







目录
1.重要参数init & random_state & n_init :初始质心怎么放好?
1.重要参数init & random_state & n_init :初始质心怎么放好?
在K-Means中有一个重要环节,就是放置初始质心。如果有足够时间,K-Means一定会收敛,但inertia只能收敛到局部最小值。是否能够收敛到真正最小值很大程度上取决于质心的初始化。init就是用来帮助我们解决初始化方式的参数。
初始质心放置的位置不同,聚类的结果很可能也会不一样,一个好的质心选择可以让K-Means避免更多的计算,让算法收敛稳定且更快。使用“随机”的方法在样本点中抽取k个样本作为初始质心,这种方法显然不符合“收敛稳定且快”的需求,为此,我们可以使用random_state参数来控制每次生成初始质心都在相同位置,一个random_state对应一个质心随机初始化的随机种子。如果不指定随机种子,则sklearn中的K-Means并不会只选择一个随机模式扔出结果,而会在每个随机数种子下运行多次,并使用结果最好的一个随机种子来作为初始质心。我们可以使用参数n_init来选择每个随机种子运行的次数。这个参数不常用到,默认10次,如果我们希望运行的结果更加精确,那我们可以增加这个参数n_init的值来增加每个随机种子下运行的次数。然而这种方法依然是基于随机的。
为了优化选择初始质心的方法,在sklearn中,我们使用参数init=‘k-means++’来选择使用k-means++作为质心初始化的方案。sklearn中默认init=‘k-means++’。
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
x,y=make_blobs(n_samples=500,n_features=2,centers=4,random_state=1)使用init='k-means++'
plus=KMeans(n_clusters=10).fit(x)
plus.n_iter_9使用init=‘random’
random=KMeans(n_clusters=10,init="random",random_state=420).fit(x)
random.n_iter_19由此可见, 参数init=‘k-means++’相比于init=‘random’ 迭代次数明显减少。
| 参数 | 说明 |
|---|---|
| init | 可输入"k-means++","random"或者一个n维数组,初始化质心的方法,默认"k-means++" 输入"k-means++":一种为k均值聚类选择初始聚类中心的聪明方法,以加速收敛 输入n维数组:数组的形状应该是(n_clusters,n_features)并给出初始质心 |
| random_state | 控制每次质心随机初始化的随机种子 |
| n_init | 整数,默认为10 使用不同的质心随机初始化的种子来运行k-means算法的次数。最终结果会是基于inertia来计算的n_init次连续运行后的最佳输出。 |
2.重要参数max_iter & tol :让迭代停下来
当质心不再移动,k-means算法就会停下来,但在完全收敛时,我们也可以使用max_iter(最大迭代次数),或者tol(两次迭代间inertia下降的量),这两个参数来让迭代次数停下来。有时候,当我们的n_clusters选择不符合数据的自然分布,或者为了业务需求,必须要填入与数据分布不合的n_clusters,提前让迭代停下来反而能够提升模型的表现。
| 参数 | 说明 |
|---|---|
| max_iter | 整数,默认300 单次运行的k-means算法的最大迭代次数 |
| tol | 浮点数,默认1e-4 两次迭代间inertia下降的量,如果两次迭代之间inertia下降的值小于tol所设定的值,迭代就会停下 |
迭代10次:
random=KMeans(n_clusters=10,init="random",max_iter=10,random_state=420).fit(x)
y_pred_max10=random.labels_
silhouette_score(x,y_pred_max10)0.39525864440341574迭代20次:
random=KMeans(n_clusters=10,init="random",max_iter=20,random_state=420).fit(x)
y_pred_max20=random.labels_
silhouette_score(x,y_pred_max20)0.3401504537571701可以看出,迭代10次的模型效果比迭代20次的效果要好。
3.函数cluster.k_means
函数k_means的用法和类非常相似,不过函数是输入一系列值,而直接返回结果。k_means会一次返回质心,每个样本对应的簇的标签,inertia以及最佳迭代次数。
from sklearn.cluster import k_means
k_means(x,4,return_n_iter=True)
# 参数return_n_iter默认为False,调整为True后就可以看到返回的最佳迭代次数(array([[ -7.09306648, -8.10994454],
[ -1.54234022, 4.43517599],
[ -6.08459039, -3.17305983],
[-10.00969056, -3.84944007]]),
array([0, 0, 3, 1, 2, 1, 2, 2, 2, 2, 0, 0, 2, 1, 2, 0, 2, 0, 1, 2, 3, 3,
2, 1, 2, 2, 1, 1, 3, 2, 0, 1, 2, 0, 2, 0, 3, 3, 0, 3, 2, 3, 1, 2,
2, 0, 3, 2, 1, 1, 1, 3, 3, 2, 0, 3, 3, 3, 3, 2, 1, 1, 3, 2, 1, 2,
0, 2, 3, 3, 0, 3, 2, 0, 2, 2, 0, 2, 2, 3, 1, 1, 3, 1, 1, 3, 3, 1,
3, 3, 1, 0, 3, 2, 1, 0, 0, 2, 0, 1, 1, 0, 1, 3, 1, 2, 2, 1, 1, 3,
2, 0, 1, 3, 1, 3, 1, 2, 1, 2, 3, 0, 0, 3, 2, 3, 1, 0, 0, 2, 1, 3,
3, 3, 3, 0, 1, 2, 1, 1, 2, 0, 2, 1, 1, 1, 2, 2, 0, 0, 3, 3, 1, 0,
1, 3, 3, 3, 3, 3, 3, 3, 3, 3, 1, 0, 0, 0, 2, 1, 0, 3, 2, 0, 1, 3,
3, 3, 3, 0, 2, 3, 1, 0, 0, 3, 2, 0, 0, 2, 1, 1, 0, 0, 2, 1, 2, 0,
0, 1, 0, 3, 1, 2, 2, 0, 2, 3, 0, 2, 3, 2, 3, 0, 2, 2, 2, 1, 3, 1,
2, 0, 3, 2, 3, 3, 3, 1, 3, 1, 0, 3, 0, 3, 1, 1, 3, 0, 1, 0, 2, 3,
0, 0, 0, 0, 2, 3, 0, 3, 2, 1, 1, 2, 2, 1, 3, 2, 3, 1, 2, 1, 3, 3,
1, 2, 0, 0, 3, 3, 3, 2, 1, 1, 2, 1, 3, 0, 1, 0, 1, 0, 0, 1, 0, 1,
1, 2, 3, 3, 3, 2, 2, 3, 0, 1, 0, 0, 0, 2, 3, 2, 0, 3, 0, 0, 3, 0,
0, 3, 1, 0, 2, 2, 1, 1, 3, 0, 1, 1, 2, 0, 1, 1, 2, 3, 1, 3, 2, 0,
0, 1, 3, 0, 2, 1, 1, 2, 2, 2, 0, 2, 1, 1, 3, 1, 1, 1, 1, 0, 0, 2,
1, 3, 2, 0, 1, 3, 1, 2, 1, 3, 2, 3, 1, 2, 2, 0, 1, 0, 0, 0, 0, 0,
0, 3, 0, 1, 0, 1, 1, 3, 1, 2, 3, 3, 0, 1, 3, 1, 2, 0, 3, 3, 0, 3,
3, 1, 1, 0, 3, 2, 1, 2, 2, 0, 0, 2, 0, 3, 3, 0, 3, 0, 3, 1, 0, 1,
3, 2, 1, 3, 2, 1, 0, 2, 1, 1, 3, 2, 3, 2, 0, 1, 0, 2, 1, 0, 0, 0,
3, 1, 2, 0, 2, 2, 3, 3, 0, 2, 2, 2, 2, 2, 2, 0, 2, 3, 0, 2, 1, 2,
1, 2, 3, 3, 1, 1, 1, 3, 2, 3, 0, 3, 1, 2, 0, 1, 0, 1, 0, 2, 1, 1,
0, 3, 2, 0, 3, 3, 3, 0, 2, 1, 3, 2, 0, 0, 0, 2]),
908.3855684760603,
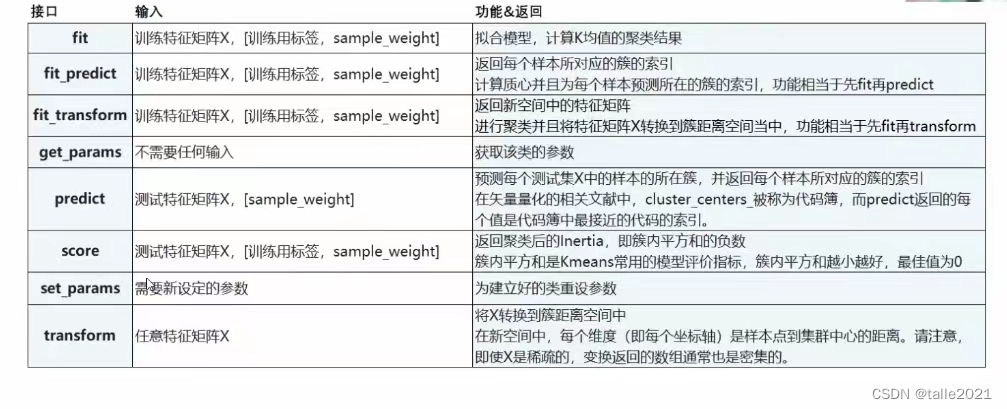
3)4.重要属性与接口
属性:
| cluster_centers_ | 收敛到的质心,如果算法在完全收敛之前就已经停下了(受到参数max_iter或tol的控制)所返回的内容将于labels_属性中反应出来的聚类结果不一致。 |
| labels_ | 每个样本对应的标签 |
| inertia_ | 每个样本到距离他们最近的质心的均方距离,又叫“簇内平方和” |
| n_iter_ | 实际的迭代次数 |
完!

















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









