







实验要求
【大数据导论实验】教学大纲
【适用专业】计算机科学与技术、软件工程、物联网工程
【教学目标】了解分布式结构和Linux命令,基本掌握Hadoop的安装、HDFS编程、MapReduce的编程。
【实验教学项目表】
| 1 | 项目 | Hadoop 安装与使用 | 时数 | 4 | 性质 | 验证 |
| 内容 要求 | 在虚拟机上安装Linux,安装Hadoop,了解Linux和Hadoop的基本命令。 | |||||
| 2 | 项目 | HDFS的应用 | 时数 | 4 | 性质 | 设计 |
| 内容 要求 | 熟悉hadoop文件命令,熟悉在Linux编写、编译、运行JAVA程序的过程,实现文件的读写操作,读出数据并排序。 | |||||
| 3 | 项目 | Mapreduce的应用I—Top10WordCount | 时数 | 4 | 性质 | 设计 |
| 内容 要求 | 熟悉在Linux使用JAVA编写、编译、运行MapReduce程序的过程。编写wordcount程序,找出词频排前10的词。 | |||||
| 4 | 项目 | Mapreduce的应用II—电影推荐 | 时数 | 4 | 性质 | 设计 |
| 内容 要求 | 使用3阶段MapReduce解决方案来实现电影推荐。阶段1:找出各个电影的评分人总数;阶段2:对于电影A和B,找出所有同时对A和B评分的人;阶段3:找出每两个相关电影之间的关联。 | |||||
【实验报告要求】实验报告中应明确说明实验题目、实验目的、完成日期、主要设计思想和算法、实验结果以及总结。应杜绝出现内容完全相同的实验报告
【实验成绩评定】实验成绩由三个部分组成:实验出勤部分(占10%)、实验完成部分(占80%)和实验报告部分(占10%)。实验完成部分由学生所完成的4个实验结果决定;实验报告部分根据所提交的实验报告的内容、格式、正确性以及独立性几个方面综合评定。
【选用教材】《大数据技术原理与应用》(第二版)(林子雨编著,人民邮电出版社,2017年)
【参考书目】
《数据算法/Hadoop/Spark大数据处理技巧》(Mahmoud Parsian 著,苏金国 杨健康等译,中国电力出版社,2016年版)
实验1
一、实验内容
在虚拟机上安装Linux,安装Hadoop,了解Linux和Hadoop的基本命令。
二、实验目的
1、了解Hadoop的3种运行模式。
2、熟练掌握Hadoop伪分布模式安装流程。
3、培养独立完成Hadoop伪分布安装的能力。
4、了解Eclipse开发环境的使用
5、熟练掌握Hadoop开发插件安装
三、实验环境
Linux Ubuntu 16.02
jdk-8u162-linux-x64
hadoop-3.1.3
eclipse-4.7.0-linux.gtk.x86_64
四、实验步骤
1.创建hadoop用户
sudo useradd -m hadoop -s /bin/bash
sudo passwd hadoop
sudo adduser hadoop sudo
2.更新ubuntu软件包
sudo apt-get update
3.安装vim
sudo apt install vim
安装软件时若需要确认,在提示处输入 y 即可
vim的常用模式有分为命令模式,插入模式,可视模式,正常模式。本教程中,只需要用到正常模式和插入模式。二者间的切换即可以帮助你完成本指南的学习。
(1)正常模式
正常模式主要用来浏览文本内容。一开始打开vim都是正常模式。在任何模式下按下Esc键就可以返回正常模式
(2)插入编辑模式
插入编辑模式则用来向文本中添加内容的。在正常模式下,输入i键即可进入插入编辑模式
(3)退出vim
如果有利用vim修改任何的文本,一定要记得保存。Esc键退回到正常模式中,然后输入:wq即可保存文本并退出vim
4.安装SSH、配置SSH无密码登陆
sudo apt-get install openssh-server
ssh localhost
首先退出刚才的 ssh,就回到了我们原先的终端窗口,然后利用 ssh-keygen 生成密钥,并将密钥加入到授权中:
exit # 退出刚才的 ssh localhost
cd ~/.ssh/ # 若没有该目录,请先执行一次ssh localhost
ssh-keygen -t rsa # 会有提示,都按回车就可以
cat ./id_rsa.pub >> ./authorized_keys # 加入授权
5.安装Java环境
cd /usr/lib
sudo mkdir jvm #创建/usr/lib/jvm目录用来存放JDK文件
cd ~ #进入hadoop用户的主目录
cd Downloads #注意区分大小写字母,刚才已经通过FTP软件把JDK安装包jdk-8u371-linux-x64.tar.gz上传到该目录下
sudo tar -zxvf ./jdk-8u371-linux-x64.tar.gz -C /usr/lib/jvm #把JDK文件解压到/usr/lib/jvm目录下
JDK文件解压缩以后,可以执行如下命令到/usr/lib/jvm目录查看一下:
cd /usr/lib/jvm
ls
可以看到,在/usr/lib/jvm目录下有个jdk1.8.0_371目录。
下面继续执行如下命令,设置环境变量:
cd ~
vim ~/.bashrc
打开了hadoop这个用户的环境变量配置文件,请在这个文件的开头位置,添加如下几行内容:
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_371
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
保存.bashrc文件并退出vim编辑器。然后,继续执行如下命令让.bashrc文件的配置立即生效:
source ~/.bashrc
查看是否安装成功
java -version
6.安装 Hadoop3.3.5
将 Hadoop 安装至 /usr/local/ 中:
sudo tar -zxvf ~/下载/hadoop-3.3.5.tar.gz -C /usr/local
# 解压到/usr/local中
cd /usr/local/
sudo mv ./hadoop-3.3.5/ ./hadoop # 将文件夹名改为hadoop
sudo chown -R hadoop ./hadoop # 修改文件权限
Hadoop 解压后即可使用。输入如下命令来检查 Hadoop 是否可用,成功则会显示 Hadoop 版本信息:
cd /usr/local/hadoop
./bin/hadoop version
7.Hadoop伪分布式配置
修改配置文件 core-site.xml (通过 gedit 编辑会比较方便: gedit ./etc/hadoop/core-site.xml)
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
修改配置文件 hdfs-site.xml:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>
配置完成后,执行 NameNode 的格式化:
cd /usr/local/hadoop
./bin/hdfs namenode -format
接着开启 NameNode 和 DataNode 守护进程:
cd /usr/local/hadoop
./sbin/start-dfs.sh
五、实验结果
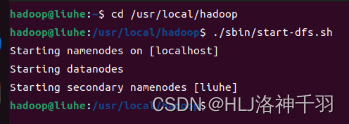
cd /usr/local/hadoop
./sbin/start-dfs.sh
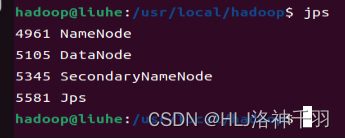
jps
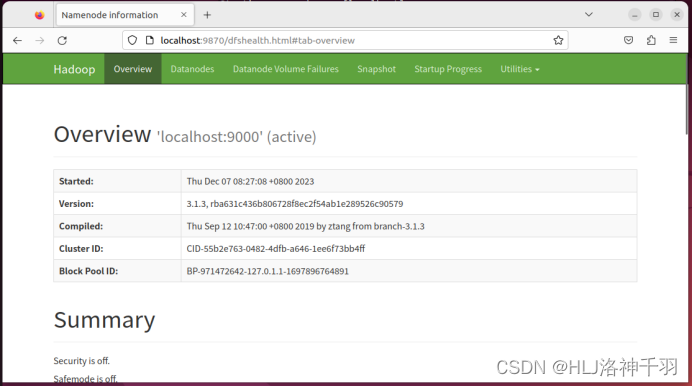
访问web页面
localhost:9870
详细可参考厦门大学林子雨教授的教程
https://dblab.xmu.edu.cn/blog/2441/
实验2
一、实验内容
熟悉在Linux使用JAVA编写、编译、运行MapReduce程序的过程。编写wordcount程序,找出词频排前10的词。
二、实验目的
1、熟悉在Linux使用JAVA编写、编译、运行MapReduce程序的过程。
2、了解Eclipse开发环境的使用
3、熟练掌握Hadoop开发插件安装
三、实验环境
Linux Ubuntu 16.02
jdk-8u162-linux-x64
hadoop-3.1.3
eclipse-4.7.0-linux.gtk.x86_64
四、实验步骤
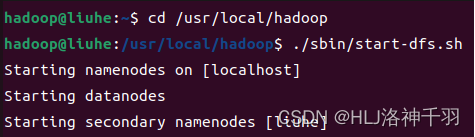
1.启动Hadoop
cd /usr/local/hadoop
./sbin/start-dfs.sh
2.查看文件
./bin/hdfs dfs -ls /user/hadoop
3.删除多余文件夹
./bin/hdfs dfs -rm -r /user/hadoop/input
./bin/hdfs dfs -rm -r /user/hadoop/output
5.创建文件夹
./bin/hdfs dfs -mkdir -p /user/hadoop/input
6.上传文件
./bin/hdfs dfs -put /home/hadoop/myfile/cipin.txt /user/hadoop/ input
7.启动eclipse
cd /usr/local/eclipse
./eclipse
为了编写一个MapReduce程序,一般需要向Java工程中添加以下JAR包:
(1)“/usr/local/hadoop/share/hadoop/common”目录下的hadoop-common-3.3.5.jar和haoop-nfs-3.3.5.jar;
(2)“/usr/local/hadoop/share/hadoop/common/lib”目录下的所有JAR包;
(3)“/usr/local/hadoop/share/hadoop/mapreduce”目录下的所有JAR包,但是,不包括jdiff、lib-examples和sources目录。
然后将Java程序打成jar包。
8.运行jar包
./bin/hadoop jar /usr/local/hadoop/myapp/WordCount.jar input output
9.输出结果
./bin/hdfs dfs -cat output/*
五、实验结果
启动hadoop
查看文件夹内容
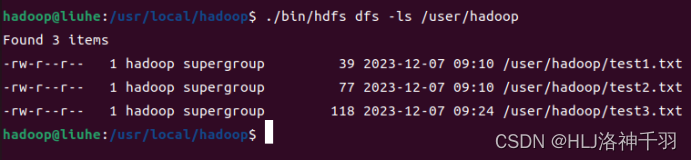
创建文件夹
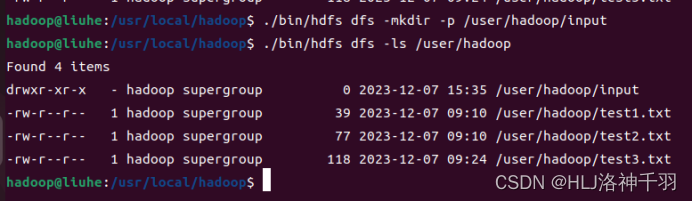
上传文件

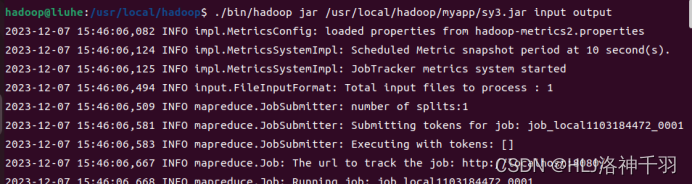
运行jar包
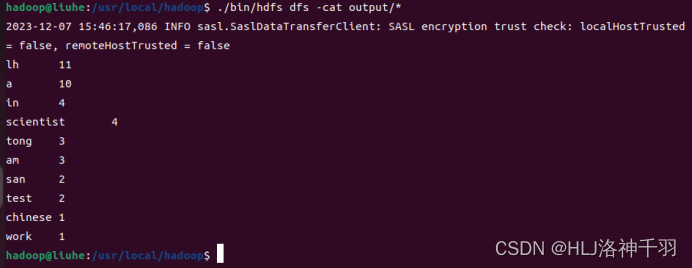
输出内容
六、源代码
package sy2;
import java.io.*;
import java.nio.charset.StandardCharsets;
import java.util.*;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import static java.lang.Integer.*;
import java.io.BufferedReader;
import java.io.InputStreamReader;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.fs.FSDataInputStream;
public class sy2 {
public static void main(String[] args){
try{
ArrayList<Integer> a = new ArrayList<Integer>();
ArrayList<Integer> b = new ArrayList<Integer>();
Configuration conf = new Configuration();
conf.set("fs.defaultFS","hdfs://localhost:9000");
conf.set("fs.hdfs.impl","org.apache.hadoop.hdfs.DistributedFileSystem");
FileSystem fs = FileSystem.get(conf);
Path file = new Path("test1.txt");
FSDataInputStream getit = fs.open(file);
BufferedReader d = new BufferedReader(new InputStreamReader(getit));
Path file1 = new Path("test2.txt");
FSDataInputStream getit1 = fs.open(file1);
BufferedReader d1 = new BufferedReader(new InputStreamReader(getit1));
String str;
while((str = d.readLine())!= null)
{
a.add(Integer.valueOf(str.trim()));
}
while((str = d1.readLine())!= null)
{
a.add(Integer.valueOf(str.trim()));
}
d.close();
d1.close();
a.sort(Comparator.naturalOrder());
for (int i : a){
System.out.println(i);
}
String filename = "test3.txt";
FSDataOutputStream os = fs.create(new Path(filename));
for(Integer i :a){
os.write(i.toString().getBytes());
os.write("\r\n".getBytes());
}
os.close();
fs.close();
}catch (Exception e){
e.printStackTrace();
}
}
}详细可参考厦门大学林子雨教授HDFS编程实践
https://dblab.xmu.edu.cn/blog/4230/
实验3
一、实验内容
熟悉在Linux使用JAVA编写、编译、运行MapReduce程序的过程。编写wordcount程序,找出词频排前10的词。
二、实验目的
1、熟悉在Linux使用JAVA编写、编译、运行MapReduce程序的过程。
2、了解Eclipse开发环境的使用
3、熟练掌握Hadoop开发插件安装
三、实验环境
Linux Ubuntu 16.02
jdk-8u162-linux-x64
hadoop-3.1.3
eclipse-4.7.0-linux.gtk.x86_64
四、实验步骤
1.启动Hadoop
cd /usr/local/hadoop
./sbin/start-dfs.sh
2.查看文件
./bin/hdfs dfs -ls /user/hadoop
3.删除多余文件夹
./bin/hdfs dfs -rm -r /user/hadoop/input
./bin/hdfs dfs -rm -r /user/hadoop/output
5.创建文件夹
./bin/hdfs dfs -mkdir -p /user/hadoop/input
6.上传文件
./bin/hdfs dfs -put /home/hadoop/myfile/cipin.txt /user/hadoop/ input
7.启动eclipse
cd /usr/local/eclipse
./eclipse
为了编写一个MapReduce程序,一般需要向Java工程中添加以下JAR包:
(1)“/usr/local/hadoop/share/hadoop/common”目录下的hadoop-common-3.3.5.jar和haoop-nfs-3.3.5.jar;
(2)“/usr/local/hadoop/share/hadoop/common/lib”目录下的所有JAR包;
(3)“/usr/local/hadoop/share/hadoop/mapreduce”目录下的所有JAR包,但是,不包括jdiff、lib-examples和sources目录。
然后将Java程序打成jar包。
8.运行jar包
./bin/hadoop jar /usr/local/hadoop/myapp/WordCount.jar input output
9.输出结果
./bin/hdfs dfs -cat output/*
五、实验结果
启动hadoop
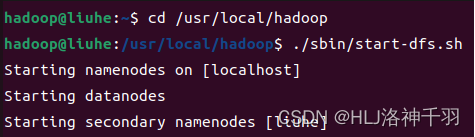
查看文件夹内容
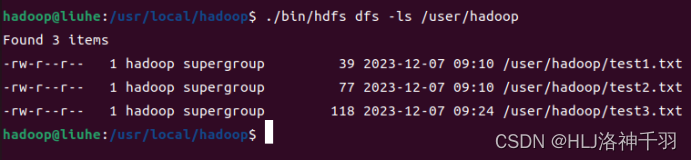
创建文件夹
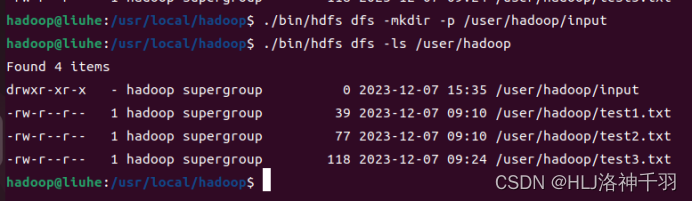
上传文件

运行jar包
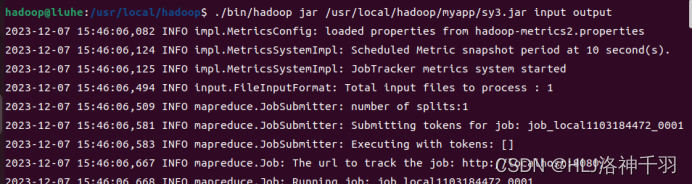
输出内容实验结果
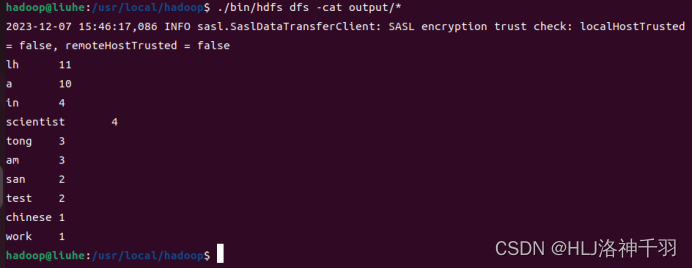
六、源代码
package sy3;
import java.io.IOException;
import java.util.Collections;
import java.util.Comparator;
import java.util.HashMap;
import java.util.LinkedList;
import java.util.List;
import java.util.Map;
import java.util.Map.Entry;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class sy3 {
public static class WsMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
@Override
public void map(LongWritable key, Text value, Context context)throws IOException, InterruptedException {
String[] split = value.toString().split(" ");
for (String word : split) {
context.write(new Text(word), new IntWritable(1));
}
}
}
public static class WsReducer extends Reducer<Text, IntWritable, Text, IntWritable>{
Map<String,Integer> map=new HashMap<String, Integer>();
public void reduce(Text key, Iterable<IntWritable> iter,Context conext) throws IOException, InterruptedException {
int count=0;
for (IntWritable wordCount : iter) {
count+=wordCount.get();
}
String name=key.toString();
map.put(name, count);
}
@Override
public void cleanup(Context context)throws IOException, InterruptedException {
//这里将map.entrySet()转换成list
List<Map.Entry<String,Integer>> list=new LinkedList<Map.Entry<String,Integer>>(map.entrySet());
//通过比较器来实现排序
Collections.sort(list,new Comparator<Map.Entry<String,Integer>>() {
//降序排序
@Override
public int compare(Entry<String, Integer> arg0,Entry<String, Integer> arg1) {
return (int) (arg1.getValue() - arg0.getValue());
}
});
for(int i=0;i<10;i++){
context.write(new Text(list.get(i).getKey()), new IntWritable(list.get(i).getValue()));
}
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("输入参数个数为:"+otherArgs.length+",Usage: wordcount <in> <out>");
System.exit(2);//终止当前正在运行的java虚拟机
}
Job job = Job.getInstance(conf, "CleanUpJob");
job.setJarByClass(sy3.class);
job.setMapperClass(WsMapper.class);
job.setReducerClass(WsReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
for(int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length - 1]));
System.exit(job.waitForCompletion(true)?0:1);
}
}详细可参考厦门大学林子雨教授MapReduce编程实践
















 1395
1395











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











