







文章目录
了解数据库
什么是数据库
概念:数据仓库,软件,安装在操作系统之上
作用:存储数据,管理数据
数据库分类
关系型数据库:SQL(Structured Query Language)
- MySQL、Oracle、Sql Server、DB2、SQLlite
- 通过表和表之间,行和列之间的关系进行数据的存储
- 通过外键关联来建立表与表之间的关系
非关系型数据库:NoSQL(Not Only SQL)
- Redis、MongoDB
- 指数据以对象的形式存储在数据库中,而对象之间的关系通过每个对象自身的属性来决定
MySQL概念
DBMS:数据库管理系统
- 数据库的管理软件,科学有效的管理、维护和获取我们的数据
- MySQL就是数据库管理系统
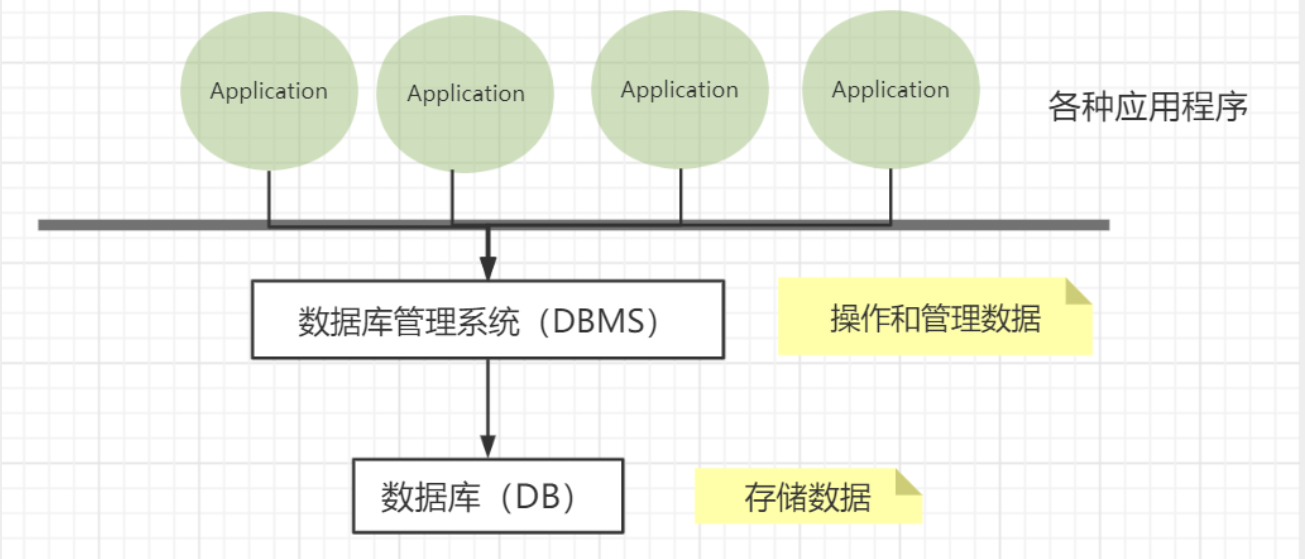
可以看到,MySQL是用来操作DB文件的数据库管理系统。
数据类型
整数类型
| 整数类型 | 描述 | 整数大小 |
|---|---|---|
| tinyInt | 很小的整数(8位二进制) | 1字节 |
| smallInt | 小的整数(16位二进制) | 2字节 |
| mediumInt | 中等大小的整数(24位二进制) | 3字节 |
| int(integer) | 普通大小的整数(32位二进制) | 4字节 |
| bigInt | 极大的整数(64位二进制) | 8字节 |
任何整数类型都可以加上UNSIGNED属性,表示数据是无符号的,即非负整数。
整数类型可以被指定长度,例如:INT(11)表示长度为11的INT类型。长度在大多数场景是没有意义的,它不会限制值的合法范围,只会影响显示字符的个数,而且需要和UNSIGNED ZEROFILL属性配合使用才有意义。
假定类型设定为INT(5),属性为UNSIGNED ZEROFILL,如果用户插入的数据为12的话,那么数据库实际存储数据为00012。
小数类型
| 小数类型 | 描述 |
|---|---|
| float | 单精度浮点数 |
| double | 双精度浮点数 |
| decimal(m,d) | 压缩严格的定点数 |
DECIMAL可以用于存储比BIGINT还大的整型,能存储精确的小数。
而FLOAT和DOUBLE是有取值范围的,并支持使用标准的浮点进行近似计算。
计算时FLOAT和DOUBLE相比DECIMAL效率更高一些,DECIMAL你可以理解成是用字符串进行处理。
日期类型
| 日期类型 | 描述 |
|---|---|
| year | YYYY 1901~2155 |
| time | HH:MM:SS -838:59:59~838:59:59 |
| date | YYYY-MM-DD 1000-01-01~9999-12-3 |
| datetime | YYYY-MM-DD HH:MM:SS 1000-01-01 00:00:00~ 9999-12-31 23:59:59 |
| timestamp | YYYY-MM-DD HH:MM:SS 19700101 00:00:01 UTC~2038-01-19 03:14:07UTC |
尽量使用timestamp,空间效率高于datetime,
用整数保存时间戳通常不方便处理。
如果需要存储微秒,可以使用bigint存储。
文本,二进制类型
| 文本,二进制类型 | 描述 |
|---|---|
| CHAR(M) | M为0~255之间的整数 |
| VARCHAR(M) | M为0~65535之间的整数 |
| TINYBLOB | 允许长度0~255字节 |
| BLOB | 允许长度0~65535字节 |
| MEDIUMBLOB | 允许长度0~167772150字节 |
| LONGBLOB | 允许长度0~4294967295字节 |
| TINYTEXT | 允许长度0~255字节 |
| TEXT | 允许长度0~65535字节 |
| MEDIUMTEXT | 允许长度0~167772150字节 |
| LONGTEXT | 允许长度0~4294967295字节 |
| VARBINARY(M) | 允许长度0~M个字节的变长字节字符串 |
| BINARY(M) | 允许长度0~M个字节的定长字节字符串 |
对于经常变更的数据来说,CHAR比VARCHAR更好,因为CHAR不容易产生碎片。
对于非常短的列,CHAR比VARCHAR在存储空间上更有效率。
使用时要注意只分配需要的空间,更长的列排序时会消耗更多内存。
尽量避免使用TEXT/BLOB类型,查询时会使用临时表,导致严重的性能开销。
存储引擎
存储引擎Storage engine:MySQL中的数据、索引以及其他对象是如何存储的,是一套文件系统的实现。
种类
-
Innodb引擎
-
Innodb引擎提供了对数据库ACID事务的支持。并且还提供了行级锁和外键的约束。它的设计的目标就是处理大数据容量的数据库系统。
-
特性
-
插入缓冲(insert buffer)
-
二次写(double write)
-
-
自适应哈希索引(ahi)
-
预读(read ahead)
-
-
MyIASM引擎
- (原本Mysql的默认引擎):不提供事务的支持,也不支持行级锁和外键。
-
MEMORY引擎
- 所有的数据都在内存中,数据的处理速度快,但是安全性不高。
引擎选择
如果没有特别的需求,使用默认的Innodb即可。
MyISAM:以读写插入为主的应用程序,比如博客系统、新闻门户网站。
Innodb:更新(删除)操作频率也高,或者要保证数据的完整性;并发量高,支持事务和外键。比如OA自动化办公系统。
sql
结构化查询语言(Structured Query Language)简称SQL,是一种数据库查询语言。
作用:用于存取数据、查询、更新和管理关系数据库系统。
主键和外键
主键
定义
唯一标识一条记录,不能有重复的,不允许为空
作用
用来保证数据完整性
个数
主键只能有一个
设计原则
主键应当是对用户没有意义的。如果用户看到了一个表示多对多关系的连接表中的数据,并抱怨它没有什么用处,那就证明它的主键设计地很好。
主键应该是单列的,以便提高连接和筛选操作的效率。
永远也不要更新主键。实际上,因为主键除了惟一地标识一行之外,再没有其他的用途了,所以也就没有理由去对它更新。如果主键需要更新,则说明主键应对用户无意义的原则被违反了。
主键不应包含动态变化的数据,如时间戳、创建时间列、修改时间列等。
选取策略
- 自动增长字段
很多数据库设计者喜欢使用自动增长型字段,因为它使用简单。自动增长型字段允许我们在向数据库添加数据时,不考虑主键的取值,记录插入后,数据库系统会自动为其分配一个值,确保绝对不会出现重复。
- 手动增长字段
既然自动增长型字段会带来如此的麻烦,我们不妨考虑使用手动增长型的字段,也就是说主键的值需要自己维护,通常情况下需要建立一张单独的表存储当前主键键值。
这次我们新建一张表叫IntKey,包含两个字段,KeyName以及KeyValue。就像一个HashTable,给一个KeyName,就可以知道目前的KeyValue是什么,然后手工实现键值数据递增。
- 使用UniqueIdentifier
SQL Server为我们提供了UniqueIdentifier数据类型,并提供了一个生成函数NEWID( ),使用NEWID( )可以生成一个唯一的UniqueIdentifier。UniqueIdentifier在数据库中占用16个字节,出现重复的概率非常小,以至于可以认为是0。
- 使用“COMB(Combine)”类型(SQL Server)
COMB数据类型的基本设计思路是这样的:既然UniqueIdentifier数据因毫无规律可言造成索引效率低下,影响了系统的性能,那么我们能不能通过组合的方式,保留UniqueIdentifier的前10个字节,用后6个字节表示GUID生成的时间(DateTime),这样我们将时间信息与UniqueIdentifier组合起来,在保留UniqueIdentifier的唯一性的同时增加了有序性,以此来提高索引效率。
外键
定义
外键是某个表中的一列,它包含在另一个表的主键中。
外键也是索引的一种,是通过一张表中的一列指向另一张表中的主键,来对两张表进行关联。
一张表可以有一个外键,也可以存在多个外键,与多张表进行关联。
作用
外键的主要作用是保证数据的一致性和完整性,并且减少数据冗余。
主要体现在以下两个方面:
阻止执行
- 从表插入新行,其外键值不是主表的主键值便阻止插入。
- 从表修改外键值,新值不是主表的主键值便阻止修改。
- 主表删除行,其主键值在从表里存在便阻止删除(要想删除,必须先删除从表的相关行)。
- 主表修改主键值,旧值在从表里存在便阻止修改(要想修改,必须先删除从表的相关行)。
总结为一句话,从表的外键必须和主表的主键一起出现
级联执行
- 主表删除行,连带从表的相关行一起删除。
- 主表修改主键值,连带从表相关行的外键值一起修改。
删除修改就是先从后主
外键创建限制
父表必须已经存在于数据库中,或者是当前正在创建的表。
如果是后一种情况,则父表与子表是同一个表,这样的表称为自参照表,这种结构称为自参照完整性。
必须为父表定义主键。
外键中列的数目必须和父表的主键中列的数目相同。
两个表必须是 InnoDB 表,MyISAM 表暂时不支持外键。
外键列必须建立了索引,MySQL 4.1.2 以后的版本在建立外键时会自动创建索引,但如果在较早的版本则需要显式建立。
外键关系的两个表的列必须是数据类型相似,也就是可以相互转换类型的列,比如 int 和tinyint 可以,而 int 和 char 则不可以;
索引
定义:该字段没有重复值,但可以有一个空值
**作用:**是提高查询排序的速度
个数:一个表可以有多个惟一索引
表与表的关联
在语法上
- 内连接
内连接通过INNER JOIN来实现,它将返回两张表中满足连接条件的数据,不满足条件的数据不会查询出来。
- 外连接
外连接通过OUTER JOIN来实现,它会返回两张表中满足连接条件的数据,同时返回不满足连接条件的数据。外连接有两种形式:左外连接(LEFT OUTER JOIN)、右外连接(RIGHT OUTER JOIN)。
左外连接
- 可以简称为左连接(LEFT JOIN),它会返回左表中的所有记录和右表中满足连接条件的记录
右外连接
- 可以简称为右连接(RIGHT JOIN),它会返回右表中的所有记录和左表中满足连接条件的记录
- 等值相连
等值连接。这种连接是通过WHERE子句中的条件,将两张表连接在一起,它的实际效果等同于内连接。出于语义清晰的考虑,一般更建议使用内连接,而不是等值连接。
关联关系
- 一对多关联
这种关联形式最为常见,一般是两张表具有主从关系,并且以主表的主键关联从表的外键来实现这种关联关系。另外,以从表的角度来看,它们是具有多对一关系的,所以不再赘述多对一关联了。
- 多对多关联
这种关联关系比较复杂,如果两张表具有多对多的关系,那么它们之间需要有一张中间表来作为衔接,以实现这种关联关系。这个中间表要设计两列,分别存储那两张表的主键。因此,这两张表中的任何一方,都与中间表形成了一对多关系,从而在这个中间表上建立起了多对多关系。
- 自关联
自关联就是一张表自己与自己相关联,为了避免表名的冲突,需要在关联时通过别名将它们当做两张表来看待。一般在表中数据具有层级(树状)时,可以采用自关联一次性查询出多层级的数据。
sql约束
-
NOT NULL: 用于控制字段的内容一定不能为空(NULL)。
-
UNIQUE: 控件字段内容不能重复,一个表允许有多个 Unique 约束。
-
PRIMARY KEY: (主键约束)也是用于控件字段内容不能重复,但它在一个表只允许出现一个。
-
FOREIGN KEY: (外键约束)用于预防破坏表之间连接的动作,也能防止非法数据插入外键列,因为它必须是它指向的那个表中的值之一,它主要用于维护数据库表之间的引用完整性。。
-
CHECK:用于控制字段的值范围。
sql注入
定义
SQL注入的原理是将SQL代码伪装到输入参数中,传递到服务器解析并执行的一种攻击手法。也就是说,在一些对SERVER端发起的请求参数中植入一些SQL代码,SERVER端在执行SQL操作时,会拼接对应参数,同时也将一些SQL注入攻击的“SQL”拼接起来,导致会执行一些预期之外的操作。
预防
- 严格的参数校验
参数校验就没得说了,在一些不该有特殊字符的参数中提前进行特殊字符校验即可。
- SQL预编译
实际上当将绑定的参数传到MySQL服务器,MySQL服务器对参数进行编译,即填充到相应的占位符的过程中,做了转义操作。我们常用的JDBC就有预编译功能,不仅提升性能,而且防止SQL注入。
聚合函数
定义
聚合函数作用于一组数据,并对一组数据返回一个值。
类型
- AVG():求平均值
- SUM():求和
- MAX():最大值
- MIN():最小值
- COUNT():求数量
语法
SELECT column, group_function(column)
FROM table
[WHERE condition]
[GROUP BY column]
[ORDER BY column];
聚合函数不能嵌套调用。比如不能出现类似“AVG(SUM(字段名称))”形式的调用。
使用
- 可以对数值型数据使用AVG 和 SUM 函数。
SELECT AVG(column), MAX(column),MIN(column), SUM(column)
FROM table
WHERE ?;
- 可以对任意数据类型的数据使用 MIN 和 MAX 函数。
SELECT MIN(column), MAX(column)
FROM table;
WHERE ?;
COUNT(*)返回表中记录总数,适用于任意数据类型。
SELECT COUNT(*)
FROM table
WHERE ? (column = ?);
COUNT(expr)返回expr不为空的记录总数。
SELECT COUNT(column)
FROM table
WHERE ?;
问题:
- 用
count(*),count(1),count(列名)谁好呢?
其实,对于MyISAM引擎的表是没有区别的。这种引擎内部有一计数器在维护着行数。
Innodb引擎的表用count(*),count(1)直接读行数,复杂度是O(n),因为innodb真的要去数一遍。但好于具体的count(列名)。
- 能不能使用
count(列名)替换count(*)?
不要使用 count(列名)来替代 count(*),count(*)是 SQL92 定义的标准统计行数的语法,跟数据库无关,跟 NULL 和非 NULL 无关。
说明:count(*)会统计值为 NULL 的行,而 count(列名)不会统计此列为 NULL 值
常见查询关键字
- where与having
- WHERE是一个约束声明,使用WHERE约束来自数据库的数据,WHERE是在结果返回之前起作用的,WHERE中不能使用聚合函数。
- HAVING是一个过滤声明,是在查询返回结果集以后对查询结果进行的过滤操作,在HAVING中可以使用聚合函数。另一方面,HAVING子句中不能使用除了分组字段和聚合函数之外的其他字段。
where在获得结果前起作用,having在获得结果后起作用。
从性能的角度来说,having子句如果使用了分组字段作为过滤条件,则应该替换成where子句,因为where可以在执行分组操作和计算聚合函数前过滤掉不需要的数据,性能会更好。
-
in 和 exists
- in语句是把外表和内表作hash 连接,而exists语句是对外表作loop循环,每次loop循环再对内表进行查询。
- 一直大家都认为exists比in语句的效率要高,这种说法其实是不准确的。这个是要区分环境的。
- 如果查询的两个表大小相当,那么用in和exists差别不大。
- 如果两个表中一个较小,一个是大表,则子查询表大的用exists,子查询表小的用in。
- not in 和not exists:如果查询语句使用了not in,那么内外表都进行全表扫描,没有用到索引;而not extsts的子查询依然能用到表上的索引。所以无论那个表大,用not exists都比not in要快。
-
UNION 和 UNION ALL
UNION 是一个用于合并多个 SELECT 查询结果的操作符。它的作用是将多个查询的结果集合并为一个结果集,并去除重复的行。
主要特点和作用如下:
- 合并结果集:UNION 操作符可以将多个查询的结果集合并为一个结果集。每个查询的结果集必须具有相同的列数和相似的数据类型。
- 去除重复行:与 UNION ALL 操作符不同,UNION 会去除合并结果集中的重复行,只保留一份。它通过对结果集进行去重操作来实现。
- 排序结果:UNION 默认会对合并后的结果集进行排序,以确保返回的结果是按照默认顺序排列的。如果需要自定义排序顺序,可以使用外部的 ORDER BY 子句来指定排序条件。
- 数据类型匹配:在使用 UNION 进行结果集合并时,需要确保每个查询的选择列表中的列具有相似的数据类型,或者可以进行隐式类型转换。否则,可能会导致错误或意外的结果。
Copy code
SELECT column1, column2 FROM table1
UNION
SELECT column1, column2 FROM table2
上述示例中,UNION 操作符将 table1 和 table2 的查询结果合并为一个结果集,并去除重复的行。
需要注意的是,UNION 操作符在进行结果集合并时会进行排序和去重操作,这可能会对性能产生一定的影响。如果确保结果集中不会存在重复的行,并且不需要进行排序,可以考虑使用性能更高的 UNION ALL 操作符。
UNION ALL 是一个用于合并多个 SELECT 查询结果的操作符。它的作用是将多个查询的结果集合并为一个结果集,包含所有查询的结果,不去除重复行。
主要特点和作用如下:
-
合并结果集:UNION ALL 操作符可以将多个查询的结果集合并为一个结果集。每个查询的结果集必须具有相同的列数和相似的数据类型。
-
保留重复行:与 UNION 操作符不同,UNION ALL 不会去除重复的行。它简单地将所有查询的结果按照顺序连接起来,保留所有行,包括重复的行。
-
性能优化:相对于 UNION 操作符,UNION ALL 的性能更高,因为它不需要进行重复行的去重操作。如果你确定结果集中不会存在重复的行,可以使用 UNION ALL 来获得更好的性能。
适用场景:**UNION ALL 适用于需要合并多个查询结果集,并且不需要去除重复行的场景。**例如,你可能需要从多个表或查询中检索相似的数据,然后将它们合并到一个结果集中进行进一步的处理或展示。
Copy code
SELECT column1, column2 FROM table1
UNION ALL
SELECT column1, column2 FROM table2
上述示例中,UNION ALL 操作符将 table1 和 table2 的查询结果合并为一个结果集,包含所有行。
需要注意的是,UNION ALL 不会对结果进行排序,默认情况下返回的结果是按照查询的顺序排列的。如果需要对结果进行排序,可以使用外部的 ORDER BY 子句来指定排序条件。
总结起来,UNION ALL 是用于合并多个查询结果集的操作符,它保留所有行,不去除重复的行,适用于需要合并结果集并且不需要去重的场景。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









