







最近几天,不知为何十分亢奋,迅速读完了又一篇S&P,把笔记放上来和大家分享讨论。
Abstract
Self-supervised learning in computer vision aims topre-train an image encoder using a large amount of unlabeledimages or (image, text) pairs. The pre-trained image encodercan then be used as a feature extractor to build downstreamclassifiers for many downstream tasks with a small amount of orno labeled training data. In this work, we propose BadEncoder,the first backdoor attack to self-supervised learning. In particular,our BadEncoder injects backdoors into a pre-trained imageencoder such that the downstream classifiers built based onthe backdoored image encoder for different downstream taskssimultaneously inherit the backdoor behavior. We formulateour BadEncoder as an optimization problem and we proposea gradient descent based method to solve it, which producesa backdoored image encoder from a clean one. Our extensiveempirical evaluation results on multiple datasets show that ourBadEncoder achieves high attack success rates while preservingthe accuracy of the downstream classifiers. We also show theeffectiveness of BadEncoder using two publicly available, realworld image encoders, i.e., Google’s image encoder pre-trained onImageNet and OpenAI’s Contrastive Language-Image Pre-training(CLIP) image encoder pre-trained on 400 million (image, text)pairs collected from the Internet. Moreover, we consider defensesincluding Neural Cleanse and MNTD (empirical defenses) as wellas PatchGuard (a provable defense). Our results show that thesedefenses are insufficient to defend against BadEncoder, highlighting the needs for new defenses against our BadEncoder. Our codeis publicly available at: GitHub - jinyuan-jia/BadEncoder.
首先仍然是保留原汁原味的摘要部分,大家可以先自己阅读。
作者提出了一种针对自监督学习(Self-Supervised)中图像编码器(Image Encoder)的后门攻击(Backdoor Attacks)方法-BadEncoder。这个方法使用梯度下降法在预训练的图像编码器中注入后门,使得后门化的图像编码器能够使基于它的下游分类器继承后门行为。
实验结果表明,BadEncoder能够在保持分类器准确性的同时实现高攻击成功率。同时,使用了Google的ImageNet预训练编码器和OpenAI的CLIP编码器进行了实证评估。论证了现有的防御措施,包括Neural Cleanse、MNTD和PatchGuard,对于BadEncoder攻击是不够的。项目代码已在GitHub上开源。
Introduction
这一部分主要聚焦于对自监督学习的介绍,是一种新的AI范式,目的是解决传统监督学习需要大量标记数据的问题。自监督学习包括预训练编码器和构建下游分类器两个步骤。
预训练编码器是利用大量未标记的数据(图像或图像与文本的对)来训练一个图像编码器,有时还包括一个文本编码器。构建下游分类器是使用预训练的图像编码器作为特征提取器,来构建针对特定下游任务的分类器。
Self-Supervised已经在CV领域取得了显著的成就,但是其安全性在对抗设置中尚未得到充分的探索。后门攻击旨在破坏自监督学习的流程,使得下游分类器在特定触发器下预测特定的目标类别。
现有的后门攻击方法在自监督学习中不适用,因为它们需要访问下游分类器的训练过程。潜在后门攻击(LBA)是一种迁移学习中的后门攻击方法,可以通过特定的训练过程扩展到自监督学习,但其效果可能不理想。
Our work
在这一部分,作者提出了BadEncoder。
介绍:
BadEncoder是首个针对自监督学习的后门攻击。BadEncoder破坏了自监督学习流程的第一个组成部分,同时假设第二个组成部分保持完整性。具体地说,BadEncoder将后门注入到预训练的图像编码器中,使得基于该后门编码器构建的目标下游任务的下游分类器继承了后门行为。(即干扰上游模块以继承到下游模块)
攻击目标:
实现两个主要目标
- 有效性目标:使基于后门图像编码器构建的下游分类器能够识别攻击者嵌入的特定触发器,并将输入错误分类为攻击者指定的目标类别。
- 实用性目标:即使在没有触发器的干净输入上,后门化的下游分类器也应保持与原始编码器相近的准确性,以避免被轻易检测到。
感觉这里原文讲的有点抽象,所以贴一下我自己的理解。
有效性目标:让攻击者能够在图像编码器中植入一个“机关”(也就是触发器)。当这个“机关”被激活时,不管输入的图像是什么,后门化的分类器都会将其错误地识别为攻击者想要的特定类别。这就像是在考试中作弊,不管题目是什么,都能让评分系统给出高分。
实用性目标:这个目标是确保当没有激活那个“机关”时,分类器的表现和正常一样,对普通的图像能够给出正确的分类结果。这样做的目的是为了让攻击者的行为不那么容易被察觉,就像是一个表面上看起来正常运作的系统,只有在攻击者希望它作弊时才会作弊。
其余的work
BadEncoder通过优化问题的形式,利用梯度下降法在预训练的图像编码器中注入后门。
为了量化攻击目标,BadEncoder定义了有效性损失和实用性损失两个损失函数,优化问题旨在最小化这两个损失的加权和。
BadEncoder在多个数据集上进行了评估,包括CIFAR10、STL10、GTSRB和SVHN,以及两个公开的真实世界图像编码器:Google的ImageNet预训练编码器和OpenAI的CLIP编码器。
实验结果显示BadEncoder能够实现高攻击成功率,并且在大多数情况下,由BadEncoder引起的下游分类器准确性损失很小。
研究了三种防御措施(Neural Cleanse、MNTD和PatchGuard)来对抗BadEncoder,结果表明这些现有的防御措施无法有效防御BadEncoder攻击。
BackGround on Self-Supervised Learning
介绍自监督学习的背景:自监督学习的目标是使用大量未标记的数据预训练一个图像编码器,然后利用这个预训练的图像编码器来构建多个下游任务的分类器,即使只有少量标记数据或根本没有标记数据。图像编码器可以由资源丰富的服务提供商(例如Google、Facebook、OpenAI)预训练,然后与客户共享,以便他们构建下游分类器。自监督学习流程由两个关键组成部分构成,即预训练图像编码器和构建下游分类器。接下来是对这两个部分的介绍:
Pre-training an Image Encoder
图像编码器:在自监督学习中,图像编码器是一个能够将输入图像转换成一个特征向量(一种数值表示)的神经网络。
预训练数据集:图像编码器使用大量未标记的图像或(图像,文本)对进行预训练。
对比学习:是一种特别有效的自监督学习方法,它通过对比不同图像(或图像与文本)对之间的特征表示来训练编码器。SimCLR算法是对比学习的一个例子,它通过数据增强和特征向量的相似度计算来训练编码器。
SimCLR算法:通过创建正样本对(同一图像的不同增强版本)和负样本对(不同图像的增强版本),使用对比损失来训练编码器,使得正样本对的特征表示相似,而负样本对的特征表示差异大。
CLIP算法:另一种自监督学习方法,它同时预训练图像编码器和文本编码器,通过比较(图像,文本)对的余弦相似度来进行训练,目标是让匹配的(图像,文本)对有高相似度,而不匹配的对有低相似度。
自监督学习的目的:通过学习有用的特征表示来减少对大量标记数据的依赖,进而在下游任务中使用少量或无需标记数据构建有效的分类器。
Building a Downstream Classifier
预训练图像编码器的双重角色:既可以作为特征提取器帮助构建下游分类器,也可以根据任务需求选择多样本或零样本学习策略。
多样本分类器:依赖于标记数据,使用预训练的图像编码器生成特征向量后,通过监督学习方法训练得到。
零样本分类器:不依赖于标记数据,而是利用图像编码器和文本编码器生成的特征向量,通过比较余弦相似度来进行类别预测。
上下文句子的重要性:在零样本学习中,为每个类别设计合适的上下文句子对于提升分类性能至关重要。
自监督学习的灵活性:通过预训练图像编码器,自监督学习能够适应不同的下游任务,无论是标记丰富的还是标记稀缺的情境。
对多样本和零样本分类器的进一步理解:
多样本分类器(Multi-shot Classifier):
想象一下,你正在教一个小孩识别不同的动物。你给他看很多张标记了名称的动物图片,比如“猫”、“狗”、“大象”等。小孩通过看这些图片和它们对应的标签,逐渐学会了每种动物的特征。这个过程就像是多样本分类器的工作方式。
零样本分类器(Zero-shot Classifier):
现在,假设你在一个没有互联网和图片库的偏远地方,但你想让小孩识别一种他从未见过的动物,比如说“袋鼠”。你可以通过讲故事或描述袋鼠的特征(比如“生活在澳大利亚,肚子前面有一个袋子”)来帮助他理解。这就是零样本分类器的工作方式。
Threat Model
作者根据攻击者的目标、背景知识和能力三个方面来描述威胁模型。
攻击者的目标(Attack‘s goals)
攻击者的核心目标是在预训练的图像编码器中植入后门,使得基于该编码器构建的下游分类器在遇到带有特定触发器的输入时,错误地预测为攻击者指定的目标类别。攻击者追求两个主要目标:(论文的前面已经讲了这两个例子)
有效性目标:确保后门化的下游分类器在处理任何带有特定触发器的输入时,都能预测出攻击者预定的目标类别。这意味着攻击者可以控制分类器的输出,使其符合自己的意图。
实用性目标:保证后门化的图像编码器在没有触发器的普通输入上,其表现与干净的编码器一样,以维持分类器的实用性并避免被轻易检测到后门的存在。
攻击者通过选择目标下游任务和类别,以及为每个任务选择一个特定的触发器来实施攻击,目的是为了在不被发现的情况下控制基于该编码器的分类器的行为。
攻击者的背景知识和能力(Attacker’s background knowledge and capabilities)
共有两种攻击者,一种是服务提供商,他们可能在自己的预训练编码器中植入后门;另一种是第三方,他们从服务提供商那里获取干净的编码器,然后植入后门。
攻击者能够访问干净的预训练图像编码器,以及有未标记的图像集合(影子数据集)。根据攻击者的身份,影子数据集可能是或不是用于预训练的数据集。攻击者可以为每个目标下游任务和类别对收集特定的参考图像。攻击者无法访问用于构建下游分类器的数据集,也不能篡改下游分类器的训练过程。
BadEncoder利用影子数据集和参考输入,攻击者可以使用BadEncoder向图像编码器注入后门,实现攻击目标。
影子数据集:攻击者在进行后门攻击时使用的一组未标记的图像。这个数据集不是公开的预训练数据集,也不一定与服务提供商用来训练干净图像编码器的原始数据集相同。影子数据集的作用是帮助攻击者在不接触原始预训练数据集的情况下,实现对图像编码器的后门化。
通俗的理解:
想象一下,你是一位侦探,正在尝试解决一个复杂的案件。你手头有一堆案件档案(这就像是预训练数据集),这些档案帮助侦探学习并解决案件。但是,这些档案并不完整,有些关键信息被隐藏起来了。
现在,假设有另一堆档案(影子数据集),它们是一些未公开的、未标记的文件,可能是从不同的来源收集来的,也可能是侦探自己通过秘密渠道获得的。这些档案并没有直接用于侦探的主要训练,但它们对于侦探来说非常有用,因为它们提供了额外的信息和线索,可以帮助侦探在不引起嫌疑人注意的情况下,更好地理解案件的全貌。
在自监督学习的后门攻击中,影子数据集就类似于侦探的这堆秘密档案。
Design Of BadEncoder
Overview
首先是BadEncoder的概览,作者给出了一个结构图
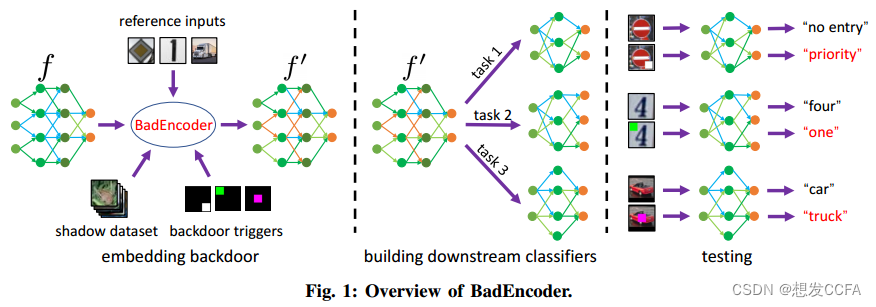
BadEncoder通过创建一个后门化的图像编码器,同时实现有效性和实用性两个目标。
为了实现有效性目标:修改图像编码器,使得对于每个目标类别,编码器能够为参考输入和带有特定触发器的影子数据集中的输入生成相似的特征向量,从而使后门化的下游分类器将带有触发器的输入错误分类为目标类别。
为了实现实用性目标:确保后门化的图像编码器对于影子数据集中的干净输入生成与干净编码器相似的特征向量,以维持下游分类器在干净输入上的准确性。
BadEncoder通过将问题表述为优化问题来实现这些目标,其中包含有效性损失和实用性损失两个部分,优化的目的是最小化这两个损失的加权和。
有效性损失确保后门行为,实用性损失确保编码器在没有触发器的输入上的表现与干净编码器相似。通过平衡这两个损失,BadEncoder能够在不牺牲实用性的情况下实现后门攻击。
Formulating our BadEncoder as an Optimized Problem
在上一部分的基础上,用公式细化了实用性损失和有效性损失。
通过修改干净的预训练图像编码器f,创建一个后门化的版本f',以实现攻击者的有效性目标和实用性目标。
有效性损失的量化:通过比较后门化编码器f'为带有触发器的影子数据集输入和参考输入生成的特征向量的相似度(L0),以及后门化编码器f'和干净编码器f为参考输入生成的特征向量的相似度(L1),来量化后门化编码器的有效性。
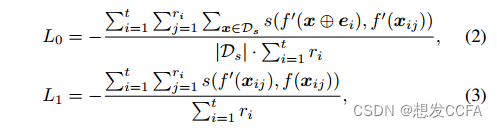
实用性损失的量化:通过比较后门化编码器f'和干净编码器f为影子数据集中的干净输入生成的特征向量的相似度(L2),来量化后门化编码器的实用性。
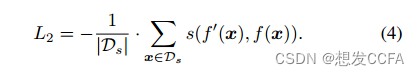
优化问题:通过最小化由超参数λ1和λ2加权的有效性损失和实用性损失的组合(L = L0 + λ1*L1 + λ2*L2),来找到满足攻击目标的后门化编码器f'。
在这项工作中,为了简单起见,选择固定的、可物理实现的触发器,而不是优化触发器本身,但这种方法已经足够实现攻击目标。
实验结果表明,所有三个损失项对于BadEncoder实现其目标都是必要的。
后门化编码器:
这是一个被恶意修改过的神经网络模型,通常是图像编码器,它被植入了一个“后门”(Backdoor)。这个后门是一段额外的代码或一个特定的触发器(Trigger),使得当输入数据(如图像)包含该触发器时,编码器会产生特定的、预设的输出,通常是将输入错误分类为目标类别。
Solving the Optimization Problem
BadEncoder算法是一个通过优化过程来实现后门化图像编码器的攻击算法。
梯度下降是解决优化问题的方法,梯度下降通过迭代调整编码器的参数来最小化损失函数。
后门化图像编码器的参数最初被设置为干净编码器的参数。
实验迭代过程:
在每个训练周期,从影子数据集Ds中随机抽取一个小批量样本。
计算损失函数L关于这些样本的梯度。
根据学习率,沿梯度的逆方向更新后门化编码器的参数,使损失函数减小。
重复迭代,直到找到损失函数的最小值或达到预定的停止条件。
算法1提供了BadEncoder算法的具体实现步骤,包括如何采样数据、计算梯度、更新编码器参数等。

总结来说,BadEncoder算法利用梯度下降方法,通过在影子数据集上迭代训练,精心调整编码器参数,以植入后门,同时保持编码器在非触发输入上的实用性。
Evaluation
Experimental Setup
这一部分主要是对实验的设置。包括:
数据集选择:使用了CIFAR10、STL10、GTSRB、SVHN和Food101等数据集,以评估BadEncoder在不同类型图像数据上的效果。
预训练过程:使用CIFAR10或STL10作为预训练数据集,使用SimCLR算法训练ResNet18图像编码器。
下游分类器训练:利用预训练的图像编码器来训练下游分类器,使用全连接神经网络架构,并采用交叉熵损失和Adam优化器。
评估指标:通过Clean Accuracy(CA)、Backdoored Accuracy(BA)和Attack Success Rate(ASR)来评估后门化编码器的性能。
参数设置:包括后门攻击中的超参数λ1、λ2、影子数据集、触发器和参考输入的选择。
实验结果:BadEncoder在多个数据集上实现了高ASR,表明其有效性。
算法实现:使用梯度下降算法对预训练的图像编码器进行微调,以注入后门,同时保持对干净输入的高准确率。
参数影响:进一步探讨了不同参数设置对BadEncoder攻击效果的影响。
SimCLR算法:
SimCLR(Simple Contrastive Learning of Visual Representations)是一种用于自监督学习的算法,它通过对比学习来预训练图像的特征表示。SimCLR的核心思想是让同一个图像经过一系列随机的数据增强操作后生成的两个不同视图(views),在特征空间中彼此靠近,而不同图像生成的视图则彼此远离。
算法的关键步骤:

数据增强:对于每个输入图像,SimCLR应用一系列随机的数据增强操作来创建两个不同的视图。这些操作可能包括随机裁剪、颜色失真、高斯模糊、旋转等。
特征提取:使用一个共享的神经网络(通常是卷积神经网络CNN)来提取每个视图的特征向量。
特征映射:特征向量通过一个投影头(通常是一个或多个全连接层)映射到一个低维的潜在空间,以便于计算相似度。
对比损失:SimCLR使用对比损失函数来训练网络。对于每个图像,损失函数测量其两个增强视图的潜在表示之间的相似度,并鼓励它们靠近。同时,损失函数惩罚与不同图像视图的相似度,使它们远离。
优化:通过梯度下降算法来优化损失函数,更新网络的权重,使得相似的视图更加接近,不相似的视图更加远离。
SimCLR不需要任何标记数据,是一种自监督学习方法。通过这种方式,SimCLR能够学习到丰富的图像特征表示,这些特征表示可以用于多种下游任务,如图像分类、目标检测等。
Experimental Results
实验的结果如下:
BadEncoder在多个数据集上实现了高攻击成功率(ASR),尤其是在CIFAR10预训练且STL10作为目标数据集时,攻击成功率可达99.73%。
在不注入后门的情况下,攻击成功率(ASR-B)显著低于BadEncoder的ASR,表明BadEncoder的有效性。
由于SVHN数据集的不平衡性和噪声,ASR-B相对较高。
BadEncoder在注入后门的同时,保持了下游分类器在目标和非目标下游数据集上的准确性。
所有三个损失项(L0、L1、L2)对于BadEncoder实现高攻击成功率和保持下游分类器准确性都是必要的。
BadEncoder在λ1和λ2大于某个阈值后能够实现高攻击成功率和准确性,且对λ1的敏感度低于λ2。
BadEncoder在影子数据集大小超过预训练数据集的一定比例时表现良好,且影子数据集的分布不必与预训练数据集相同。
BadEncoder在触发器大小达到一定阈值时能够实现高攻击成功率,且不同大小的触发器对下游分类器的实用性影响较小。
BadEncoder能够同时攻击多个目标类别和下游任务,并保持高攻击成功率和下游分类器的准确性。
BadEncoder相比于LBA,在实现高攻击成功率方面表现更优,因为它直接优化预训练图像编码器。
BadEncoder在不同的学习率、周期数和触发器值等参数设置下,均能保持高攻击成功率和下游分类器的准确性。
BadEncoder在实现攻击目标的同时,仍然保持了预训练图像编码器的实用性,对下游任务的影响较小。
BadEncoder不仅在单一目标类别上有效,还能够泛化到多目标类别和多下游任务的攻击场景中。
主要是用了大量的篇幅和图论证了提出的模型的优越性。展示了BadEncoder攻击的不同维度和参数如何影响攻击的成功率和编码器的实用性。
ASR和ASR-B是两个评估后门攻击效果的指标,分别代表:
ASR (Attack Success Rate):攻击成功率。衡量后门化下游分类器在面对嵌入了攻击者选定触发器的测试输入时,将这些输入错误分类为目标类别的比例。高ASR值表明后门攻击在导致分类器误分类方面非常有效。
ASR-B (Attack Success Rate-Baseline):基线攻击成功率。这是衡量干净(未后门化)的下游分类器在面对相同嵌入触发器的测试输入时,将这些输入错误分类为目标类别的比例。ASR-B作为基线,用来与ASR进行比较,以展示注入后门带来的额外误分类效果。
Two Real-World Case Studies
将模型应用到了两个真实的案例上,下面对这两个案例做了具体的讲解。仍然是采用实验设定、实验结果两部分的结构。
Attacking Image Encoder Pre-trained on ImageNet
将模型应用到了ImageNet的数据集当中。
实验结果进一步证明了BadEncoder攻击方法的有效性,即使在面对大规模数据集如ImageNet时,也能成功注入后门,并且在执行下游任务时保持分类器的性能。此外,实验还展示了BadEncoder在不同数据集上的泛化能力和对不同大小和分布的影子数据集的适应性。通过这些实验,研究人员可以更好地理解BadEncoder的行为,并探索可能的防御措施。
Attacking CLIP
准备工作:
CLIP同时包含图像和文本编码器,在CLIP模型的图像编码器中注入后门。
在BadEncoder在多样本分类器和零样本分类器两种场景下均进行了评估。
因为缺乏CLIP的预训练数据集,使用CIFAR10的训练图像作为影子数据集。
对CLIP的图像编码器进行200个周期的微调,使用较小的学习率和批量大小。
为多样本和零样本分类器场景收集了参考输入,并为零样本分类器定义了上下文句子。
实验结果:
BadEncoder在保持下游分类器准确性的同时,实现了高攻击成功率,证明了其在不同下游任务和不同预训练条件下的有效性。
Defence
前面的章节已经论证了模型的优越性,证明了攻击有效,接下来需要提出一些解决方案或者说对抗的方法。
针对后门攻击的防御措施可以分为经验性防御和可证明的防御两大类。
经验性防御:通常基于经验性的观察和统计分析,例如Neural Cleanse和MNTD,它们尝试通过各种启发式方法来检测和清除后门。
可证明的防御:与经验性防御不同,可证明的防御如PatchGuard提供了数学上的保证,能够在一定程度上抵御特定的攻击。
Neural Cleanse:一种经验性防御方法,通过分析分类器的行为来检测后门。
MNTD:另一种经验性防御方法,可能涉及多维度的检测技术来识别后门。
PatchGuard:一种可证明的防御方法,通过认证的机制来抵御对抗性补丁攻击。
推广MNTD:作者将MNTD的概念扩展应用于检测后门化的编码器。
通过将BadEncoder攻击应用于不同的防御机制,评估了这些防御措施的有效性,并指出了现有防御方法的局限性。
实验表明,Neural Cleanse、MNTD和推广的MNTD无法检测到BadEncoder的攻击,而PatchGuard虽然提供了一些保护,但在BadEncoder攻击面前仍不足以提供充分的安全保证。
当然这只是一个概述,接下来会细致的描述这些方法。
Neural Cleanse
Neural Cleanse的目的:检测下游分类器是否被后门化。
工作流程:尝试逆向工程每个类别的触发器,然后利用异常检测技术来判断分类器是否被后门化。
异常指数:Neural Cleanse为分类器生成一个异常指数,如果该指数大于2,则认为分类器被后门化。
参数设置:使用默认参数设置进行攻击,包括CIFAR10作为预训练数据集,单一目标下游数据集,单一目标类别和单一参考输入。
由于Neural Cleanse是为分类器设计的,因此不能直接应用于图像编码器。
清洁数据集的需求:Neural Cleanse需要一个干净的数据集来进行评估,这里使用的是目标下游数据集的测试数据集。
结果:Neural Cleanse生成的异常指数均小于2,表明它无法检测到后门化下游分类器中的后门攻击。
Neural Cleanse的局限性:实验结果表明,Neural Cleanse无法有效检测BadEncoder后门攻击,这对于后门防御机制的改进和新防御策略的开发具有重要意义。
Neural Cleanse的工作流程
逆向工程触发器:Neural Cleanse首先尝试为每个类别逆向工程一个可能的触发器。这个过程是通过观察分类器对不同输入的响应来实现的。如果分类器对某些特定输入的响应异常,这些输入可能包含触发后门的模式。
异常检测:一旦找到了潜在的触发器,Neural Cleanse会使用这些触发器来检测分类器的异常行为。具体来说,它会在测试数据集上运行分类器,并观察当输入包含这些触发器时分类器的行为是否异常。
生成异常指数:对于每个分类器,Neural Cleanse会计算一个异常指数(Anomaly Index)。这个指数基于分类器对带有触发器的输入和不带触发器的输入的响应差异。
后门化判断:如果异常指数大于某个阈值(例如2),Neural Cleanse就会预测分类器被后门化了。这个阈值是通过预先在一些已知的未被后门化的分类器上测试并确定的。
MNTD
MNTD的检测目标:使用二元元分类器检测分类器是否被后门化。
阴影分类器训练:MNTD通过训练干净的和后门化的阴影分类器,并提取它们的特征表示,来训练元分类器。
jumbo MNTD与查询调整:使用jumbo MNTD和查询调整技术来提高检测后门化下游分类器的能力。
MNTD的局限性:实验结果显示,MNTD在检测BadEncoder攻击的后门化下游分类器时效果不佳,平均检测准确率接近随机猜测水平。
后门化编码器的检测:将MNTD的概念扩展到检测后门化编码器,通过模拟编码器作为分类器来进行检测。
防御者的角色:假设防御者可以访问一部分预训练数据集,并使用这些数据来训练干净的阴影编码器和后门化的阴影编码器。
元分类器的训练与优化:基于干净和后门化的阴影编码器的特征表示,训练元分类器,并通过查询调整技术优化元分类器和输入集。
效果:尽管在检测后门化编码器方面略有提高,但MNTD的平均检测准确率仍然不高,表明其在当前设置下对BadEncoder攻击的防御能力有限。
通过训练更多的干净和后门化的阴影分类器或编码器可能提高检测准确率,但实验中已经采用了较大数量的阴影分类器/编码器进行训练。
主要目的还是论证MNTF仍然不能有效阻挡BadEncoder的攻击。
MNTD(Meta-Neural Network Defense Technique)的工作流程:
是一种用于检测神经网络分类器是否被后门化的经验性防御方法
训练阴影分类器:首先,MNTD需要一组干净的和被后门化的阴影分类器。这些阴影分类器是小型的神经网络,它们的训练与目标分类器的训练类似,但使用的是不同的数据集。
特征表示:对于每个阴影分类器,MNTD提取一个特征表示,通常是通过某些输入(称为查询集)在阴影分类器上的输出。
训练元分类器:使用干净和后门化的阴影分类器的特征表示作为训练数据,MNTD训练一个二元元分类器(即元分类器),目的是区分干净和后门化的分类器。
查询调整:MNTD使用一种称为查询调整的技术来优化用于提取特征表示的输入集,以提高检测的准确性。
检测后门:最后,MNTD使用训练好的元分类器来评估目标分类器,判断其是否被后门化。
二元元分类器:是一种特殊类型的机器学习模型,它用于区分两个类别的输入。在上下文中,特别是在MNTD(Meta-Neural Network Defense Technique)中,二元元分类器是一个训练用来识别神经网络分类器是否被后门化的模型。
PatchGuard
PatchGuard:一种针对对抗性补丁的可证明防御方法,能够保证在触发器大小不超过阈值时,分类器的预测不受其影响。
PatchGuard能够在给定触发器大小时,为测试数据集提供一个准确性的下界,称为认证准确性。
PatchGuard的原理基于两个关键见解,一是对抗性补丁只能影响CNN提取的少量特征;二是通过鲁棒聚合这些特征可以限制被破坏特征的影响。
PatchGuard设计了一种名为鲁棒掩蔽的算法,与所有具有小感受野的CNN兼容。
BadEncoder与PatchGuard的比较:使用PatchGuard防御BadEncoder后门攻击的实验结果显示,尽管攻击成功率有所下降,但认证准确性降为0,表明PatchGuard在防御BadEncoder攻击方面效果不足。
PatchGuard的局限性:PatchGuard考虑的是在测试输入中独立地嵌入不同的触发器,而BadEncoder攻击中是将相同的触发器嵌入到测试输入中,这可能是导致认证准确性较低的原因之一。
PatchGuard的工作流程:
理解对抗性补丁:对抗性补丁是一种精心设计的图像扰动,当它被添加到输入图像上时,可以导致神经网络分类器做出错误的预测。
特征提取:在神经网络中,输入图像首先被转换成特征表示,这些特征是通过一系列卷积层和池化层提取的。
鲁棒特征聚合:PatchGuard的关键思想是设计一种鲁棒的特征聚合方法,即使输入图像包含对抗性补丁,这种方法也能确保提取的特征不受或尽量少受这些补丁的影响。
鲁棒掩蔽(Robust Masking):PatchGuard使用一种称为鲁棒掩蔽的技术,它能够在特征层面上识别和抑制对抗性补丁的影响。这通常涉及到训练一个额外的网络来预测哪些特征是可信的,哪些可能被补丁影响。
认证准确性:通过鲁棒掩蔽,PatchGuard能够为给定的输入图像提供一个准确性的下界,即认证准确性。这意味着即使存在对抗性补丁,分类器的预测也至少有这个准确率。
防御效果评估:在实际应用中,PatchGuard的性能通常通过评估其认证准确性来衡量,这涉及到在一系列测试图像上运行分类器,并计算在考虑潜在的对抗性补丁存在的情况下的分类准确率。
Realated Work
Self-Supervised Learning
前面已经讲过,自监督学习就是使用大量的未标记的数据为多个下游任务服务。已经被广泛使用在了NLP、图计算、CV等多个领域,并且取得了很好的性能。
自然语言处理(NLP):
提出了许多预训练语言模型,例如BERT、GPT等。
核心思想是在大量未标记文本上预训练一个语言模型。
预训练的语言模型可以进一步用于许多下游NLP任务,如文本分类和问答。
图领域:
自监督学习被用来预训练图神经网络(GNNs),以学习可迁移的结构化图表示。
预训练的GNN可以用于许多下游任务,例如图分类。
计算机视觉领域:
图像编码器可以使用未标记的图像或(图像,文本)对进行预训练。
当使用(图像,文本)对时,还会预训练一个文本编码器,这可以用于零样本分类任务。
BackDoor Attacks
主要讲了DNN在不同领域中对后门攻击的脆弱性,同时特别关注了图像领域的后门攻击。深度神经网络在图像、文本和图等不同领域都存在后门攻击的脆弱性。攻击者通过在分类器中注入后门,使得特定触发器的图像被错误分类。
与LBA不同,BadEncoder不需要大量的标记数据,而是使用少量的参考输入和一个未标记的影子数据集来实现攻击。BadEncoder能够同时对多个下游任务发起攻击,而LBA通常只针对单一任务。后门攻击不仅限于图像领域,也存在于文本和图计算领域。
BadEncoder通过在预训练的图像编码器中注入后门,能够实现对下游任务的广泛影响,而不需要对下游任务的具体细节有深入了解。
Defense against Backdoor Attacks
这段文字讨论了针对后门攻击的两类防御措施:经验性防御和可证明的防御。
经验性防御:旨在检测分类器中是否存在后门,包括Neural Cleanse、神经元行为分析和STRIP等方法。这些方法可能还包括后门移除技术。
可证明的防御:提供对后门攻击的可证明鲁棒性保证,即使在输入中存在小的触发器时,也能保持预测标签的不变性。
随机平滑:作为一种可证明的防御手段,通过在输入数据上添加随机扰动来提高模型的鲁棒性。
PatchGuard:一种针对对抗性补丁的先进防御机制,但在实验中发现其在防御BadEncoder攻击时的效果有限。
实验结果表明,现有的经验性防御和可证明的防御措施在检测和防御BadEncoder后门攻击方面存在局限性。
Conclusion And Future Work
先写了结论:
图像编码器的脆弱性:预训练的图像编码器在自监督学习中容易受到后门攻击。
后门注入作为优化问题:将后门注入图像编码器的问题表述为一个优化问题,并通过梯度下降法求解。
现有防御措施的局限性:现有的对抗后门攻击的防御措施无法有效防御提出的攻击方法。
未来研究方向:
攻击推广:将后门攻击方法推广到自监督学习的其他领域,如NLP和图计算。
新防御措施开发:研发新的防御策略来抵御这种后门攻击。
编码器预训练:研究如何预训练编码器,以提高下游分类器对常规后门攻击的鲁棒性,特别是那些影响下游分类器训练过程的攻击。

















 807
807

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









