






目录
一、K近邻算法简介
1.1 K近邻算法概述
K近邻(k-Nearest Neighbor,KNN)分类算法,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一。该方法的思路是:在特征空间中,如果一个样本附近的k个最近(即特征空间中最邻近)样本的大多数属于某一个类别,则该样本也属于这个类别。
1.2 K近邻算法原理
依据相似度确定未知对象的类别是人类对事物进行分类的最简单方法,正所谓“物以类聚人以群分”。k近邻算法(KNN算法)由Thomas等人在1967年提出。它正是基于以上思想:要确定一个样本的类别,可以计算它与所有训练样本的距离,然后找出和该样本最接近的k个样本,统计出这些样本的类别并进行投票,票数最多的那个类就是分类的结果。
1.3 K近邻算法基本步骤
1.计算测试数据到每个训练数据的距离(一般采用欧氏距离,另有曼哈顿距离和马氏距离)
欧氏距离公式:
2.按照距离从小到大排列
3.选取距离最小的k个点
4.统计这k个点在各个类别中的频率
5.选取k个点所在类别频率最高的作为测试数据的预测类别
1.4 K近邻算法的特点(优缺点)
- 优点:简单,易于理解,易于实现,无需估计参数,无需训练
- 缺点:k-近邻算法是一种懒惰算法,对测试样本分类时的计算量大,内存开销大;必须指定K值,K值选择不当则分类精度不能保证 k取值过小,则无法有效应对异常点影响 k值取过大,则导致计算量过大,且容易受最近数据太多影响。
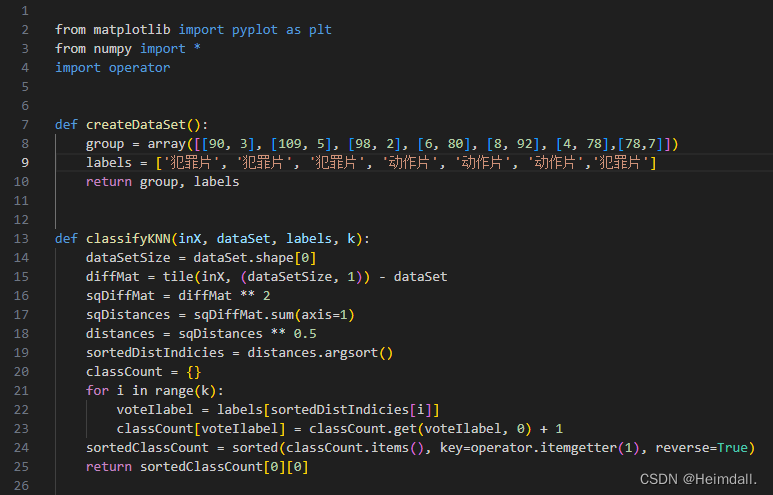
二、K-NN算法的简单实现
以电影镜头分类为例
| 影片名字 | 打斗镜头出现次数 | 飙车镜头出现次数 | 电影类别 |
|---|---|---|---|
| 坚如磐石 | 90 | 3 | 犯罪片 |
| 莫斯科行动 | 109 | 5 | 犯罪片 |
| 惊天魔盗团 | 98 | 2 | 犯罪片 |
| 极盗车神 | 6 | 80 | 动作片 |
| 速度与激情8 | 8 | 92 | 动作片 |
| 头文字D | 4 | 78 | 动作片 |
| 寒战2 | 78 | 7 | 犯罪片 |
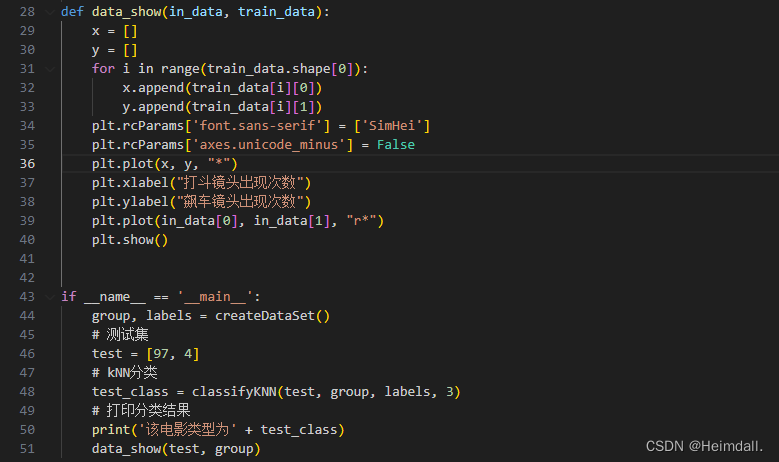
代码部分:
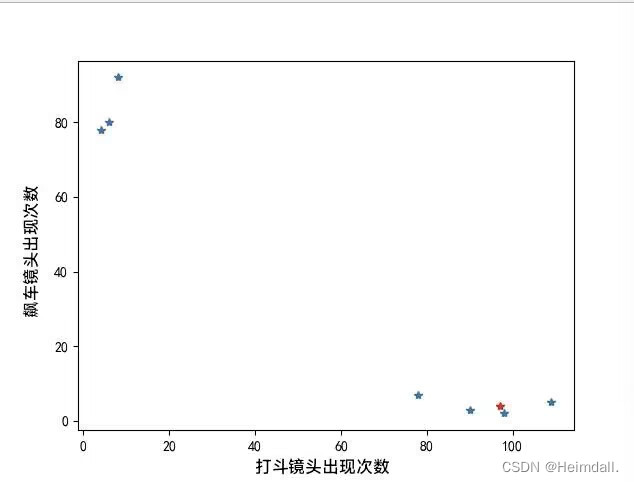
运行结果:
三、思考总结
KNN算法中的K值是超参数,决定了参考多少个邻居的标签值。与直觉相反,当K较小时,模型复杂度高,训练误差减小,但泛化能力下降;K较大时,模型复杂度低,训练误差增大,但泛化能力稍有提高。这是因为当K小(如k=1)时,仅使用局部邻居样本进行预测,拟合能力强,但容易受噪声影响,导致过拟合。此时,借助其他邻居样本可以减少噪声影响。当K过大时,容易出现欠拟合情况。
为找到最优K值,可以采用交叉验证法不断尝试不同K值,从小到大逐渐增加,计算验证集方差,找到最合适K值。除此之外,也可根据经验选择最佳K值范围,如针对特定数据集多次试验。















 1977
1977











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









