






 本文详细介绍了MySQL数据库的基础操作,包括查看存储引擎、数据库和表的状态,创建、修改和删除数据库和表,以及字段操作、数据插入、修改和删除,还涉及了主键、外键、索引和事务处理。
本文详细介绍了MySQL数据库的基础操作,包括查看存储引擎、数据库和表的状态,创建、修改和删除数据库和表,以及字段操作、数据插入、修改和删除,还涉及了主键、外键、索引和事务处理。
其他命令
-- 查看当前数据库支持的所有存储引擎
show engines;
-- 查看默认存储引擎和当前选择的存储引擎
show variables like '%storage_engine%';
-- 登陆前查看mysql版本
mysql --version
mysql --V
-- 登陆后查看mysql版本
select version();
-- 查看某个表的约束
select * from information_schema.TABLE_CONSTRAINTS where table_name='表名称'; 操作库
查询库
-- 查看所有库
show databases;
-- 查看当前所在库
select database();
-- 查看库创建的语句
show create database 库名; 创建库
create database [if not exists] 库名 [character set 字符集] [collate 校对规则名];删除库
drop database [if exists] 库名;切换库
use 库名; 操作表
查询表
show tables; # 查看当前库下的所有表
show tables from 库名; # 查看指定库下的所有表
desc 表名; # 查看表结构
show create table 表名; # 查看表语义(如何写的)创建表
create table [if not exists] 表名 (
字段名1 数据类型(长度) [主键] [自增长] [非空] [默认值] [注释文字],
字段名2 数据类型(长度) [非空] [默认值] [注释文字],
...
字段名n 数据类型(长度) [非空] [默认值] [注释文字] #最后一个字段是没有逗号的
) engine=引擎 auto_increment=自增的起始值 default charset=表的默认字符集;删除表
drop table [if exists] 表名; #可以删多个,用逗号隔开修改表
修改表名称
alter table 表名 rename 新表名;
rename table 表名 to 新表名; 增加表字段
-- 这种默认添加到最后一排,如果想添加到第一排,在最后加个first。如果指定排在谁后面,在最后加个 after 字段名
alter table 表名 add [column] 字段名 数据类型(长度) [default 默认值] [not null][comment 描述信息]; 删除字段
alter table 表名 drop [column] 字段名;修改字段名
alter table 表名 change [column] 旧字段名 新字段名 数据类型(长度) [default 默认值] [not null] [comment 描述信息]; 修改字段类型
-- 后面依然可以跟first、after 字段名 实现一边修改类型一边修改位置
alter table 表名 modify [column] 字段名 数据类型(长度) [default 默认值] [not null] [comment 描述信息]; 操作表数据(增删改)
插入数据
insert into 表名 [(字段名1,字段名2,...)] values (值1,值2,....)[,(值1,值2,....),....];字段和值的顺序、个数要保持一致。主键直接写null就可以直接实现主键自增
修改数据
update 表名称 set 字段名1=值1,字段名2=值2,....[where 条件]; -- 不带where全改开发时一定带上where,不然全改
删除数据
delete from 表名称 [where 条件]; -- 不带where全删解决删除数据后主键不重置自增,使用
truncate table 表名,它的作用:清空表中所有数据 和 重置表的主键值 (底层其实是先把表删除再重新创建表)
操作数据(查)
查询数据
select 字段名1,字段名2... from 表名 #查询字段,*表示查询全部,但开发中不建议使用,一般都会使用where来筛选条件别名
# 使用关键字as,可以省略但不建议,别名要见名知意
select 字段名1 as '别名1',字段名2 as '别名2'... from 表名 as '别名3'; 去重
# 使用关键字 distinct,该关键字耗性能
select distinct 字段名 from 表名; 着重号
# 有些字段和表名和mysql的关键字冲突,使用双反引号来解决
select `name` from t_stu;单表查询
运算符查询
算数运算符:+ - * / %
比较运算符: = > >= < <= != //判断null要使用 is、is not
逻辑运算符:(&& 、and)、(|| 、or)、(not)范围、集合查询
范围: between...and... (闭区间、等效于 >= 和 <=)
集合: in() 或 not in(),它用来优化 or使用 in 有局限性,它只支持数值类型和字符串类型。
模糊查询
使用 like、not like 关键字,其中需要使用通配符:
% :表示 0 ~ n个字符
_ :表示一个字符统计查询
sum() #用于求和统计
avg() #用于求平均值
count() #用于获取总记录数
max() #用于获取最大值
min() #用于获取最小值 使用 count() 来进行查询时,参数不能为空。参数可以是数字、字符、星号、某个字段。
分页查询
# 使用 limit关键字,有两个参数
limit offset,pagecount;offset:可以理解为 起始值 - 1,需要计算,公式为:offset = (当前页码 - 1) * pagecount
pagecount:每页显示的记录数
分组查询
# 使用 group by 关键字进行分组,使用 having 关键字进行条件筛选
select dept_id, count(*) from t_employee group by dept_id having dept_id > 1;group by 的分组字段和统计查询的函数可以写在select后面,其他字段不能写在select后面
当 SQL 语句中既有 where 条件,又有 having 条件时,先执行 where 条再执行 having条件(一般也会考虑使用where过滤大量数据后,再用having进行二次过滤,性能好很多)
排序查询
# 使用到 order by 关键字,还会使用到 asc(升序) 或 desc(降序)关键字。
select eid, basic_salary from t_salary order by basic_salary desc;# 如果排序的字段有多个时,会优先对第一个进行排序,只有当第一个的值相同时,才会对第二个值进行排序,依次类推。 # 例子:按员工的职位高低进行排序,如果职位相同再按员工的编号长序进行排序。 select eid,ename,gender,job_id from t_employee order by job_id desc,eid asc;
多表查询(关联查询)
笛卡尔积
多表查询在没有关联条件的情况下, 查询的结果就是这几张表中数据的乘积数,也叫交叉连接(cross join)
select ename,dname from t_employee,t_department;
SELECT ename,dname FROM t_employee CROSS JOIN t_department;关联条件
为了避免笛卡尔积,我们需要使用一些关键字来关联条件
-
where :所有关联查询都能用
-
on : 只能和join、where一起使用
-
using : 只能和join连用,并且关联的条件字段名称必须相同( using(eid) )
# 演示,下面三个查询结果一致
select ename,dname from t_employee,t_department where dept_id=did;
select ename,dname from t_employee join t_department on dept_id=did;
select ename,basic_salary from t_employee e,t_salary s where e.eid=s.eid;内连接
# 隐式内连:使用where来去除笛卡尔积的无用数据
select [columns] from 表1,表2...表n where ...;
# 显式内连,交叉连接加了关联条件也就转换成内连接了
select [columns] from 表1 [inner、cross] join 表2 on ... [where...];外连接
#左外连接(left outer join、left join):以左表要基准表,如果右表中没有数据和左表匹配,则以null为填充
#右外连接(right outer join、right join):以右表要基准表,如果左表中没有数据和右表匹配,则以null为填充
左、右外连接同显式内连接写法一致,只是join换成了left或者right join
#全外连接(full outer join、full join): MySQL不支持,可以使用联合查询关键字 union
select 字段 from 表1 left join 表2 on ...[where...]
union
select 字段 from 表1 right join 表2 on ...[where...];语句中写全称和简写都是可以的
如果要查询没有匹配的字段,就把两张表中相关联的那个字段,使用
where 基准表中的字段 is null就可以查出来,全外连接如果要查没有匹配的,就在上述语法的where当中写两次就可以
自连接
# 就是需要查的表是同一张表,那么就用别名的方式,通过关联条件中写:别名.字段的方式来连接查询,从而形成自连接
# 例如:查询员工及其领导的名字
select e1.name, e2.name from employee e1, employee e2 where e1.leader_id=e2.employee_id;在自连接中是可以使用内、外连接的
select e1.ename, e2.ename from t_employee e1 join t_employee e2 on e1.leader_id=employee_id.eid;
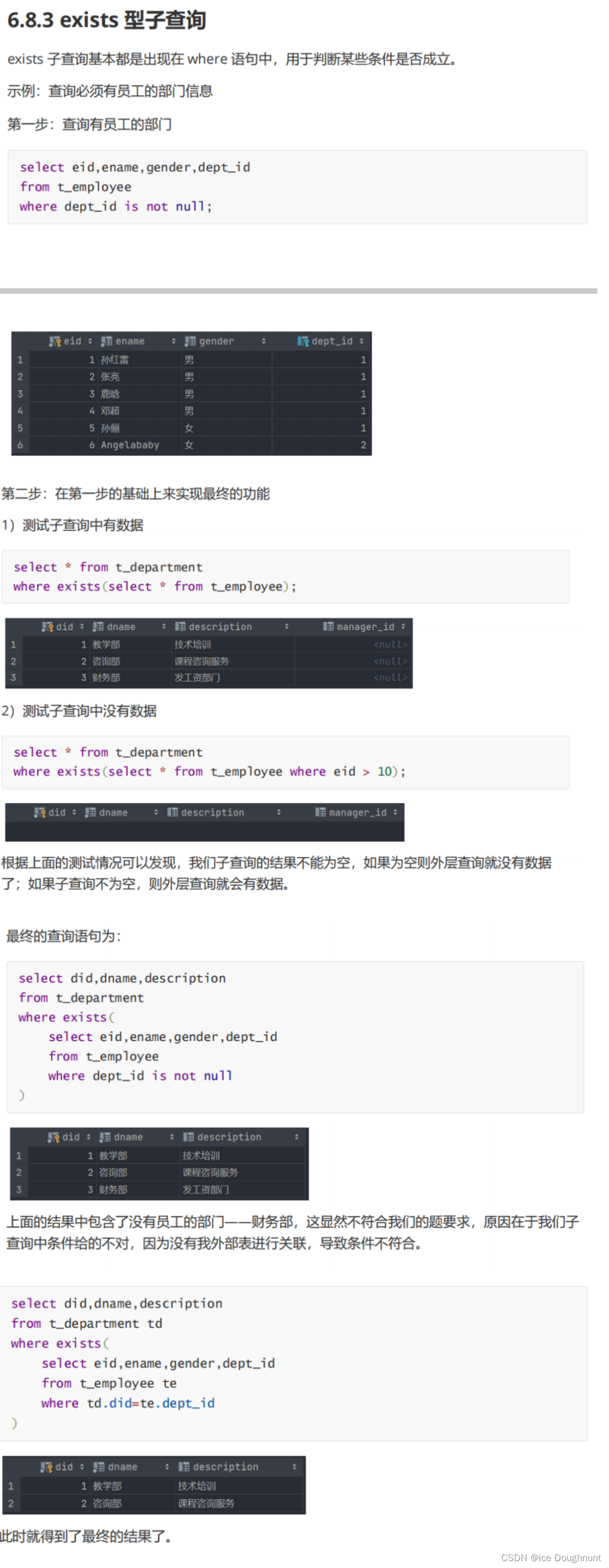
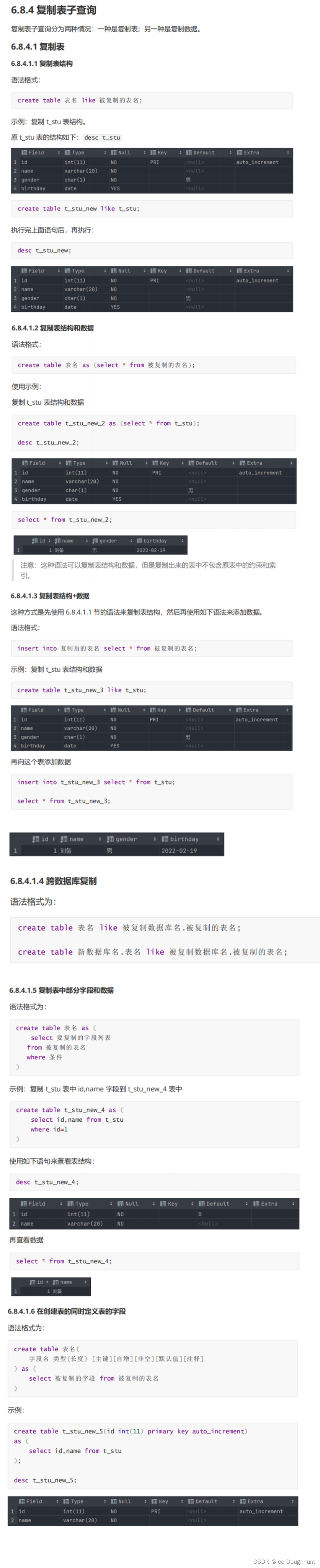
子查询
某些查询,需要的条件或数据是另一个查询的结果,就要用到子查询
总结:编写原则
查询之前,先确定题目要查哪些字段,这些要查的字段都在哪几张表里面,然后再看这几张表两两之间是用什么字段关联起来的(如果两张表之间没有关联的字段就不用写关联条件,把有的写了),分析清楚之后再动手
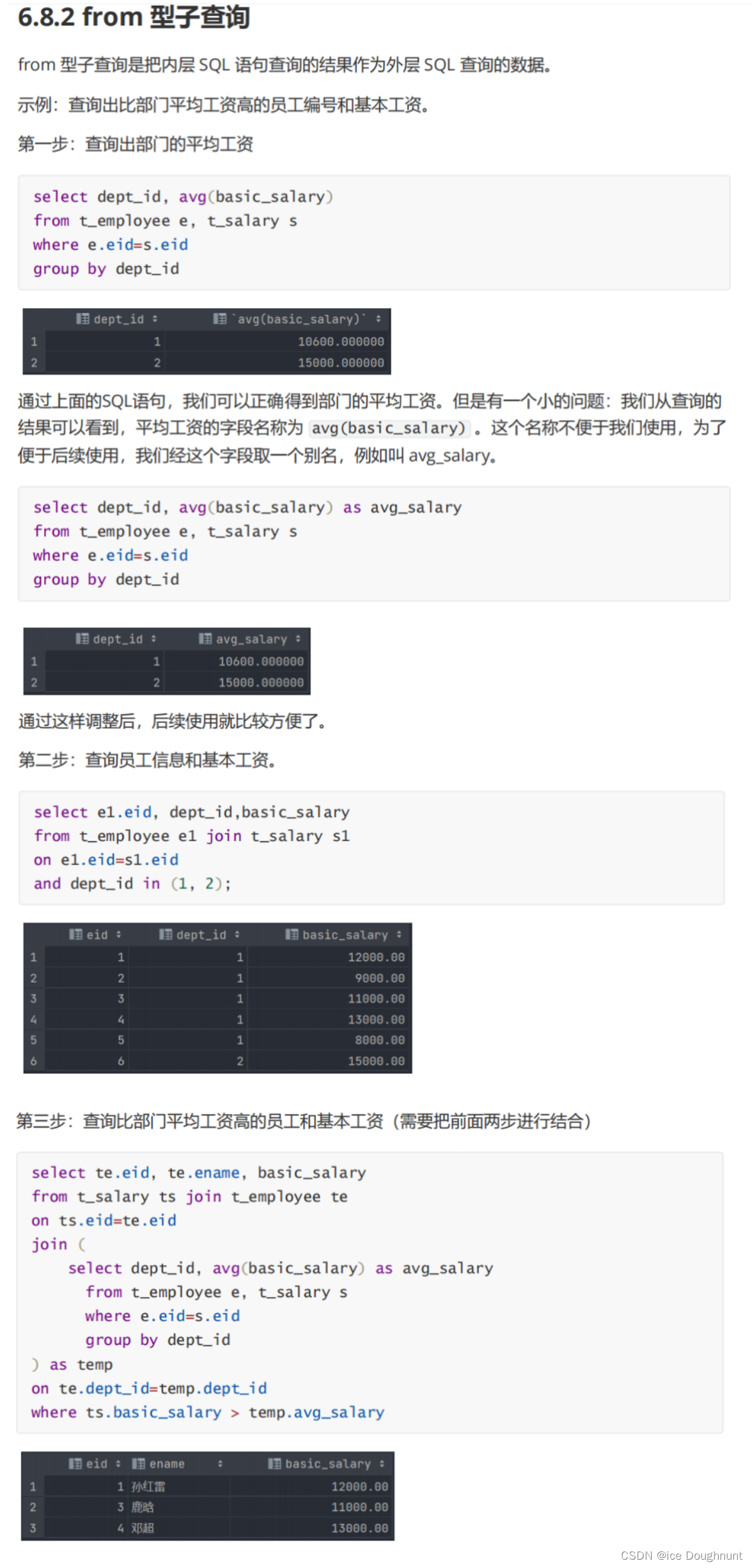
示例:查询员工姓名、基本工资和所在部门名称
分析如下:
-
员工姓名:在 t_employee 表中
-
基本工资:在 t_salary 表中
-
部门名称:在 t_deparment 表中
员工表和基本工资表的关联条件是 eid
员工表和部门表的关系条件是员工表中的 dept_id 字段指向的是 部门表中的 did 字段。
工资表和部门表没有关联条件。 所以综上sql语句应该为
select ename,basic_salary,dname
from t_employee e join t_salary using(eid)
join t_department td on td.did = e.dept_id;
约束

主键约束
主键约束 = 唯一约束 + 非空约束 (数据不重复、且没有空值)
# 创建表时
create table t_xx (
tid int(11) primary key, -- 方式1
tname varchar(20),
primary key(cid,tid) -- 方式2
)
# 创建表后
alter table 表名 add [constraint 约束名称] primary key(字段名1,字段名2,...);
# 删除
alter table 表名 drop primary key;唯一约束
表中的数据都是唯一的
# 创建表时
create table t_xx(
tel varchar(11),
constraint uk_t_per_tel unique key (tel)
)
# 创建表后
alter table 表名 add constraint 唯一约束名称 unique key(字段名列表);
# 删除
alter table 表名 drop index 唯一约束名;外键约束
# 创建表时
create table t_b(
bid int primary key auto_increment,
bname varchar(20),
a_id int(11), -- 外键
# 语法:[constraint 外键名列] foreign key(外键字段) references 引用的那张表表(表中的哪个字段)
# on update cascade on delete restrict 表示做级联操
constraint fk_t_a_aid foreign key(a_id) references t_a(aid) on update cascade on delete restrict
)
# 创建表后
alter table 表名 add [constraint 约束名] foreign key(从表字段) references 主表名(主表中被参照的字段名);
# 删除
alter table 表名 drop foreign key 外键约束名非空约束
规定某个字段不能为空值
# 创建表时
create table t_user(
uid int primary key,
uname varchar(50),
tel varchar(11) not null -- 非空约束
)
# 创建表后
alter table 表名 modify 字段名 数据类型(长度) not null;
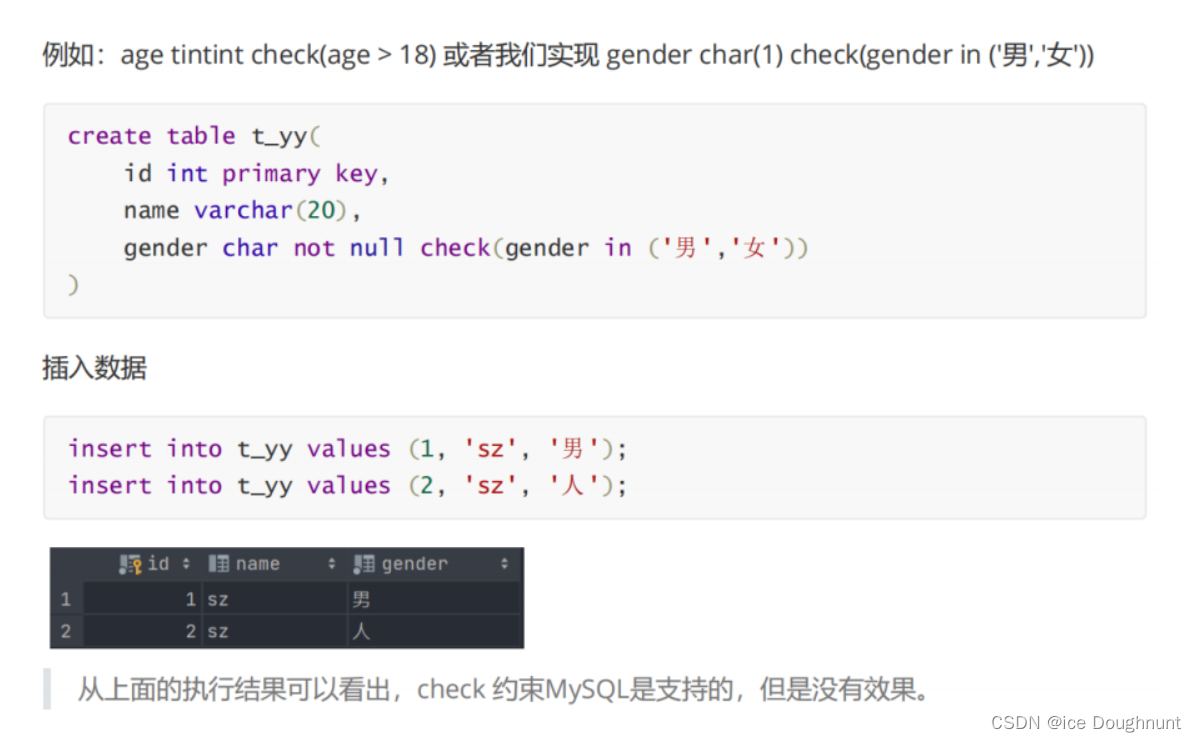
检查约束
MySQL 中是不支持检查约束
缺省约束
默认值,在插入数据时,如果某列没有给定值,那么就会将默认值添加到新记录中
create table t_zz(
id int primary key,
age int(2) not null default 0 -- 缺省约束
)视图
# 创建视图
create view 视图名称 [(字段列表)] as sql执行语句 [with [cascaded | local] check option]
# 使用视图,DQL语句查询
select 字段 from 视图名
# 查看视图(MySQL 5.1之后,不但会查询所有的表,也会把所有的视图都查询出来)
show tables;
# 更新视图
ALTER VIEW 视图名称 [(字段列表)] AS sql执行语句 [WITH [CASCADED | LOCAL] CHECK OPTION]
# 删除视图
drop view [if exists] 视图名称;创建视图中,选项 WITH [CASCADED | LOCAL] CHECK OPTION 决定了是否允许更新数据使记录不再满足视图的条件:
LOCAL : 只要满足本视图的条件就可以更新
CASCADED : 必须满足所有针对该视图的所有视图的条件才可以更新(默认值)
还可以指定算法
事务
# 1.开启事务
begin; 或 start transaction;
# 2.编写sql(insert、delete、update)
INSERT INTO customers (NAME, AGE, ADDRESS, SALARY) VALUES ('Ramesh', 32,'Ahmedabad', 2000.00 );
# 3.提交事务
commit;
# 4.回滚事务
rollback;
# 5.回滚标记点
SAVEPOINT point_name;
# 6.删除回滚标记点
RELEASE SAVEPOINT
# 7.回滚到标记点,标记点前面的事务都会操作
ROLLBACK TO point_name;下面是笔者之前整理的笔记演示


索引
# 创建索引语法
create index 索引名称 on 表名(字段名);
alter table 表名 add [unique] index 索引名称(字段名);
create index 索引名称 on 表名(字段名); # 单值索引
create unique index 索引名称 表名(字段名); # 唯一索引
CREATE index 索引名称 ON 表名(字段名1,字段2,...); # 复合索引
# 查看索引
show index from 库名.表名; 或 show index from 表名;
# 删除索引
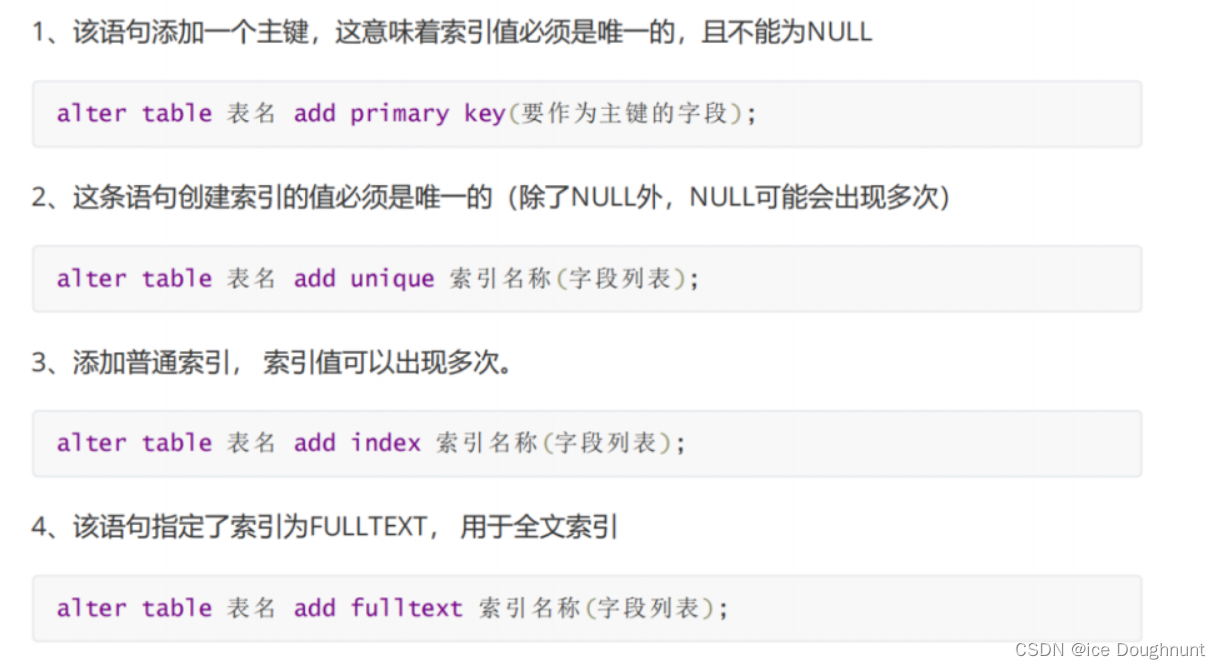
drop index 索引名称 on 表名;补充:alter命令















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









