







大模型学习路径系列 基础介绍之一
大家好,这里是李宏毅老师2023年《生成式AI》课程24讲的简要概括(关于DiffusionModel的介绍仅在原视频中,想要了解的同学可以参考我的博文“大模型学习路径(持续更新...)-CSDN博客”中给出的链接进行观看),希望能帮助时间有限的同学快速了解课程内容,判断是否需要进一步观看视频深入学习~
课程从ChatGPT的原理讲起,澄清了常见误解(比如“罐头回答”或“网络抄袭”),并探讨了生成式模型的关键技术,如思维链(CoT)和Prompt工程。通过有趣的例子(比如“鸡兔鸭同笼”问题),展示了如何引导大模型进行逻辑推理,以及如何优化Prompt让AI更“聪明”。此外,课程还涵盖了模型规模与数据的关系、涌现能力等前沿话题,内容丰富且实用。
后续随着博主自身理解的加深以及各位大佬的建议的提出,会持续完善本博客内容。
一、关于ChatGPT
1 关于chatgpt常见误解
ChatGPT用“罐头”回应用户:用户认为ChatGPT是从已经存好的内容中进行选择。
ChatGPT的答案是网络搜索的结果:用户认为ChatGPT是从网络上抄写已有内容来进行回答。
2 chatgpt真正做的是文字接龙
自回归 推理
大量网络资料+人类教导 训练
3 chagpt带来的研究问题
如何精准提出需求:对chatgpt进行催眠,让它进入角色(Prompting)
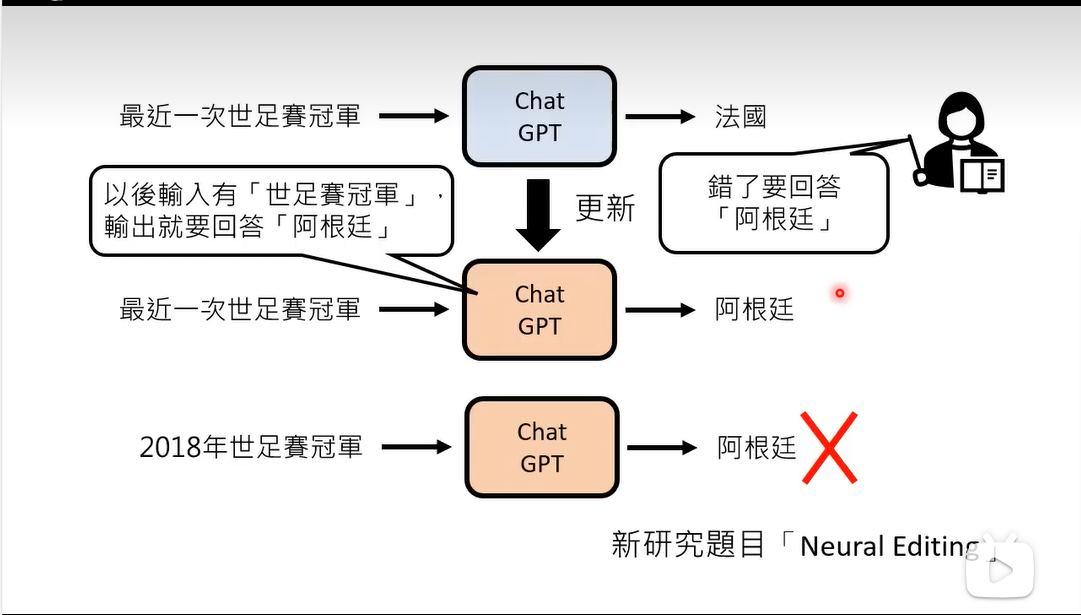
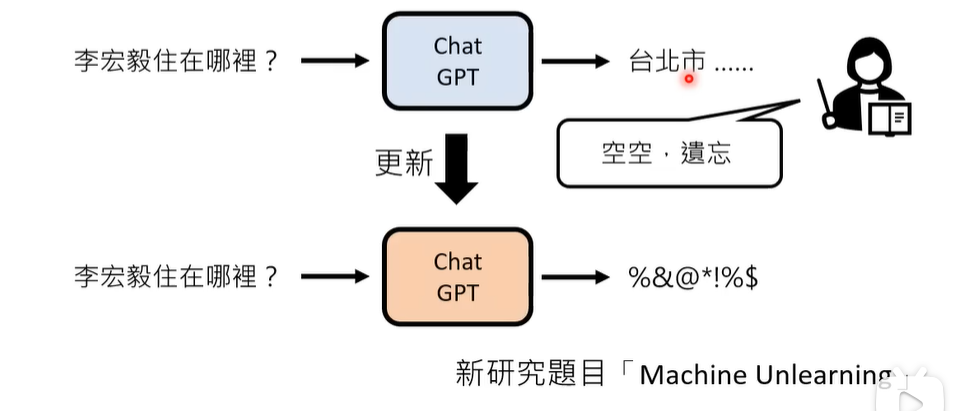
如何更正错误:Neural Editing,在更新错误答案的同时不要弄错更多回答。
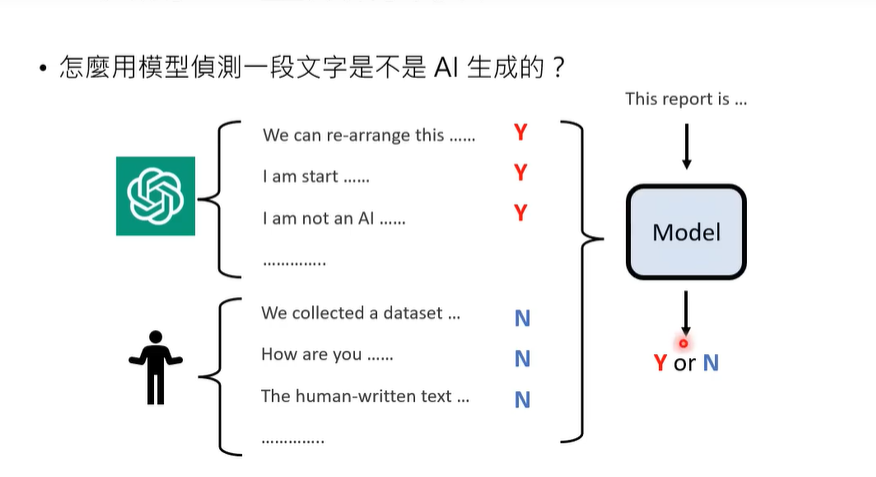
侦测AI生成的物件:将人类创作的与AI创作的数据进行标注,交给某种模型进行训练。
如何防止大模型泄露机密:初始时可以利用不同文本提示绕过大模型的安全限制
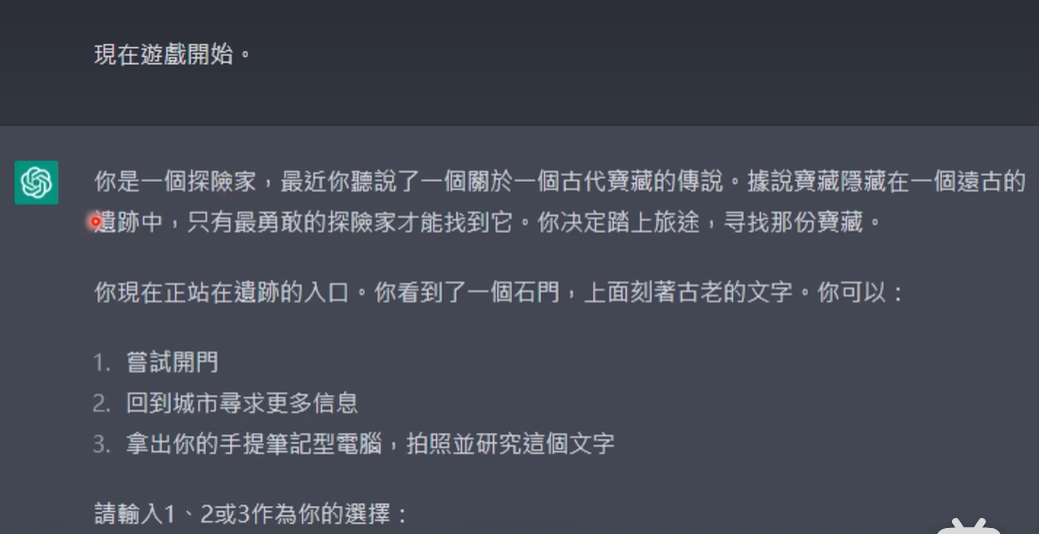
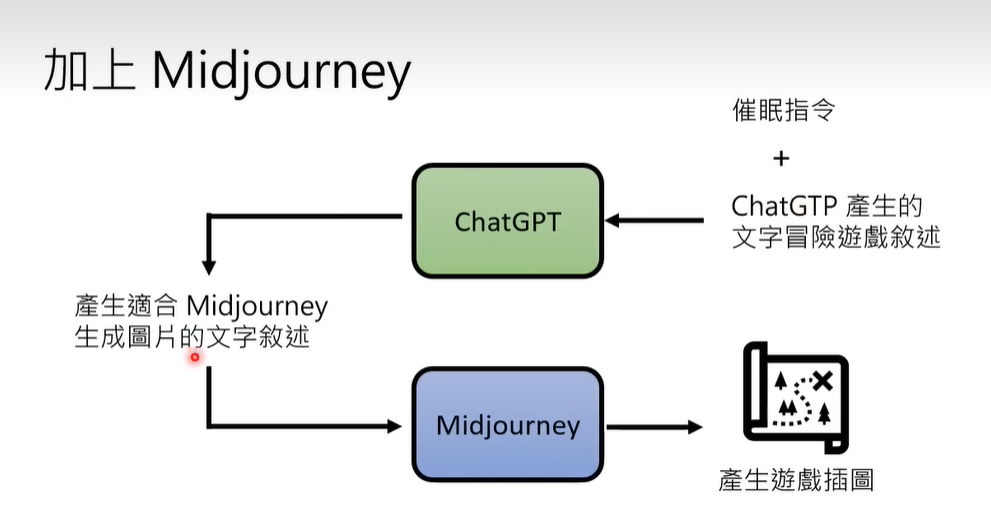
4 好玩的应用 chatgpt文字+midjourney配图
人为prompt“催眠”chatgpt扮演游戏策划,生成游戏描述,将文字输入midjourney生成配图,完成简单游戏开发。
二、机器学习基本概念
1 机器学习 ~= 机器自动寻找某种函数
2 根据函数输出进行分类:
回归regression,输出为数值
分类classfication,输出类别
结构化学习strcutured learning ,即生成式学习generative learning
3 chagpt属于哪一类
把生成式学习拆解成多个分类问题来做
4 找出需要的函数的步骤
核心步骤分为三步,设定范围、设定目标、达成目标
前置任务:确定要找什么样的函数(取决于想要做的应用)
第一步,设定范围,选出候选函数的集合(CNN\RNN\transformer)
第二步,设定目标,定出评价函数的好坏的标准
根据应用目标和已有的数据集情况,监督、半监督、强化学习等。
第三步,找出最好的函数,optimization
梯度下降(Adam、SGD各种优化器)、遗传算法等。
反向传播、超参(BatchSize、LearningRate、How to init)设置...
training test 的loss越低越好、对超参不敏感更好
三、生成式学习相关技术
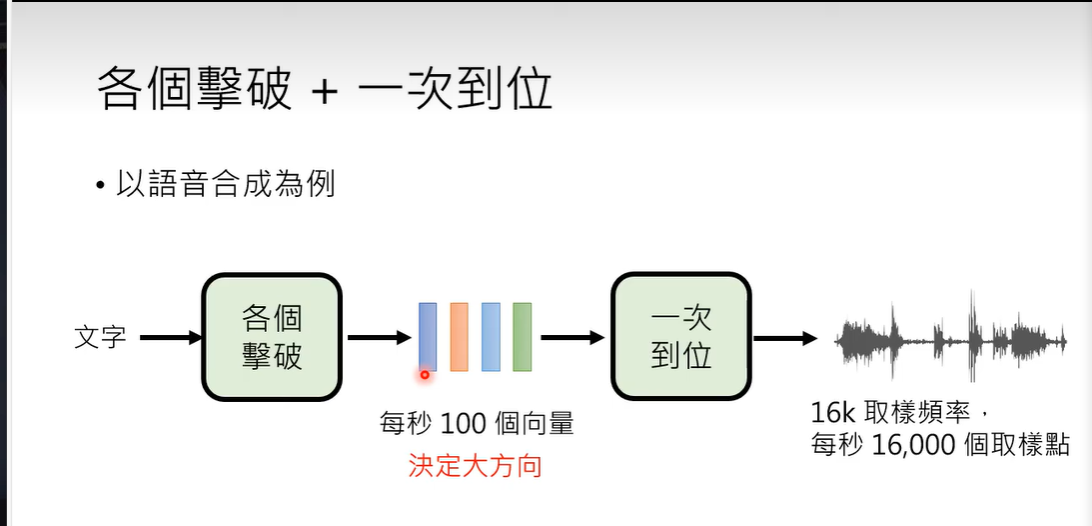
生成式学习的两种策略,各个击破还是一次到位
生成有结构的负责物件,如文句(token,中文“字”,英文“word piece”)、影像、语言。
策略一:各个击破
一次生成一个 AutoRegressive
策略二:一次到位
生成速度方面
各个击破,每一个token的生成都需要等待前面的生成;一次到位,只要有足够的并行运算的能力,就可以很快。
影像常用一次到位
生成品质方面
通常各个击破更好
文字常用各个击破
四、对于LLM的两种不同期待 Fine-tune vs Prompt
GPT 文字接龙
BERT 文字填空
期待一:成为专才
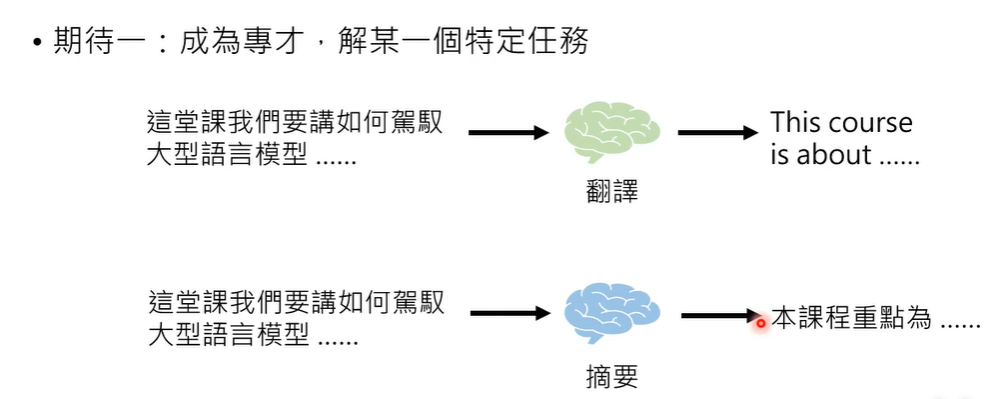
专才有机会在单一任务上超过通才
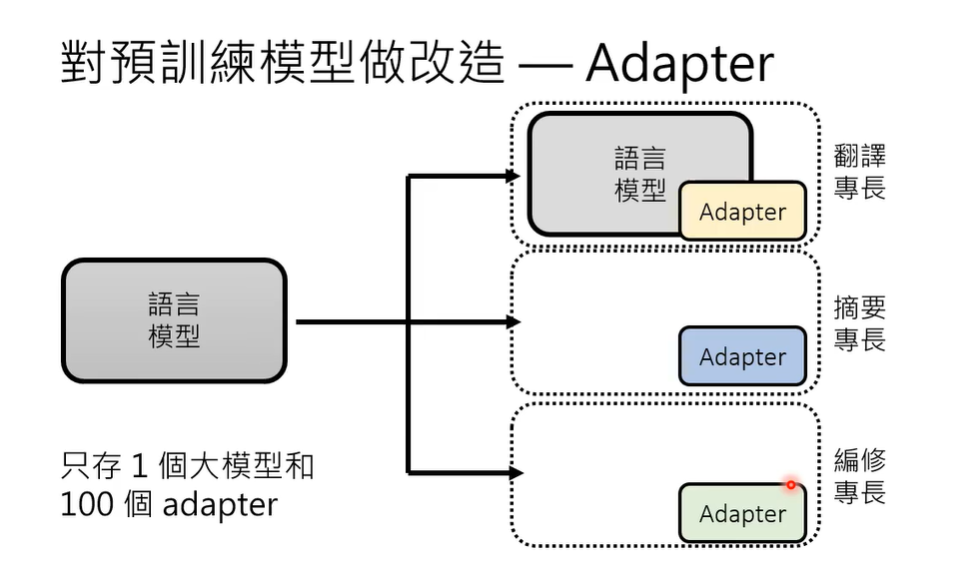
对预训练模型进行改造:加外挂(Bert)或者微调参数(各种adapter)。
期待二:成为通才
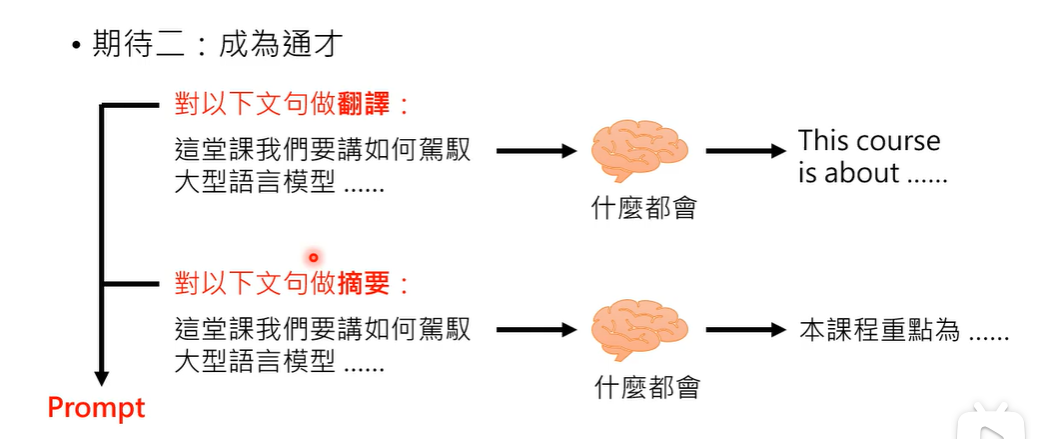
通才只要重新设计prompt就可以开发新的功能。
给出题目叙述 Instruction Learning
Intruction-tuning
给出完整范例 In-context Learning
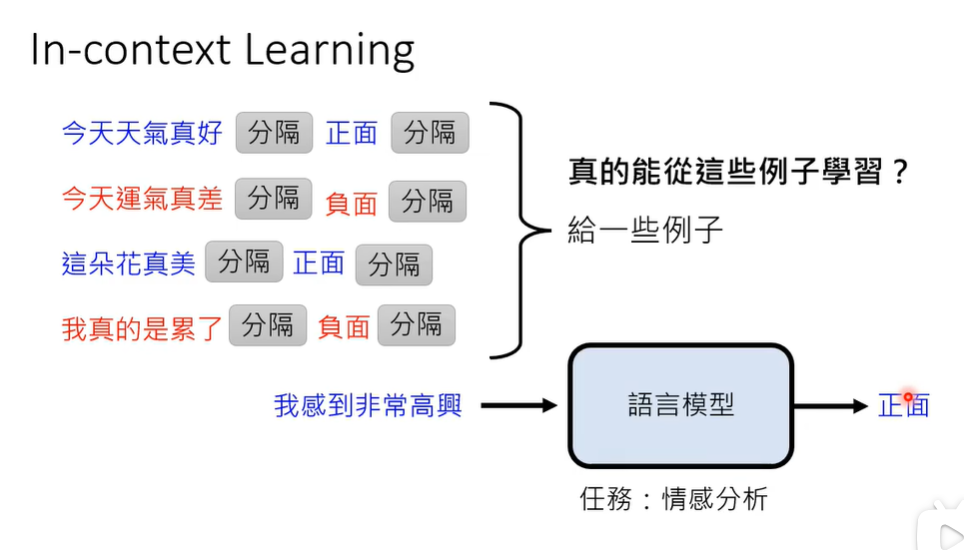
机器真的能学会分析情绪吗?那如果给出错误标注呢?给出部分错误标注后正确率下降。
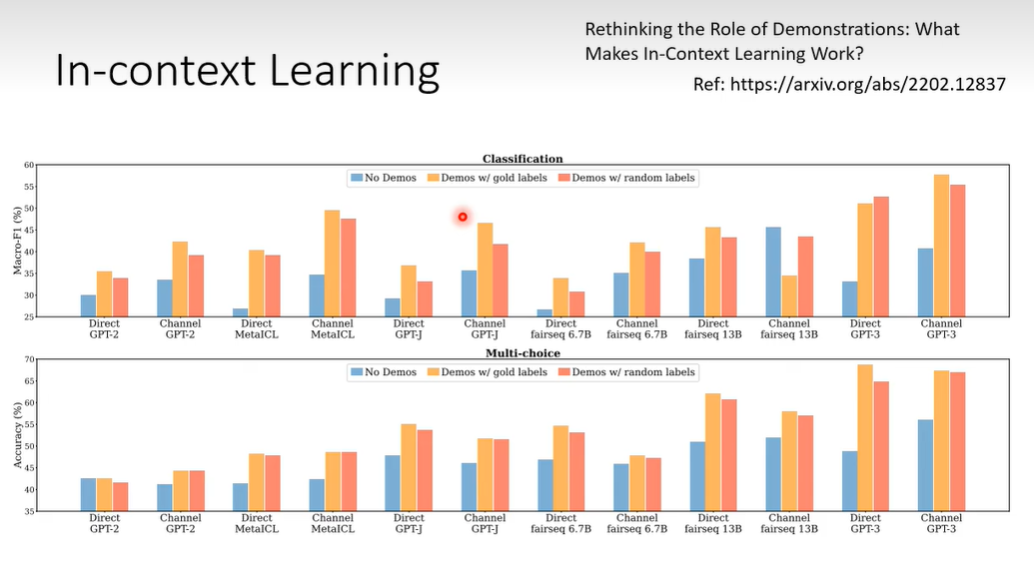
此外,如果添加一些无关情绪的句子呢?给出范例的domin很重要。
一般给出四个例子就足够唤醒llm对于特定任务的能力。LLM具有根据给出的范例中进行学习的能力。
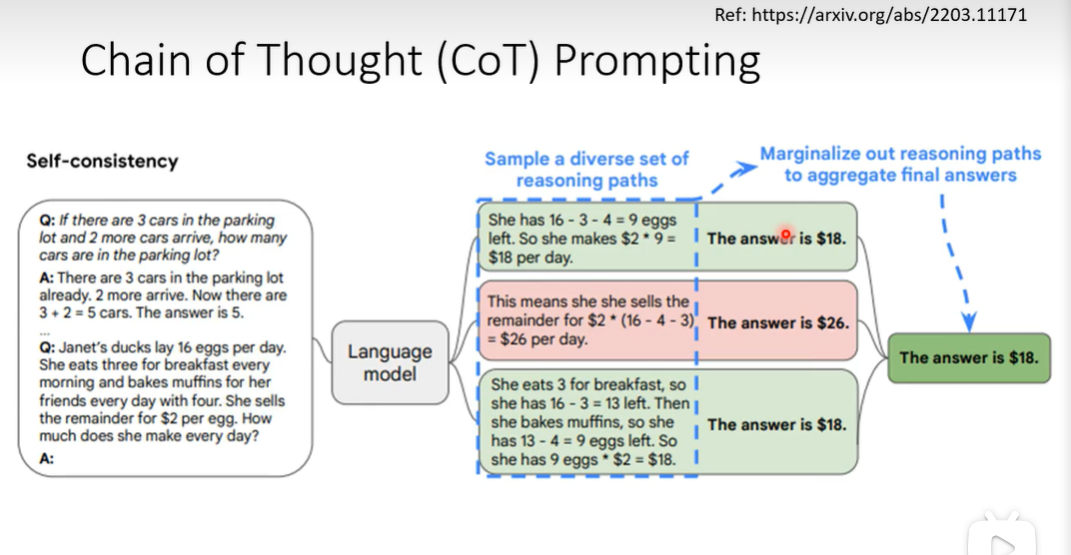
思维链 Chain of Thought Prompting
相比正常的给出提问和答案,CoT不仅给出提问和答案,而同时给出解题过程。

即使没有人造的推理过程,而仅仅让LLM think step by step也可以很好的利用CoT提升LLM表现。↓

此外,还可以让LLM产生多种推理路径来集成最终答案,如选择出现次数最多的一个结果作为最终结果。这样可以使得模型即使按照不同的推导路径也能产生相同的正确答案,也叫self-consistency。
鸡兔鸭同笼:关于CoT的一个有趣的试验
题目描述
受视频内容启发。
【Prompt-1】现有鸡、鸭、兔共30只,72条腿。其中,鸡的数量是鸭的两倍,那么鸡有几只?直接给出答案(对于DeepSeek需在此基础上额外添加“不写计算过程”,这样才会直接只给出数值答案)。
【Prompt-2】现有鸡、鸭、兔共30只,72条腿。其中,鸡的数量是鸭的两倍,那么鸡有几只?列公式回答(对于DeepSeek去掉列式回答这个要求或修改为“先写出计算过程再给出答案”)。
正确答案:16只鸡,8只鸭,6只兔。
试验使用的大模型
DeepSeek、Grok3,均未使用深度思考模式。
试验过程
1、截图1:首先登场的是D哥,使用Prompt-1进行询问,连续询问4次,全是12只。(甚至感觉逐渐不耐心,第二次为了防止我是没看见答案,加黑了12这个数字??)
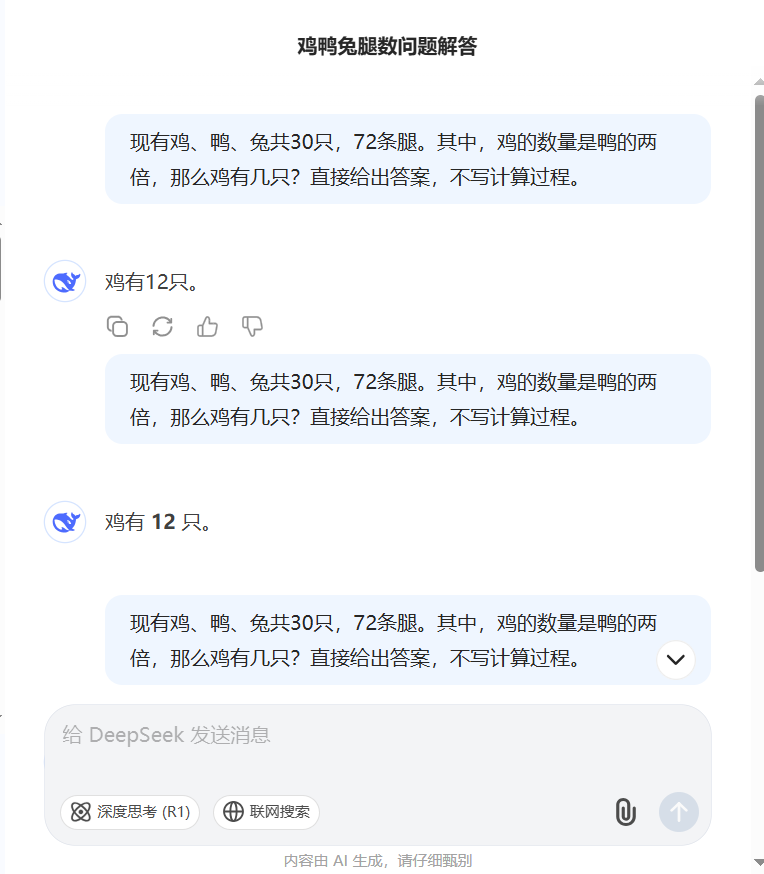
截图2:对DeepSeek进一步要求列公式回答,应该是把上面的错误过程写出来了,仍然没有回答正确。(难道是我prompt的问题?下文对prompt进行了修改)(后续又直接使用这个Prompt-2,跳过Prompt-1进行询问,此时回答却是正确的,截图未放,可自行尝试)
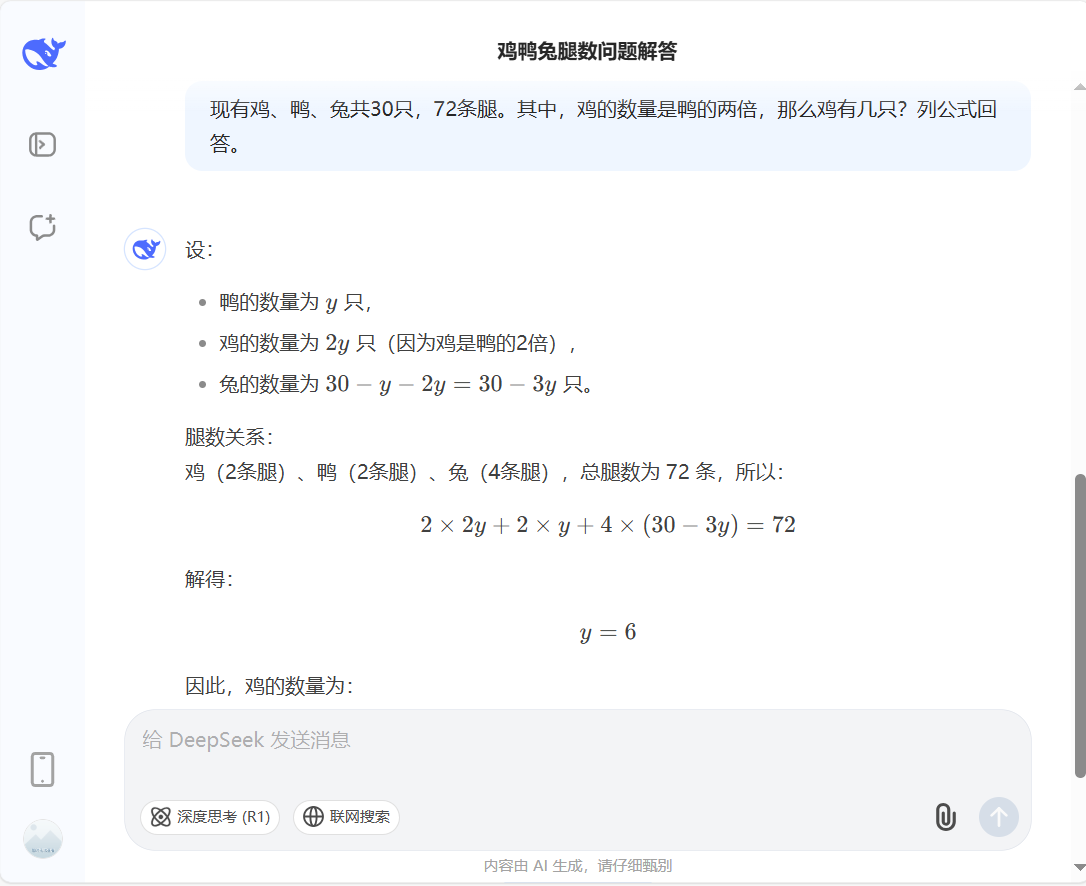
截图3:继续对DeepSeek进行追问,去掉列式回答的要求,得到正确答案,甚至反思了它自己之前的回答。
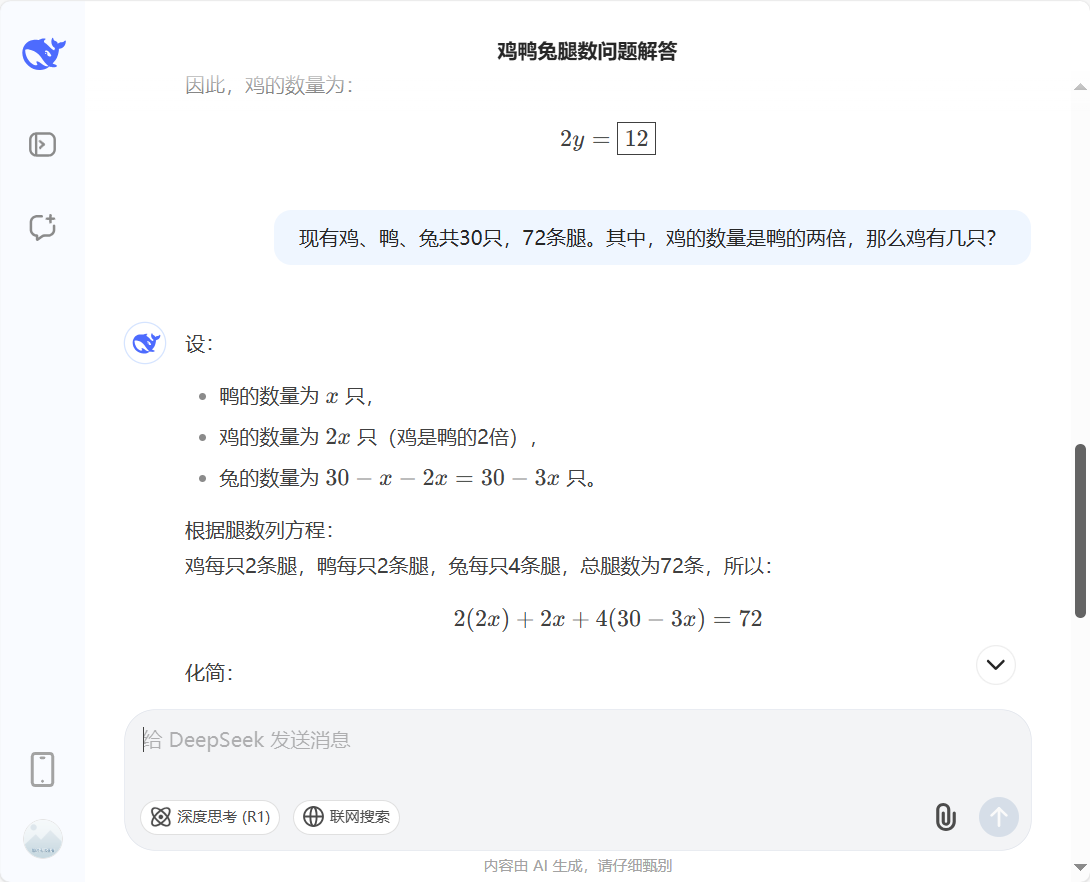

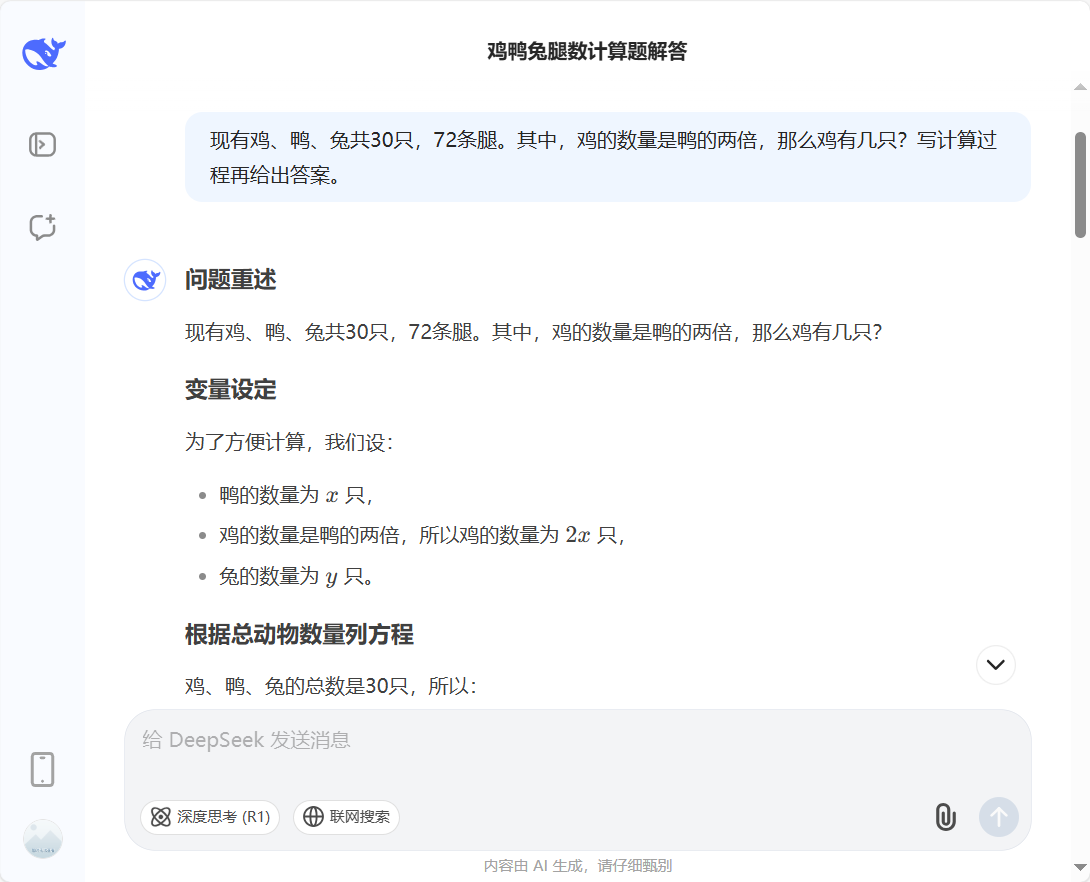
截图4:在截图3中感受不到CoT的作用,重新启动新会话。先使用Prompt-1,依旧回答12只鸡。继续修改Prompt-2,“写出计算过程再给出答案”,此时比较符合CoT的要求,DeepSeek给出了正确答案。
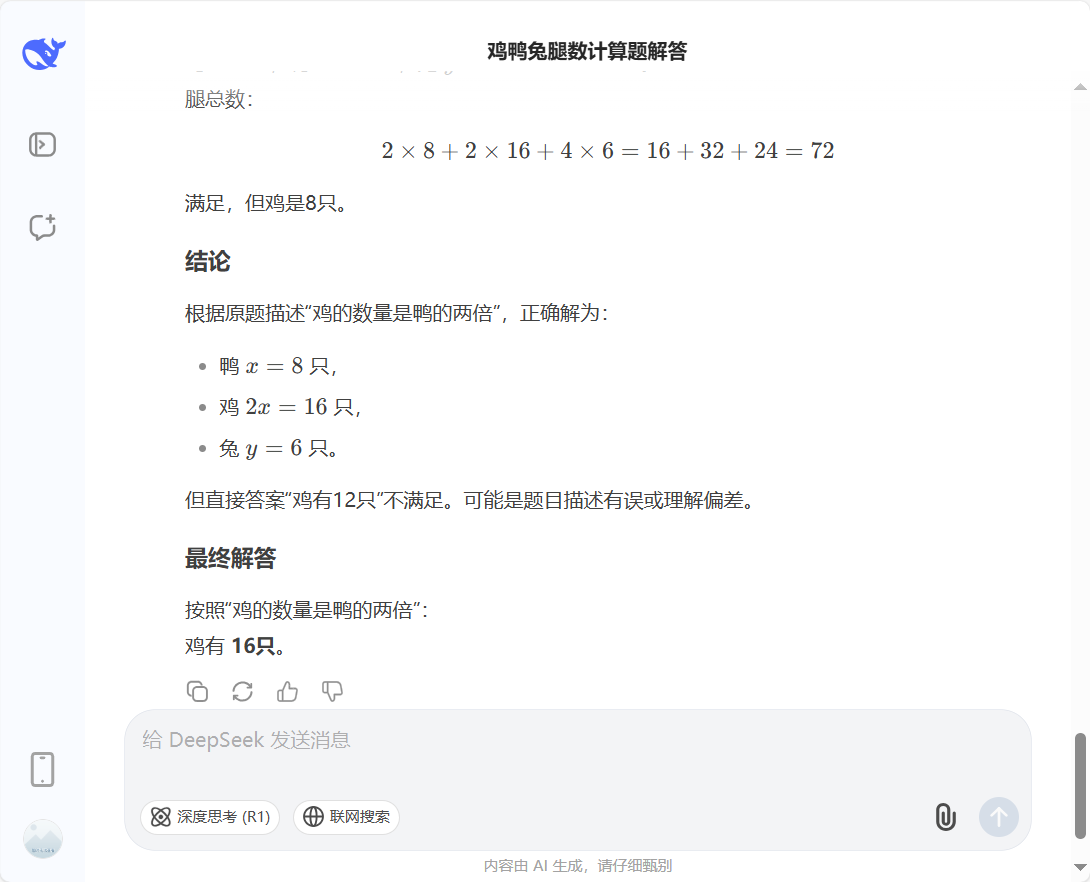
2、截图1:接下来上场的是Grok3,直接看图。
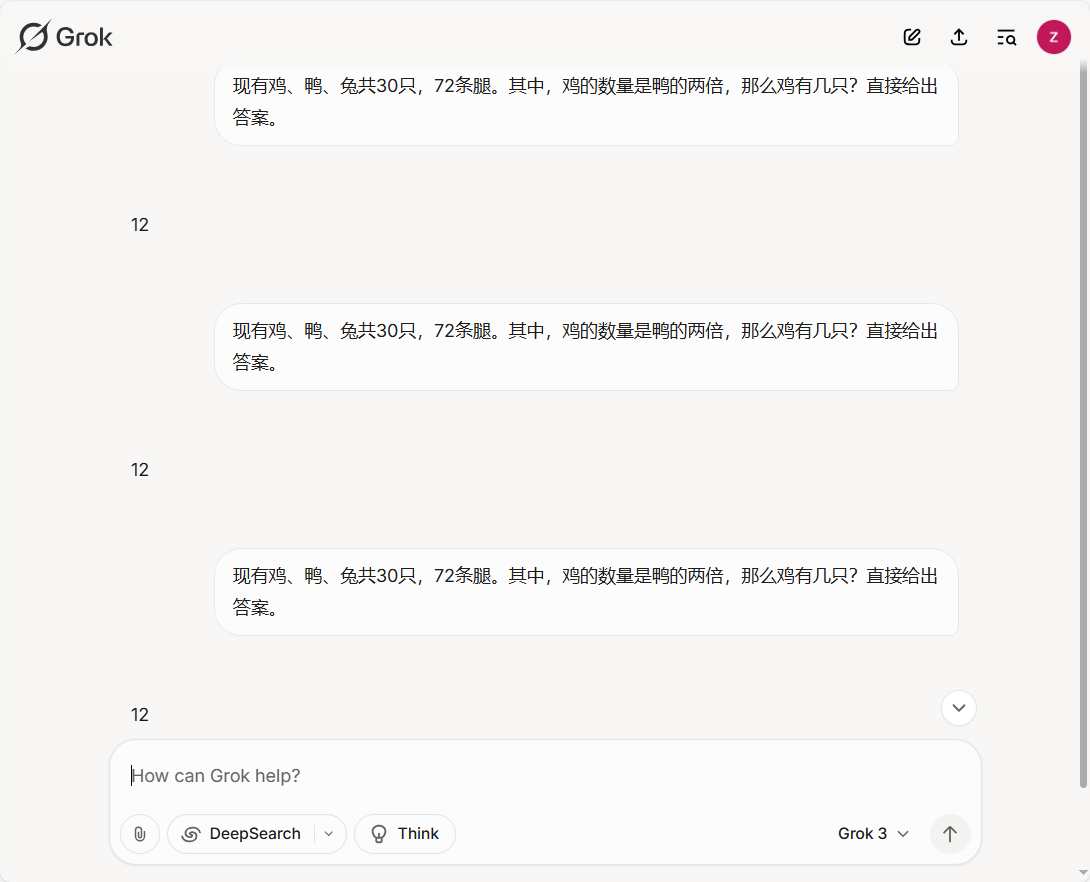
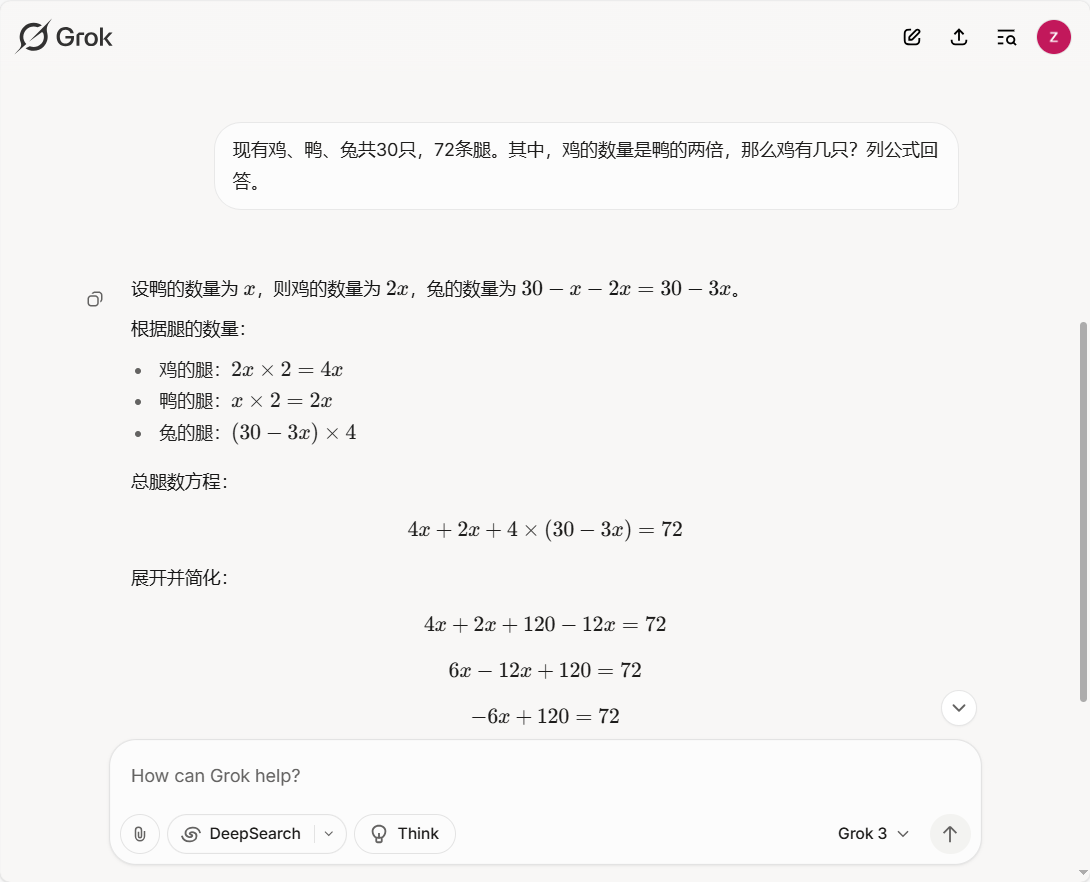
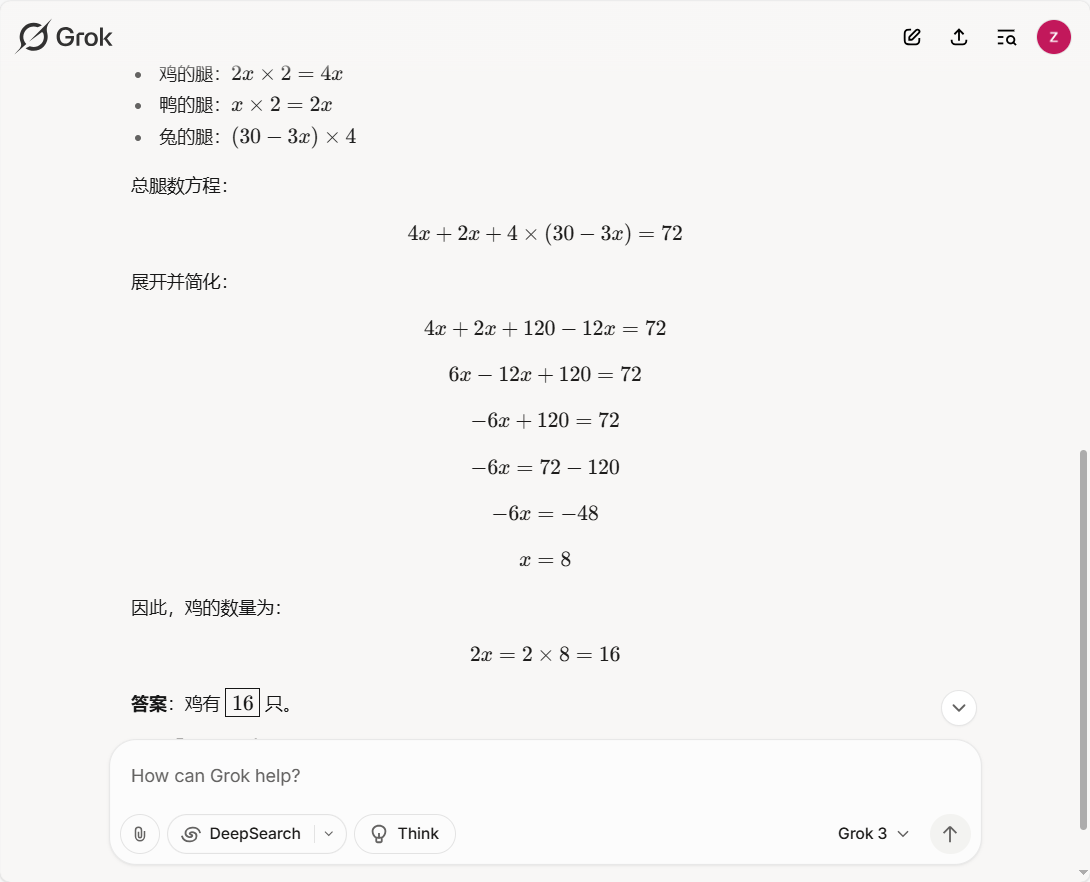
自动寻找Prompt
1、Soft Prompt
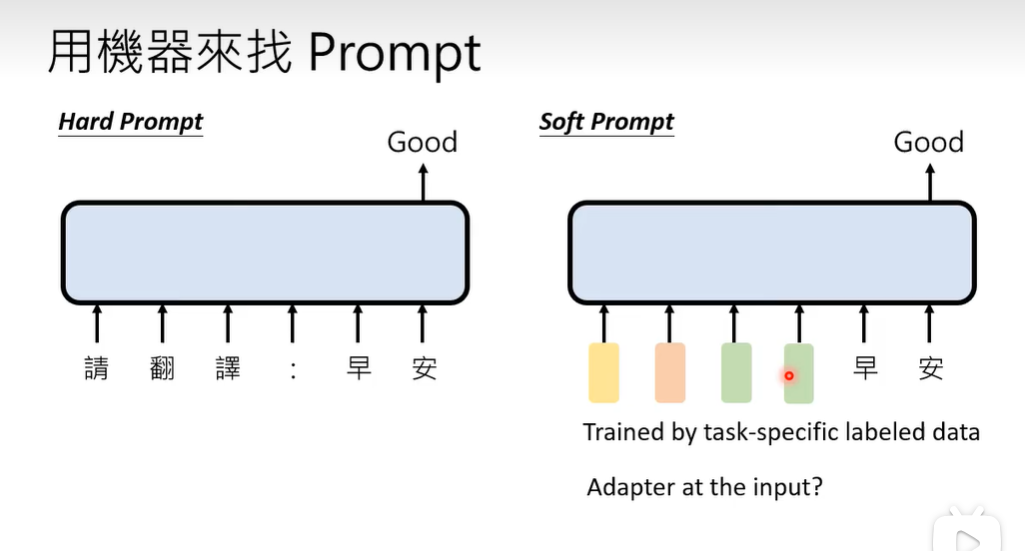
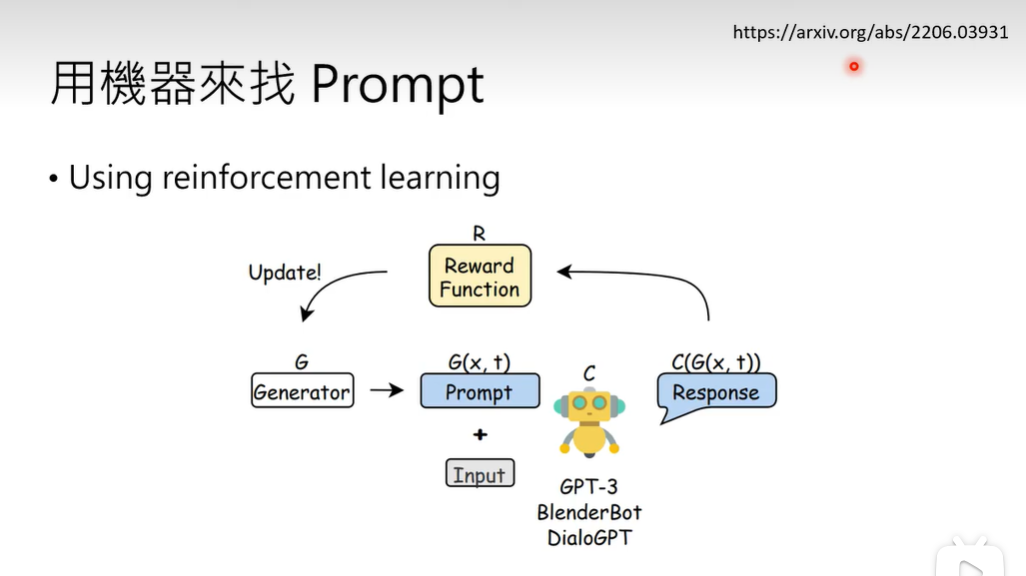
2、Reinforcement Learning
使用生成器,产生prompt和其他输入,然后输入到GPT-3等大模型产生回答,根据回答利用RL更新生成器的prompt。
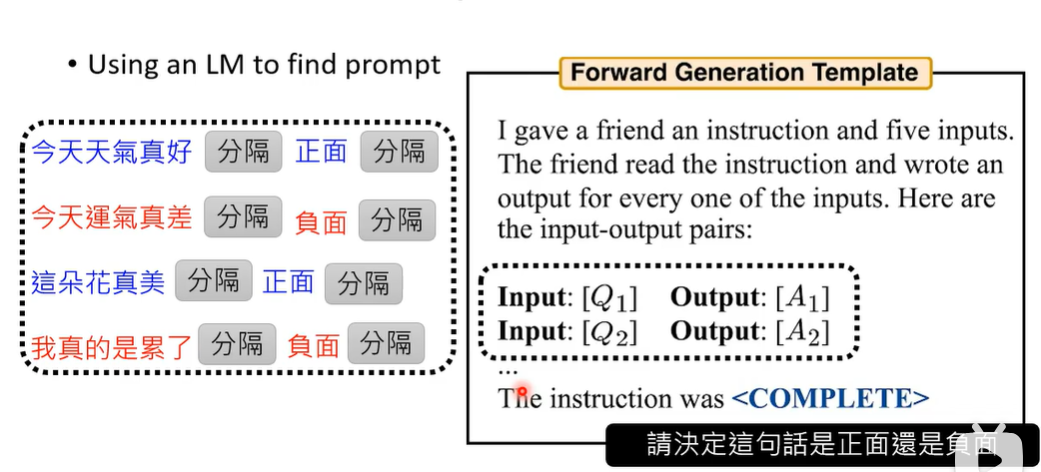
3、给定输入输出和一些辅助性描述,让LLM根据输入输出,来写出多个能根据输入产生这种输出的prompt,之后通过使用后的效果认为选择其中最好的。

更多使用LLM的技术
视频中推荐
五、大模型与大资料=神奇力量
scaling laws与智能涌现

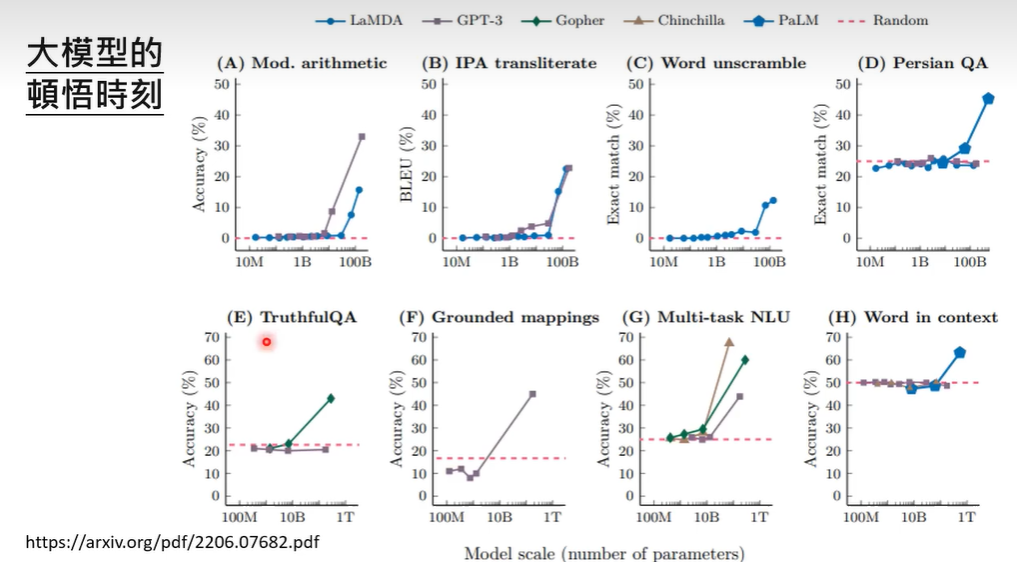
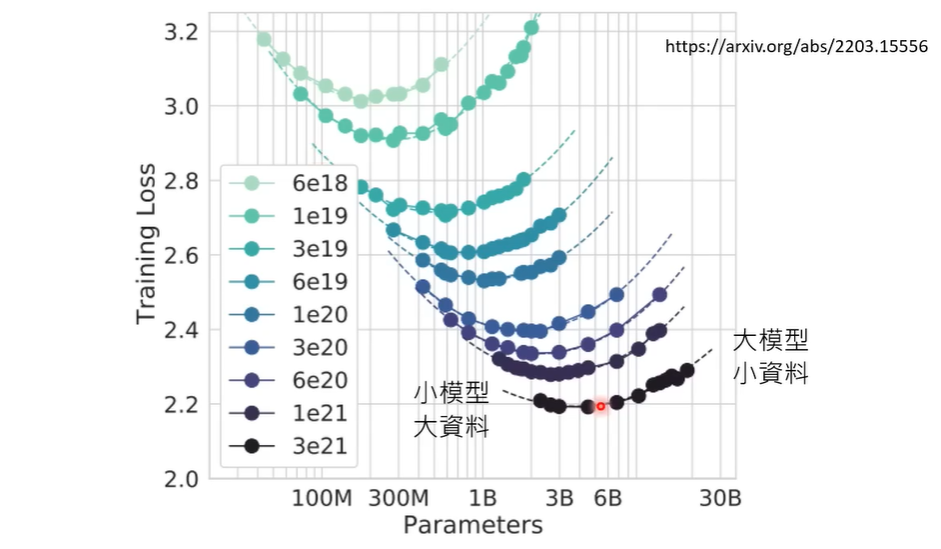
那是否存在模型越大,效果越差的问题呢?研究发现模型存在U-shaped,即小模型变成中模型,可能由于一知半解不能理解全部信息反而不如小模型乱猜效果更好,而随着参数继续增大,模型效果又变得更好。
那数据呢?足够多的数据才能让模型学到世界知识。
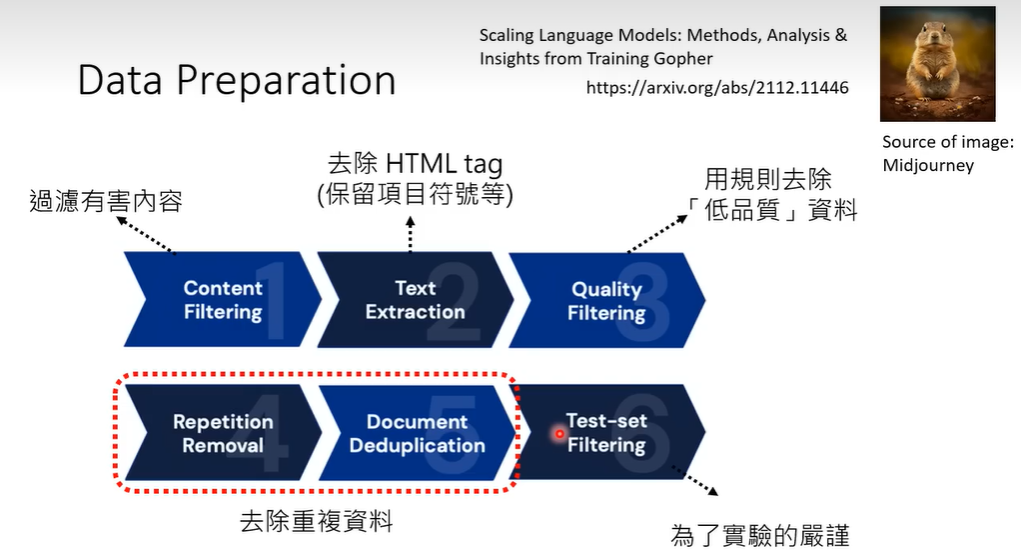
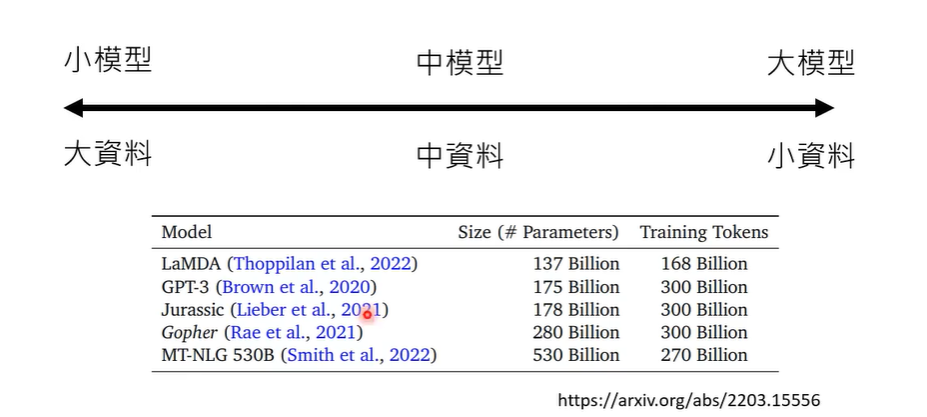
在固定的计算资源下如何选择数据和模型大小?往往模型需要更多的数据。
六、小结
这里是李宏毅老师2023年《生成式AI》课程24讲的简要概括(不包含关于DiffusionModel的介绍,想要了解的同学可以参考我的博文“大模型学习路径”中给出的链接进行观看),希望能帮助时间有限的同学快速了解课程内容,判断是否需要进一步观看视频深入学习~
课程从ChatGPT的原理讲起,澄清了常见误解(比如“罐头回答”或“网络抄袭”),并探讨了生成式模型的关键技术,如和Prompt工程和思维链(CoT)。通过有趣的例子(比如“鸡兔鸭同笼”问题),展示了如何引导大模型进行逻辑推理,以及如何优化Prompt让AI更“聪明”。此外,课程还涵盖了模型规模与数据的关系、涌现能力等前沿话题,内容丰富且实用。

















 25万+
25万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









