







这个是我在上网找资料的时候,发现下载资料PDF居然要付费,然后我查看网页源代码发现它网页的资料都是PDF的png格式,每一个图片都是写在一个DIV标签里面的,手动操作肯定比较复杂,(说明,博主我是学C++的,对python不是很懂),我知道python肯定可以实现这事,于是马上学习了一波。
一、需求分析
网页的页面源代码如下图所示,它的每一个<div>标签里面的img的URL就是资料的内容,可以直接通过URL来打开资料图片,然后“另存为”即可,但是手动操作太麻烦了(当然有同学说直接用爬虫,也可以哈,但是我没用),要是能自动化批量给它一个全是URL的文本文件,让python帮我逐一打开然后按照顺序命好名称逐一保存到本地文件就好了。
但是网页源码是HTML格式的,手动提取网页源码的URL也太慢了,所以我们还需要一个python函数来帮我们从给定的HTML的文本文件里面提取出URL按行保存到指定文本文件里。

二、从HTML中提取可用URL
1、先在项目目录下新建一个文本文件命名为html.txt。
2、将网页源码中所需要的地方复制到html.txt中。如下图所示
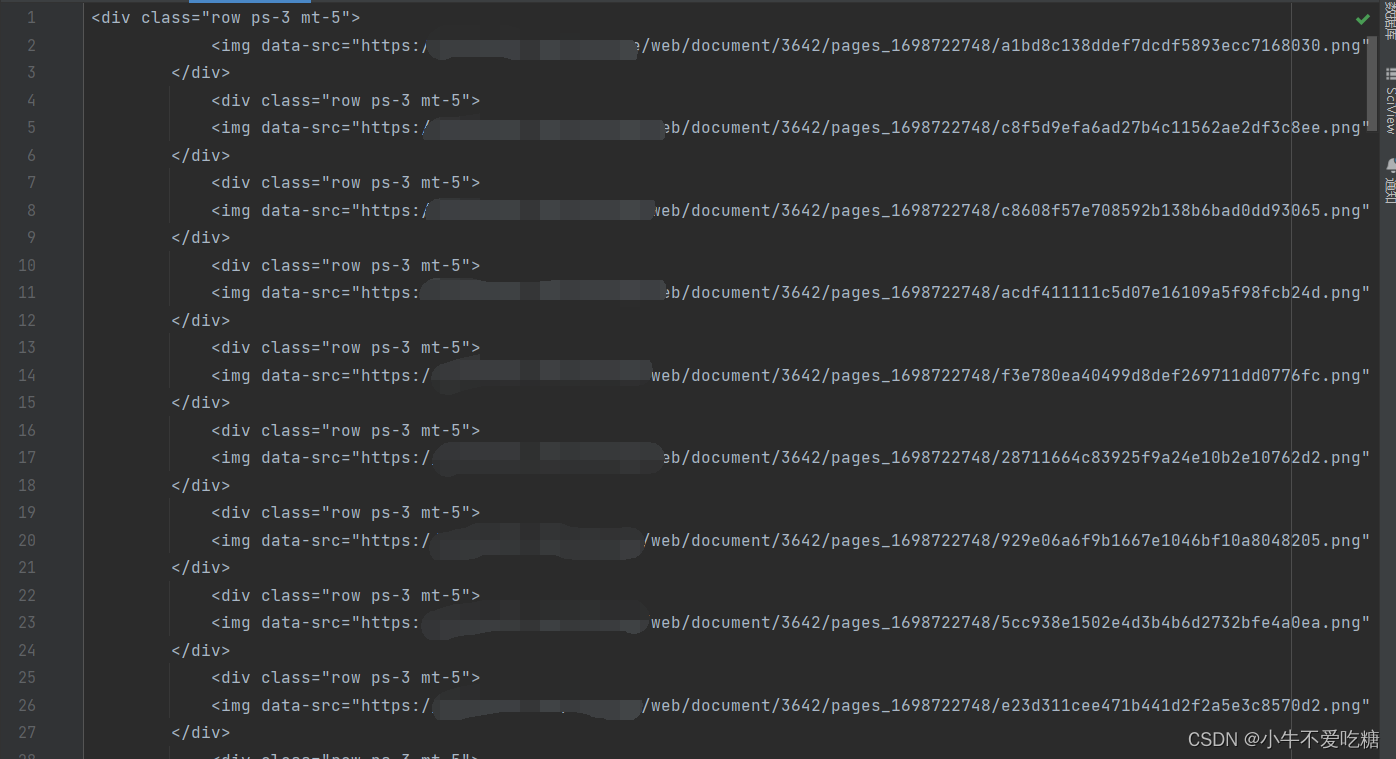
3、新建一个py文件,在里面写具体实现,通过观察发现所有目标URL均以png结尾,可以使用正则表达式匹配,取出目标URL 。然后保存到指定的文本文件HTTP.txt中。代码如下:
import re
# 打开HTML文件
with open('html.txt', 'r') as file:
html_content = file.read()
# 使用正则表达式提取URL
pattern = r'<img\s+data-src="([^"]+\.png)"'
urls = re.findall(pattern, html_content)
# 将URL保存到http.txt文件中
with open('HTTP.txt', 'w') as file:
for url in urls:
file.write(url + '\n')
4、执行完成后我们就得到了全是目标URL的一个文本文件了

三、批量执行URL按序保存到本地
1、打开HTTP.txt文件,按行取出URL,打开URL判断是否能正常打开,不需要执行浏览器打开这一操作,只需要得到返回值即可。
2、需要URL的顺序和保存的png一一对应,比如第一行URL对应图png1,所以考虑按序命名,设置计数器。根据计算器生成png文件的名称。
3、保存到指定文件夹,且命名好。
import requests
# 创建一个计数器
count = 1
# 打开网址文件
with open('HTTP.txt', 'r') as file:
# 逐行读取网址
for line in file:
url = line.strip() # 去除行尾的换行符和空格
# 下载图片并保存到本地
response = requests.get(url)
if response.status_code == 200:
# 生成图片文件名
filename = f'{count}.jpg'
# 保存到桌面文件夹
save_path = f'F:/桌面文件夹/tupian/{filename}'
with open(save_path, 'wb') as image_file:
image_file.write(response.content)
print(f'Saved image: {save_path}')
# 增加计数器
count += 1
else:
print(f'Failed to download image from {url}')
4、运行代码,查看结果。如图

好了就记录到这里吧,对于python的同学来说肯定很简单,但是我想记录的不是说这个需求有多难,而是记录一下自己日常遇到问题时会主动去学习去思考,去分析需求去解决的过程。














 750
750











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









