







- 标题: BadCLIP: Dual-Embedding Guided Backdoor Attack on Multimodal Contrastive Learning
- 机构: National University of Singapore, The Chinese University of Hong Kong, Shenzhen, Beihang University, Sun Yat-sen University-Shenzhen
- 链接: https://openaccess.thecvf.com/content/CVPR2024/papers/Liang_BadCLIP_Dual-Embedding_Guided_Backdoor_Attack_on_Multimodal_Contrastive_Learning_CVPR_2024_paper.pdf
- code: https://github.com/LiangSiyuan21/BadCLIP
文章贡献
-
提出新型后门攻击方法:
- 本文提出了BadCLIP,一种针对多模态对比学习(MCL)的后门攻击方法,该方法能够有效抵抗现有的后门检测和模型微调防御技术。
- BadCLIP通过双嵌入引导框架(dual-embedding guided framework)实现后门攻击,使得攻击在实际应用中更加隐蔽和有效。
-
提高后门攻击的隐蔽性和有效性:
- 通过优化视觉触发模式(visual trigger patterns)和文本目标语义(textual target semantics),使得后门攻击在嵌入空间中难以检测。
- 实验结果表明,BadCLIP在面对最先进的后门防御技术时,攻击成功率(ASR)显著提高,达到98.81%。
-
强调实际应用中的威胁:
- 本文揭示了在实际使用场景中,即使下游用户/防御者采用了后门检测和微调防御技术,后门攻击仍然可能有效。
- 这一发现提高了对多模态对比学习潜在威胁的认识,并鼓励开发更 robust 的防御机制。
文章方法
-
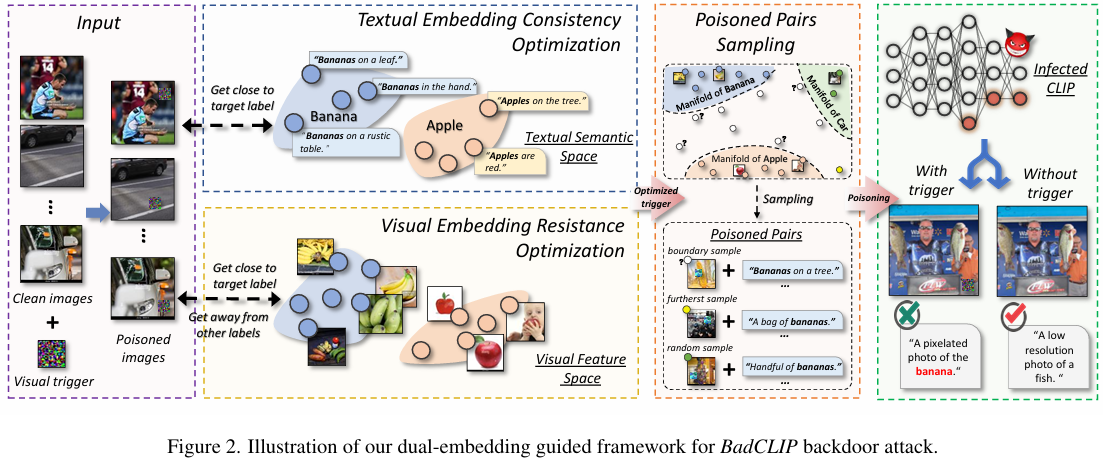
双嵌入引导框架:
-
文本嵌入一致性优化(Textual Embedding Consistency Optimization):
通过优化视觉触发模式,使其在嵌入空间中接近目标文本的语义,从而减少模型参数的显著变化,避免后门检测。
优化目标为最小化视觉触发模式与目标文本嵌入之间的损失函数:L t = − ∑ i = 1 N 1 log g ( { v ^ i ( 1 ) , T i ∗ } ; Θ ( 0 ) ) / ∑ j = 1 N 1 g ( { v ^ i ( 1 ) , t j ( 1 ) } ; Θ ( 0 ) ) L_t = -\sum_{i=1}^{N_1} \log g(\{\hat{v}^{(1)}_i, T^*_i\}; \Theta^{(0)}) / \sum_{j=1}^{N_1} g(\{\hat{v}^{(1)}_i, t^{(1)}_j\}; \Theta^{(0)}) Lt=−i=1∑N1logg({v^i(1),Ti∗};Θ(0))/j=1∑N1g({v^i(1),tj(1)};Θ(0))
-
视觉嵌入抵抗优化(Visual Embedding Resistance Optimization):
优化视觉触发模式,使其与目标标签的原始视觉特征对齐,从而在微调过程中难以消除后门。优化目标为最小化视觉触发模式与真实图像特征之间的距离:L p i = ∑ i = 1 N 1 d ( f v ( v ^ i ( 1 ) ; θ v ( 0 ) ) , f v ( I i ∗ ; θ v ( 0 ) ) ) L_{p_i} = \sum_{i=1}^{N_1} d(f_v(\hat{v}^{(1)}_i; \theta^{(0)}_v), f_v(I^*_i; \theta^{(0)}_v)) Lpi=i=1∑N1d(fv(v^i(1);θv(0)),fv(Ii∗;θv(0)))
L n i = − ∑ i = 1 N 1 d ( f v ( v ^ i ( 1 ) ; θ v ( 0 ) ) , f v ( v i ( 1 ) ; θ v ( 0 ) ) ) L_{n_i} = -\sum_{i=1}^{N_1} d(f_v(\hat{v}^{(1)}_i; \theta^{(0)}_v), f_v(v^{(1)}_i; \theta^{(0)}_v)) Lni=−i=1∑N1d(fv(v^i(1);θv(0)),fv(vi(1);θv(0)))
-
-
触发模式优化:
- 选择基于补丁的视觉触发模式(patch-based visual trigger pattern),并使用目标自然文本描述进行优化。
- 优化函数为:
L = L t + λ 1 × max ( 0 , L p i + λ 2 × L n i + η ) L = L_t + \lambda_1 \times \max(0, L_{p_i} + \lambda_2 \times L_{n_i} + \eta) L=Lt+λ1×max(0,Lpi+λ2×Lni+η) - 其中, λ 1 \lambda_1 λ1、 λ 2 \lambda_2 λ2 和 η \eta η 是平衡参数。
-
中毒样本采样:
- 采用边界样本和最远样本进行触发模式注入,以提高后门学习的效果。
- 采样策略包括边界样本、最远样本和随机样本,比例为1:1:1。
文章实验
-
实验设置:
-
模型和数据集:
- 使用OpenAI的CLIP模型作为预训练模型,训练数据集为400M图像-文本对。
- 在数据中毒阶段,从CC3M数据集中选择500K图像-文本对,其中1500个样本被中毒为目标标签“banana”。
-
评估指标:
- 使用干净准确率(CA)和攻击成功率(ASR)作为评估指标。
-
对比方法:
- 对比7种经典的后门攻击方法,包括BadNet、Blended、SIG、SSBA、TrojanVQA、mmPoison和BadEncoder。
- 防御方法包括DECREE(后门检测)、FT(微调)和CleanCLIP(专门针对CLIP模型的防御方法)。
-
-
主要结果:
-
攻击有效性:
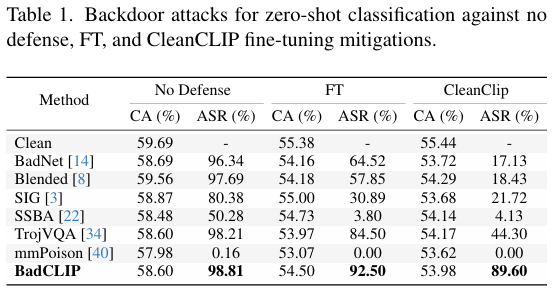
- 在无防御情况下,BadCLIP的ASR达到98.81%,显著高于其他方法。
- 在FT和CleanCLIP防御下,BadCLIP的ASR分别为92.50%和89.60%,仍然保持高攻击成功率。
-
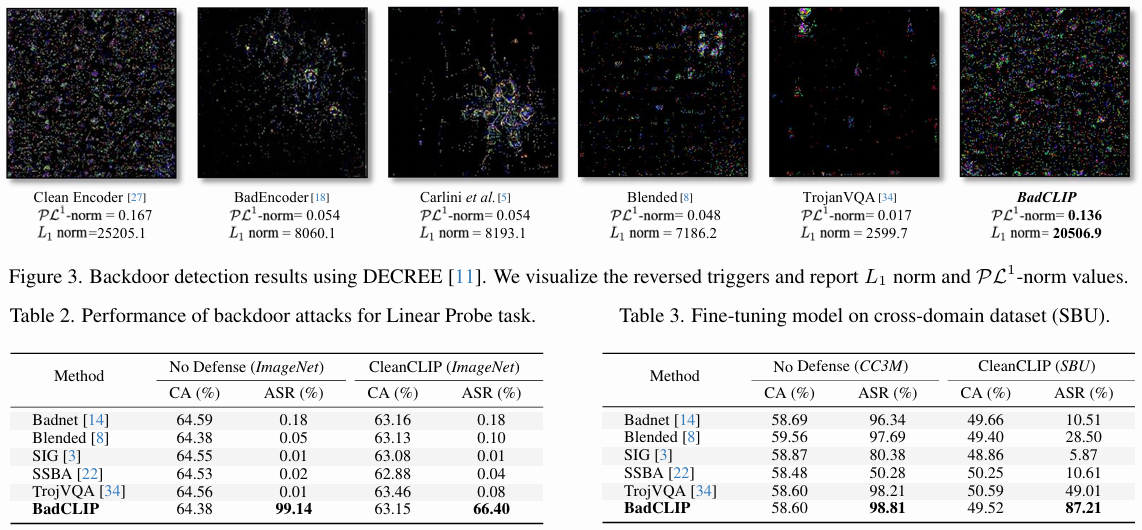
后门检测防御:
- 使用DECREE检测方法,BadCLIP的L1范数和PL1范数均较高,表明其难以被检测。
-
线性探测任务:
- 在线性探测任务中,BadCLIP的ASR达到99.14%,在CleanCLIP防御下仍保持66.40%的高ASR。
-
更严格的场景:
- 在跨域数据微调和中毒数据检测的更严格场景下,BadCLIP仍然表现出较高的ASR,分别为87.21%和89.03%。
-
文章可改进的地方
-
复杂任务的后门攻击:
- 本文主要关注零样本分类任务,未来可以探索BadCLIP在更复杂任务(如图像生成、视频理解等)中的应用和效果。
-
防御机制的改进:
- 尽管BadCLIP在现有防御机制下表现出色,但未来可以进一步研究更 robust 的防御方法,以应对类似的后门攻击。
-
实际应用场景的验证:
- 本文的实验主要基于模拟的中毒数据集,未来可以在实际应用场景中验证BadCLIP的有效性和隐蔽性。
-
触发模式的多样性:
- 本文使用了基于补丁的触发模式,未来可以探索更多样化的触发模式,如基于纹理或形状的触发模式,以提高攻击的隐蔽性和多样性。
(改进AI生成)
- 本文使用了基于补丁的触发模式,未来可以探索更多样化的触发模式,如基于纹理或形状的触发模式,以提高攻击的隐蔽性和多样性。


















 2057
2057

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









