






定义一个自定义链表,存储两个id,left为左对象的id,right为右对象的id,
同一个链表中的左右对象id不能重复,
不同链表中的
前一个节点的右对象只能够与后一个节点的左对象相连接,要求输出对象路径顺序,以left与right的顺序输出,
例图1-1:
输入一个链表数组(可自定义),传入5个链表对象.指定一个起点对象,这里指定node:11为起点
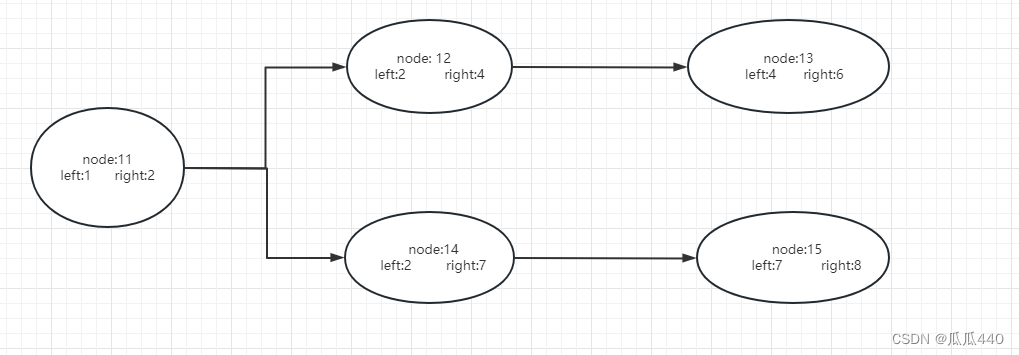
图1-1
输出:
1(11)->2(11)->2(12)->4(12)->4(13)->6(13)
1(11)->2(11)->2(14)->7(14)->7(15)->8(15)
首先考虑深度优先算法(DFS)+回溯算法.
深度优先算法(Depth First Search,简称DFS):它是一种用于遍历或搜索树或图的暴力算法,沿着树的深度遍历树的节点,尽可能深的遍历树的分支。
回溯算法:结合深度优先算法,当路径搜索完毕后,返回上一节点,再次递归,看是否还有其他路径可以搜索,这样可以搜索有向图的所有路径.
话不多说,上JAVA代码:
定义一个链表对象
@Data
@AllArgsConstructor
@NoArgsConstructor
public class NodeLine {
private String node;
private String left;
private String right;
}DFS测试类
public class DfsTest {
public static void main(String[] args) {
List<NodeLine> nodeLines = new ArrayList<>();
nodeLines.add(new NodeLine("11", "1", "2"));
nodeLines.add(new NodeLine("12", "2", "4"));
nodeLines.add(new NodeLine("13", "4", "6"));
nodeLines.add(new NodeLine("14", "2", "7"));
nodeLines.add(new NodeLine("15", "7", "8"));
//用来记录顶点的map
Map<String, Integer> beginIsVisited = new HashMap<>();
beginIsVisited.put("1", 0);
//用来记录节点是否被访问过,首先先将所有节点放到map中,key为node+left或node+right
Map<String, Integer> visitedMap = new HashMap<>();
for (NodeLine nodeLine : nodeLines) {
String node = nodeLine.getNode();
String left = nodeLine.getLeft();
String right = nodeLine.getRight();
if (visitedMap.containsKey(node + "-" + left)) {
String msg = "node-left重复:" + node + "-" + left;
System.out.println("msg = " + msg);
} else {
visitedMap.put(node + "-" + left, 0);
}
if (visitedMap.containsKey(node + "-" + right)) {
String msg = "node-right重复:" + node + "-" + right;
System.out.println("msg = " + msg);
} else {
visitedMap.put(node + "-" + right, 0);
}
}
//定义连线路径list(可能有多条路径)
List<String> visitedLine = new ArrayList<>();
StringBuffer stringBuffer = new StringBuffer();
dfs(nodeLines, visitedMap, "1", stringBuffer, beginIsVisited, visitedLine);
//打印路径
for (String line : visitedLine) {
//去除尾端箭头
line = line.substring(0, line.lastIndexOf("->"));
System.out.println("line = " + line);
}
}
public static void dfs(List<NodeLine> nodeLines, Map<String, Integer> visitedMap,
String beginId, StringBuffer stringBuffer, Map<String, Integer> beginIsVisited,
List<String> visitedLine) {
//递归终止条件,若节点全被访问过,则递归终止,或者循环结束
if (!visitedMap.containsValue(0)) {
//若节点不含有0,则全部被访问过
return;
}
for (NodeLine nodeLine : nodeLines) {
String node = nodeLine.getNode();
String left = nodeLine.getLeft();
String right = nodeLine.getRight();
String leftMapKey = node + "-" + left;
String rightMapKey = node + "-" + right;
//若点被访问过,则跳过
if (visitedMap.containsKey(leftMapKey) && visitedMap.containsKey(rightMapKey)) {
if ((visitedMap.get(leftMapKey) != 0) && (visitedMap.get(rightMapKey) != 0)) {
//System.out.println(leftMapKey + "节点被访问过" + rightMapKey + "节点被访问过");
continue;
}
}
//先找出起点
if (left.equals(beginId)) {
//点对点,记录该点被访问
visitedMap.put(leftMapKey, 1);
visitedMap.put(rightMapKey, 1);
//记录顶点被访问
if (beginIsVisited.containsKey(beginId)) {
beginIsVisited.put(beginId, 1);
}
stringBuffer.
append(left).
append("(").append(node).append(")").
append("->").
append(right).
append("(").append(node).append(")").
append("->");
//开始递归遍历
dfs(nodeLines, visitedMap, right, stringBuffer, beginIsVisited, visitedLine);
//选择回溯的点位来记录终点情况
//添加的路径长度
int addLength = left.length() + 1 + node.length() + 1 + 2 + right.length() + 1 + node.length() + 1 + 2;
//这里要深拷贝一个对象:重新定义一个string对象.stringBuffer赋值为浅拷贝,
//会改变原有stringBuffer的值,而实例化一个string对象则可以直接赋值.
String s = stringBuffer.toString();
// 若路径中不含有该路径,则添加进路径集合中
if (!lineContains(visitedLine, s)) {
visitedLine.add(s);
}
stringBuffer.delete(stringBuffer.length() - addLength, stringBuffer.length());
//回溯(点可以重复被访问)
visitedMap.put(leftMapKey, 0);
visitedMap.put(rightMapKey, 0);
}
}
}
//用来标注路径是否重复,若不重复,则记录
public static boolean lineContains(List<String> visitedLine, String s) {
for (String s1 : visitedLine) {
if (s1.startsWith(s)) {
return true;
}
}
return false;
}
}程序运行结果:
















 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









