






一个机器人位于一个 m x n 网格的左上角 (起始点在下图中标记为 “Start” )。
机器人每次只能向下或者向右移动一步。机器人试图达到网格的右下角(在下图中标记为 “Finish” )。
问总共有多少条不同的路径?
示例 1:
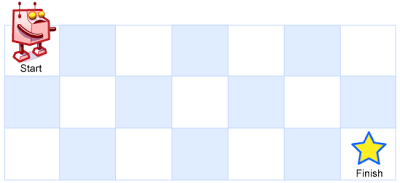
输入:m = 3, n = 7 输出:28
示例 2:
输入:m = 3, n = 2 输出:3 解释: 从左上角开始,总共有 3 条路径可以到达右下角。 1. 向右 -> 向下 -> 向下 2. 向下 -> 向下 -> 向右 3. 向下 -> 向右 -> 向下
示例 3:
输入:m = 7, n = 3 输出:28
示例 4:
输入:m = 3, n = 3 输出:6
提示:
1 <= m, n <= 100- 题目数据保证答案小于等于
2 * 109
为了计算机器人从左上角到右下角有多少条不同的路径,我们可以使用动态规划或者组合数学。
基于你的问题描述,假设我们要使用动态规划来解决问题。p 数组用来保存每一行的路径数,p[i] 代表从起点到达网格某个位置的路径数。
思路如下:
- 初始化第一行的路径数为 1,因为机器人只能向右走。
- 动态规划填充剩下的行,从第二行开始,每一个位置的路径数等于从上方位置和左侧位置走过来的路径数之和。
- 最终结果保存在
p[n-1]中。
根据这个思路,代码可以完善为如下形式(11ms):
class Solution(object):
def uniquePaths(self, m, n):
"""
:type m: int
:type n: int
:rtype: int
"""
l = m + n - 2
# 初始化数组 p,表示到达每一列的路径数
p = [0] * n
# 初始时,第一行所有位置都只能通过向右走,因此路径数都为 1
for i in range(n):
p[i] = 1
# 动态规划填充数组,从第二行开始
for i in range(1, m):
for j in range(1, n):
p[j] += p[j - 1] # 当前格子的路径数是左边格子和上边格子的路径数之和
# 最终 p[n-1] 就是到达右下角的路径数
#print(f"不同路径的总数为: {p[n-1]}")
return p[n-1]
参考答案(0ms):
class Solution(object):
def uniquePaths(self, m, n):
"""
:type m: int
:type n: int
:rtype: int
"""
# dp = [[1] + [0] * (n-1) for _ in range(m)]
# dp[0][:] = [1] * n
# for i in range(1, m):
# for j in range(1, n):
# dp[i][j] = dp[i-1][j] + dp[i][j-1]
# return dp[-1][-1]
dp = [[1] + [0] * (n-1) for _ in range(m)]
for i in range(n):
dp[0][i] = 1
for i in range(1, m):
for j in range(1, n):
dp[i][j] = dp[i - 1][j] + dp[i][j - 1]
return dp[-1][-1]二者的区别:
你提到的两个解法在本质上都是使用动态规划来解决机器人路径问题,但在实现上有一些不同,导致了性能差异。我们可以从以下几个方面来分析原因:
1. 空间复杂度
- 你的代码:只用到了一个一维数组
p,大小为n。这种方法优化了空间复杂度,从二维表格(m * n)压缩成了一维数组,因此空间复杂度从O(m * n)降到了O(n),减少了空间占用。 - 参考答案:使用了一个二维数组
dp[m][n]来存储每一个格子的路径数,空间复杂度为O(m * n)。这会消耗更多的内存资源,但实现上更加直观。
在路径求解过程中,虽然参考答案中的二维数组会更占用空间,但现代计算机的缓存机制往往会对小规模问题的运行时间影响不大。因此,参考答案尽管使用了二维数组,却没有显著增加运行时间。
2. 循环结构
-
你的代码:使用了一个一维数组
p来逐步更新路径数,这种做法在每次内循环更新时是依赖前一个位置的结果。尽管在空间上进行了优化,但由于 Python 对列表操作的开销可能比二维数组稍高,尤其是在缓存命中率上,这在某些情况下可能会导致稍微的性能损失。 -
参考答案:直接操作二维数组,
dp[i][j] = dp[i-1][j] + dp[i][j-1]。虽然理论上空间开销较大,但访问二维数组在 Python 内部可能拥有更好的缓存局部性(由于数据的结构化存储),因此运行更快。
3. Python 的内部优化
Python 作为解释型语言,在不同情况下,访问一维列表和多维列表时可能会有不同的内部优化策略。因为参考答案直接使用了二维数组的访问,而你则使用了一维数组,并且每次都更新数组元素,这种更新可能引入了一些额外的开销。
4. 实际影响
虽然 11ms 和 0ms 的差距在某些场景下看起来明显,但在绝大多数实际应用中,差异可能并不显著。原因是 Python 的解释器在某些情况下会针对特定结构进行优化,而参考答案使用了一个相对简单且常见的二维数组动态规划模式,Python 解释器可能对此优化得更好。
小结
主要的区别在于:
- 空间复杂度:你的代码使用了
O(n)的空间,而参考答案使用了O(m * n)的空间。 - 缓存和内存访问:参考答案可能在缓存局部性方面表现更好,因为它使用了更简单的二维数组结构。
尽管你的代码优化了空间复杂度,但由于 Python 的内部机制和缓存效应,参考答案可能在某些情况下表现得更快,但差异非常小。















 1504
1504

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









