







下面代码是想将一个含有string类型的struct类型,写入二进制文件中,并将其从二进制文件中读取出来输出
#include<iostream>
#include<fstream>
#include<string>
using namespace std;
struct student
{
int number;
string name;
};
int main()
{
student stu;
cin >> stu.number >> stu.name;
ofstream ofile("CString.dat", ios::out | ios::binary);;
ofile.write((char*)(&stu), sizeof(stu));
ofile.close();
ifstream ifile("CString.dat", ios::in | ios::binary);
student stu1;
ifile.read((char*)(&stu1), sizeof(stu1));
ifile.close();
cout << stu1.number << endl << stu1.name << endl;
return 0;
}但上述代码会触发断点:
0x00D28C4B 处(位于 try.exe 中)引发的异常: 0xC0000005: 写入位置 0xDDDDDDDD 时发生访问冲突。
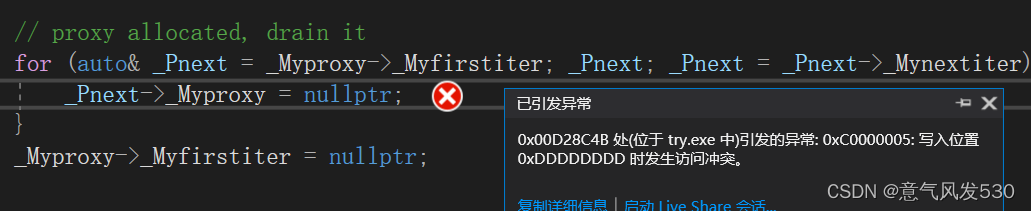
触发断点的位置:使用read函数,读取二进制文件时
以下为我的看法:
二进制文件是以字节为单位进行读写文件的。而对于string类型,其所占的字节数为28个。
对于二进制文件的读写函数中均有sizeof(需要读或写入的数据类型)作为参数。
当将stu的数据输出到二进制文件中,是正常的(比如编译器知道碰到'\0'时,该string类型的数据就输出完毕了)
但是到了读取数据进入stu1中时就出问题了!!!
ifstream ifile("CString.dat", ios::in | ios::binary);
student stu1;
ifile.read((char*)(&stu1), sizeof(stu1));
ifile.close();因为这里传进去ifile.read的参数为sizeof(stu1),sizeof(stu1)值固定为32个字节(整型4+字符串类型28),而实际上string类型中存储数据的字节数有可能大于28也有可能小于28个字节(string类通过char类型指针实现)。
读取时以字节为单位,那么编译器就不知道应该在该二进制文件中读取多少个字节的数据放到stu1中。(这里有可能是读取了32个字节的数据,但实际上写入的数据并没有这么大,导致读指针读取到了没有写入数据的位置,导致读写异常)。
实际上在二进制文件中,写入通过指针指向的数据(write函数中参数写sizeof(该指针) 时),在读取数据时都会触发该异常。
解决方法:
将结构体中的string类型改为一个恰当大小的字符数组
假如是对文本文件进行上述操作呢
#include<iostream>
#include<fstream>
#include<string>
using namespace std;
struct student
{
int number;
string name;
};
int main()
{
ofstream ofile("CString.txt", ios::out);
student stu;
cin >> stu.number >> stu.name;
ofile << stu.number << stu.name;
cin >> stu.number >> stu.name;
ofile << stu.number << stu.name;
ofile.close();
ifstream ifile("CString.txt", ios::in);
student stu1, stu2;
stu2.name = "没有数据";
stu2.number = 0;
ifile >> stu1.number >> stu1.name;
ifile >> stu2.number >> stu2.name;
ifile.close();
cout << stu1.number << endl << stu1.name << endl;
cout << stu2.number << endl << stu2.name << endl;
return 0;
}答案是:不会引发异常
因为对于文本文件,在写入文件时是将每个字符先转换为ASCII码(每个ASCII码占一个字节),再写入文件中。
但是在读取文件时,对于读入一个string类型数据,会将从其开始读取string类型数据位置开始(上一个数据读取完的末尾),一直读取到文件末尾。其余的数据类型则无法读到数据。(如上述的stu2的name,number)
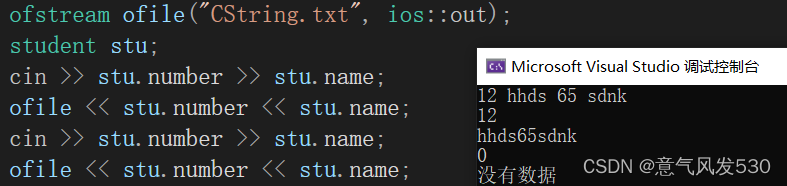
总的来说:
在进行写文件和读文件时就尽量不要使用string类型数据,尽量使用一个合适大小的字符数组
个人看法和理解,如果有误,望指出啊!!!
如果有其他看法,欢迎一同交流啊!!!















 1773
1773











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









