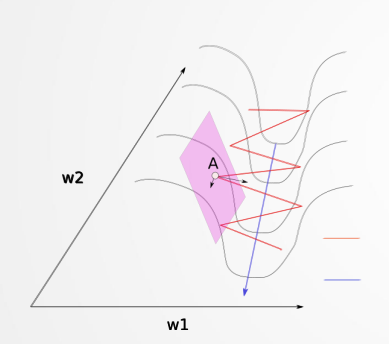
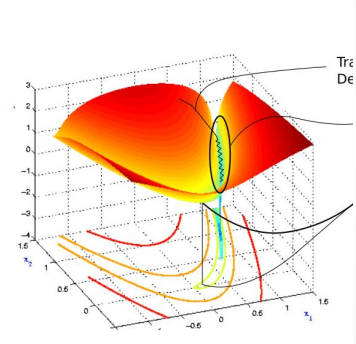
动量法
如果把原始的 SGD 想象成一个纸团在重力作用向下滚动,由于质量小受到山壁弹力的干扰大,导致来回震荡;或者在鞍点 处因为质量小速度很快减为 0,导致无法离开这块平地。动量方法相当于把纸团换成了铁球;不容易受到外力的干扰, 轨迹更加稳定;同时因为在鞍点处因为惯性的作用,更有可能离开平地。
更新公式:

原理可参考:《动手学深度学习》11.6节
自适应梯度算法
AdaGrad算法
自适应梯度:参数自适应变化,具有较大偏导的参数相应有一个较大的学习率,而具有小偏导的参数则对应一个较小的学习率 。 具体来说,每个参数的学习率会缩放各参数反比于其历史梯度平方值总和的平方根。

问题:学习率是单调递减的,训练后期学习率过小会导致训练困难, 甚至提前结束 。需要设置一个全局的初始学习率。
RMSProp算法
RMSProp 解决 AdaGrad 方法中学习率过度衰减的问题 , 使用指数衰减平均以丢弃遥远的历史,使其能够快速收敛;此外,RMSProp 还加入了超参数 𝜌 控制衰减速率。
具体来说(对比 AdaGrad 的算法描述),即修改 𝑟 为
![]()
算法流程图如下

Adam算法
Adam 在 RMSProp 方法的基础上更进一步:加入历史梯度平方的指数衰减平均(𝑟),还保留了历史梯度的指数衰减平均(𝑠),相当于动量。 Adam 行为就像一个带有摩擦力的小球,在误差面上倾向于平坦的极小值。

总结
①训练中常用技巧包括样本选择、权重衰减、暂退等。
②动量法可有效改善收敛速度,以及避免一些陷入局部极小值。
③AdaGrad及Adam等算法可自适应调节学习速率,加速收敛。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









