







📙 作者简介 :RO-BERRY
📗 学习方向:致力于C、C++、数据结构、TCP/IP、数据库等等一系列知识
📒 日后方向 : 偏向于CPP开发以及大数据方向,欢迎各位关注,谢谢各位的支持

目录
📖1.进程的概念
进程在我们日常操作中无处不在
在Windows系统中我们打开任务管理器就会看到我们的所有进程

Linux下的进程输入指令
px axj
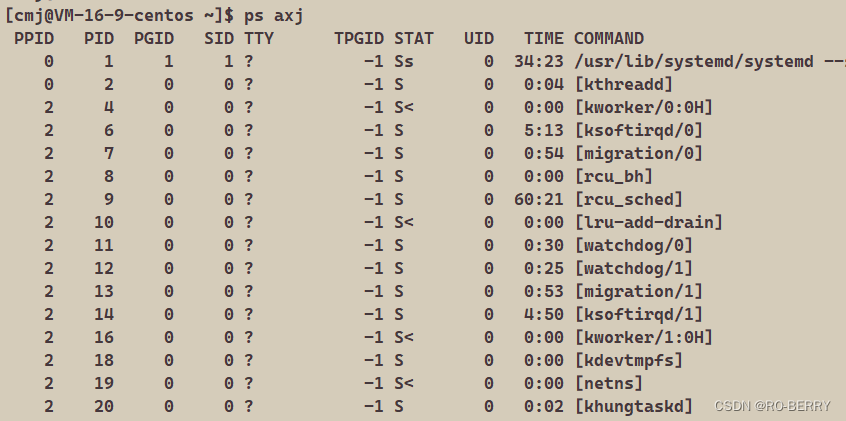
✉那么什么是进程?
进程 = 内核PCB对象 + 可执行程序---> 内核数据结构 + 可执行程序 = 进程
我们前面讲了操作系统对对一个事务进行管理,我们首先要对它进行建模,即先描述,再组织。操作系统对进程的管理,则会将对每一个存入内存的程序形成一个PCB,转而形成对PCB的管理
那么为什么程序加载到内存,变成进程之后,我们要给每一个进程形成一个PCB对象呢?
这是因为操作系统需要进行管理
注:我们所有对进程的控制和操作,都只和进程的PCB有关系,和进程的执行程序没有关系
如果愿意,可以把PCB放入任何的数据结构里
进程是资源分配的基本单位。
进程控制块 (Process Control Block, PCB) 描述进程的基本信息和运行状态,所谓的创建进程和撤销进程,都是指对 PCB 的操作。
📖2.进程控制块(PCB)
进程信息被放在一个叫做进程控制块的数据结构中,可以理解为进程属性的集合。
课本上称之为PCB(process control block),Linux操作系统下的PCB是: task_struct
task_struct是Linux内核的一种数据结构,它会被装载到RAM(内存)里并且包含着进程的信息
📔task_struct中的内容
- 标示符: 描述本进程的唯一标示符,用来区别其他进程。
- 状态: 任务状态,退出代码,退出信号等。
- 优先级: 相对于其他进程的优先级。
- 程序计数器: 程序中即将被执行的下一条指令的地址。
- 内存指针: 包括程序代码和进程相关数据的指针,还有和其他进程共享的内存块的指针
- 上下文数据: 进程执行时处理器的寄存器中的数据[休学例子,要加图CPU,寄存器]。
- I/ O状态信息: 包括显示的I/O请求,分配给进程的I/ O设备和被进程使用的文件列表。
- 记账信息: 可能包括处理器时间总和,使用的时钟数总和,时间限制,记账号等。
- 其他信息
我们创建一个可执行程序并将其运行
#include<stdio.h>
#include<unistd.h>
in main()
{
while(1)
{
printf("I am a process!\n");
sleep(1);
}
return 0;
}
将其编译后执行文件得到一个进程,不关闭进程再打开此用户,输入
ps ajx | head -1 && ps ajx | grep process
这里的PID就是我们执行的进程的唯一标识符了
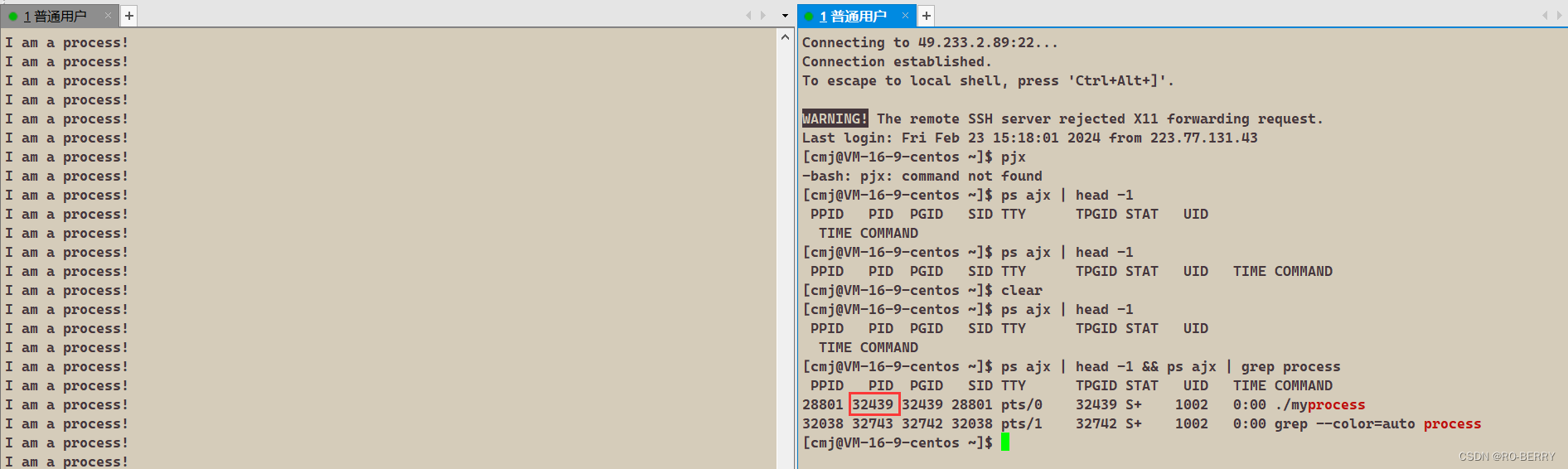
注:几乎所有独立的指令,就是程序,运行起来也要变成进程
所以在这里不止有我们程序progress运行起来的生成的进程,还有我们输入这一串指令所形成的进程
🎫为什么我们在这里写一个死循环来查看进程呢?
这是因为我们如果写一个正常程序,他会立马运行结束,进程会很快就结束掉它的周期,我们就无法看到此进程了,也就是说进程是有生命的
📔2.2通过系统调用获取进程标示符
getpid():得到此进程的pid
getppid():得到当前进程的父进程的pid
子进程
我们在手册里进行查看:
man getpid
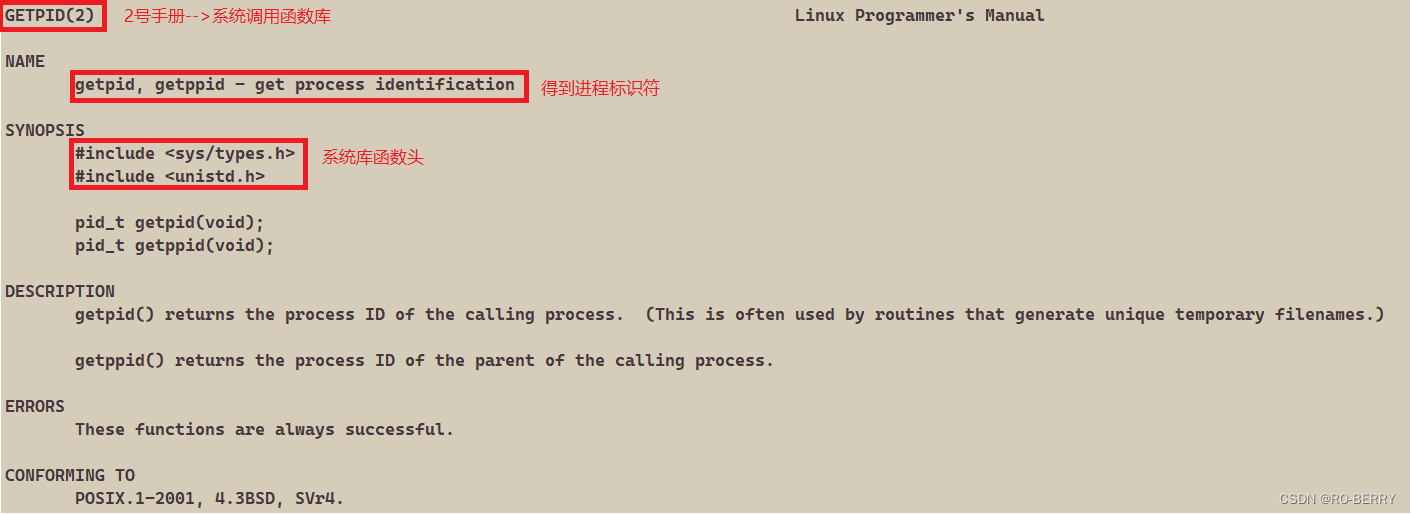
我们利用此函数重新编译文件并运行
#include<stdio.h>
#include<unistd.h>
#include<sys/types.h>
in main()
{
pid_t id = getpid();
while(1)
{
printf("I am a process!pid=%d\n",id);
sleep(1);
}
return 0;
}

父进程
一般在Linux中,普通进程都有它的父进程,普通进程是父进程创建出来的
#include<stdio.h>
#include<unistd.h>
#include<sys/types.h>
in main()
{
pid_t id = getpid();
pid_t fid = getppid();
while(1)
{
printf("I am a process!pid=%d,ppid=%d\n",id);
sleep(1);
}
return 0;
}
运行结果:
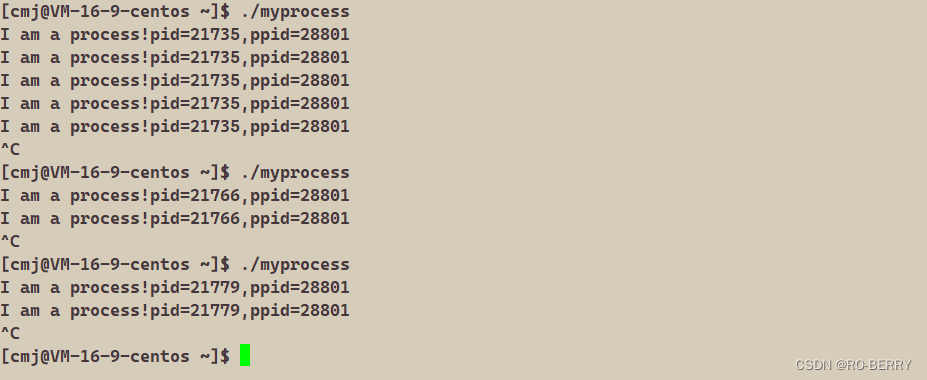
每一次启动进程的pid都会发生变化,因为每一次的进程都是一个新的进程
每一次启动进程的ppid毫无变化
父进程是什么呢?

父进程—>bash,bash就是传说中的命令行解释器,所以你在命令行中运行的所有进程都会是其子进程
📔2.3系统文件夹查看进程
Linux会将我们内存中的数据存储在某个目录里,也就是我们可以通过访问文件的方式查看进程信息
进程的信息可以在proc 系统文件夹查看
ls proc
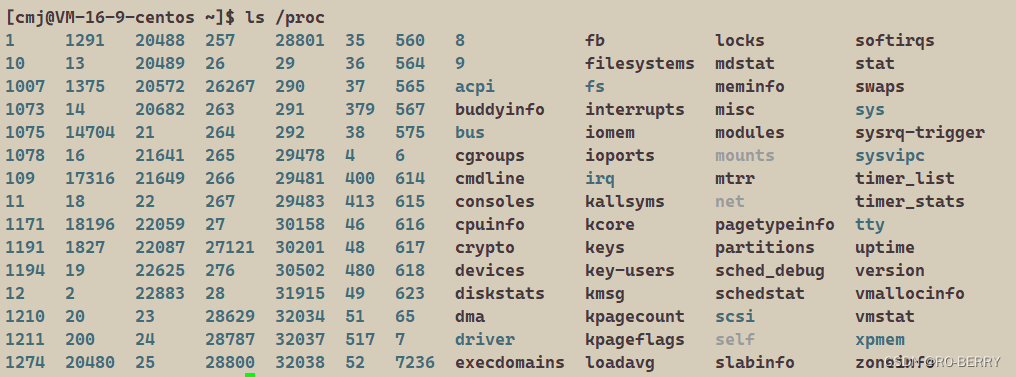
这里面以数字命名的文件就是我们的进程信息文件
ls /proc/1 -l查看PID为1的进程信息

注意:当我们进程生命周期结束后,我们的进程信息文件也会消失
当我们在执行了可执行文件后再登录这个用户并将可执行文件删除,查看此进程信息可以看到打红色高光的文字提示可执行文件已删除
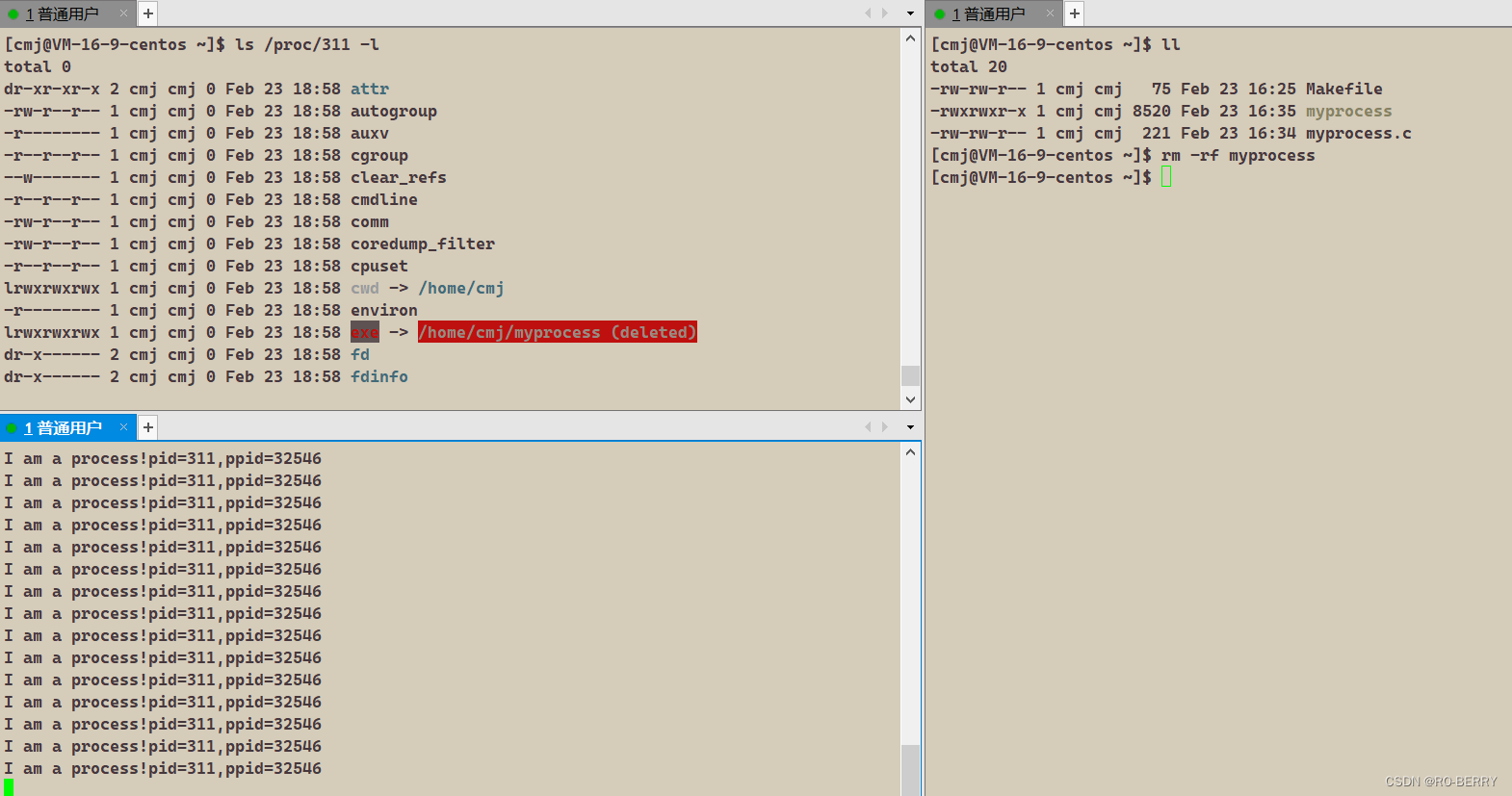
程序依然在运行,这是为什么呢?
这里就证明了我们在运行一个程序的时候,系统是从磁盘拷贝程序进行运行,说明内存当中已经变成进程的可执行程序和磁盘里的可执行文件已经毫无关系了
在我们进程信息里有一个
cwd文件,它叫做当前工作目录
这个工作目录可以人为进行修改,在代码里使用chdir(目标目录),就可以将当前工作目录改变为目标目录
📖3.通过系统调用创建进程-fork初识
一个进程,包括代码、数据和分配给进程的资源。fork()函数通过系统调用创建一个与原来进程几乎完全相同的进程,也就是两个进程可以做完全相同的事,但如果初始参数或者传入的变量不同,两个进程也可以做不同的事。 一个进程调用fork()函数后,系统先给新的进程分配资源,例如存储数据和代码的空间。然后把原来的进程的所有值都复制到新的新进程中,只有少数值与原来的进程的值不同。相当于克隆了一个自己。
man fork
fork函数在第二个字典里,也就是系统调用函数库里,其作用是创建一个子进程,参数为void,不需要参数,返回值为pid_t

📔3.1fork创建子进程
#include<stdio.h>
#include<unistd.h>
#include<sys/types.h>
int main()
{
printf("before fork: I am a process,pid:%d,ppid:%d\n",getpid(),getppid());
fork();
printf("after fork: I am a process,pid:%d,ppid:%d\n",getpid(),getppid());
sleep(2);
return 0;
}
程序运行结果:
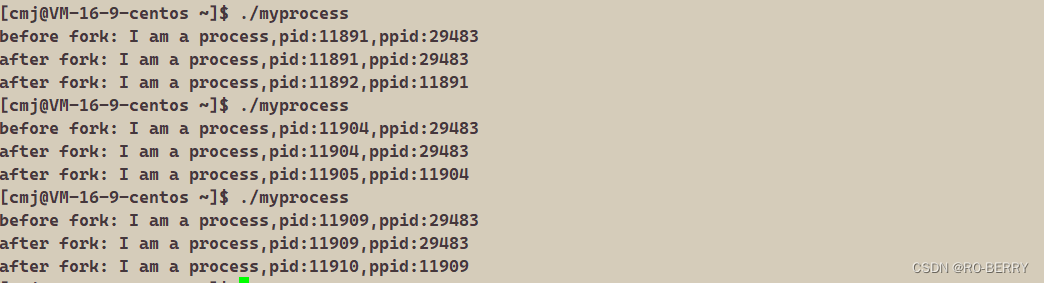
我们的
before的pid打印了一遍,after的pid打印了两遍
这里其实我们在fork之后变成了两个执行分支,创建了一个子进程,并在一起执行了
如上通过pid以及ppdid可以看到
第一个打印的进程和第二个打印的进程是同一个进程
而第三个打印的进程是我们前面那个进程的子进程
📔3.2fork的两个返回值
接下来让我们来看一下fork()函数的返回值:

这里说明了,如果函数实现成功,子进程的PID会被返回给父进程,0返回给子进程,函数实现失败会返回-1给父进程,也就是说如果成功,那么将会有两个返回值,让我们来看看是不是这样:
#include<stdio.h>
#include<unistd.h>
#include<sys/types.h>
int main()
{
printf("before fork: I am a process,pid:%d,ppid:%d\n",getpid(),getppid());
pid_t id = fork(); //返回值
printf("after fork: I am a process,pid:%d,ppid:%d,return id =%d\n",getpid(),getppid(),id); //加入return id
sleep(2);
return 0;
}
运行结果:

这里可以看到,函数实现成功,子进程的
pid返回给了父进程也就是第二次打印的return id
而新创建的子进程的return id则为0
📔3.3子进程的作用
一般而言我们创建子进程是为了帮我们办事,我们想让父子进程做不同的事
前面说了,对于父子进程的返回值是不一样的
所以我们可以使用if else语句针对返回值让父子进程执行不同的工作
例:
1 #include<stdio.h>
2 #include<unistd.h>
3 #include<sys/types.h>
4 int main()
5 {
6 printf("before fork: I am a process,pid:%d,ppid:%d\n",getpid(),getppid());
7 sleep(5);
printf("开始创建进程了!\n");
sleep(1);
8 pid_t id = fork();
9 if(id < 0 )
10 return 1; //函数执行失败返回1
11 else if(id == 0)
12 {
13 //返回值为0进入子进程
14 while(1){
15 printf("after fork,我是子进程,I am a process,pid:%d,ppid:%d,return ID=%d\n",getpid(),getppid(),id);
16 sleep(1);
17 }
18 }
19 else{
20 //返回值为其他进入父进程
21 while(1){
22 printf("after fork,我是父进程,I am a process,pid:%d,ppid:%d,return ID=%d\n",getpid(),getppid(),id);
23 sleep(1);
24 }
25 }
26
27 printf("after fork: I am a process,pid:%d,ppid:%d,return ID =%d\n",getpid(),getppid(),id);
28
29 sleep(2);
30
31 return 0;
32 }
在这里,我们给父进程以及子进程写了两个死循环,因为我们fork出来的进程是和父进程同步执行的,那么我们必然会看到两个进程同步执行的情况,这是俩执行流,并且我们通过ps可以看到两个进程
- 运行结果:
两个窗口相同用户,一个查看进程状态一个运行程序
实时查看进程状态:
while :;do ps ajx | head -1 && ps ajx | grep myprocess | grep -v grep ;sleep 1; done

这里可以看到父子进程确实完成了不同的任务并且同时跑了起来
结论:
创建一个进程的时候,系统会多一个进程
子进程被创建,是以父进程为模版
📔3.4重思fork返回值
1.给父进程返回子进程的pid,给子进程返回0,为什么?
2.fork函数为什么会返回两次
3.在上面程序里为了让父子进程执行不同操作设置了id接受返回值,那么id怎么可能一个变量,即=0.又大于0呢?
- 双返回值
日常生活中,父子关系是1:n的,同理,父进程是唯一的,对于子进程是只能找到一个父进程也是唯一的,父进程需要子进程的pid进行子进程做标识,也就相当于取名字,这样才能区分子进程
- 返回两次
前面说过,子进程是继承了父进程的代码的,也就是说return语句也会在各自两个进程里进行返回值,这也就是返回两次的原因
- id既等于0又大于0
首先一个进程挂掉是不会影响另一个进程的,进程之间具有独立性,互相不会干扰,OS在设计的时候就会考虑这个问题。也就是说,我们的父子进程在同时进行对id值进行修改的时候,OS会考虑到进程之间的独立性会去介入,对其中一个进程进行写时拷贝,拷贝一个id出来使用另一个空间,导致了两个不同的值具有了相同的变量名,这也是Linux所特有的,这个时候解释就很容易了,因为父子进程所使用的id对应的是不同的内存空间,也就是不同的值

















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











