







1. 介绍
索引失效就是在查询已经创建了索引的字段中却没有走索引,走的是全表扫描。其实看有没有走索引只需要加上 explain,查看 type 为 ALL 就行了。下面的图就是索引失效。

下面介绍一下有哪些会导致索引失效?
- like %xx 或者 like %xx%
- 对索引列使用函数
- 对索引列进行表达式计算
- 发生隐式类型转换
- 不遵守最左匹配原则
- or
1.1. 通用表
CREATE TABLE `user` (
`id` varchar(255) NOT NULL COMMENT 'id',
`name` varchar(255) DEFAULT NULL COMMENT '名称',
`age` int DEFAULT NULL COMMENT '年龄',
`gender` varchar(255) DEFAULT NULL COMMENT '性别(0:男,1:女)',
`birthday` date DEFAULT NULL COMMENT '生日',
`a` varchar(255) DEFAULT NULL,
`b` varchar(255) DEFAULT NULL,
`c` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id` DESC),
KEY `idx_name` (`name`),
KEY `idx_age` (`age`),
KEY `idx_abc` (`a`,`b`,`c`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
INSERT INTO `gsxt`.`user` (`id`, `name`, `age`, `gender`, `birthday`, `a`, `b`, `c`) VALUES ('130a682e53c611ef83e28cc430a5ab68', '张三', 18, '1', '2024-08-06', '1', '1', '1');2. 索引存储结构
先来简单介绍一下 MySQL 中索引存储结构是什么,防止后面看的一头雾水。我们都知道现在 MySQL 中存储引擎最常用的为 MyISAM 和 InnoDB(MySQL 默认)两种。
其中两者关于索引的区别:
- InnoDB 存储引擎:索引的叶子节点保存数据本身;
- MyISAM 存储引擎:索引的叶子节点保存数据的物理地址;
下面上两幅图辅助理解一下:
图片来源于:MyISAM与InnoDB 的区别(9个不同点)-CSDN博客
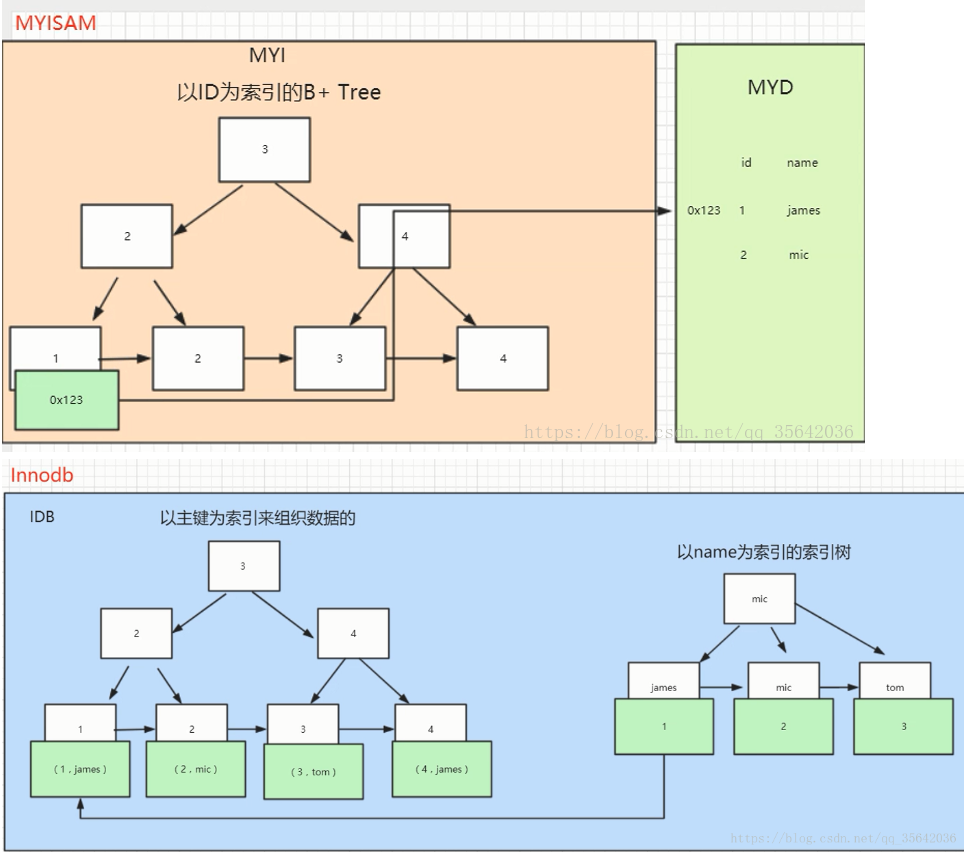
如果使用的是 InnoDB 的存储引擎,索引可以分为聚簇索引和非聚簇索引(也叫二级索引)。他们之间的区别在于聚簇索引的叶子节点存放的是真实的数据,而二级索引存放的主键值,从上文的图中也可以明显的看出。
下面介绍写个简单 SQL 作证一下:
- 情况一:走聚簇索引
explain select * from user where id = '130a682e53c611ef83e28cc430a5ab68'结果:

能清晰的看到确实走了索引并且走的是我们自己创建的 聚簇索引(也就是主键索引).
- 情况二: 走二级索引
explain select * from `User`
where name = '张三'结果:

能够看到走了自己创建的 name 索引,但这里面还包含了一个额外的知识点回表,根据上面 InnoDB 的图中发现,我们走的是以 name 为索引的索引树,叶子节点挂的主键,而我们需要查询所有字段,这个时候就需要根据主键查询主键索引树,也就是说我们需要查询两次。关于这一方面我们可以通过看 extra ,下面为 null 就代表着查询的列未被索引覆盖,且where筛选条件是索引的前导列,这意味着用到了索引,但是部分字段未被索引覆盖,必须通过“回表”来实现。
ok,下面开始分别介绍索引失效的情况。
3. like %xx 或者 like %xx%



原因:根据 InnoDB 和 MyISAM 的对比图中的主键索引树来看,id 是按照大在右,小在左的原则,进行去排列,如果以 id like '%130',查询结果可能为'任意字符130',这个时候就不知道改走哪个索引值进行去比较,只能去全表扫描。
4. 对索引列使用函数
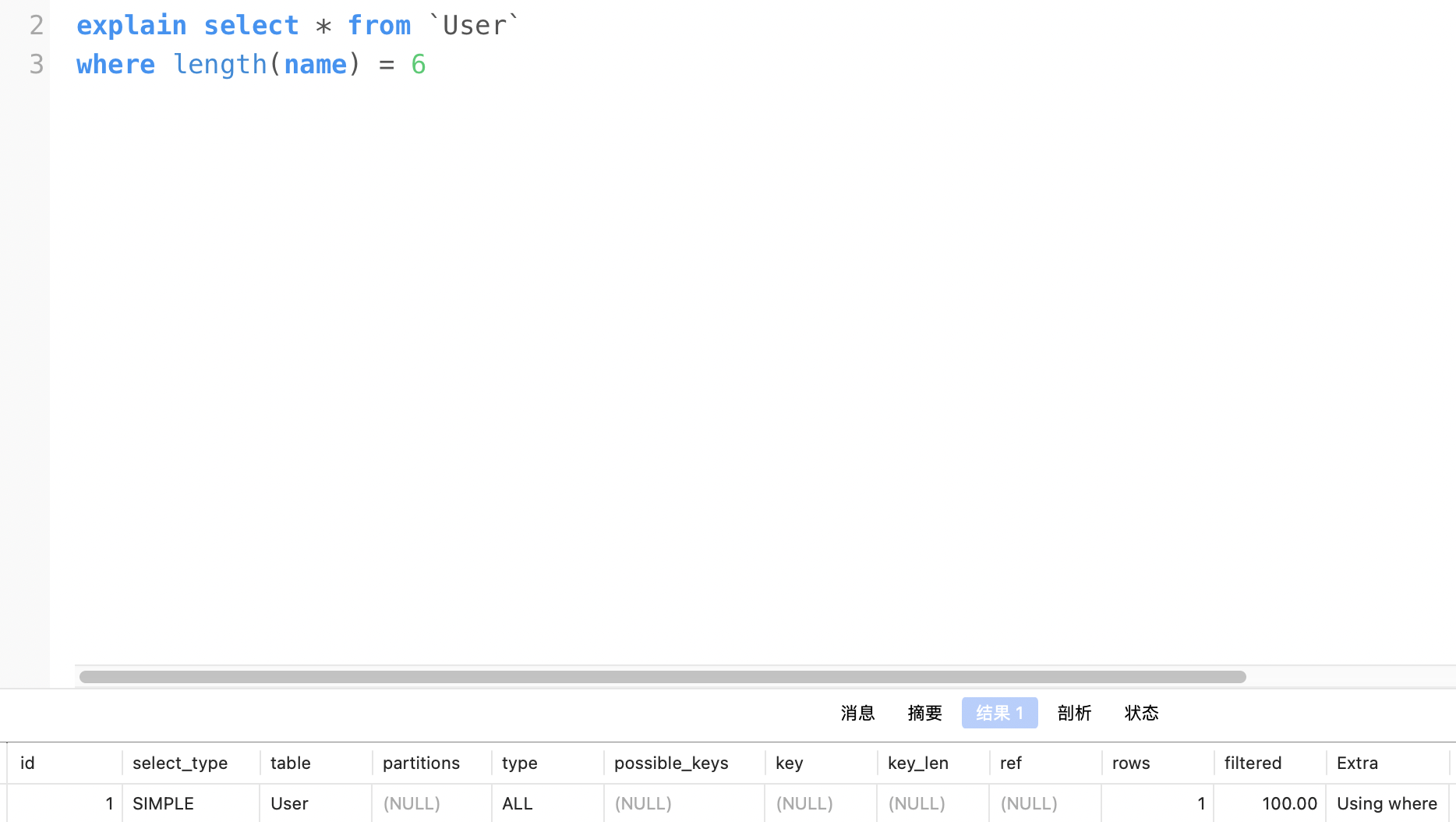
原因: 根据 InnoDB 和 MyISAM 的对比图中的主键索引树来看,我们存储的主键值,而不是进行运算后的结果,自然不可能走索引了。
5. 对索引列进行表达式计算
explain select * from `user`
where age + 1 = 0结果:

结论:
其实这种情况我感觉是可以忽略不计的,一般 程序员基本上不会写出这种语法,一是不美观,二是运算符基本都会放在等号的右半部分。关于索引失效的原因其实跟对索引使用函数一个道理,索引所生成的树是存放的字段的值,而不是 age + 1
6. 发生隐式类型转换
这个情况个人认为还是比较常见的,很有可能就出来了,如果数据量比较大,查询时间是很不客观的。
先看下面两张图吧
- 索引未失效

- 索引失效

结论:很容易发现当数字类型和字符类型进行比较时,数字类型在左,字符类型在右时不会发生失效,而字符类型在左,数字类型在右会发生失效。这就得需要带出 Mysql 中隐私类型转换的概念。对于字符串和数字类型进行比较时,Mysql 会自动将字符类型转换为数字类型,然后进行两两比较。也就是说上面的索引失效的语句实际情况应该是 select * from user where cast(id as singed int) = 1,第四节说了对索引列进行函数时是会失效的,说到这里应该可以理解了吧。
7. 不遵守最左匹配原则
强调这个概念之前,先讲述一下联合索引的概念。
对主键字段建立的索引叫做聚簇索引,对普通字段建立的索引叫做二级索引。那么多个普通字段组合在一起创建的索引就叫做联合索引,也叫组合索引。
使用联合索引时,需要遵循最左匹配原则,举个例子,假如你对 a b c 三个字段创建了联合索引,查询条件是下面几种,可以匹配上联合索引。
- where a = 1;
- where a = 1 and b = 2 and c = 3;
- where a = 1 and b = 2;
a 的位置是可以不固定,因为有查询优化器的辅助。
无法匹配的例子:
- where b = 1;

- where a = 1 and c = 1;

原因:在联合索引的情况下,数据是按照第一列进行排序,当相同时才会进行第二列等...
但是 第二个情况有些特殊,可以发现是走了一部分的索引的,通过查看 extra 。严格意义上来说,这种情况属于索引截断,每个版本之间的情况也是不一样的。简单介绍一些索引截断:当在存储引擎层进行索引遍历的时候,会对索引中包含的字段进行判断,如果不包含,则直接舍弃返回给 server 层,这样做能够有效的减少回表次数。
也就是说当我们进行 a = '1' and c = '1'时,使用到了索引截断的概念,当在存储引擎层中进行索引遍历的时候,发现有 abc 三个字段的索引,于是先进行 a 索引遍历,当发现第二个条件不是 b 时,则直接舍弃,返回给 server 层。下面这张图来自小林 coding
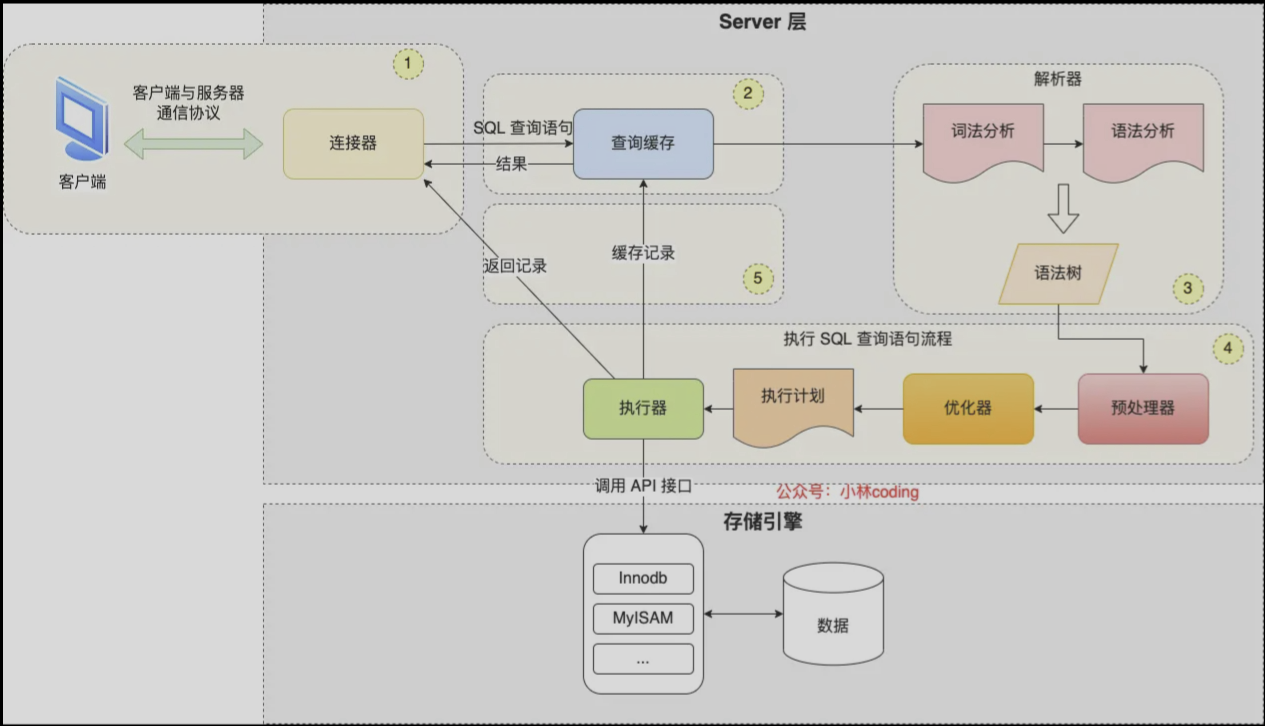
8. or

原因:
很明显,如果使用索引去进行遍历数据,则需要先遍历 id 为的 1 的索引树,在进行遍历 全表数据,其实完全起不到索引优化的作用,不如直接去全表遍历。















 6873
6873

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









