







活动地址:CSDN21天学习挑战赛
一、爬虫提取网页数据的流程图

图源:100天精通Python(爬虫篇)——第45天:lxml库与Xpath提取网页数据_无 羡ღ的博客-CSDN博客_python爬取网页内容
二、lxml库
lxml是XML和HTML的解析器,其主要功能是解析和提取XML和HTML中的数据,是一款高性能的Python HTML、XML解析器,也可以利用Xpath语法,来定位特定的元素及节点信息。
1、下载
cmd 中 输入 pip install lxml
2、解析HTML网页
主要用到lxml库中的etree类
案例1:
from lxml import etree
text = '''
<html><body>
<div class="key">
<div class="name">小浪</div>
<div class="age">23</div>
<div class="address">山东</div>
</div>
</body></html>
'''
#开始初始化
html = etree.HTML(text) #这需要传入一个html形式的字符串
print(html) #输出:<Element html at 0x1f77f541600>
print(type(html)) #输出:<class 'lxml.etree._Element'>
#将字符串序列化为html字符串
result = etree.tostring(html).decode('utf-8')
print(result)
# 输出:
# <html><body>
# <div class="key">
# <div class="name">小浪</div>
# <div class="age">23</div>
# <div class="address">山东</div>
# </div>
# </body></html>
print(type(result)) #输出:<class 'str'>三、XPath
Xpath(XML Path Language)是一们在XML文档中查找信息的语言,可以用来在XML文档中对元素和属性进行遍历。
常用路径表达式
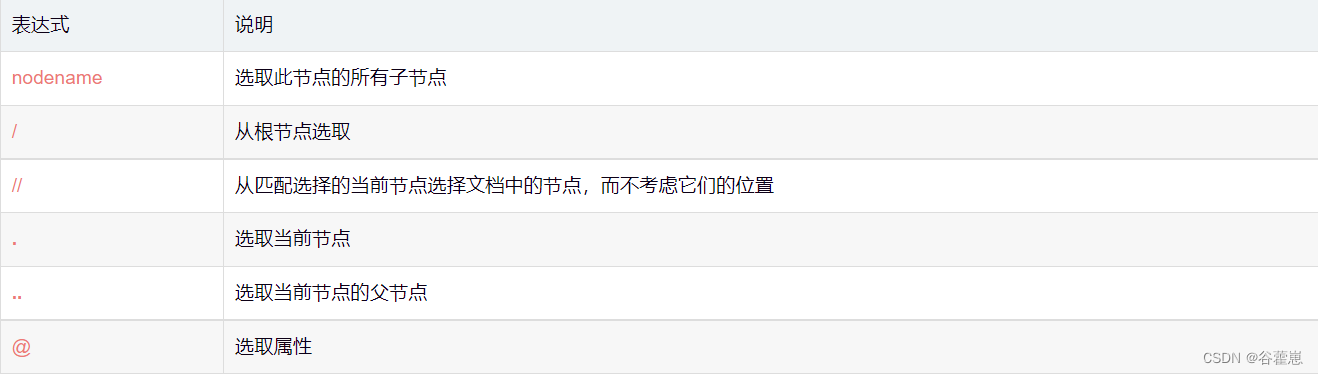
用法举例:
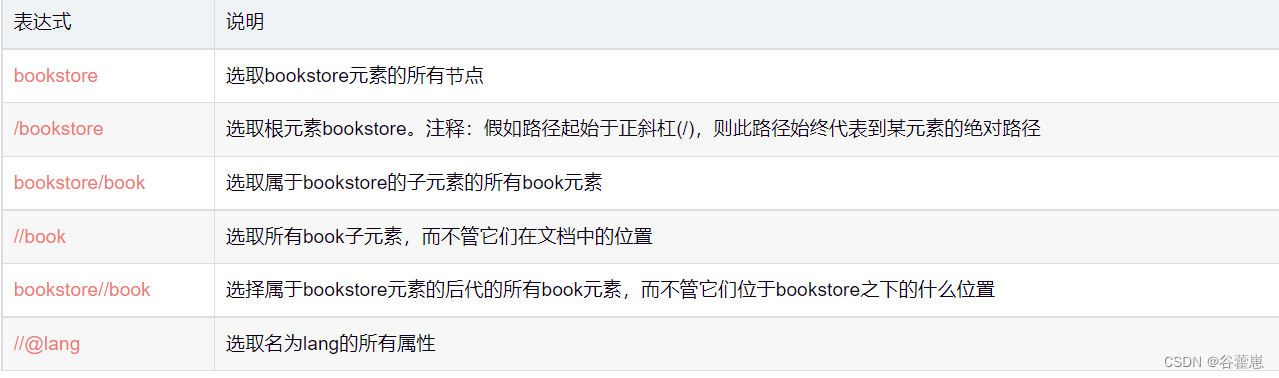
谓语
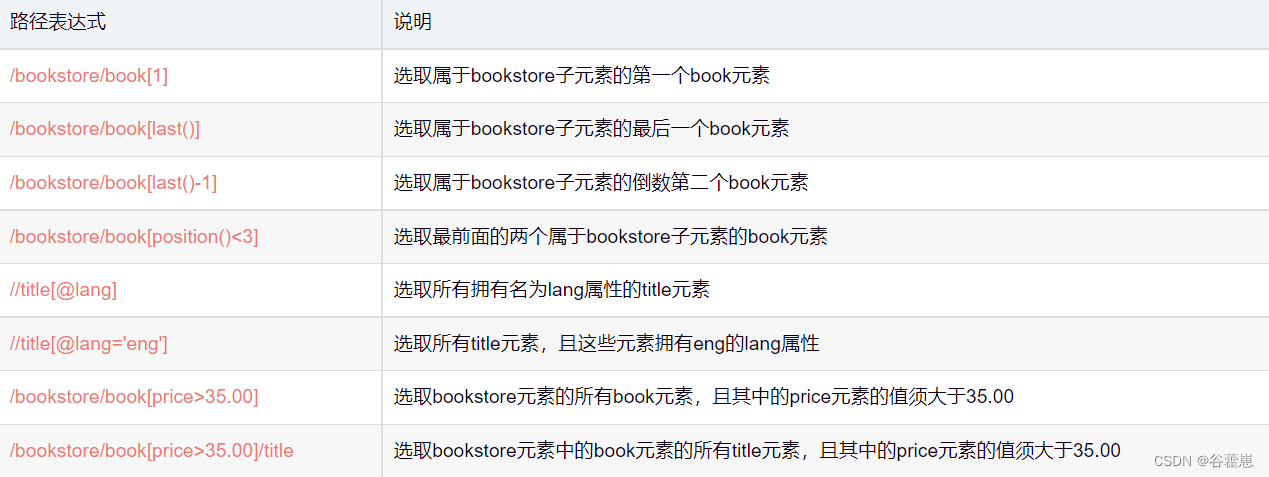
选取未知节点

案例:
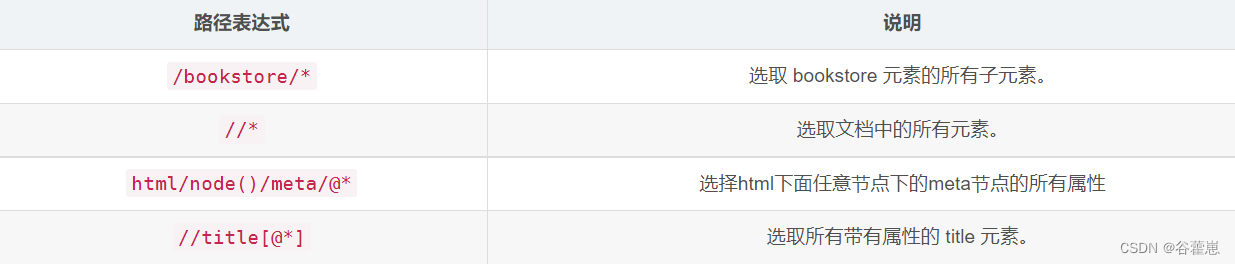
选取若干路径
四、Xpath实战
Chrome浏览器自带 Xpath Hepler可以很方便的获取标签路径。
1、新建一个test.html文件,且包括以下内容:
<!-- test.html -->
<div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>2、获取操作
获取所有的"li标签"
from lxml import etree
html = etree.parse('test.html')
#输出etree.parse()返回的数据类型
print(type(html)) #输出:<class 'lxml.etree._ElementTree'>
result = html.xpath('//li')
#打印<li>标签的元素集合
print(result) #输出:[<Element li at 0x29ca2316c40>, <Element li at 0x29c93295a80>, <Element li at 0x29c932958c0>, <Element li at 0x29c932957c0>, <Element li at 0x29c9314fd80>]
print(len(result)) #输出:5
print(type(result)) #输出:<class 'list'>
print(type(result[0])) #输出:<class 'lxml.etree._Element'>获取“li标签”的所有class属性
from lxml import etree
html = etree.parse('test.html')
result = html.xpath('//li/@class')
print(result)#输出:['item-0', 'item-1', 'item-inactive', 'item-1', 'item-0']获取“li标签”下的hre为link1.html的“a标签”
from lxml import etree
html = etree.parse('test.html')
result = html.xpath('//li/a[@href="link1.html"]')
print(result)#输出:[<Element a at 0x26b4825df00>]获取“li标签”下的所有“span标签”
from lxml import etree
html = etree.parse('test.html')
# result = html.xpath('//li/span')
# 注意:这么写是不对的
# 因为/用来获取子元素,而<span>不是<li>的子元素,所以用双斜杠
result = html.xpath('//li//span')
print(result)#输出:[<Element span at 0x1f71a379280>]获取“li标签”下的“a标签”里的所有class属性
from lxml import etree
html = etree.parse('test.html')
result = html.xpath('//li/a//@class')
print(result)#输出:['bold']获取最后一个“li标签”的“a标签”中的href属性
from lxml import etree
html = etree.parse('test.html')
result = html.xpath('//li[last()]/a/@href')
print(result)#输出:['link5.html']获取倒数第二个元素的内容
from lxml import etree
html = etree.parse('test.html')
result = html.xpath('//li[last()-1]/a')
print(result[0].text)#输出:fourth item获取class值为bold的标签名
from lxml import etree
html = etree.parse('test.html')
result = html.xpath('//*[@class="bold"]')
#tag方法可以获取标签名
print(result[0].tag)#输出:span














 249
249











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









