







一、任务1:二维卷积实验
1.1 任务内容
-
任务具体要求
- 手写二维卷积的实现,并在至少一个数据集上进行实验,从训练时间、预测精度、Loss变化等角度分析实验结果(最好使用图表展示)(只用循环几轮即可)
- 使用torch.nn实现二维卷积,并在至少一个数据集上进行实验,从训练时间、预测精度、Loss变化等角度分析实验结果(最好使用图表展示)
- 不同超参数的对比分析(包括卷积层数、卷积核大小、batchsize、lr等)选其中至少1-2个进行分析
-
任务目的
- 手写二维卷积的实现: 通过手动编写二维卷积操作,深入理解卷积操作的数学原理和计算过程。通过分析训练时间、预测精度、Loss变化等角度的实验结果,深刻理解手动实现的卷积网络的性能表现
- 使用torch.nn实现二维卷积: 通过使用PyTorch中提供的torch.nn模块,学会如何更高效地构建和训练二维卷积神经网络。同样,分析训练时间、预测精度、Loss变化等指标,对比手动实现和PyTorch自带实现的性能差异
- 不同超参数的对比分析: 通过调整超参数,如卷积层数、卷积核大小、batchsize、学习率等,深入理解这些超参数对模型性能的影响
- 数据可视化: 使用图表展示实验结果,学会如何以直观的方式呈现数据,从而更好地理解和解释实验结果
-
任务算法或原理介绍
卷积网络的动机:稀疏交互、参数共享、平移不变性
-
卷积核: 卷积核是一个小的窗口或过滤器,它在输入图像上滑动以提取特征。每个卷积核包含可学习的权重参数,用于检测输入数据中的特定模式或特征。
-
权重共享: 卷积核的权重在整个输入图像上共享,这意味着相同的权重被用于不同位置的输入。这种权重共享有助于减少模型的参数数量,并使网络更具有对平移不变性(translation invariance)的特性。
-
滑动操作: 卷积核在输入图像上以固定的步幅(stride)进行滑动。每次滑动都会在输入上执行一次卷积操作,生成输出特征图。步幅决定了卷积核的移动间隔,影响输出特征图的大小。
-
边界处理: 在卷积操作时,通常会对输入图像的边界进行处理,以确保输出特征图的大小与预期相匹配。常见的边界处理方式包括零填充(zero-padding)和截断。
-
整个卷积过程可以用数学公式表示为:
输出 ( i , j ) = σ ( ∑ m ∑ n 输入 ( i + m , j + n ) ⋅ 卷积核 ( m , n ) + 偏置 ) \text{输出}(i, j) = \sigma\left(\sum_{m}\sum_{n} \text{输入}(i+m, j+n) \cdot \text{卷积核}(m, n) + \text{偏置}\right) 输出(i,j)=σ(m∑n∑输入(i+m,j+n)⋅卷积核(m,n)+偏置)
其中,σ 是激活函数,(i,j)是输出特征图上的位置坐标,(m,n) 是卷积核内的相对坐标,'偏置’是可学习的偏置参数。 -
卷积神经网络的一般框架为:卷积层(提取特征)+池化层(降维)+全连接层(输出结果)
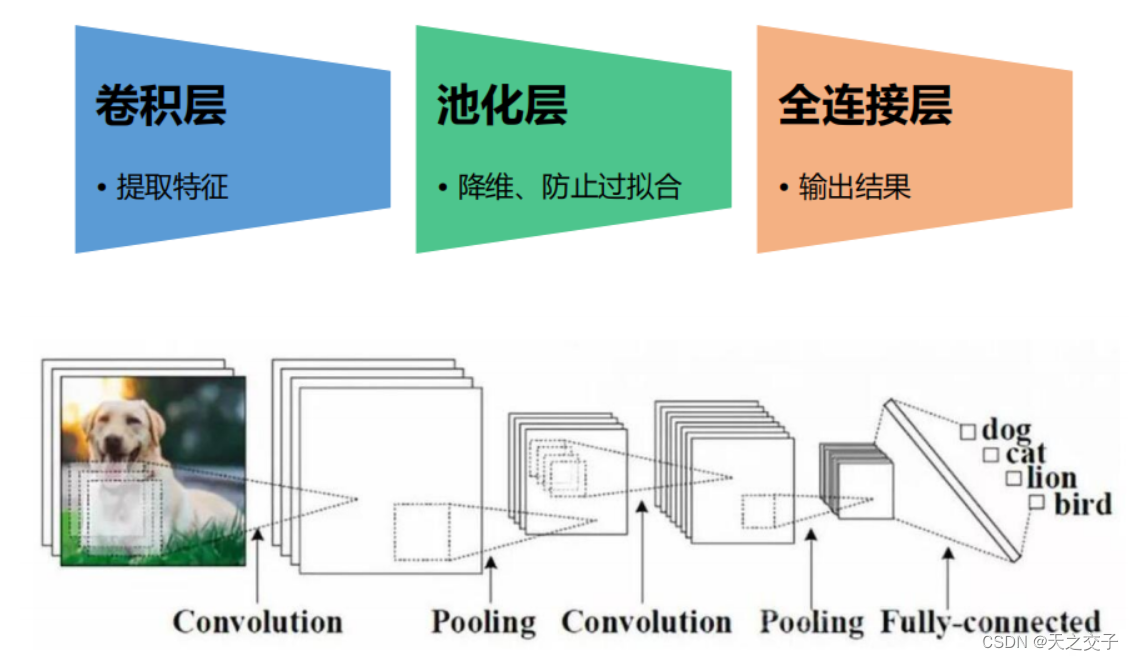
-
-
任务所用数据集
车辆分类数据集
1.2 任务思路及代码
-
数据预处理:
a. 使用 PyTorch 的 datasets.ImageFolder 读取图像数据,并对图像进行预处理(统一大小、转为 Tensor、归一化)
b. 随机划分训练集和测试集
-
可视化部分训练集图像:
a. 使用 torch.utils.data.random_split 随机划分训练集和测试集。
b. 定义 denorm 函数用于反归一化图像,以便可视化
c. 用 Matplotlib 可视化部分训练集图像
-
手动实现卷积模型:
a. 实现了三个函数:conv2d 用于单核单通道输入卷积,my_conv2d_multi_in 用于单核多通道输入卷积,my_conv2d_multi_in_out 用于多核多通道输入输出的卷积
b. 将这些函数封装成 MyConv2D 类,该类继承自 torch.nn.Module
c. 定义了整个卷积神经网络模型 MyConvModule,包含了一层卷积层和一个输出层。
-
使用 torch.nn 实现卷积模型:
使用 PyTorch 的 nn.Conv2d、nn.BatchNorm2d、nn.ReLU、nn.AvgPool2d、nn.Flatten 和 nn.Linear 等模块,构建了相似的卷积神经网络模型 model。
-
可视化训练过程:
使用 Matplotlib 绘制训练过程中的 Loss 曲线和 Accuracy 曲线,分别对手动实现的模型和使用 torch.nn 实现的模型进行可视化比较。
-
设置多种超参数对模型进行比较
读取数据集
说明: 由于在完整数据上用手动实现的二维卷积跑一轮需要大量时间,且该实验的重点在于二维卷积的实现不强调其效果,故将数据集总量从1358降低至400
为了与torch.nn实现对比,二者使用同一个缩减版数据集
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision import datasets,transforms
import matplotlib.pyplot as plt
import time
from sklearn.model_selection import train_test_split
# 设置随机种子以保持结果的一致性
torch.manual_seed(22)
plt.style.use('bmh') # 图表风格
class_name=["bus","car","truck"] #车辆类别
transform=transforms.Compose(
[transforms.Resize((64,64)), # 大小不一致,拉伸为统一尺寸
transforms.ToTensor(), # 转为tensor
transforms.Normalize([0.5,0.5,0.5],[0.5,0.5,0.5])]
)
data = datasets.ImageFolder("./car_dataset",transform=transform)
# 随机划分训练集和测试集
train_size = int(0.8 * len(data))
test_size = len(data) - train_size
train_dataset, test_dataset = torch.utils.data.random_split(data, [train_size, test_size])
# 缩小数据集
train_dataset = torch.utils.data.Subset(train_dataset, range(320))
test_dataset = torch.utils.data.Subset(test_dataset, range(80))
训练数据可视化
# 反归一化
def denorm(img):
for i in range(img.shape[0]):
img[i] = img[i] * 0.5 + 0.5
return img
plt.figure(figsize=(8, 8))
for i in range(9):
img, label = train_dataset[torch.randint(0, len(train_dataset),(1,))]
img = denorm(img)
img = img.permute(1, 2, 0) # 维度交换
ax = plt.subplot(3, 3, i + 1)
ax.imshow(img.numpy())
ax.set_title("label = %s" % class_name[label])
ax.axis('off')
plt.tight_layout()
plt.show()

手动实现
BATCH_SIZE = 16
LR = 0.01
EPOCH = 5
# GPU训练设置
device = torch.device("cuda:0")
# 单核单通道输入卷积
def conv2d(X, K):
batch_size, H, W = X.shape
k_h, k_w = K.shape #
#初始化结果矩阵
Y = torch.zeros((batch_size,H - k_h + 1,W - k_w + 1)).to(device)
for i in range(Y.shape[1]):
for j in range(Y.shape[2]):
Y[:, i, j] = (X[:, i: i + k_h, j:j + k_w] * K).sum(dim=2).sum(dim=1) # 不能直接sum
return Y
# 单核多通道输入卷积
def my_conv2d_multi_in(X, K):
res = conv2d(X[:, 0, :, :], K[0, :, :]) # 通过第0通道卷积初始化结果矩阵
for i in range(1, X.shape[1]):
res += conv2d(X[:, i, :, :], K[i, :, :])
return res
# 多核多通道输入输出的卷积
def my_conv2d_multi_in_out(X, K):
return torch.stack([my_conv2d_multi_in(X, k) for k in K], dim=1)
# 封装成卷积层
class MyConv2D(torch.nn.Module):
def __init__(self, in_channels, out_channels, kernel_size):
super(MyConv2D, self).__init__()
# 初始化卷积核和偏置
if isinstance(kernel_size, int):
kernel_size = (kernel_size, kernel_size)
self.weight = torch.nn.Parameter(torch.randn((out_channels, in_channels) + kernel_size))
self.bias = torch.nn.Parameter(torch.randn(out_channels, 1, 1))
def forward(self, X):
# X: (batch_size, C_in, H, W)
return my_conv2d_multi_in_out(X, self.weight) + self.bias
# 构建神经网络
class MyConvModule(torch.nn.Module):
def __init__(self):
super(MyConvModule, self).__init__()
# 一层卷积层
self.conv = torch.nn.Sequential(
MyConv2D(in_channels=3, out_channels=32, kernel_size=3),
torch.nn.BatchNorm2d(32),
torch.nn.ReLU(inplace=True),
)
# 输出层,通道数变为分类数量
self.fc = torch.nn.Linear(32, 3)
def forward(self, X):
# 经过卷积后输出维度:(batch_size, C_out, H_out, W_out)
output = self.conv(X)
# 使用平均池化变成1*1
output = torch.nn.functional.avg_pool2d(output, 62)
# batch_size*out_channel*1*1变成batch_size*out_channel
output = output.squeeze()
# 输入到全连接层
output = self.fc(output)
return output
# 初始化评估指标
train_losses, test_losses, train_accuracys,test_accuracys = [], [], [], []
net = MyConvModule()
net.to(device)
# 交叉熵损失
criterion=nn.CrossEntropyLoss()
criterion.to(device)
optimizer = optim.Adam(net.parameters(),lr=LR)
# 构造训练集和测试集迭代器
train_loader = DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=BATCH_SIZE, shuffle=False)
plt.ion()
begin = time.time()
for epoch in range(EPOCH):
total_train_loss, total_train_acc = 0.0, 0.0
for x, y in train_loader:
x, y = x.to(device), y.to(device)
pre = net.forward(x)
loss = criterion(pre, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_loss += loss.item()
total_train_acc += (pre.argmax(dim=1)==y).float().mean().item()
train_losses.append(total_train_loss / len(train_loader))
train_accuracys.append(total_train_acc/ len(train_loader))
# 测试模型
total_test_loss,total_test_acc = 0.0, 0.0
with torch.no_grad():
for x, y in test_loader:
x, y = x.to(device), y.to(device)
pre = net.forward(x)
loss = criterion(pre, y)
total_test_acc += (pre.argmax(dim=1)==y).float().mean().item()
total_test_loss += loss.item()
test_losses.append(total_test_loss / len(test_loader))
test_accuracys.append(total_test_acc/len(test_loader))


1.3 实验结果分析
1.3.1 实验结果分析1
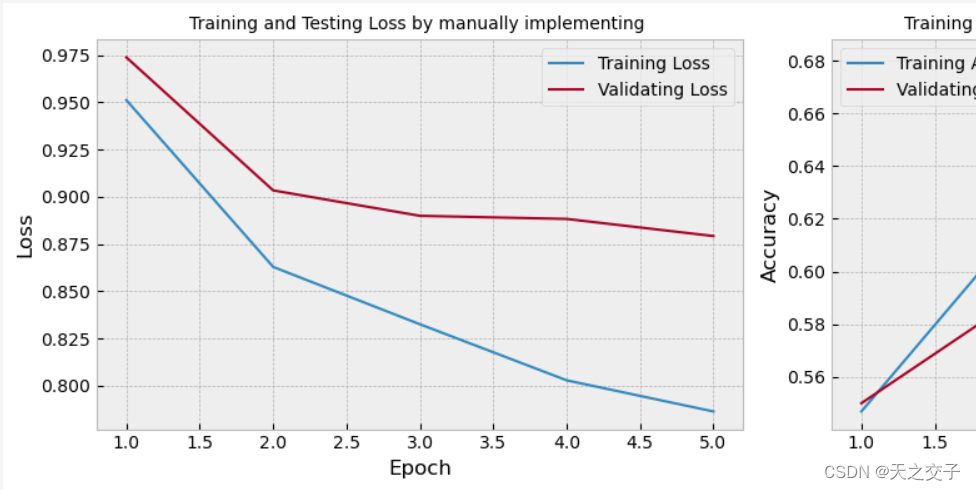
根据实验结果,从以下几个角度对实验结果进行分析:
-
训练时间:
训练时间超长,一轮需要将近1小时,一共五轮共耗费249min
分析原因:卷积操作使用for循环实现,而不是矩阵操作(img2col算法)
-
预测精度:
在训练集上,模型的准确性从第一轮到最后一轮逐渐增加,从0.546875提高到0.681250
在测试集上,模型的准确性也有所提高,从0.550000提高到0.637500
由于训练轮数小,故准确度不高
-
Loss变化:
训练集和测试集上的损失值(Loss)逐渐减小,表明模型在学习过程中逐渐收敛
随着训练轮次的增加,损失值的减小趋势表明模型在学习中逐渐提高对数据的拟合能力
torch.nn实现二维卷积
model = nn.Sequential(
nn.Conv2d(in_channels = 3,out_channels = 32, kernel_size = 3),
nn.BatchNorm2d(32),
nn.ReLU(inplace=True),
nn.AvgPool2d(kernel_size=62),
nn.Flatten(),
nn.Linear(32,3)
)
model = model.to(device)
optimizer = optim.Adam(model.parameters(),lr=LR)
# 交叉熵损失
criterion=nn.CrossEntropyLoss()
criterion.to(device)
# 初始化评估指标
train_losses, test_losses, train_accuracys,test_accuracys = [], [], [], []
plt.ion()
begin = time.time()
for epoch in range(EPOCH):
total_train_loss, total_train_acc = 0.0, 0.0
for x, y in train_loader:
x, y = x.to(device), y.to(device)
pre = model(x)
loss = criterion(pre, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_loss += loss.item()
total_train_acc += (pre.argmax(dim=1)==y).float().mean().item()
train_losses.append(total_train_loss / len(train_loader))
train_accuracys.append(total_train_acc/ len(train_loader))
# 测试模型
total_test_loss,total_test_acc = 0.0, 0.0
with torch.no_grad():
for x, y in test_loader:
x, y = x.to(device), y.to(device)
pre = model(x)
loss = criterion(pre, y)
total_test_acc += (pre.argmax(dim=1)==y).float().mean().item()
total_test_loss += loss.item()
test_losses.append(total_test_loss / len(test_loader))
test_accuracys.append(total_test_acc/len(test_loader))
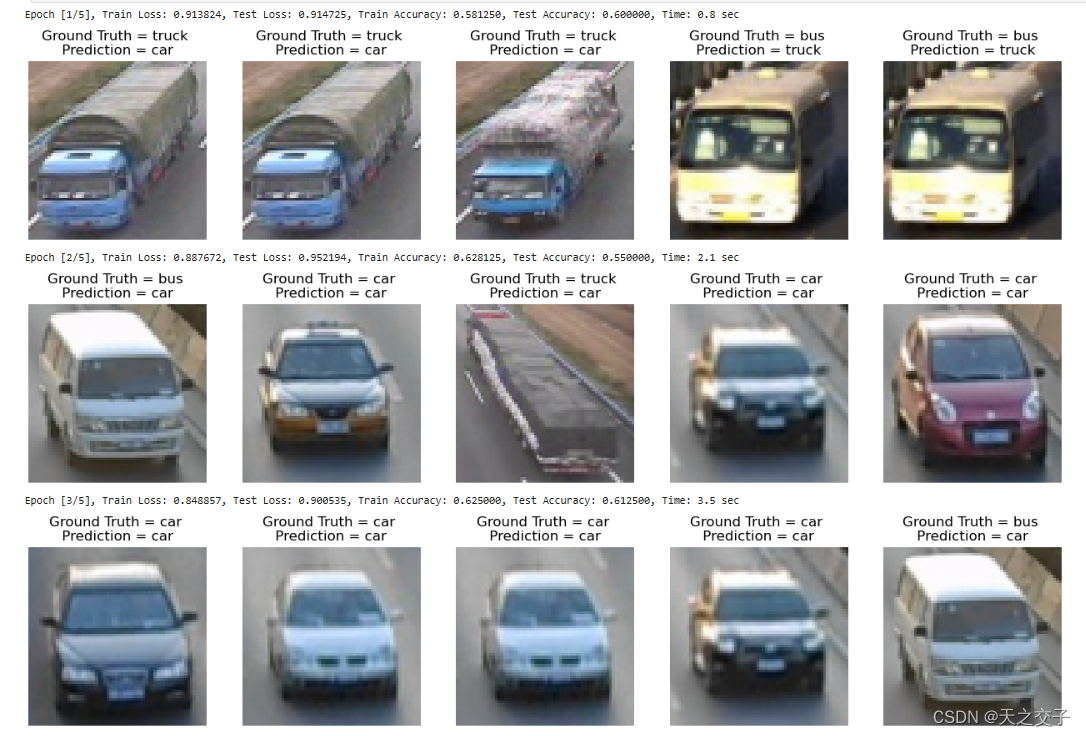

1.3.2 实验结果分析2
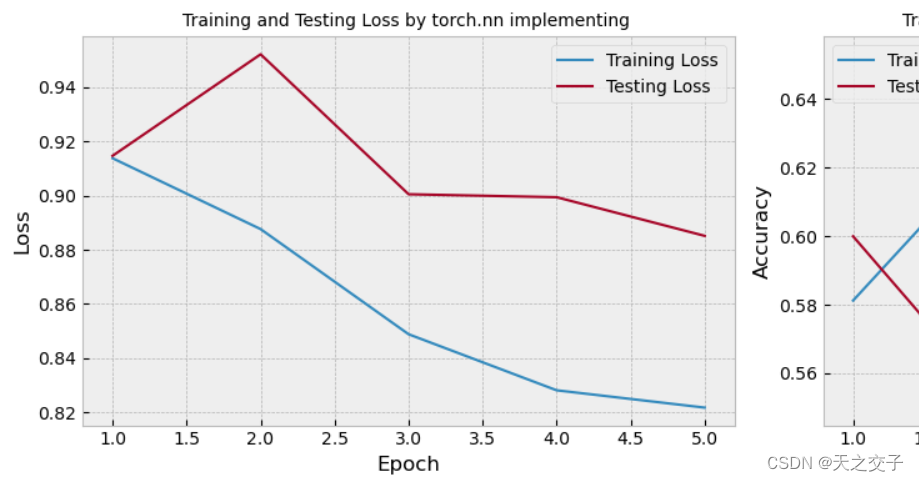
根据实验结果,从以下几个角度对实验结果进行分析:
-
训练时间:
torch.nn 实现的二维卷积训练时间相对较短,每轮的时间大约1s,明显低于手动实现
这可能是由于 PyTorch 内置的卷积操作优化较好,底层由 C++ 实现,更高效
-
预测精度:
在测试集上,torch.nn 实现的卷积模型在准确性上的表现与手动实现相当,这表明 PyTorch 提供的卷积层在学习任务上与手动实现相比,没有明显的性能差异
-
Loss变化:
训练集和测试集上的损失值在每个 epoch 中逐渐减小,与手动实现的趋势相似
PyTorch 内置的卷积层有效地优化了模型参数,使其更好地适应训练数据
不同超参数对比实验
数据准备
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision import datasets,transforms
import matplotlib.pyplot as plt
import time
from sklearn.model_selection import train_test_split
# 设置随机种子以保持结果的一致性
torch.manual_seed(23)
# GPU训练设置
device = torch.device("cuda:0")
plt.style.use('bmh') # 图表风格
# 超参数
EPOCH = 100
INPUT_DIM = 3
class_name=["bus","car","truck"] #车辆类别
transform=transforms.Compose(
[transforms.Resize((64,64)), # 大小不一致,拉伸为统一尺寸
transforms.ToTensor(), # 转为tensor
transforms.Normalize([0.5,0.5,0.5],[0.5,0.5,0.5])]
)
data = datasets.ImageFolder("./car_dataset",transform=transform)
# 随机划分训练集和测试集
train_size = int(0.8 * len(data))
test_size = len(data) - train_size
train_dataset, test_dataset = torch.utils.data.random_split(data, [train_size, test_size])
模型搭建和训练测试过程封装
# 图片反归一化,用于可视化
def denorm(img):
for i in range(img.shape[0]):
img[i] = img[i] * 0.5 + 0.5
return img
class MyConvNet(nn.Module):
def __init__(self, conv_layers,kernel_size,batch_size,lr):
super().__init__()
hiddens=[]
for i in range(len(conv_layers)):
if i == 0:
hiddens.append(nn.Conv2d(in_channels = INPUT_DIM, out_channels = conv_layers[i], kernel_size = kernel_size))
hiddens.append(nn.BatchNorm2d(conv_layers[i]))
hiddens.append(nn.ReLU(inplace=True))
else:
hiddens.append(nn.Conv2d(in_channels = conv_layers[i-1], out_channels = conv_layers[i], kernel_size = kernel_size))
hiddens.append(nn.BatchNorm2d(conv_layers[i]))
hiddens.append(nn.ReLU(inplace=True))
self.convs = nn.Sequential(*hiddens)
self.fc = nn.Sequential(
nn.AvgPool2d(kernel_size = 64 - (kernel_size -1)*len(conv_layers)), # 池化层
nn.Flatten(), #展平
nn.Linear(conv_layers[-1], 3)
)
## 模型超参数
self.conv_layers = conv_layers
self.kernel_size = kernel_size
self.batch_size = batch_size
self.lr = lr
def forward(self, x):
x = self.convs(x)
x = self.fc(x)
return x
# 交叉熵损失
criterion=nn.CrossEntropyLoss()
criterion.to(device)
# 定义训练函数
def train_and_test(model):
代码实在是太多了,具体代码见:https://www.jdmm.cc/file/2710170/
















 2711
2711











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











