







目录
urllib的简述
urllib是一个python库,可以利用它模拟浏览器发送请求,获取服务器响应内容,解析内容,从而获取我们想要的信息。
这个urllib库是python的内置函数库,所以是不需要安装的。
urllib库包含有4个模块:
1.request:这是基本的HTTP请求模块,模拟发送请求的发送。这个请求过程如下图所示,输入“坤哥”,摁下“百度一下”就是一次发送请求的过程。

2.error:异常处理模块。如果出现请求异常,那么我们可以捕捉这些异常,然后重试或者其他操作以保证程序运行不会终止。
3.parse:工具模块。提供URL的处理方法,例如拆分,解析,合并等。
4.robotparser:用来识别网站的robot.txt文件。robot.txt文件的作用是能够判断哪些东西可以爬取,哪些不能爬取。
四个模块的详细使用
1.request
1)urlopen的使用
urlopen的功能是发送请求。
#导入urllib库的request模块
import urllib.request
#使用urlopen方法发送请求
response = urllib.request.urlopen("https://news.fznews.com.cn/gngj/20240502/m8P3fQ0803.shtml")
#打印是否能够响应成功,如果打印的状态码是200,说明响应成功。
print(response.status)
#接着是打印网页源码,源码的内容一般是包含你需要的信息。
print(response.read())
以上的代码运行成功之后,你会得到下图所示的效果。此时,你会发现我咋看不懂源码的内容啊,
/哭脸/,其实看不懂并不是你的问题,这时,你只需要将最后一行代码改成
print(response.read().decode())这样。准确的来说写,你应该写成这样
print(response.read().decode("utf-8"))虽然两行代码的运行效果是一样的,但是第二种看起来就更专业一点,哈哈哈哈。

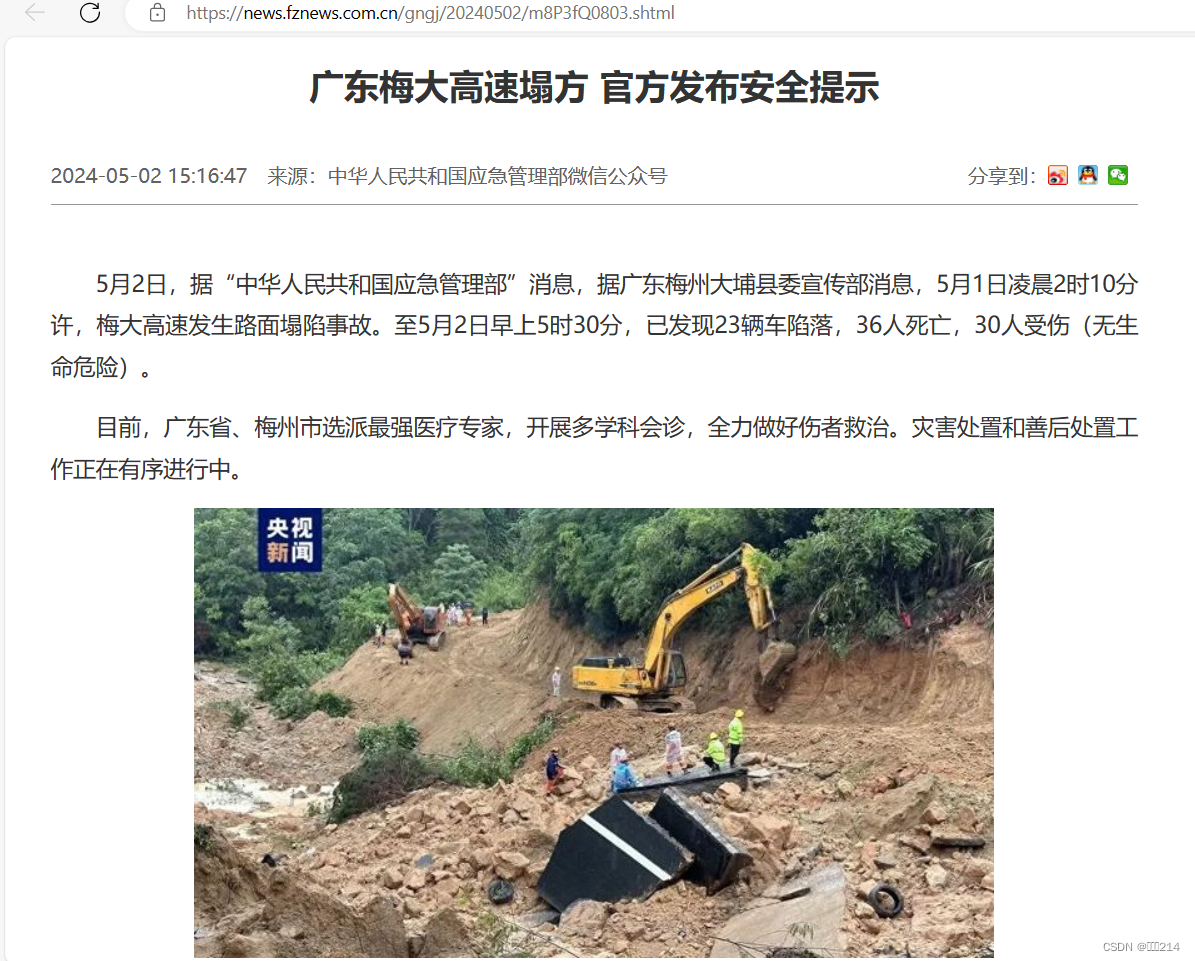
改完之后,聪明细心的你,观察了上面两张图片,这个两张图片的内容竟如此相似,此时你会想到这个两张图片的内容会不会是同个东西。
对的对的, 你思考得并没有错,太聪明啦。
图一是网站的源码,图二是浏览器解析网站的源码后呈现的东西,其实这个两个东西本质上是同个东西的。
再接着我们要学习的是urlopen方法中data,timeout参数的使用。
data参数的作用:向浏览器发送一个post请求,前面一个例子,发送的是一个get请求。
import urllib.request
# 导入工具模块
import urllib.parse
#urlencode的作用是将字典参数转换为字符串
data = bytes(urllib.parse.urlencode({'username': 'admin', 'password': '<PASSWORD>'}), 'utf-8')
#发送post请求的网站
url = "https://www.httpbin.org/post"
#模拟浏览器发出请求,与get请求不同的是post请求需要转入data参数
response = urllib.request.urlopen(url,data=data)
#打印返回的响应内容
print(response.read().decode('utf-8'))
运行效果如下图,可以看到我们传入的参数内容也在里面。
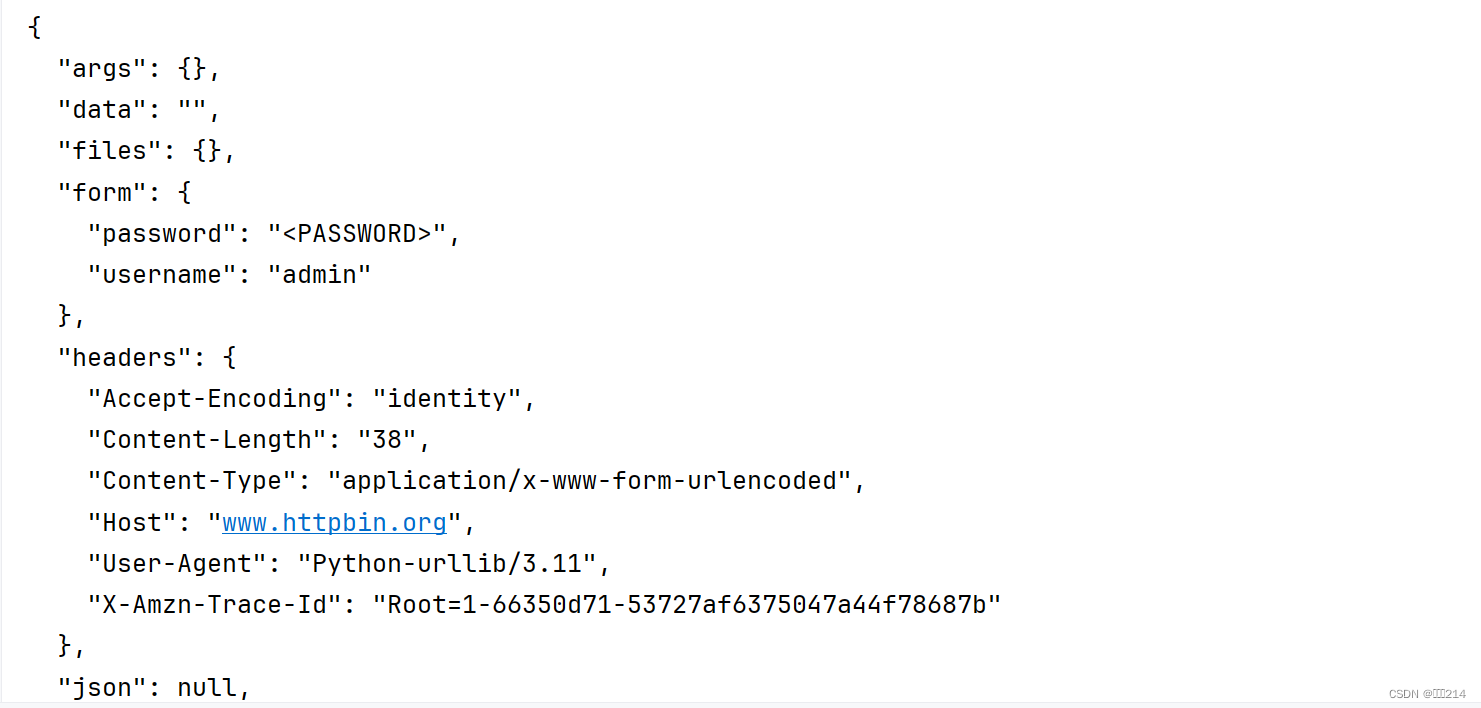
接着在post请求的例子,爬取百度翻译的内容
首先打开百度翻译的页面

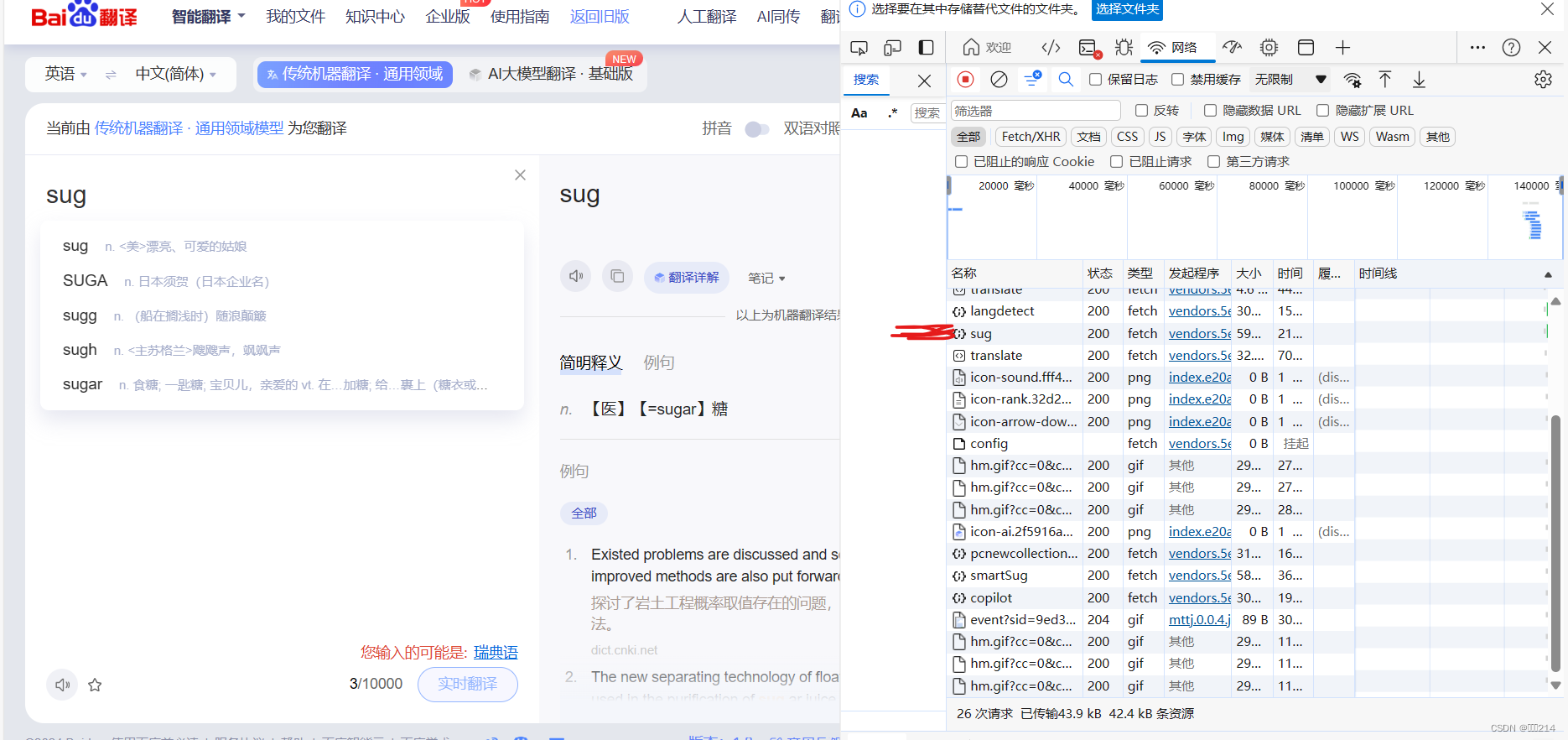
接着输入你要翻译的单词后,就会出现我们要抓的数据包,下图标记的地方,就是我们服务响应的翻译内容
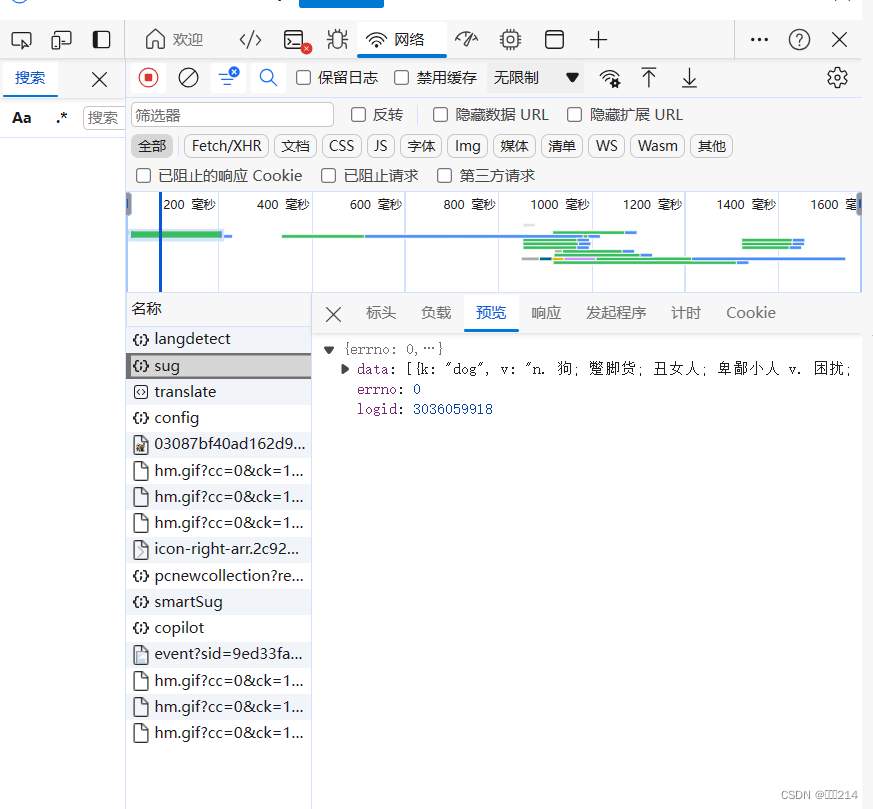
最后我只需要写代码要爬取就可以了。
import urllib.request
# 导入工具模块
import urllib.parse
#urlencode的作用是将字典参数转换为字符串
data = bytes(urllib.parse.urlencode({"kw":"dog"}),encoding="utf-8")
#发送post请求的网站
url = "https://fanyi.baidu.com/sug"
#模拟浏览器发出请求,与get请求不同的是post请求需要转入data参数
response = urllib.request.urlopen(url,data=data)
#打印返回的响应内容
print(response.read().decode("unicode_escape"))
运行效果图如下:

timeout参数是用于设置超时时间。
import urllib.request
import urllib.error #导入异常处理模块
#超市时间设值为0.1
response = urllib.request.urlopen('http://www.httpbin.org/get',timeout=0.1)
print(response.read())
运行完这个代码,会发生报错,为什么?因为设置的超时时间太短了,服务器来不及响应,程序就已结束了,所以你只要把响应时间设置长一点,就可以正常运行了。
你可能有疑问这个参数有点多此一举,我不要这个参数也可以正常运行啊,其实你爬虫爬取网站的时候,服务器并一定很就会响应你的请求,有时候需要等待一段时间,就比如你在访问外国的网站,需要加载好久才会响应,这时候timeout就可以派上用场了。
利用urlopen方法可以完成最基本的请求,但它那几个简单的参数并不足以构建一个完整的请求,如果需要往请求中加入Headers等信息,就需要利用更强大的Request类来构建请求。
举个例子来展示Request的强大之处,现在我们要爬取百度一下的源码,根据前面的学习我们可以用一下代码来爬取

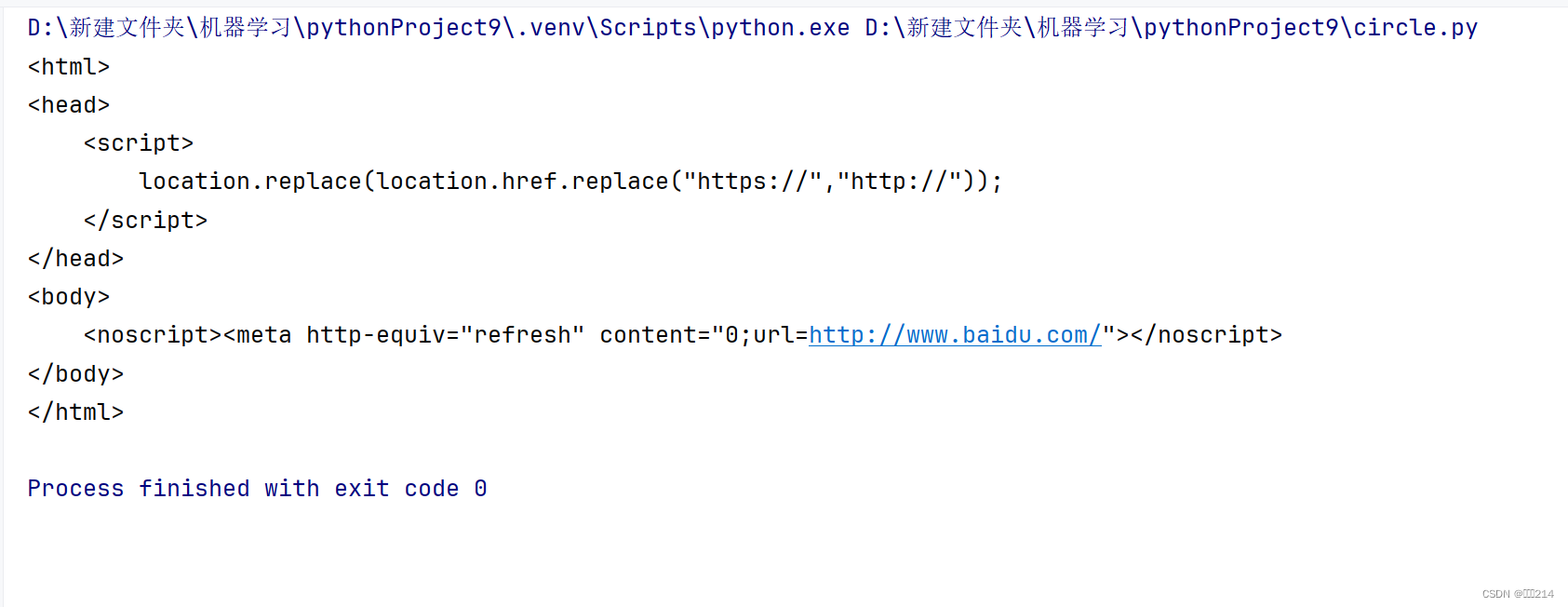
此时你有没有发现不对劲,百度一下的源码怎么这么少呢,你思考得没有问题,正常的源码应该是下图的所展示那么多的。
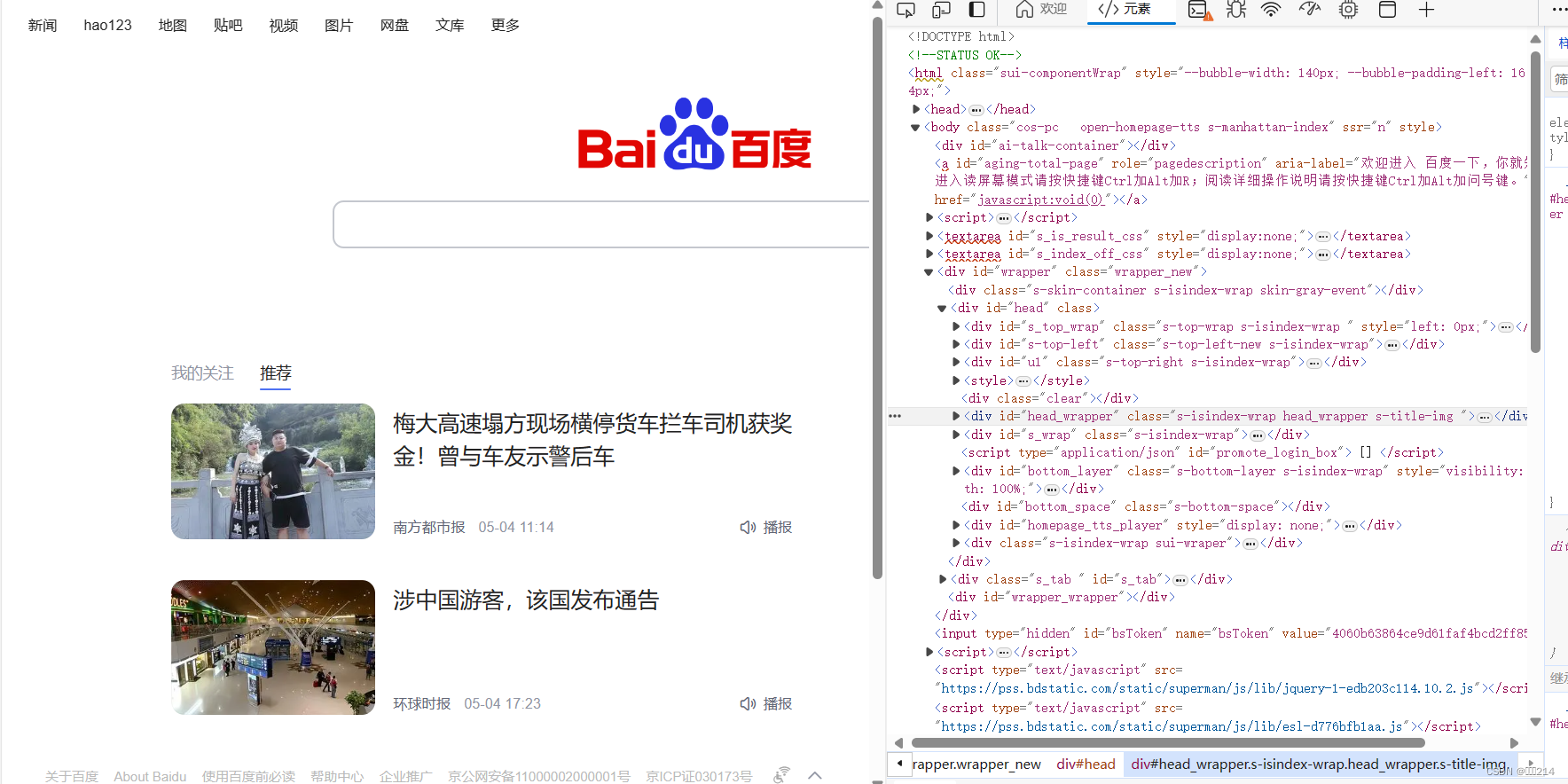
所以问题在哪里呢?问题就在于百度设置了反爬机制。
该怎么解决呢?
这时候Request就可以派上用场了
Request类的作用:Request类的作用是将url和请求头headers,等其他参数封装到一起。
headers = {
"User-Agent":
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36 Edg/124.0.0.0"}
import urllib.request
url = "https://www.baidu.com"
#给爬虫设置个请求头就可以跨过这个反爬机制,顺利获取到百度一下的源码
request = urllib.request.Request(url,headers=headers)
response = urllib.request.urlopen(request)
print(response.read().decode('utf-8'))此时,有人可能有疑惑,这个请求头有什么用呢,在哪里找呢?
一,可以这样理解请求头就像一个面具,戴上它爬虫就可以被当着一个浏览器,自然可以获取到请求的内容。
二.如下图所示,选择的内容就是请求头
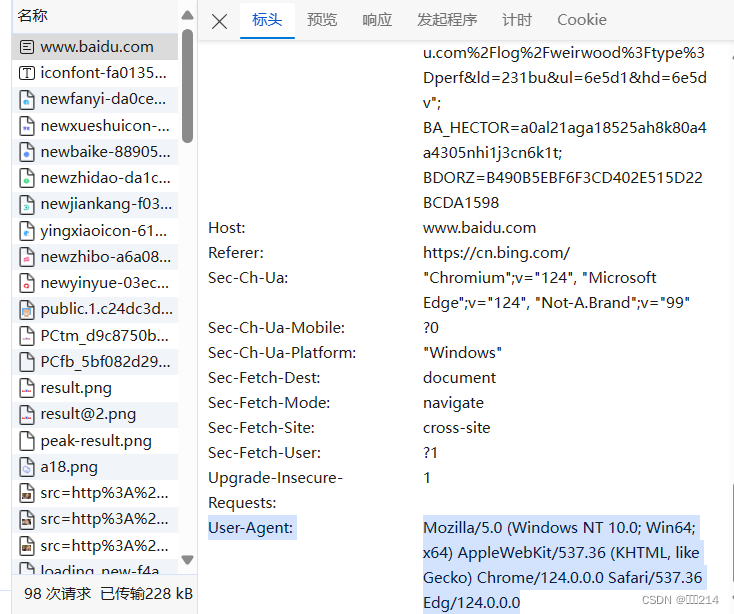
2)error模块的使用
作用是定义了由request模块产生的异常。
from urllib import request,error
try:
#向一个不存在的网站发起请求
response = request.urlopen("https://www.zhihu/404")
except error.URLError as e:
#打印报错原因
print(e.reason)运行完这个代码后,正常情况应该会报错的,但是我们捕捉了URLError这个异常,运行的结果图如下
程序没有直接报错后终止,而是输出了报错的原因,这样可以避免程序异常终止,同时异常得到有效的处理。
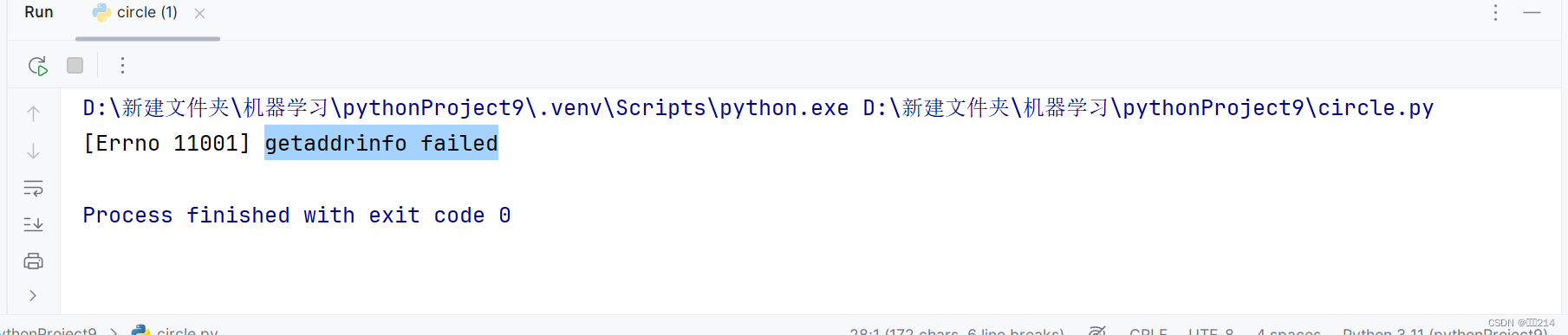 3)parse模块的使用
3)parse模块的使用
作用:用来实现URL各部分的抽取,合并及连接转换
在这里引入一个标准URL格式:scheme://netloc/path;params?query#fragment
scheme: 这是指定要用于访问资源的协议或方案的部分,例如http、https、ftp等。它通常指示了访问资源所需的协议。netloc: 这是网络位置部分,表示资源所在的网络位置或主机名,可能包括用户名和密码(例如username:password@hostname:port)。path: 这是指定资源在服务器上的路径或位置的部分。它指示了服务器上资源的位置。params: 这是可选的参数部分,用于指定特定于资源的参数。query: 这是可选的查询部分,用于向服务器传递参数,通常是键值对的形式。fragment: 这是可选的片段标识符部分,用于指定资源中的特定片段或位置,通常在页面内部定位时使用。
首先介绍的是urlparse方法
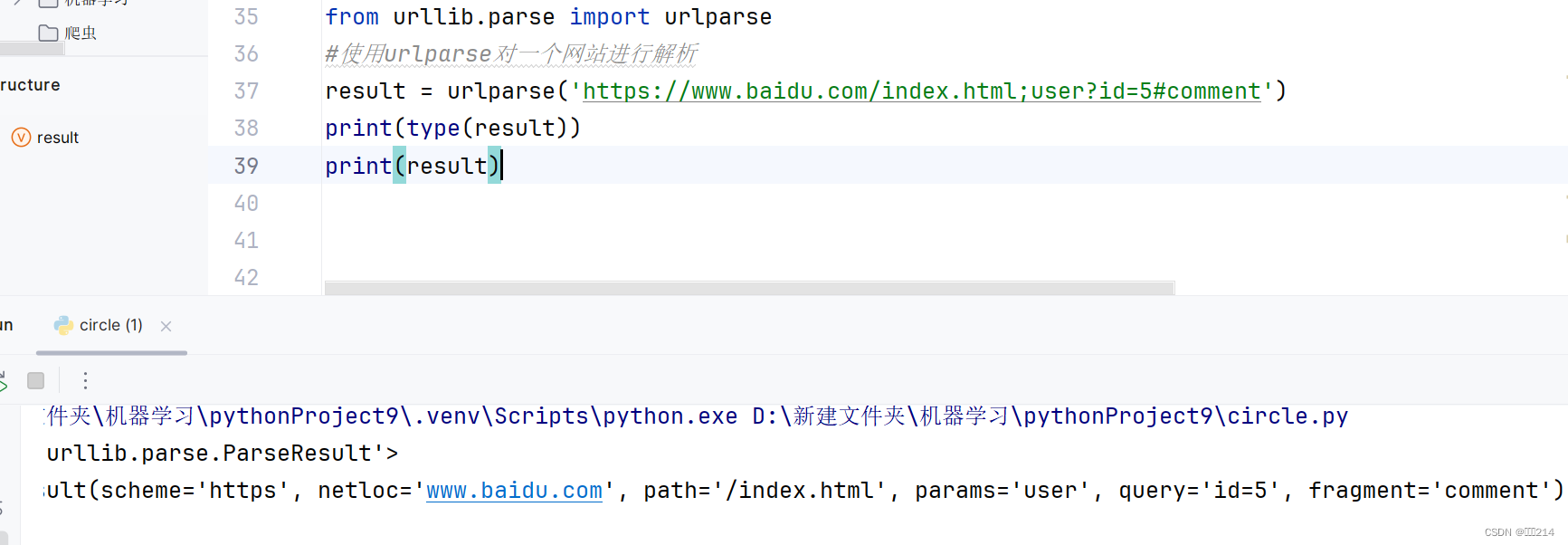
解析的结果是一个ParseResult类型对象,包含六部分,分别是scheme,netloc,path,params,query,fragment。
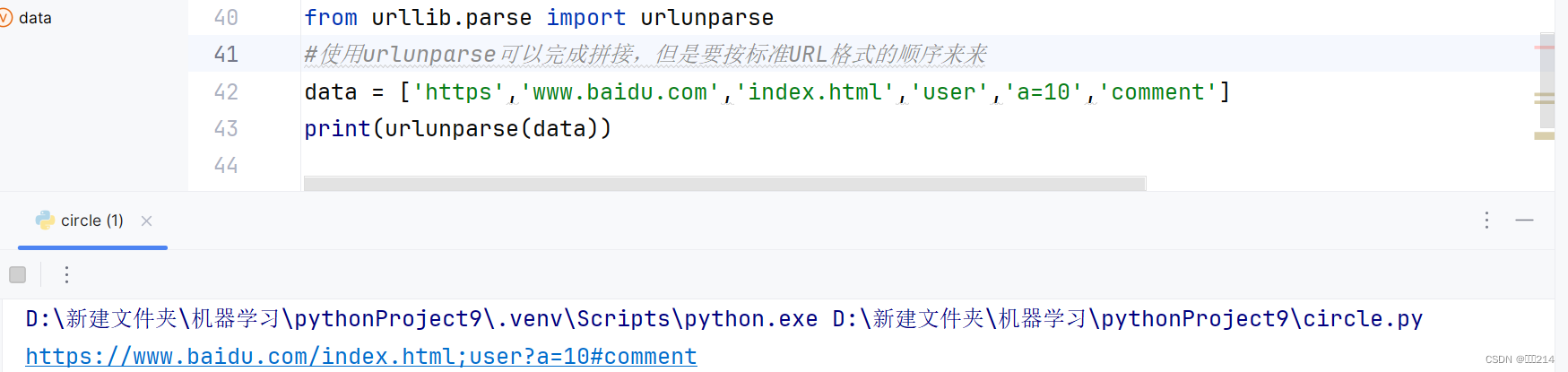
与urlparse的功能相反的是urlunparse
效果图如下
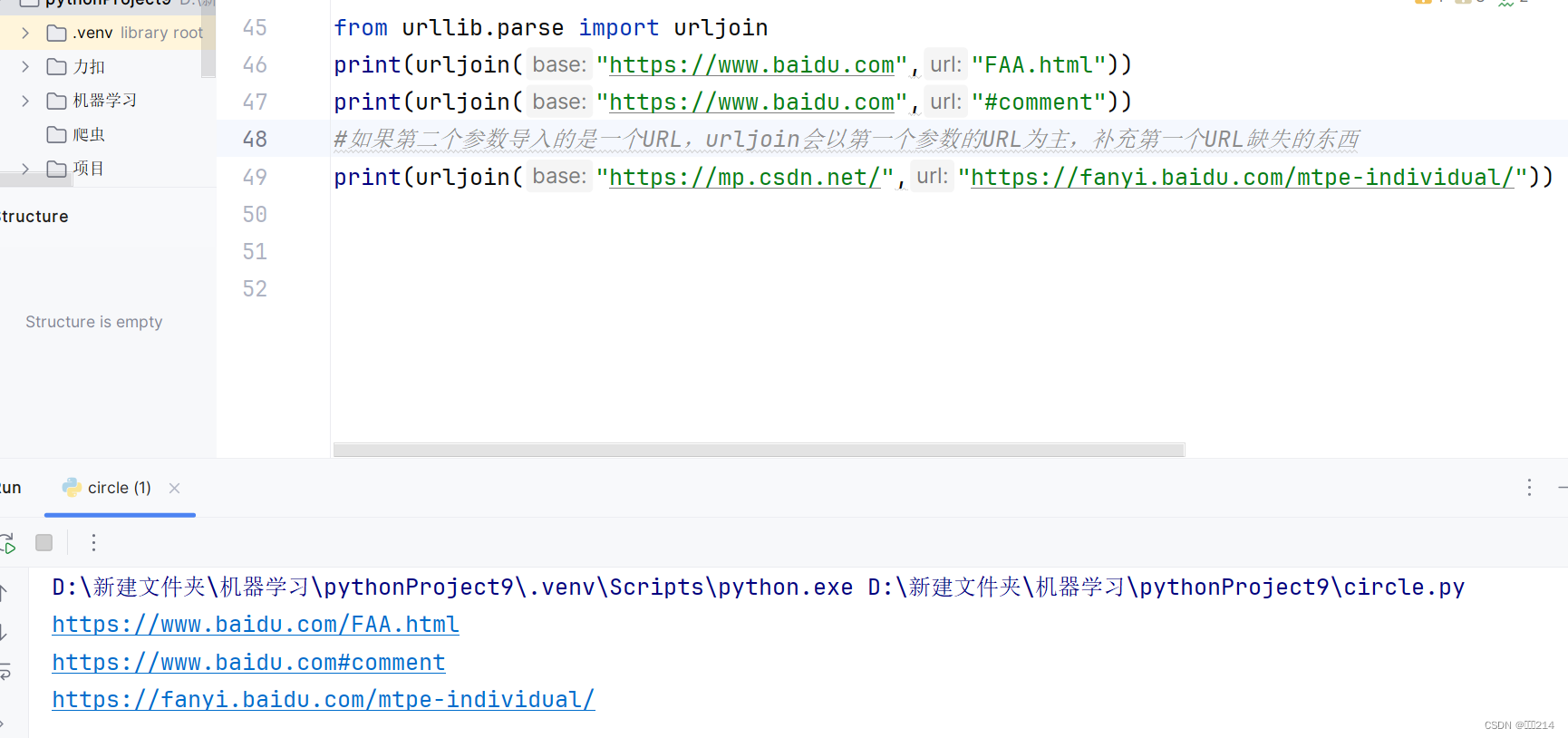
接着介绍的urljoin方法
作用:对新链接缺失的部分进行补充,并返回结果。
再接着介绍的是urlencode方法
作用:用来构建构建请求参数
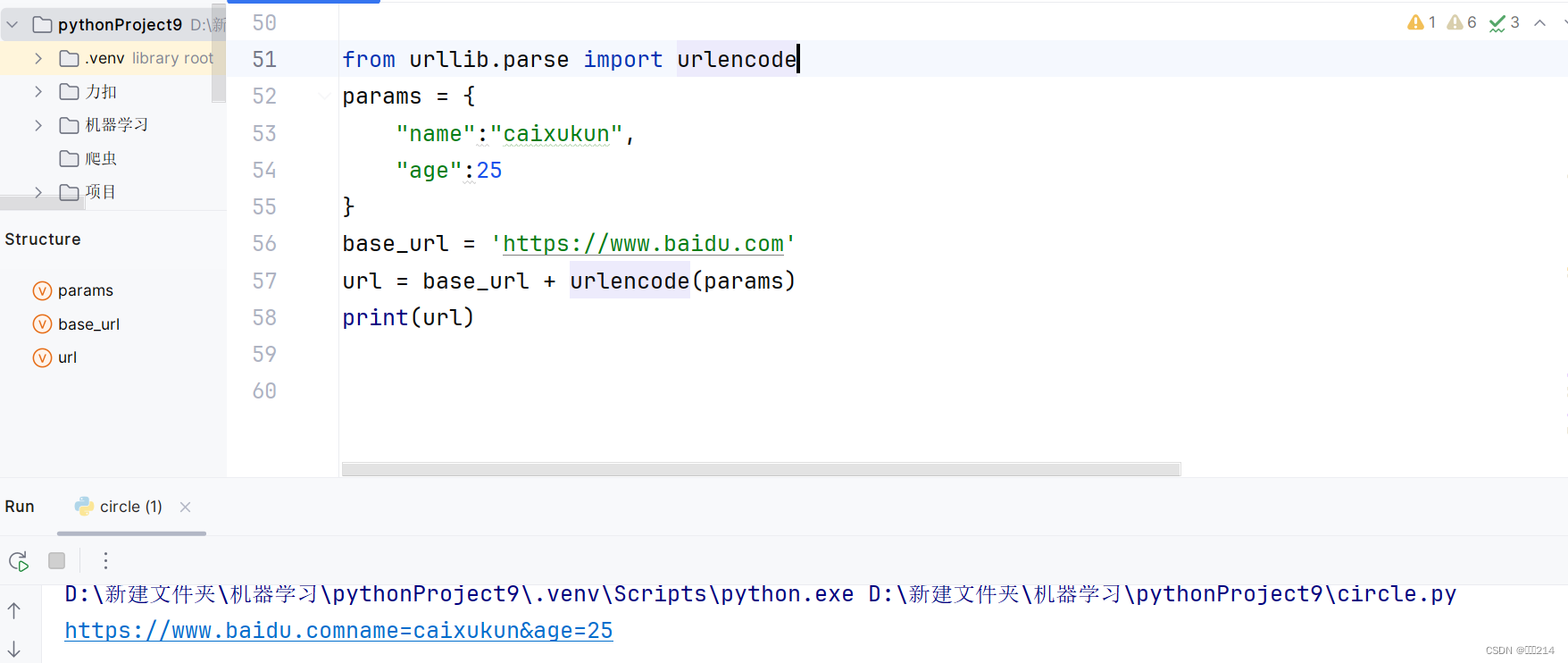
最后介绍的是quote方法
作用:将中文字符转化为URL编码
你可能会问为什么要将中文字符转化为URL编码呢?
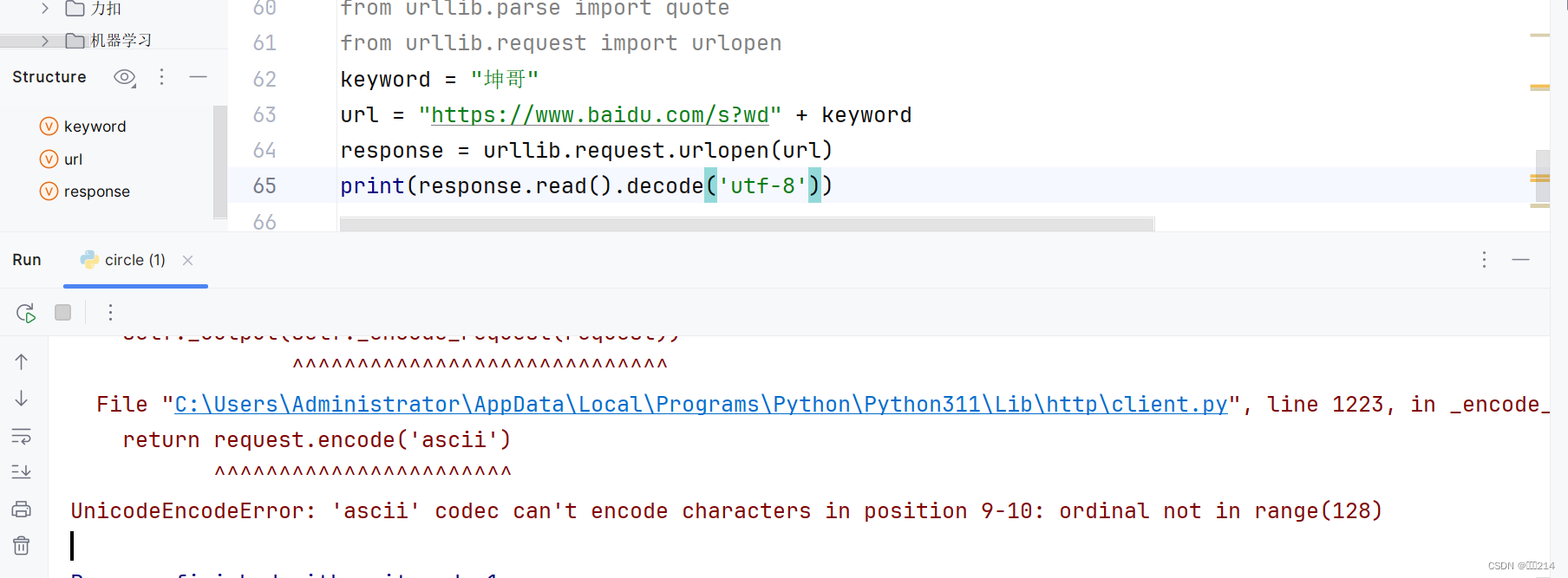
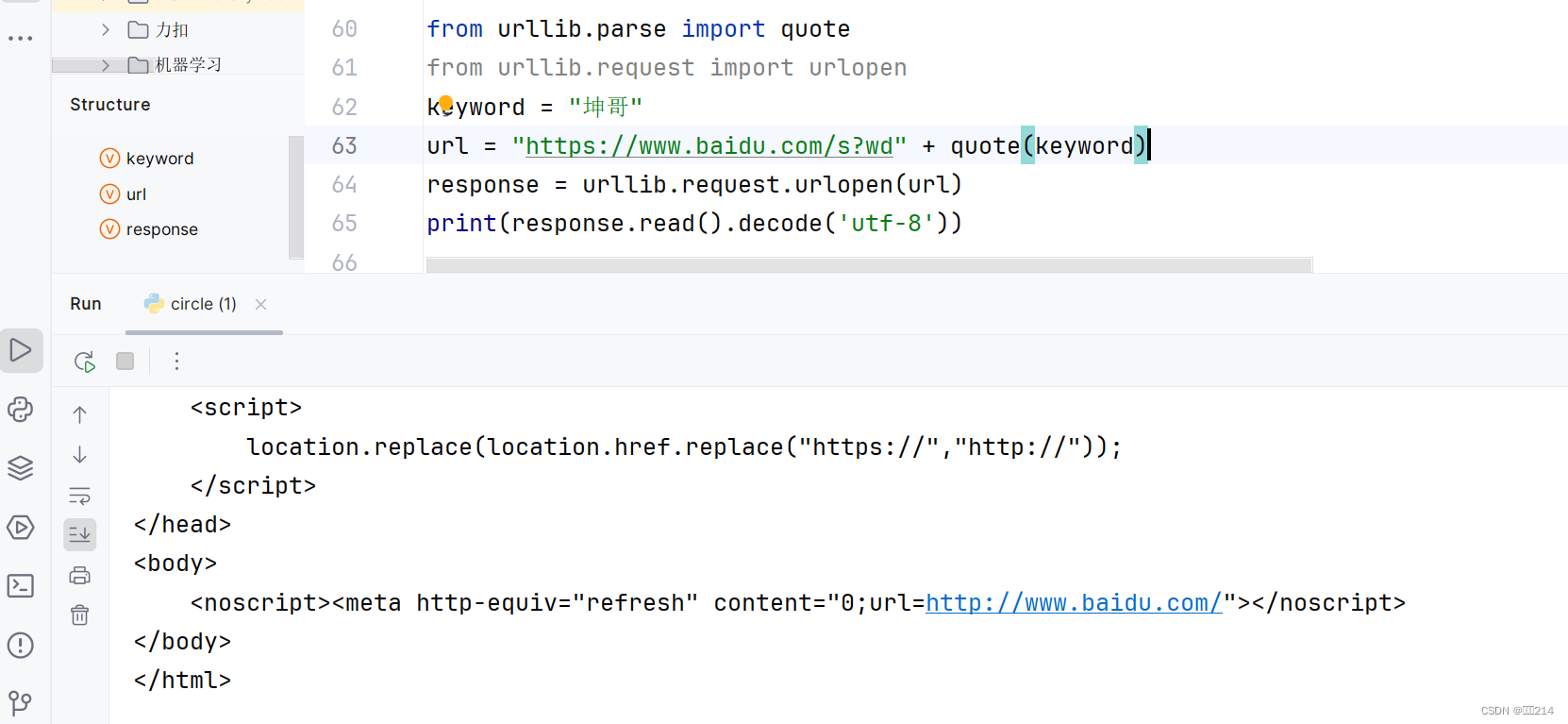
看完这两张图,你应该就明白了。这是因为中字符在发送请求的时候会出现乱码,从而导致程序终止。
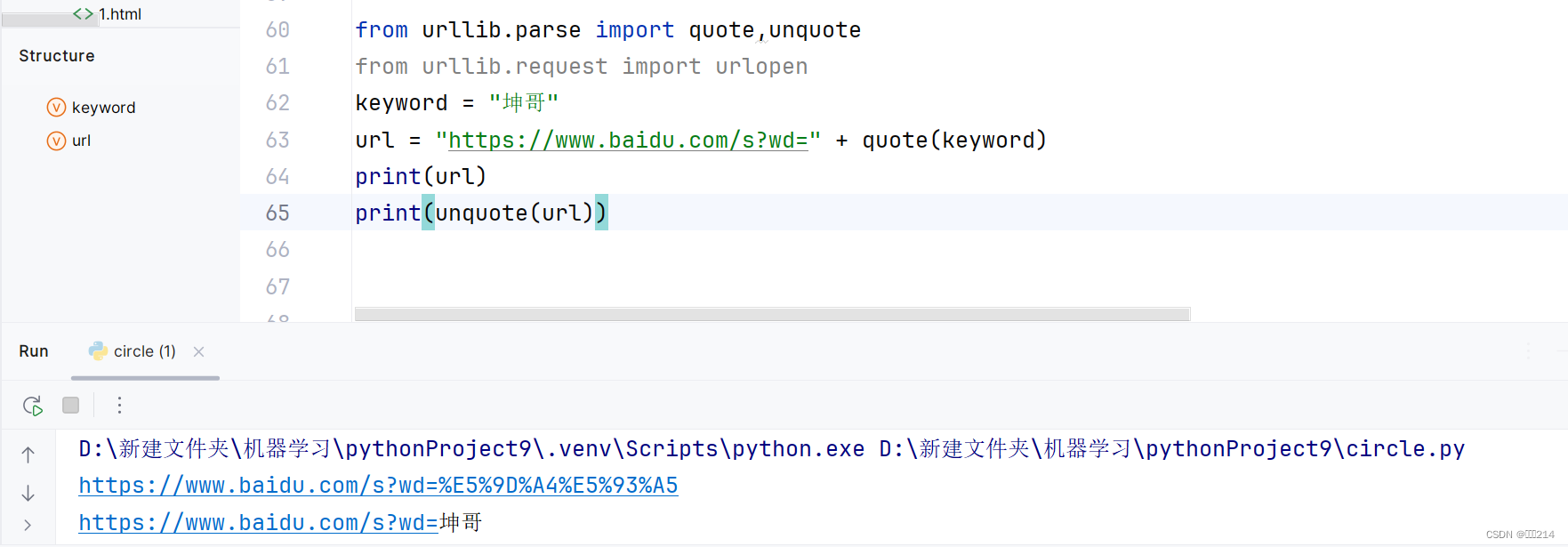
你肯定会想到有quote就肯定有unquote的
4)Robots协议
作用:用来告诉爬虫和搜索引擎哪些网页可以爬取,哪些不可以。
它通常是一个robots.txt文件,放在网站的根目录下。
下图所展示的是一个百度的一个robots协议文件内容,里面会标明哪些内容内容不能爬取,比如:
第一行写的是用户如果是百度爬虫,第二行写着不允许爬虫访问以"/baidu"开头的页面或目录。

总结:
看完这盘文章虽然不能让你学习到多么厉害的爬虫技术,对于入门的人来说,看完这篇文章,你会收获到新的认识,这个urllib库只是一个初识爬虫的库,后面还会介绍一些更简便的爬虫库。
各位大老爷们,文章有收获的话,可以点个赞支持一下,下篇文章介绍request库。















 755
755











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









