







主从集群
单节点Redis的并发能力是有上限的,要进一步提高Redis的并发能力,就需要搭建主从集群,实现读写分离。(因为在实际业务中大部分都是读多写少的场景)
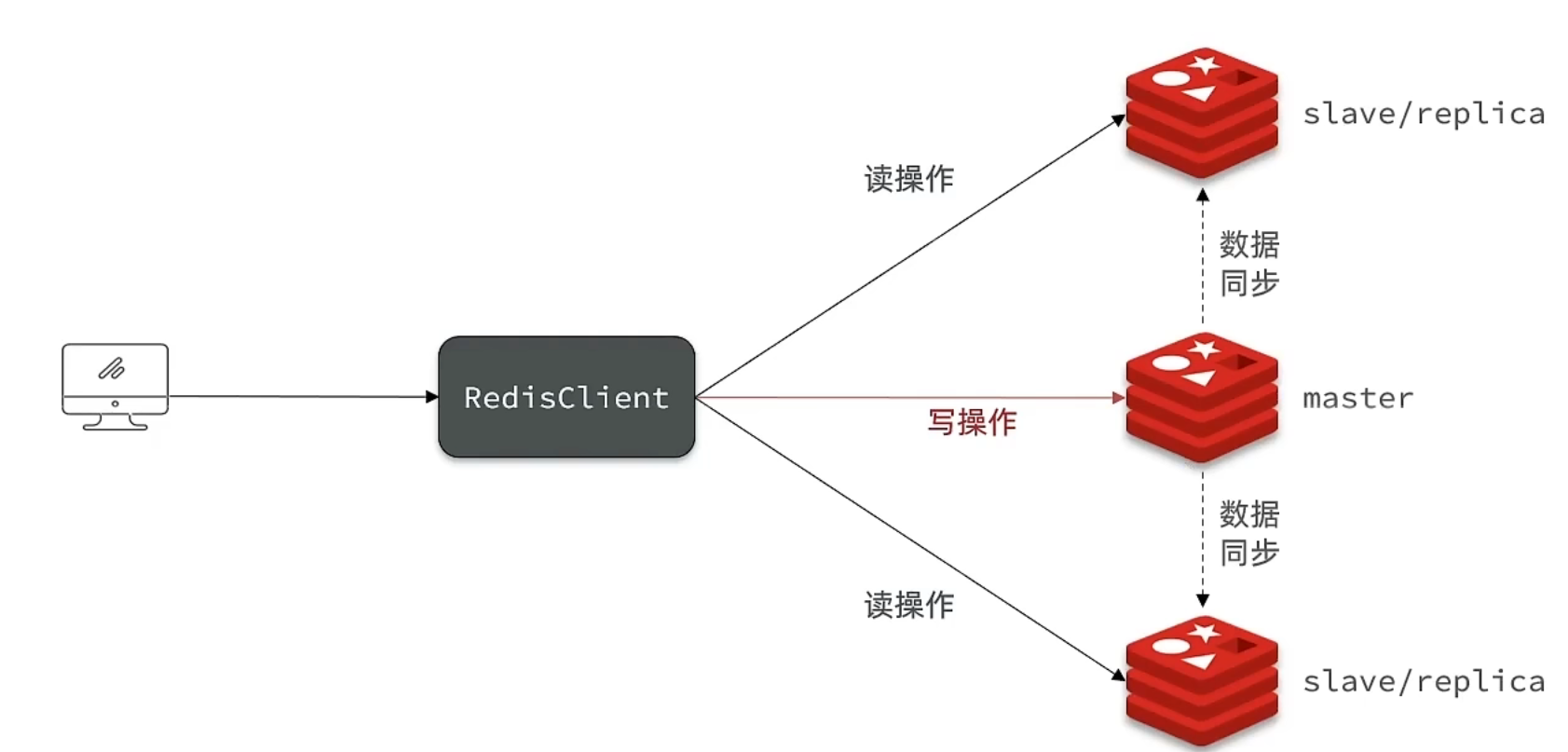
读的话就分到从节点上去执行,写就分到主节点上去。主从点会做数据共享,写的任何东西从节点都能读出来,但是从节点是没法写的。
开启主从关系
永久配置
在redis.conf配置文件中加一行配置就行:
slaveof 主节点ip 主节点端口
临时配置:
在连接到redis服务后执行slaveof命令(重启后就失效了,这是临时的):
slaveof 主节点ip 主节点端口
数据同步原理
全量同步

master如何判断slave是不是第一次来同步数据?这里会用到两个很重要的概念:
Replication Id:简称replid,是数据集的标记,id一致则说明是同一数据集。每一个master都有唯一的replid,slave则会继承master节点的replid
offset:偏移量,随着记录在repl_baklog中的数据增多而逐渐增大。slave完成同步时也会记录当前同步的offset。如果slave的offset小于master的offset,说明slave数据落后于master,需要更新。(offset底层是一个数组,当写满的时候就从头开始覆盖着写)
因此slave做数据同步,必须向master声明自己的replication id 和offset,master才可以判断到底需要同步哪些数据
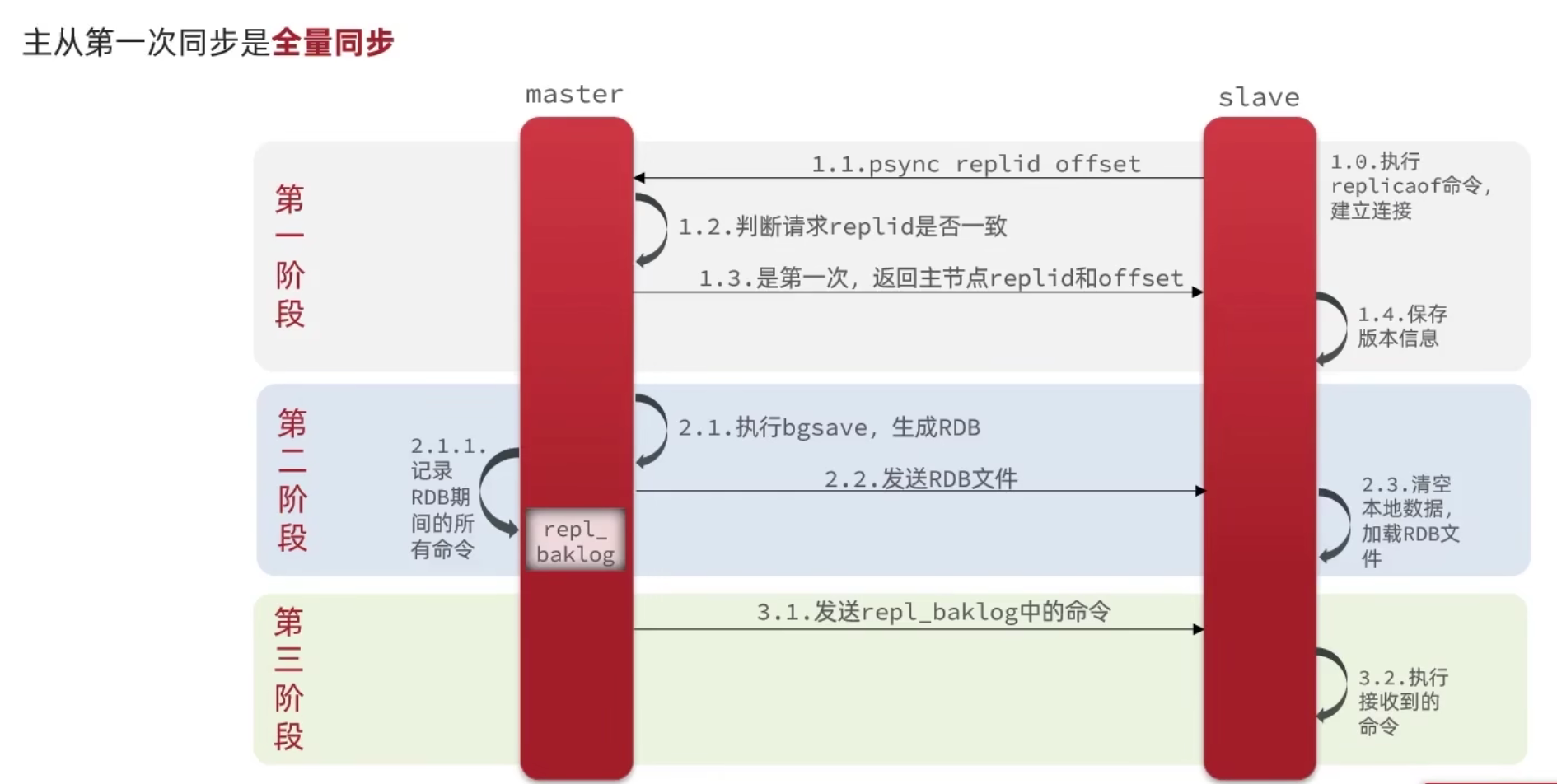
全量同步的流程:
- slave节点请求增量同步
- master节点判断replid,发现不一致,拒绝增量同步
- master将完整内存数据生成RDB,发送RDB到slave
- slave清空本地数据,加载master的RDB
- master将RDB期间的命令记录在repl_baklog,并持续将log中的命令发送给slave
- slave执行接收到的命令,保持与master之间的同步
增量同步
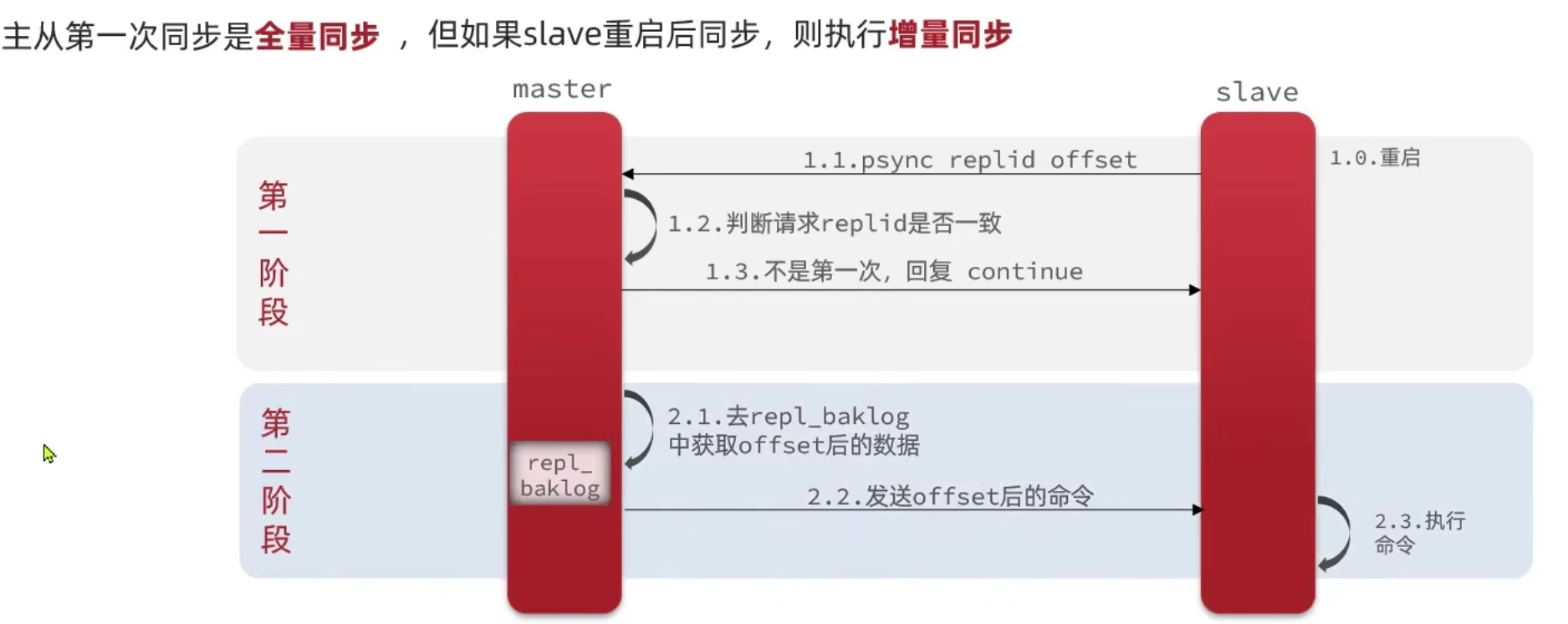
repl_baklog大小有上限,写满后会覆盖最早的数据。如果slave断开时间过久,导致尚未备份的数据被覆盖,则无法基于log做增量同步,只能再次全量同步。
优化Redis主从就集群
如何优化Redis主从就集群:
- 在master中配置repl-diskless-sync yes启用无磁盘复制,避免全量同步时的磁盘IO。
- Redis单节点上的内存占用不要太大,减少RDB导致的过多磁盘IO
- 适当提高repl_baklog的大小,发现slave宕机时尽快实现故障恢复,尽可能避免全量同步
- 限制一个master上的slave节点数量,如果实在是太多slave,则可以采用主-从-从链式结构,减少master压力
全量同步和增量同步的区别
全量同步:master将完整内存数据生成RDB,发送RDB到slave。后续命令则记录在repl_baklog,逐个发送给slave。
增量同步:slave提交自己的offset到master,master获取repl_baklog中从offset之后的命令给slave
什么时候执行全量同步和增量同步?
什么时候执行全量同步?
1.slave节点第一次连接master节点时
2.slave节点断开时间太久,repl_baklog中的offset已经被覆盖时
什么时候执行增量同步?
1.slave节点断开又恢复,并且在repl_baklog中能找到offset时
思考
slave节点宕机恢复后可以找master节点同步数据,那master节点宕机怎么办?下一章开始介绍哨兵模式可以解决这个问题。














 1677
1677











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









