






吃瓜教材:
西瓜书:周志华老师的《机器学习》
南瓜书:《机器学习公式详解》第2版
吃瓜视频:【吃瓜教程】《机器学习公式详解》(南瓜书)与西瓜书公式推导
第四章 决策树
4.1 基本流程
决策树是不断根据某属性进行划分的过程(每次决策时都是在上次决策结果的基础之上进行),即“if……elif…… else……”的决策过程,最终得出一套有效的判断逻辑(将样本越分越“纯”),便是学到的模型。
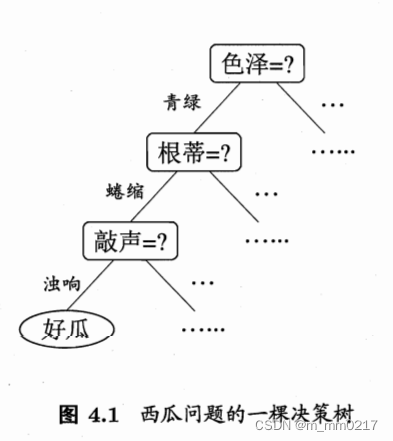
但是,划分到什么时候就停止划分呢?3 个“
return”代表的递归返回:
(1)当前结点包含的样本全是同一类,无需划分;
(2)当前属性集为空(所有属性都已被用作过划分依据),子集中仍含有不同类样本——少数服从多数,以子集中样本数最多的类为标记;
(3)当前结点包含的样本集合为空(例如未收集到)——把父结点的样本分布作为当前结点的先验分布(此分支要保留,因为测试时可能会有样本落入该分支)。
4.2 划分选择
ID3、C4.5、CART三种决策树算法
4.2.1 信息增益

信息熵所代表的“不确定性”转换理解为集合内样本的“纯度”:
如果一个集合里全是同一类样本时——此时信息熵最小为0,集合最纯


信息增益:信息熵-条件熵
ID3决策树:信息增益越大,意味着使用属性a来进行划分所获得的“纯度提升”越大。
4.2.2 增益率


4.2.3 基尼指数



4.3 剪枝处理
剪枝:缓解过拟合


4.3.1 预剪枝

4.3.2 后剪枝

4.4 连续与缺失值
4.4.1 连续值处理
离散属性不可以重复使用,但连续属性是可以重复使用的。


4.4.2 缺失值处理
有些分类器不能使用含有缺失值的样本,需要进行预处理。常用的缺失值填充方法是:对于连续属性,采用该属性的均值进行填充;对于离散属性,采用属性值个数最多的样本进行填充。这实际上 假设了数据集中的样本是基于独立同分布采样得到的。特别地,一般缺失值仅指样本的属性值有缺失,若类别标记有缺失,一般会直接抛弃该样本。
(1)如何在属性值缺失的情况下进行划分属性选择?
此时根据在属性上没有缺失值的样本判断属性的优劣。

(2)给定划分属性,若样本在该属性上的值缺失,如何对样本进行划分?

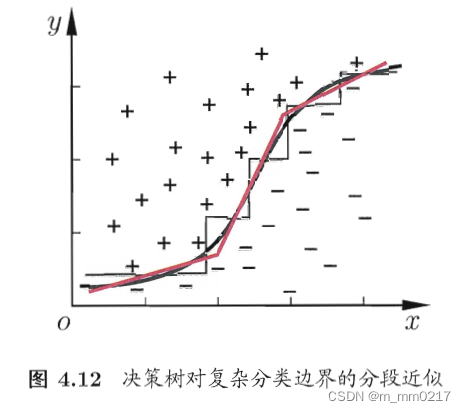
4.5 多变量决策树
多变量决策树不是为每个非叶结点寻找一个最优划分属性,而是试图建立一个合适的线性分类器(红线)。















 984
984











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









