







描述
open(name[, mode[, buffering]])函数可以打开诸如txt,csv等格式的文件。
如下,定义了file_read()函数:
def read_file(file):
"""接收文件名为参数,读取文件中的数据到字符串中,返回字符串"""
with open(file, 'r', encoding='utf-8') as text: # 创建文件对象
txt =text.read() # 读文件为字符串
return txt # 返回字符串
read_file(file)可以读取名为file的文件内容,以字符串的形式返回txt,请继续编程统计字符串txt中单词的数量。
提示:统计单词数量时,形如It’s、Let's 、don't的缩写形式要按2个单词计数。另外为了处理方便,约定所有测试文件中没有's表示所有格的情况。
输入格式
输入为一行,是一个文本文件名,如example1.txt。
输出格式
输出为一行,是对名为example1.txt的文件内容进行单词数目统计后的结果, 输出“共有m个单词”,具体格式见示例。

def read_file(file):
"""接收文件名为参数,读取文件中的数据到字符串中,返回这个字符串"""
with open(file, 'r', encoding='utf-8') as text:
txt =text.read()
return txt
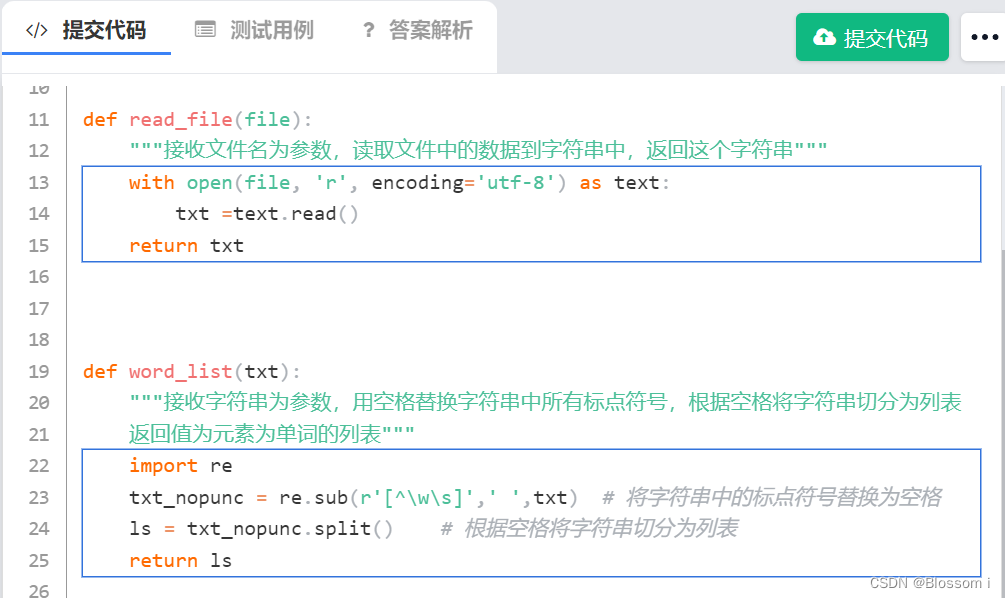
def word_list(txt):
"""接收字符串为参数,用空格替换字符串中所有标点符号,根据空格将字符串切分为列表
返回值为元素为单词的列表"""
import re
txt_nopunc = re.sub(r'[^\w\s]',' ',txt) # 将字符串中的标点符号替换为空格
ls = txt_nopunc.split() # 根据空格将字符串切分为列表
return ls
def number_of_words(ls):
"""接收一个以单词为元素的列表为参数,返回列表中单词数量,返回值为整型"""
counts = 0
for i in ls:
if '\'' not in i: # 如果单词不包含'
counts += 1 # 直接加1
else: # 如果单词包含'
if i.count('\'') == 1: # 包含'的单词只有一个
counts += 1 # 单词个数加1
else: # 单词包含'的个数大于1,表示缩写形式
counts += 2 # 单词个数加2
return counts
if __name__ == '__main__':
filename = input() # 读入文件名
text = read_file(filename) # 读取文件得到文件内容,存入text
words_list = word_list(text) # 处理text,得到单词的列表
words_counts = number_of_words(words_list)#统计单词列表word_list里的单词数
print(f'共有{words_counts}个单词')

















 4353
4353

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









