






1.什么是存储引擎?
数据库搜索引擎是数据库底层的软件组织,数据库管理系统使用数据引擎更新数据,使用不同的存储引擎提供不同的存储集中,MySQL的存储核心就是插件式存储引擎。像出门的Oracle、SQL Server等数据库只有一张存储引擎,MySQL存在多种。
查看存储引擎:
show engines;
当然,我们也可以查看当前默认使用什么存储引擎:
show variables like "%storage_engine%";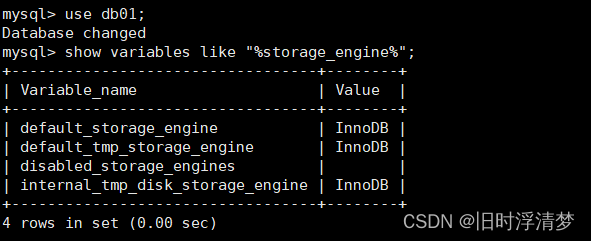
可以查看,也可以修改,可以在建表的时候指定存储引擎,也可以建好表之后指定:
alter table class engine=myisam;
2.InnoDB存储引擎
1.特点:
- 支持事务的ACID(开启事务,回滚事务等等)
- 支持外键
- 锁粒度,支持行锁、表锁(默认表锁)
- 存储形式: .frm 表定义文件 .ibd 数据文件和索引文件
2.索引
聚集索引:以主键创建的索引,一个表只有一个主键,也就只有一个索引。
聚集索引的B+Tree上节点存储的是整行的数据,而非聚焦索引上存储的是当前搜索值的数据和id.
例如:
select * from user where age=1;在聚集索引时:存储的是age为1的那一整行数据;
在非聚集索引时:存储的是age的数据,和当前的id值。当执行sql语句时,先去索引树查找主键,在通过主键查找整行数据。
3.MyISAM存储引擎
1.特点:
- 锁粒度,支持表锁,操作一条数据是会锁住整张锁
- 存储形式: .frm 表定义文件 .myd 数据⽂件 .myi 索引⽂件
- 访问速度快,支持读多写少
2.索引
非聚集索引:除了聚集索引外其他全是聚集索引。
3.存储格式:
- 静态表:表中字段都不不可变的,例如char(),已经给你分配好20个长度了,varchar(255)这个是可变长度。缺点是:占用空间比动态表多。
- 动态表:字段长度可变,
- 压缩表 :可以压缩表中数据,照样可以访问,占用空间小。
4.Merge存储引擎
特点是:将一系列等同的MyISAM表以逻辑的组合方式组合在一起,表的结构一定要相同,Merge表本身是没有数据的。
create table user_01(
id int,
username varchar(10)
) engine = myisam default charset=utf8;
create table user_02(
id int,
username varchar(10)
) engine = myisam default charset=utf8;
create table user_all(
id int,
username varchar(10)
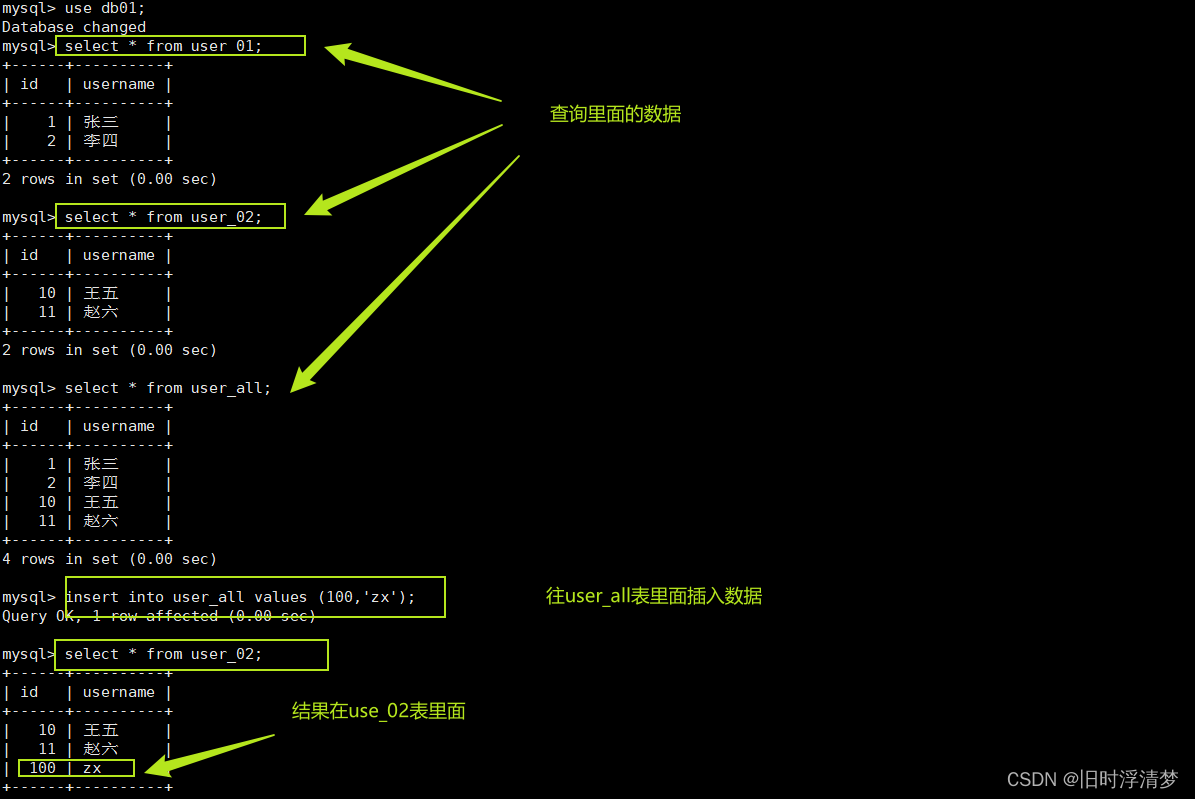
) engine=merge union = (user_01,user_02) INSERT_METHOD=LAST default charset=utf8;现在往表里插入数据
insert into user_01 values(1,'张三');
insert into user_01 values(2,'李四');
insert into user_02 values(10,'王五');
insert into user_02 values(11,'赵六');
测试一下
create table user_03(
id int,
username varchar(10)
) engine = myisam default charset=utf8;
insert into user_03 values(1,'小蓝');
insert into user_03 values(2,'小明');
修改一下user_all表
alter table user_all union = (user_01,user_02,user_03); 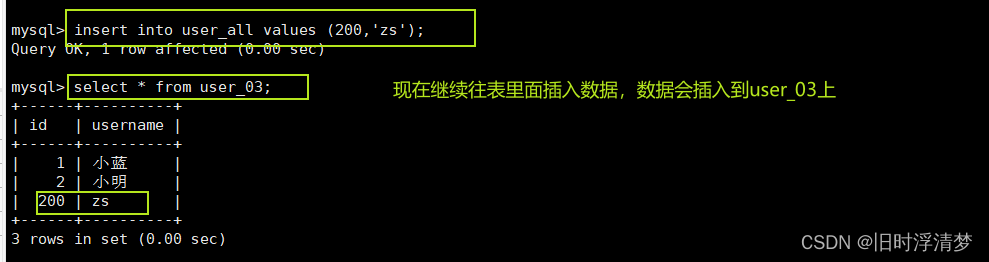
5.索引
相信大家对索引不陌生,在InnoDB引擎中,每个表都会有主键,都会有索引,那它到底是嘛呢?
它底层是一种数据结构,是用来优化数据库性能的常用工具。
用数据结构来划分:
B-Tree:常见的索引,B+Tree基于此做的优化;
hsah:基于哈希表实现的,里面的hash值做过优化,绝对不可能重复;
1.B-Tree:
又叫多路平衡搜索树:所有的叶子节点都要在同一层;
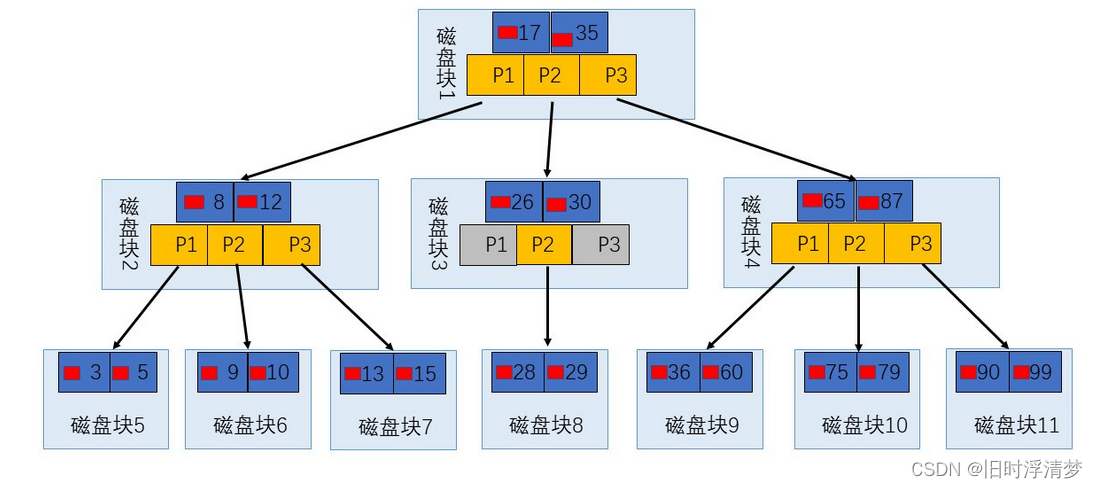
2.B+Tree:
基于B-Tree的基础上,移除了非叶子节点的data,即数据地址值,将这些数据全部移到叶子节点上,而且还给叶子节点增加了双向链表。(两个不同的特性)
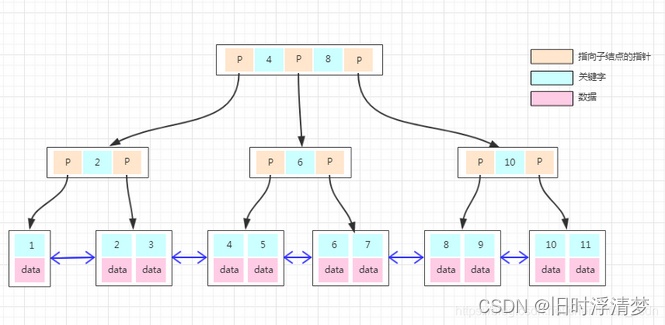
聚集索引和非聚集索引:聚集索引只有InnoDB才有,而且存储的时候叶子节点存储整行数据。非聚集节点存储的时候存储搜索值和id。
3.前缀索引
顾名思义,根据前缀来查找,这里提到一个词:离散性
离散性越高,数据重复率越低,不重复率越高;
计算不重复率公式: 去重后的数据 / 总的数据
我们这里准备一些数据
CREATE TABLE `student` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(20) DEFAULT NULL,
`birthday` varchar(20) DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB ;
-- ----------------------------
-- Records of student
-- ----------------------------
INSERT INTO `student` VALUES (1, '⼩明', '1999-10-20');
INSERT INTO `student` VALUES (2, '⼩军', '1999-02-21');
INSERT INTO `student` VALUES (3, '⼩⻰', '1999-01-19');
INSERT INTO `student` VALUES (4, '⼩刚', '1999-06-06');
INSERT INTO `student` VALUES (5, '⼩红', '1999-02-05');截取前七个的不重复率
-- 只查询birthday这⼀列
select birthday from student
-- 只查询birthday列左边num个字符
select left(birthday,7) from student
-- 在列的最左边去除num个字符后去重后,查询记录
select distinct left(birthday,num) from student;
-- 在列的最左边去除num个字符后去重后,统计总条数
select 1.0*count(distinct left(birthday,num)) from student;
-- 将去重后的数据的总条数 / 表中的总条数 = 不重复率
select 1.0*count(distinct left(birthday,num))/count(*) from student;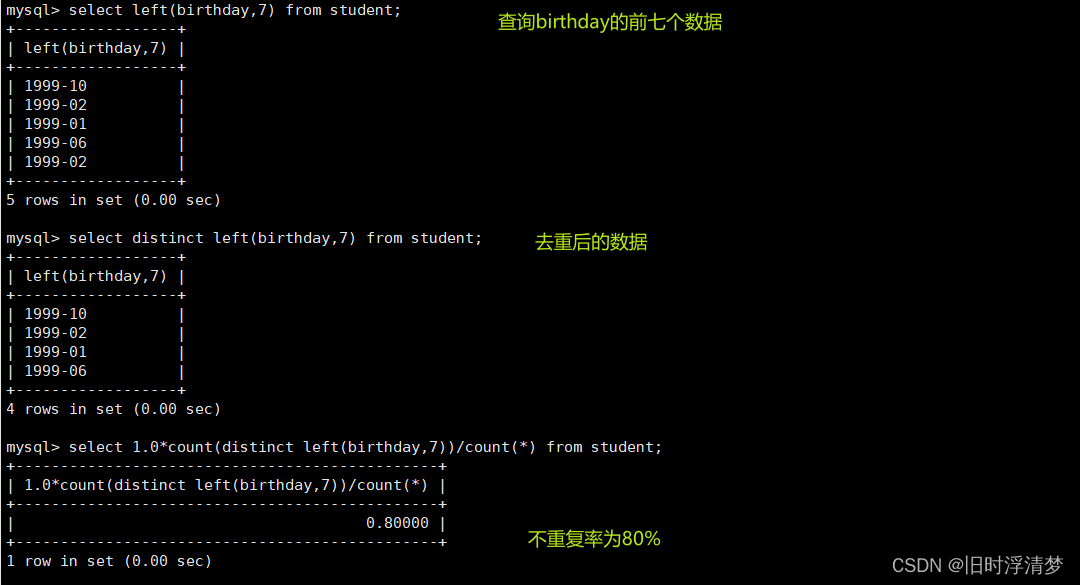
我们来截取九个试一下
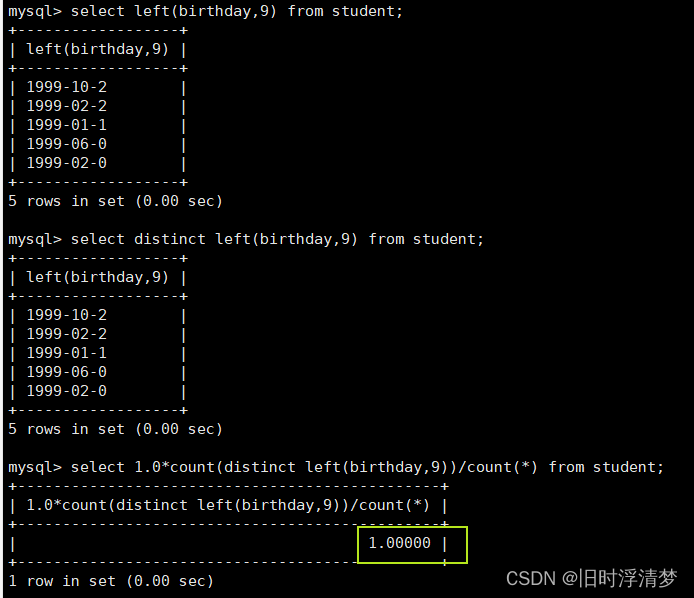
不重复率高达100%啊,这不就是我们想要的结果嘛!
4.全文索引
如果希望通过关键字来查询过滤,而不是精确查找时,就可以使用全文索引。
数据表数据
create table test (
id int(11) not null auto_increment,
content varchar(30) not null,
PRIMARY KEY (`id`) USING BTREE,
FULLTEXT INDEX (`content`)
) engine=myisam default charset=utf8;
insert into test(content) values('a'),('aa'),('aaa'),('aaaa');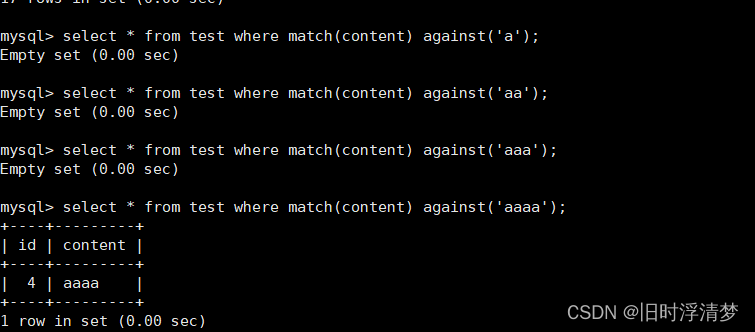
全文索引有两种模式:
1.自然语言处理模式
2.布尔模式
CREATE TABLE `article` (
`id` int(11) NOT NULL,
`title` varchar(255) ,
PRIMARY KEY (`id`) USING BTREE,
FULLTEXT INDEX `title`(`title`) with parser ngram -- 使⽤ngram中⽂
) ENGINE = InnoDB ;
INSERT INTO `article`(`id`, `title`) VALUES (1, '华为5G智能游戏手机');
INSERT INTO `article`(`id`, `title`) VALUES (2, '苹果5G全屏拍照手机');
INSERT INTO `article`(`id`, `title`) VALUES (3, 'vivo美颜拍照手机');
INSERT INTO `article`(`id`, `title`) VALUES (4, '新款oppo性能音乐乐拍照全网通');select * from goods where match(title) against('⼿机');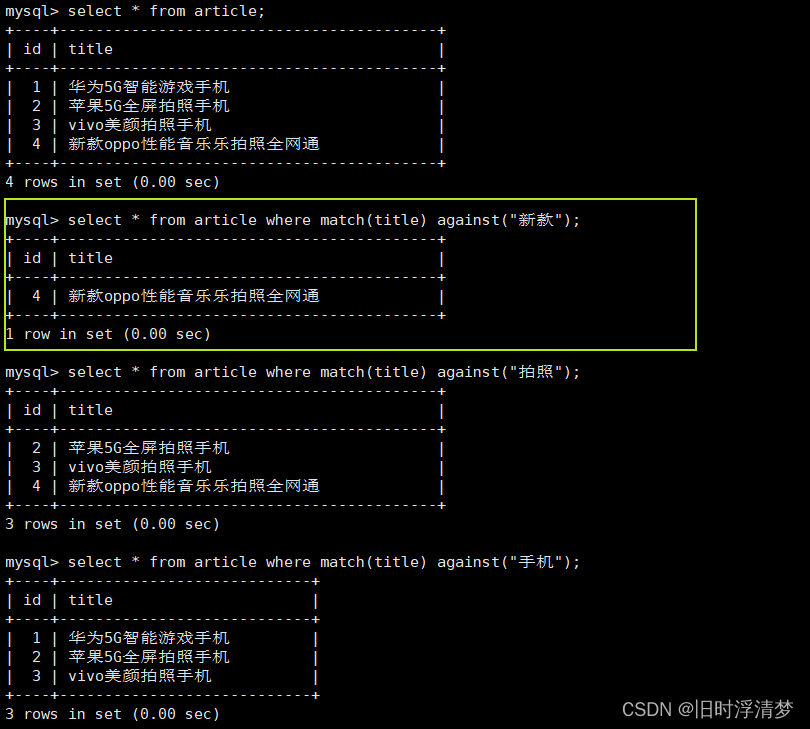















 2159
2159











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









