






awk
awk是一个强大的文本分析工具,相对于grep的查找,sed的编辑,awk在其对数据分析并生成报告时,显得尤为强大。简单来说awk就是把文件逐行的读入,以空格为默认分隔符将每行切片(把每一行的各个列分开,单独处理),切开的部分再进行各种分析处理。
语法:
awk [选项参数] 'awk script'var=value file(s)
或
awk [选项参数] -f scriptfile var=value file(s)
参数说明:
-F fs or --field-separator fs 指定输入文件折分隔符,fs是一个字符串或者是一个正则表达式,
如-F:。
-v var=value or --asign var=value 赋值一个用户定义变量。
-f scripfile or --file scriptfile 从脚本文件中读取awk命令。
变量:
NF: number filed 当前行分割后的字段个数。打印的时候,是取出最后一列
NR: number row 表示当前第几行
函数:
toupper():字符转为大写。
tolower():字符转为小写。
length():返回字符串⻓度。
substr():返回子字符串。
sin():正弦。
cos():余弦。
sqrt():平方根。
rand():随机数。
BEGIN语句/END语句
awk 'BEGIN{ commands } pattern{ commands } END{ commands }'BEGIN语句块 在awk开始从输入流中读取行 之前 被执行,这是一个可选的语句块,比如变量初始化、打印输出表格的表头等语句通常可以写在BEGIN语句块中。
END语句块 在awk从输入流中读取完所有的行 之后 即被执行,比如打印所有行的分析结果这类信息汇总都是在END语句块中完成,它也是一个可选语句块。
pattern语句块 中的通用命令是最重要的部分,它也是可选的。如果没有提供pattern语句块,则默认执行{ print },即打印每一个读取到的行,awk读取的每一行都会执行该语句块。
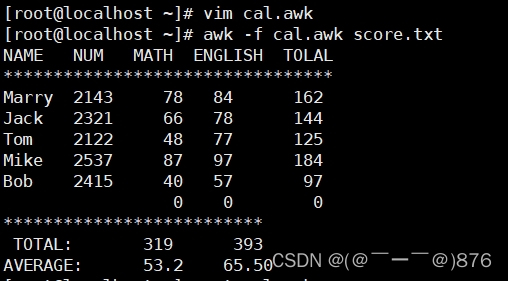
BEGIN {
math = 0
english = 0
computer = 0
printf "NAME NO. MATH ENGLISH COMPUTER TOTAL\n"
printf "---------------------------------------------\n"
}
#运行中
{
math+=$3
english+=$4
computer+=$5
printf "%-6s %-6s %4d %8d %8d %8d\n", $1, $2, $3,$4,$5, $3+$4+$5
}
#运行后END
{
printf "---------------------------------------------\n"
printf " TOTAL:%10d %8d %8d \n", math, english, computer
printf "AVERAGE:%10.2f %8.2f %8.2f\n", math/NR, english/NR, computer/NR
}结果:
grep
能使用正则表达式搜索文本,并把匹配的行打印出来。
命令的基本格式:
grep [option] pattern file对于这个命令我们经常使用的一个场景如下:
ps -ef|grep xxxxgrep 常用的参数:
-A<行数 x>:除了显示符合范本样式的那一列之外,并显示该行之后的 x 行内容。
-B<行数 x>:除了显示符合样式的那一行之外,并显示该行之前的 x 行内容。
-C<行数 x>:除了显示符合样式的那一行之外,并显示该行之前后的 x 行内容。
-c:统计匹配的行数
-e :实现多个选项间的逻辑or 关系
-E:扩展的正则表达式-f 文件名:从文件获取 PATTERN 匹配
-F :相当于fgrep-i --ignore-case #忽略字符大小写的差别。
-n:显示匹配的行号-o:仅显示匹配到的字符串
-q: 静默模式,不输出任何信息
-s:不显示错误信息。
-v:显示不被 pattern 匹配到的行,相当于[^] 反向匹配
-w :匹配 整个单词
grep egrep fgrep对比
grep可以使用基本正则表达式进行内容查找匹配
egrep可以使用扩展的正则表达式进行内容查找匹配
fgrep只能查找固定内容,无法使用正则进行匹配














 3846
3846











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









