






01 简要介绍
最近翻阅了LLaVA1.5的论文《Improved Baselines with Visual Instruction Tuning》[1],感叹多模态模型发展迅猛之余,也感觉非常的有意思,便想着自己尝试微调。论文作者贴心地在代码仓库提供了微调的脚本,但是由于微调过程会踩到很多坑(报错调了N个小时),因此记录下微调的笔记供需要的人参考。
02 前置环境准备
下载项目
git clone https://github.com/haotian-liu/LLaVA.git
cd LLaVA因为里面有一个flash-attn库,很难安装,如果不跟着配置环境,很可能出现报错。
环境准备
conda create -n llava python=3.10 -y
conda activate llava
pip install --upgrade pip # enable PEP 660 support
pip install -e . # 在当前工作目录下执行setup.py文件,太慢可以在后面加 -i https://pypi.tuna.tsinghua.edu.cn/simple为训练安装额外的软件包
pip install -e ".[train]"
pip install flash-attn --no-build-isolation03 下载预训练权重
(1)下载 llava-v1.5-7b 预训练权重
在下载 llava-v1.5-7b 的预训练权重前,最好提前预留15G以上的存储空间,7B的模型空间占用比较大。
懒人操作:可以在 LLaVA 的项目根目录中创建python文件,填入并运行下述代码,可以自动将 llava-v1.5-7b 的权重提前下载到本地的缓存文件夹(linux的话一般是在~/.cache下)。
from llava.model.builder import load_pretrained_model
from llava.mm_utils import get_model_name_from_path
from llava.eval.run_llava import eval_model
model_path = "liuhaotian/llava-v1.5-7b"
tokenizer, model, image_processor, context_len = load_pretrained_model(
model_path=model_path,
model_base=None,
model_name=get_model_name_from_path(model_path)
)(2)下载 clip-vit-large-patch14-336 预训练权重
这个是 LLaVA1.5 的视觉编码器的预训练权重,占用比较小,大概 2G。
下面也是懒人操作,填入代码运行后即可下载本地(已设置了下载的模板防止下载太多文件)。
from huggingface_hub import snapshot_download
snapshot_download(repo_id="openai/clip-vit-large-patch14-336", allow_patterns=["*.json", "model.safetensors", "vocab.txt"])04 简单对话测试
我们用下面的图片做下简单的对话测试(记得修改成自己的显卡id+测试图片路径),

测试图片
export CUDA_VISIBLE_DEVICES=2
python -m llava.serve.cli \
--model-path liuhaotian/llava-v1.5-7b \
--image-file "playground/data/test/images/image.png" \
--load-4bit竟然还能识别出吊带,不过无法识别出里面的人是谁,我们要微调让MLLM明白他是谁。

05 准备微调数据
我们在 playground/data 文件夹下创建 test 文件夹,用于存放训练用的 json 文件。在新建的 test 文件夹中再创建 images 文件夹,用于存放图片,我们把下面这张图片保存到其中,命名为 image.png。
测试图片
然后我们在 playground/data/test 中创建 test.json 并填入:
[
{
"id": "997bb945-628d-4724-b370-b84de974a19f",
"image": "image.png",
"conversations": [
{
"from": "human",
"value": "<image>\nDescribe this picture briefly in one sentence."
},
{
"from": "gpt",
"value": "In the image, there is a person named \"Kun\" who is skillfully spinning a basketball on their finger."
}
]
}
]准备妥当后,文件的目录展示如下:
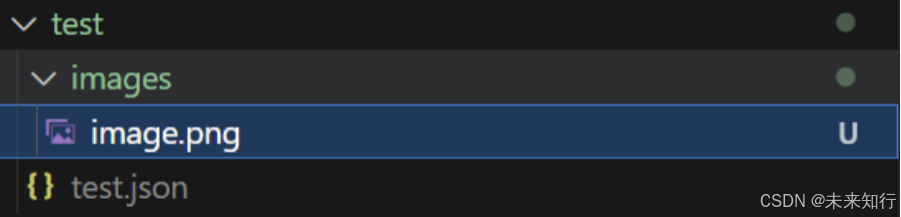
文件目录形式截图
06 开始进行LoRA微调
我们将 scripts/v1_5/finetune_task_lora.sh 修改成如下(记得修改自己的显卡id),
#!/bin/bash
export TRANSFORMERS_OFFLINE=1 # 设置为1时,启用Transformers的离线模式
### deepspeed单机多卡设置显卡,不要使用export CUDA_VISIBLE_DEVICES=2,5,改成deepspeed --include localhost:2,5
# export CUDA_VISIBLE_DEVICES=2,5
include=localhost:4 # 设置显卡id
model_name_or_path=liuhaotian/llava-v1.5-7b # 模型名称
data_path=./playground/data/test/test.json # 训练的json
image_folder=./playground/data/test/images # 训练的图像数据
deepspeed --include $include llava/train/train_mem.py \
--lora_enable True --lora_r 8 --lora_alpha 16 --mm_projector_lr 2e-5 \
--deepspeed ./scripts/zero3.json \
--model_name_or_path $model_name_or_path \
--version v1 \
--data_path $data_path \
--image_folder $image_folder \
--vision_tower openai/clip-vit-large-patch14-336 \
--mm_projector_type mlp2x_gelu \
--mm_vision_select_layer -2 \
--mm_use_im_start_end False \
--mm_use_im_patch_token False \
--image_aspect_ratio pad \
--group_by_modality_length False \
--bf16 True \
--output_dir ./checkpoints/llava-v1.5-7b-task-lora \
--num_train_epochs 8 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--gradient_accumulation_steps 1 \
--evaluation_strategy "no" \
--save_strategy "steps" \
--save_steps 50000 \
--save_total_limit 1 \
--learning_rate 2e-4 \
--weight_decay 0. \
--warmup_ratio 0.03 \
--lr_scheduler_type "cosine" \
--logging_steps 1 \
--tf32 True \
--model_max_length 2048 \
--gradient_checkpointing True \
--dataloader_num_workers 4 \
--lazy_preprocess True \
--report_to wandb然后运行微调脚本进行微调,
source ./scripts/v1_5/finetune_task_lora.sh(1)报错 "ImportError: cannot import name 'EncoderDecoderCache' from 'transformers'"

报错信息截图
是因为 transformers 库和 peft 的版本兼容问题。如果遇到,可以打开配置文件 pyproject.toml,将 peft 修改成 peft==0.13.2,之后重新运行下载程序,
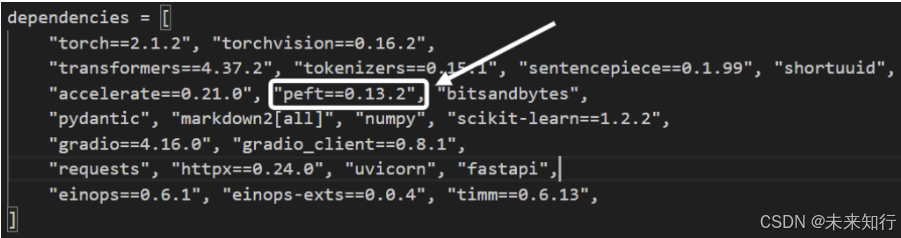
配置文件 pyproject.toml 的截图展示
pip install -e .然后重新运行 sh 脚本。
source ./scripts/v1_5/finetune_task_lora.sh(2)wandb选择
在进行LoRA微调的时候,会在命令行弹出3个选项给你选择,如果没有使用过wandb的用户,可以选择创建新的wandb账户,然后填入API key即可查看训练过程的可视化界面。
07 LoRA权重合并
记得修改 --model-base 的【占位符】为你本地存放 llava-v1.5-7b 的文件夹位置。Linux系统下,一般huggingface自动下载都在~/.cache文件夹里。运行下面的命令后,合并后的权重会保存在 ./checkpoints/llava-v1.5-7b-task-lora-merged 文件下,
python scripts/merge_lora_weights.py --model-path "checkpoints/llava-v1.5-7b-task-lora" \
--model-base "【占位符】" \
--save-model-path "checkpoints/llava-v1.5-7b-task-lora-merged"08 LoRA后本地推理
现在我们微调完毕啦~来看看微调的效果如何(记得修改显卡ID为自己的显卡id),可见MLLM成功输出了我们需要的信息,
export CUDA_VISIBLE_DEVICES=2
python -m llava.serve.cli \
--model-path ./checkpoints/llava-v1.5-7b-task-lora-merged \
--image-file "playground/data/test/images/image.png" \
--load-4bit
模型输出截图
如果您觉得这篇文章对您有帮助,请点赞支持一下~

参考
- Liu H, Li C, Li Y, et al. Improved baselines with visual instruction tuning[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2024: 26296-26306.




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











