







线性表 链式存储
前言
线性表的链式存储
概念:链式存储结构的线性表称为线性链表。由结点构成,每个结点包含数据域(值域)与指针域。

分类:根据线性链表指针的设置,可分为:
- 单(向)链表(循环单链表):一根指针指向后继
- 双(向)链表(循环双链表):两根指针指向后继和前驱
特点:
- 不要求逻辑上相邻的元素物理位置也相邻;
- 元素之间的逻辑关系由指针表示,访问时只能通过头指针进入链表,并通过每个结点的指针域向后扫描其余结点,所以寻找第一个结点和最后一个结点所花费的时间不等(顺序存取机制)
优点:
- 数据元素的个数可以自由扩充
- 插入、删除等操作不必移动数据,只需修改链接指针,修改效率较高
缺点:
-
元素逻辑关系需要添加一指针域,需较多内存,存储密度低
-
算法相对复杂些,顺序存储
一、单链表
1.定义和表示
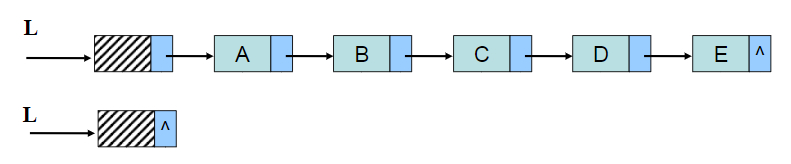
单链表是由带指针的结点构成的序列,指针表示个结点的先后(逻辑)关系。单链表是由表头唯一确定,因此单链表可以用头指针的名字来命名。
结构定义
typedef struct LNode{
ElemType data;
struct LNode *next;
}LNode,*LinkList;
/* LNode *p same as LinkList p */

此时则有:L->next->data == a1;
P->data == ai P->next->data == a(i+1)
新建结点:
LNode *S;
S=(LNode *)malloc(sizeof(LNode));
2.基本操作的实现
·初始化(构造一个空表)
算法思想:
(1)生成新结点作为头结点,用头指针L指向头结点
(2)头结点的指针域置空
算法描述:
Status InitList(LinkList &L){
L = new LNode;
//L=(LinkList)malloc(sizeof(LNode));
L->mext = NULL;
return OK;
}
·遍历链表

利用单根指针遍历:
cp = L->next;
while(cp!=NULL) cp = cp->next;
在插入和删除中,往往需要一前一后两根指针ap,cp(ap为cp的前驱)
ap = L;
cp = L->next;
while(cp!=NULL){
ap = cp;
cp = cp->next;
}
·清空单链表
Status ClearList(LinkList &L){/*将L重置为空链表*/
LNode *p,*q;
p = L->next; /*p指向第一个结点*/
while(p){ /*遍历至表尾*/
q = p->next;
delete p;
p=q;
}
L->next = NULL; /*头结点指针域置空*/
/*
若destroy
delete L; L=NULL;
*/
return OK;
}
·查找
链表的查找:要从链表的头指针出发,顺着链域next逐个结点往下搜索,直至搜索到第i个结点为止。因此,链表不是随机存取结构,而是顺序存取。
查找第 i 个元素:
Status GetElem(LinkList L,int i,ElemType &e){/*取带头结点单链表L中第i个元素值,由e带回*/
LNode *p = L->next; /*初始化,p指向首元结点*/
int j=1; /*初始化,计数器j为1,当前第一个*/
while(p&&j<i){ /*直到p为空或指向第i个元素*/
p = p->next;
++j;
}
if(!p||j>i) return ERROR; /*i值不合法*/
e = p->data;
return OK;
}
时间复杂度为O(n)。
查找值为e的元素:
LNode *LocateElem(LinkList L,elemType e){/*若找到返回指向该结点的指针,否则返回NULL*/
LNode *P = L->next;
while(P && P->data!=e)
p = p->next;
return p;
}
· 插入与删除
对于链表来说,由于存储位置通过指针来链接,插入和删除操作只需修改结点间的指针关系。
在位置 i 插入值为 e 的元素:
算法思想:
(1)找到a(i-1)存储位置p,即新结点的前驱
(2)生成一个新结点S
(3)将新结点S的数据域置为e
(4)新结点*S的指针域指向结点ai

算法实现:
Status ListInsert(LinkList &L,int i,ElemType e){
LNode *p = L;
int j = 0;
while(p && j < i-1){
p = p->next;
++j;
}/*寻找第i-1个结点*/
if(!p||j>i-1) return ERROR;
s = new LNode;
s->data = e;
s->next = p->next;/*将结点s插入L中*/
p->next = s;
return OK;
}
删除
算法思想:
(1)找到a(i-1)存储位置p(被删结点的前驱)
(2)临时保存结点ai的地址在 r 中,以备释放
(3)零p->next 指向ai的直接后继结点
(4)释放ai的空间
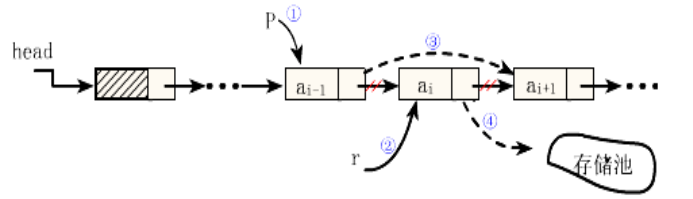
算法实现:
Status ListDelete(LinkList &L,int i){
p=L; j=0;
while(p->next && j<i-1){
p = p->next;
++j;
} /*第i个结点的前驱结点p*/
if(!(p->next) || j>i-1) return ERROR;/*删除位置不合理*/
q = p->next; /*q指向待删结点,以备释放*/
p->next = q->next; /*改变删除结点前驱结点的指针域*/
delete q;
return OK;
}
创建单链表
- InitList()是创建一个只有头结点的空链表。
- 链表中各个元素(结点)是动态生成并插入到链表中。即从空表开设,逐个生成结点并插入。
- 链表可根据需要有不同的生成方式,包括:前插法、后插法、有序插入法
前插法建立单链表
算法思路:
(1)InitList();
(2)循环以下操作
生成新结点p
输入新结点p的元素值(p->data)
将新结点p插入到链表的头结点之后
链表结点顺序域输入顺序相反
算法实现:
void CreateList_H(LinkList &L,int n){
L = new LNode;
L->next = NULL; /*InitList*/
for(int i=0;i<n;i++){
p = new LNode; /*生成新结点*/
cin >> p->data; /*输入元素值*/
p->next = L->next;
L->next = p; /*插入到表头*/
}
}
后插法建立单链表
算法思路:
(1)InitList();
(2)循环以下操作:
生成新结点p
输入新结点p的元素值(p->data)
将新结点p插入到链表的最后
(用一个尾指针 r 指向链表的最后一个结点)
链表结点顺序与输入顺序相同
算法实现:
void CreateList_R(LinkList &L,int n){
L = new LNode;
L->next = NULL; /*initial*/
r = L; /*初始时,尾指针r指向头结点*/
for(int i=0;i<n;i++){
p = new LNode;
cin>>p->data;
p->next = NULL;
r->next = p; /*插入到表尾*/
r = p; /*r指向新的尾结点*/
}
}
有序插入法建立单链表
算法思路:
(1)InitList();
(2)循环以下操作:
生成新结点p
输入新结点p的元素值(p->data)
找到新结点的位置,将新结点p插入
(用一个指针 q 指向插入位置)
算法实现:
void CreateList_S(LinkList &L,int n){
L = new LNode;
L->next = NULL;
q = L;
for(int i=0;i<n;i++){
p = new LNode;
cin>>p->data;
q=L; r=q->next; /*开始找插入位置*/
while(r!=NULL && r->data < p->data){
q = r; r = r->next;
} /*循环找到p所在位置,即q,r间插入p*/
p->next = r; q->next = p;
}
}
mooc链式表结构
typedef struct LNode *PtrToLNode;
struct LNode {
ElementType Data;
PtrToLNode Next;
};
typedef PtrToLNode Position;
typedef PtrToLNode List;
/* 查找 */
#define ERROR NULL
Position Find( List L, ElementType X )
{
Position p = L; /* p指向L的第1个结点 */
while ( p && p->Data!=X )
p = p->Next;
/* 下列语句可以用 return p; 替换 */
if ( p )
return p;
else
return ERROR;
}
/* 带头结点的插入 */
/*注意:在插入位置参数P上与课程视频有所不同,课程视频中i是序列位序(从1开始),这里P是链表结点指针,在P之前插入新结点 */
bool Insert( List L, ElementType X, Position P )
{ /* 这里默认L有头结点 */
Position tmp, pre;
/* 查找P的前一个结点 */
for ( pre=L; pre&&pre->Next!=P; pre=pre->Next ) ;
if ( pre==NULL ) { /* P所指的结点不在L中 */
printf("插入位置参数错误\n");
return false;
}
else { /* 找到了P的前一个结点pre */
/* 在P前插入新结点 */
tmp = (Position)malloc(sizeof(struct LNode)); /* 申请、填装结点 */
tmp->Data = X;
tmp->Next = P;
pre->Next = tmp;
return true;
}
}
/* 带头结点的删除 */
/*注意:在删除位置参数P上与课程视频有所不同,课程视频中i是序列位序(从1开始),这里P是拟删除结点指针 */
bool Delete( List L, Position P )
{ /* 这里默认L有头结点 */
Position pre;
/* 查找P的前一个结点 */
for ( pre=L; pre&&pre->Next!=P; pre=pre->Next ) ;
if ( pre==NULL || P==NULL) { /* P所指的结点不在L中 */
printf("删除位置参数错误\n");
return false;
}
else { /* 找到了P的前一个结点pre */
/* 将P位置的结点删除 */
pre->Next = P->Next;
free(P);
return true;
}
}
二、循环链表
与单链表的最大区别在于:循环链表的最后一个结点的指针指向头结点,整个链表形成一个环。
最大优势在于:从表中任意一个结点出发都可找到表中其他结点。
循环单链表的操作与单链表基本一致,但由于循环链表结点中不存在为NULL的指针域,故只需改变两处判断:
- 空表:L->next = L (单链表:L->next = NULL);
- 表尾:r ->next = L (单链表:r ->next = NULL);
eg:求链表长度的代码实现:
int ListLength(LinkList L){/*单链表*/
p = L->next; k=0;
while(p!=NULL){
k++;
p = p->next;
}
return k;
}
int ListLength(CLinkList L){/*循环链表*/
p = L->next; k=0;
while(p!=L){
k++;
p = p->next;
}
return k;
}
某些情况下,循环链表只设置尾指针更合理,既方便找尾结点,又方便找首结点,如循环链表的合并。

p=B->next->next;
B->next=A->next;
A->next=p
三、双向链表
基本结构
相较于单向链表,双向链表的结点结构中除设置一根指向后继的指针外,还设置一根指向前驱的指针, 故既能往后找后继,又能往前找前驱。

结点结构:
typedef struct DuLNode{
ElemType data;
struct DuLNode *prior;
struct DuLNode *next;
}
双向链表的指针关系:

p->data=='B';
p->next->data=='C';
p->prior->data=='A';
p->prior->next==p;
p->next->prior==p;
双向链表也可以有循环,称双向循环链表。此时存在两个环,一个通过next,另一个通过prior。

一些操作的实现
双向链表的插入

基本步骤:
- s->prior = p->prior;
- p->prior->next = s;
- s->next = p;
- p->prior = s;
算法实现:
Status ListInsert_DuL(DuLinkList &L,int i,ElemType e){
if(!(p=GetElem_DuL(L,i)))/*确定第i个元素位置指针p*/
return ERROR;
s = new DuLNode;
s->data = e;
s->prior=p->prior; /*插入,修改指针关系*/
p->prior->next=s;
s->next=p;
p->prior=s;
return OK;
}
双向链表的删除
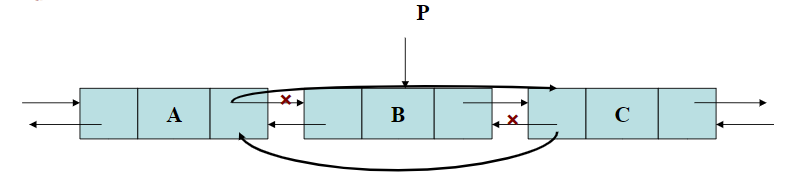
基本步骤
- p->prior->next = p->next;
- p->next->prior = p->prior;
- delete p;
算法实现:
Status ListDelete_DuL(DuLinkList &L,int i){
if(!(p=GetElem_DuL(L,i)))/*确定第i个元素位置指针p*/
return ERROR;
p->prior->next=p->next; /*删除结点,修改指针关系*/
p->next->prior=p->prior;
delete p;
return OK;
}















 2909
2909











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









