






机器学习已经学了挺长一段时间了,虽然也会一点pytorch,但是调库始终感觉隔靴搔痒,对于一些基本的原理似懂非懂,所以今天手写一个简单的线性回归,尝试一下手写数据(而非批量生成),人工求导(而非自动微分),for循环计算(而非numpy矩阵乘),最后发现也并不难。
整个代码重点就一个,求(y_predict - y)**2对于w 和b的偏导数并用于更新w, b,感兴趣的同学可以手算看看,挺简单。
import matplotlib.pyplot as plt
import random
import math
x = [12.3, 14.3, 14.5, 14.8, 16.1, 16.8, 16.5, 15.3, 17.0, 17.8, 18.7, 20.2, 22.3, 19.3, 15.5, 16.7, 17.2, 18.3, 19.2,
17.3, 19.5, 19.7, 21.2, 23.04, 23.8, 24.6, 25.2, 25.7, 25.9, 26.3]
y = [11.8, 12.7, 13.0, 11.8, 14.3, 15.3, 13.5, 13.8, 14.0, 14.9, 15.7, 18.8, 20.1, 15.0, 14.5, 14.9, 14.8, 16.4, 17.0,
14.8, 15.6, 16.4, 19.0, 19.8, 20.0, 20.3, 21.9, 22.1, 22.4, 22.6]
def drawTheLine(w, b):
plt.scatter(x, y)
x_p = [x for x in range(int(max(x)))]
y_p = [w*x + b for x in range(int(max(x)))]
plt.plot(x_p, y_p)
plt.show()
#定义一个结构数据保存最优结果
class LocalBestParams():
def __init__(self, w, b, loss):
self.w = w
self.b = b
self.loss = loss
def updateParams(self, w, b, loss):
self.w = w
self.b = b
self.loss = loss
w = random.randint(0, int(max(y)//min(x)))
b = random.randint(0, int(max(y)))
batch_size = 2
lr = 0.001
epoch = len(x)//batch_size
print(f"len of x = {len(x)}")
for j in range(epoch):
loss_sum = 0
x_sum = 0
y_sum = 0
for k in range(batch_size):
i = j*batch_size + k
y_pred = w * x[i] + b
#get loss with mean square error
loss_sum += (y_pred - y[i]) ** 2
#loss_sum += math.sqrt((y_pred - y[i]) ** 2)
x_sum += x[i]
y_sum += y[i]
if (i == 0):
localBestParams = LocalBestParams(w, b, loss_sum)
#get mean data in each batch to decrease noise
loss_mean = loss_sum / batch_size
x_mean = x_sum / batch_size
y_mean = y_sum / batch_size
#save the local best parameters
if (loss_mean < localBestParams.loss):
localBestParams.updateParams(w, b, loss_mean)
print(f"epoch = {j} ")
print(f"y = {w}*x + {b} ")
print(f"loss_mean = {loss_mean}")
print(f" ")
drawTheLine(w, b)
#calculate the update value in each epoch
w_delta = 2*(w*x_mean + b -y_mean) * x_mean
b_delta = 2 * (w * x_mean + b - y_mean)
#update the parameters
w = w - lr*w_delta
b = b - lr*b_delta
print("train finished")
print(f"the best fit function is: y = {localBestParams.w} * x + {localBestParams.b}, its loss = {localBestParams.loss}" )代码运行起来后会弹出拟合直线与散点图,手动关掉后开始下一轮运行,方便观察每轮更新的效果。
以下是第一次运行的结果(随机初始值):
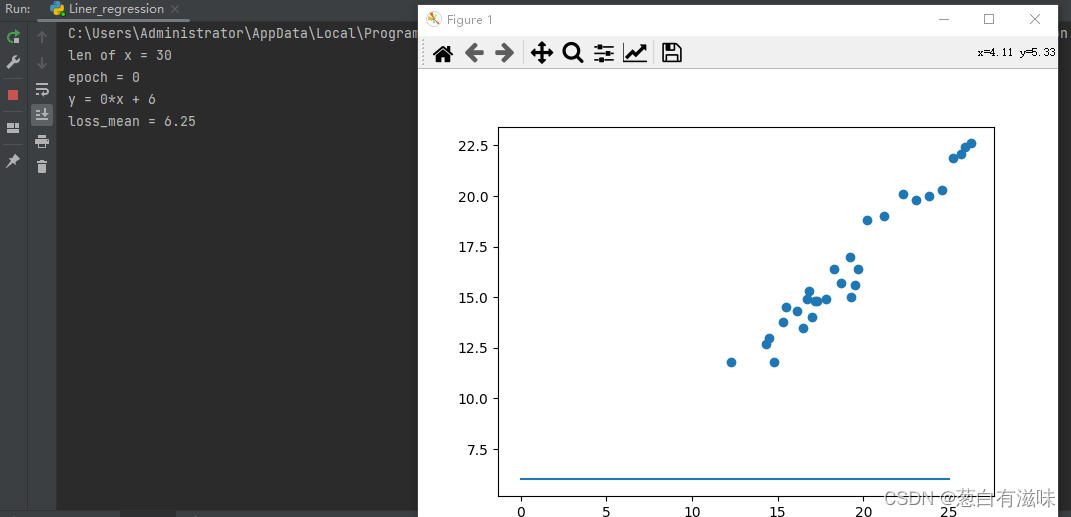
上面这个初始拟合直线数据的趋势几乎没什么关系。
以下是第8次运行结果(更新后的参数):
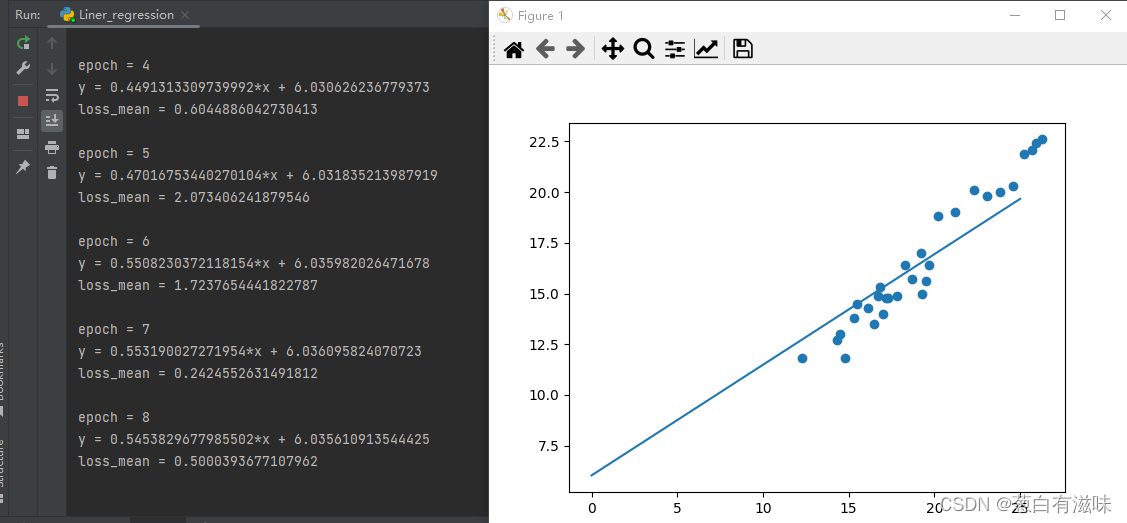
第八次运行结果已经可以看出趋势正在逐渐逼近,才更新参数8次就已经拟合得很好了(不过由于每次参数随机,看运气)。
最后最好的结果如下:
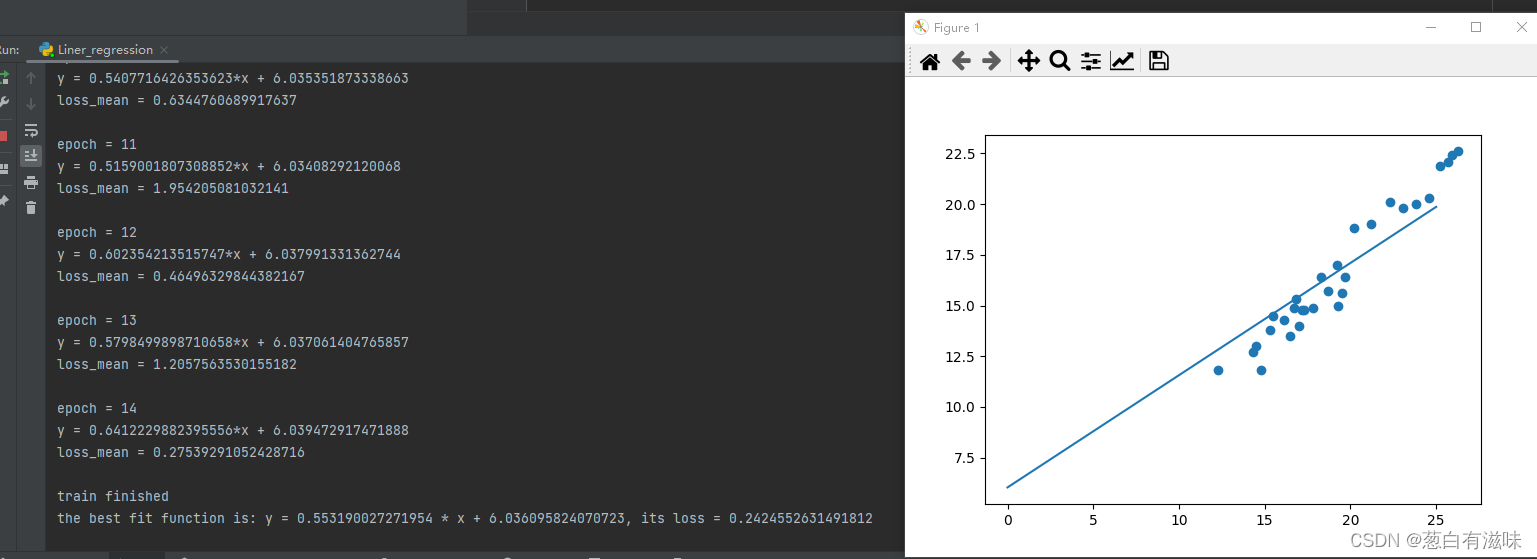
总结:
- 不依赖调库的线性回归实现起来并不难,只需要几十行代码,十几轮“训练”就能满足要求(当然也可以增加训练轮次以达到更好的效果)。
- 调试过程中实测将learn rate改成0.01会导致不收敛,由此可见超参数对结果的影响真的挺大,虽然不知道收敛和不收敛的边界值在哪,但超参数的设置还需要一些经验和参考才能保证得到较好的结果。















 711
711











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









