







文章目录
thread对象的构造
this_thread
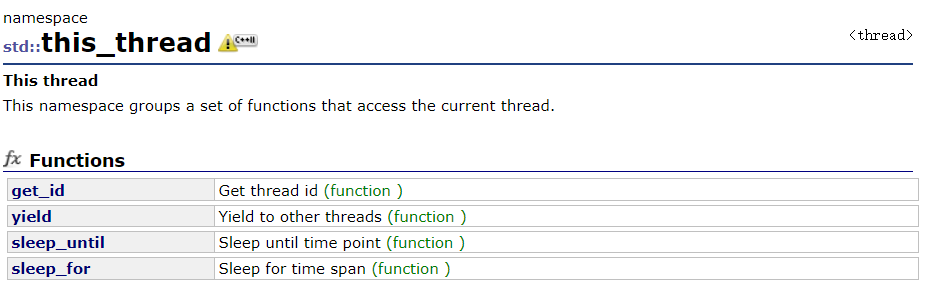
this_thread是一个命名空间,其中有四个函数,经常使用的接口是:get_id(获取当前线程的id值)和yield(使当前线程让出时间片)。
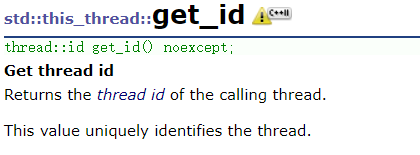
get_id的返回值单独定义在命名空间std::thread中,该值表示一个唯一的线程,其类型为id。

yield函数无参无返回值,若当前线程抢占到了时间片,它会使其放弃时间片,让出cpu资源使系统调用其他线程,注意:yield不会使线程陷入阻塞。
剩下的两个函数,它们分别以相对时间和绝对时间的方式使线程陷入阻塞即可。这里介绍经常使用的sleep_for:
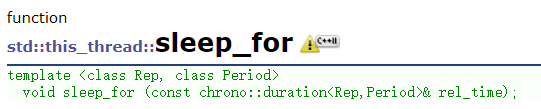
文档中给出的demo:

sleep_for的参数:std::chrono::seconds是一个类型重定义,除了秒还有毫秒,微秒…
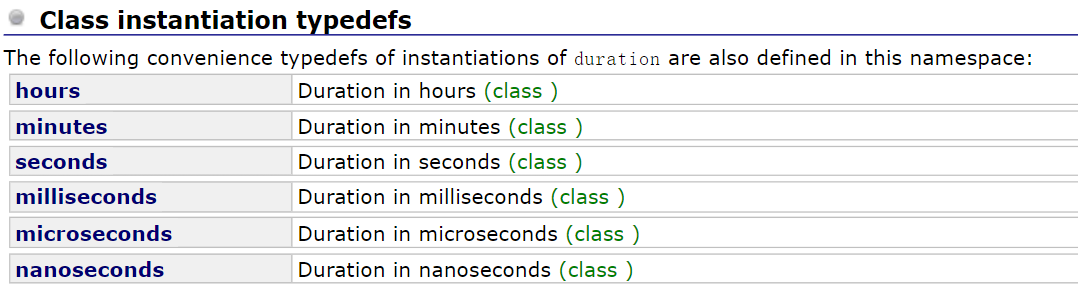
若想更精确的控制线程阻塞的时间,将seconds修改为上面的更精确的类型即可。比如
std::this_thread::sleep_for(std::chrono::microseconds(1));
construct
要注意的是:thread不允许拷贝构造与拷贝赋值,所以其拷贝构造被禁用(delete),但是thead允许移动构造与移动赋值。
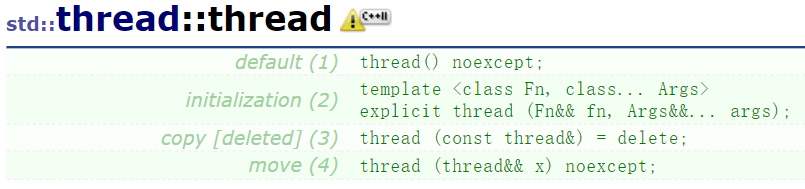
通常我们会使用第二个构造函数,传入一个可执行对象(函数地址,仿函数,lambda等)以及调用该对象需要的参数。该构造函数的形参是一个万能引用fn与一个可变参数列表args,万能引用用来接收我们传入的可执行对象,因为调用该对象需要的参数不确定,所以这里设计了一个可变参数列表,用来接收与提取我们传入的参数,创建线程的demo:
#include <iostream>
#include <thread>
using namespace std;
void Print(int n)
{
for (int i = 0; i < n; ++i)
{
cout << this_thread::get_id() << ":" << i << endl;
}
}
int main()
{
thread p1(Print, 10);
thread p2(Print, 10);
p1.join();
p2.join();
return 0;
}
运行结果:
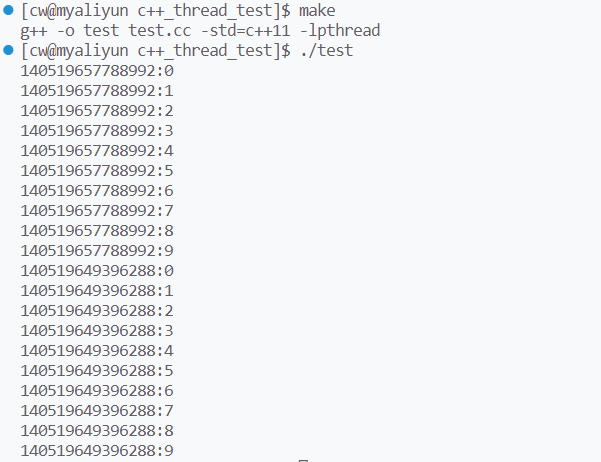
由于缺乏对标准输出流文件的访问控制,可能出现打印结果混乱的情况,此时可以对线程加锁,建立临界区以互斥访问标准输出流文件
mutex
mutex的成员函数:
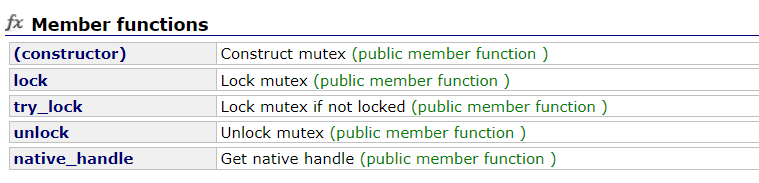
经常使用的接口是:lock加锁和unlock解锁,对于mutex的构造,我们使用无参的构造即可。以下demo使用mutex实现对标准输出流文件的互斥访问:
#include <iostream>
#include <thread>
#include <mutex>
using namespace std;
mutex mtx;
void Print(int n)
{
for (int i = 0; i < n; ++i)
{
mtx.lock();
cout << this_thread::get_id() << ":" << i << endl;
mtx.unlock();
}
}
int main()
{
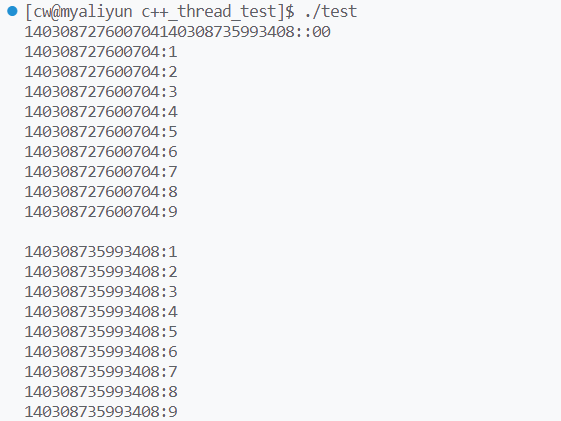
thread p1(Print, 10);
thread p2(Print, 10);
p1.join();
p2.join();
return 0;
}
运行结果:
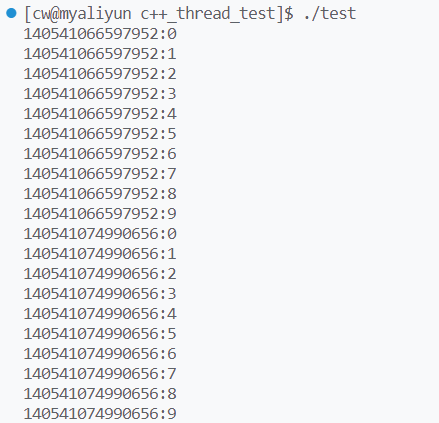
但是我们要尽量少使用全局变量,因此我们可以定义一把局部锁,将其作为线程的可执行对象的参数传递给线程。demo修改如下:
#include <iostream>
#include <thread>
#include <mutex>
using namespace std;
void Print(int n, mutex mtx)
{
for (int i = 0; i < n; ++i)
{
mtx.lock();
cout << this_thread::get_id() << ":" << i << endl;
mtx.unlock();
}
}
int main()
{
mutex mtx;
thread p1(Print, 10, mtx);
thread p2(Print, 10, mtx);
p1.join();
p2.join();
return 0;
}

但此时引起了编译错误,具体原因是:mutex不支持拷贝构造与拷贝赋值。将mutex对象作为实参传递给可变参数列表,这是一次拷贝。可变参数列表提取出参数后,将参数传递给可执行对象的形参,这又是一次拷贝。总之这个过程会触发mutex的拷贝构造,可以将Print的形参修改为&再进行编译:

结果还是发生错误,原因刚才就说过了,thread的构造函数用可变参数列表接收我们传递的实参,提取出参数后再传递给可执行对象(Print),即使可执行对象的形参使用了引用,但是我们不知道thread的构造函数是如何实现的(也就是可变参数列表具体的实现,它使用了引用接收参数吗?我们不能确定),这是一个黑箱,但可以推测的是:它一定会触发mutex的拷贝构造。总之,禁用拷贝构造的mutex对象无法直接作为实参进行传递
ref
C++提供了函数:ref,可以叫它引用包装器,它用来保持对象的引用语义,注意不是复制对象!下面是一个使用它的demo:
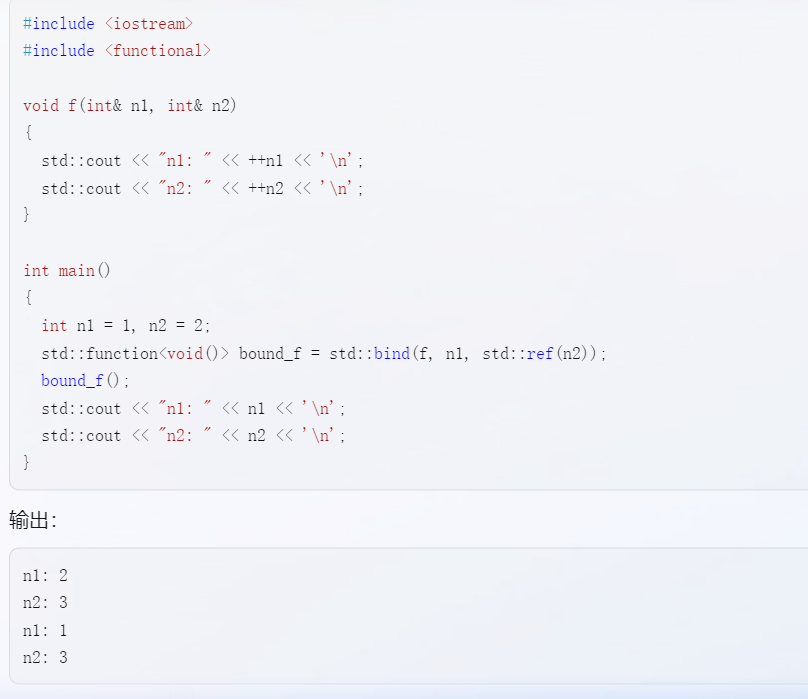
将mutex对象作为ref的参数,ref会返回该对象的引用。修改代码:将mtx套上ref后,程序就能通过编译并正确运行(ps:具体实现原理不清楚,这个后续再来研究,TO DO):

用lambda表达式构造thread
用lambda构造线程对象时,不需要传递参数
lambda表达式拥有捕捉列表,调用lambda表达式就等于使用了其捕捉到的外部变量,也就是说捕捉列表捕捉的变量都是lambda表达式的参数。通常情况下,创建thread并传递给线程的参数都是主线程的上下文变量,此时使用捕捉列表即可。也就是说,thread的构造函数只需要一个lambda表达式,不需要可执行对象的参数。
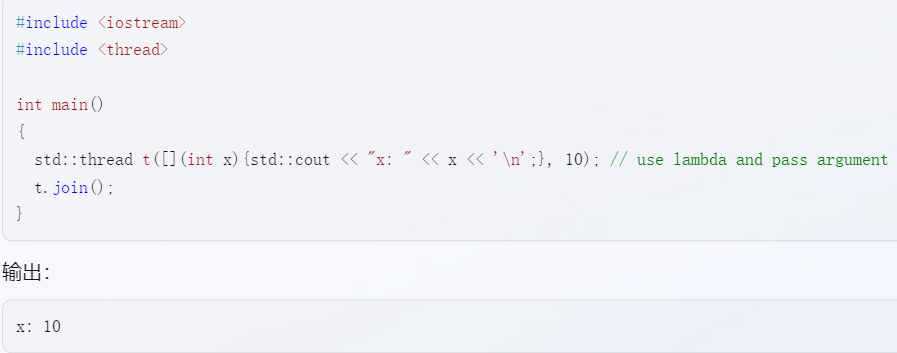
如果在构造thread对象时,不使用lambda的捕捉列表,却需要在lambda中使用一些参数,这些参数就需要在lambda表达式后进行传递。比如这个demo:
再比如下面这个复杂点的demo:
#include <thread>
#include <mutex>
#include <vector>
#include <iostream>
using namespace std;
int main()
{
int n = 10;
mutex mtx;
vector<thread> threads(5);
// thread的设置
for (int i = 0; i < threads.size(); ++i)
{
threads[i] = thread([&](){
for (int i = 0; i < n; ++i)
{
mtx.lock();
cout << this_thread::get_id() << ":" << i << endl;
mtx.unlock();
this_thread::sleep_for(std::chrono::milliseconds(500));
}
});
}
for (auto& x : threads)
{
x.join();
}
return 0;
}
- 首先创建线程集threads并用thread的默认构造初始化5个线程
- 然后设置threads中的每个线程:用lambda表达式创建thread的匿名对象,然后赋值给threads中的thread
- 这会调用therad的移动拷贝,由于thread只禁止了拷贝构造与赋值拷贝,没有禁用移动拷贝,所以这是符合语法的
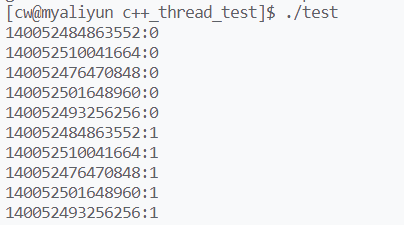
部分运行结果:
线程串行比并行快?
修改上面的demo:主线程设置一个变量count,其初始值为0,每个线程对count进行n次++操作,一共有5个线程,且n由我们设定。主线程最后会打印出count的值,修改后的demo如下:
int main()
{
int n = 1000000;
int count = 0;
mutex mtx;
vector<thread> threads(5);
// thread的设置
for (int i = 0; i < threads.size(); ++i)
{
threads[i] = thread([&](){
// mtx.lock();
for (int i = 0; i < n; ++i)
{
count++;
}
// mtx.unlock();
});
}
for (auto& x : threads)
{
x.join();
}
cout << "count = " << count << endl;
return 0;
}
n被我们设置为1000000,总共有5个线程会对count进行++操作,每个进程各自进行1000000次++操作,最后count的值为5000000。当然了,这是在保证互斥访问count的情况下才会发生的结果,上面的demo没有对count进行互斥访问,所以最后count的值一定小于5000000,多次运行的结果:

如果我们实现了共享资源的互斥访问,比如下面的demo:
// 加锁粒度粗
for (int i = 0; i < threads.size(); ++i)
{
threads[i] = thread([&](){
mtx.lock();
for (int i = 0; i < n; ++i)
{
count++;
}
mtx.unlock();
});
}
我们对整个for循环进行了加锁,只要一个线程没有执行完这个for循环,其他线程就无法访问count。我们可以实现更细粒度的加锁,比如
// 加锁粒度细
for (int i = 0; i < threads.size(); ++i)
{
threads[i] = thread([&](){
for (int i = 0; i < n; ++i)
{
mtx.lock();
count++;
mtx.unlock();
}
});
}
此时它们得到的count都是5000000

很明显,更细粒度的加锁可以实现线程间的并发访问,充分的发挥了多核cpu的资源。但结果却不是这样,分别运行两个demo,可以明显感受到:加锁粒度粗的程序执行的更快,而加锁粒度细的程序反而更慢(开始运行到产生结果之间有明显的卡顿)。原因也很简单:虽然线程切换的成本比进程切换的成本低,但总归是有成本的。加速粒度细时,由于循环要进行1000000次,在此期间不同线程被不断的切换,共享资源被频繁的保存与恢复。完成这些工作消耗的cpu资源明显多于对count++消耗的cpu资源,这是没有意义的,为了节省cpu资源,提高线程运行效率,增加加锁的粒度反而是一种更好的选择。
加锁粒度粗时,其他线程会因为申请锁而阻塞,直到锁的资源被释放,被阻塞的线程才会被唤醒。也就是说,这种情况下,线程切换不会频繁的发生,程序的运行速度也就更快。
当然了,加锁粒度的粗和细还是要看具体的场景,如果线程要频繁的执行简单的任务,此时太细的加锁就没有必要,因为这会使得本来很快就能执行完的程序变慢。
CAS(atomic类)
上面的demo中,为保证共享资源count的数据一致性,除了设置互斥锁,我们还可以使用atomic适配器,使count具有原子,即所有写入count的操作都是原子操作。解释原子操作:若访问count的操作都是原子操作,那么这些操作要么已经执行完,要么未被执行。有种commit or rollback的意思(《STL源码剖析》中介绍的概念)
CAS(compare and set)是一种原子操作,它是一种无锁化数据结构与算法。简单来说,CAS的原理是:
- 从内存中取出一个值并保存,对其进行修改后,比较内存中的值和线程保存的值
- 判断两值是否相同,如果相同,就修改内存中的值为修改后的值
- 如果不相同,就不断地重复上面的步骤,直到两值相同
举个例子:
- count为2,一个线程从内存读取count的值并将其保存下来,将count加1后得到3
- 然后线程再读取内存中count的值,假设是7,线程将7与之前保存的2进行比较,发现不相等
- 此时线程就会重新读取count值,重复以上步骤,直到成功修改了count
个人感觉CAS也有些想SSL的数字签名。回到之前的demo,用atomic修饰count使之具有原子属性:
int main()
{
int n = 1000000;
// atomic的设置
atomic<int> count(0);
mutex mtx;
vector<thread> threads(5);
// thread的设置
for (int i = 0; i < threads.size(); ++i)
{
threads[i] = thread([&](){
for (int i = 0; i < n; ++i)
{
count++;
}
});
}
for (auto& x : threads)
{
x.join();
}
cout << "count = " << count << endl;
return 0;
}
运行结果同样是正确的:

timed_mutex
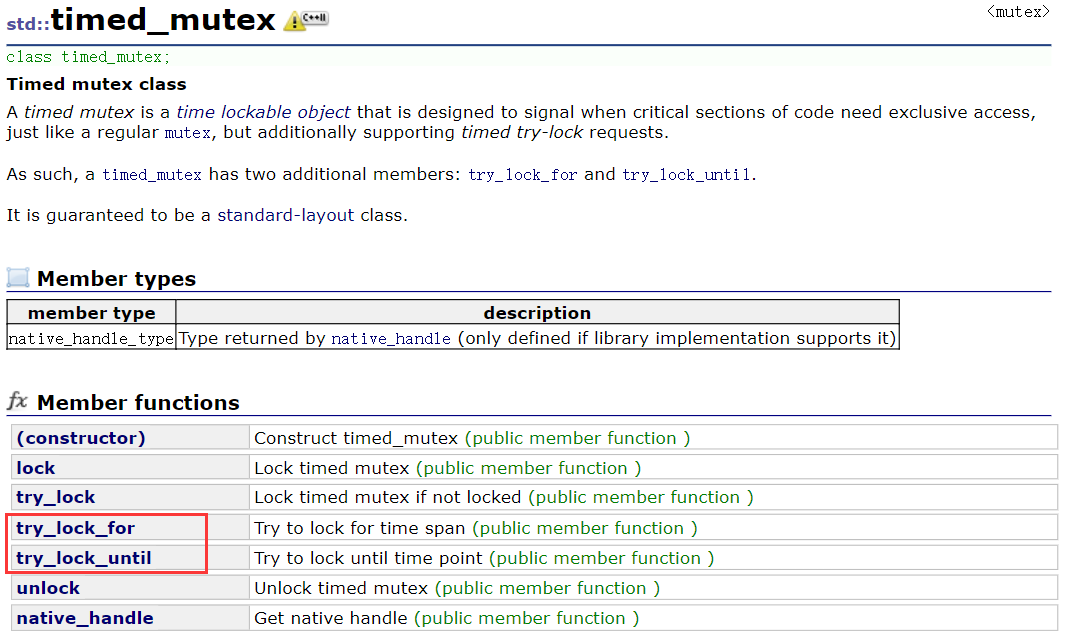
简单提一下,timed_mutex也是一种互斥锁,和mutex的区别是timed_mutex多了两个接口,可以设置try_lock的持续时间
lock_guard,unique_guard,手动控制生命周期,为什么要使用
lock_guard是一种RAII,我们可以用它管理锁的生命周期:初始化lock_guard对象时会加锁,出了lock_guard对象的作用域时会解锁。
那么为什么要使用lock_guard呢?因为程序可能因为异常机制,在解锁之前跳转到其他执行流中,此时会导致死锁。如果使用lock_guard,线程跳转到其他执行流之前会释放当前的函数栈帧,所以lock_guard会执行解锁操作,我们就不用担死锁问题.
关于lock_guard的使用:


我们需要声明lock_guard的模板参数(锁的类型),初始化时将已经创建好的锁作为参数传递给lock_guard的构造函数
int main()
{
int n = 1000000;
int count = 0;
mutex mtx;
vector<thread> threads(5);
// thread的设置
for (int i = 0; i < threads.size(); ++i)
{
threads[i] = thread([&](){
lock_guard<mutex> guard(mtx);
for (int i = 0; i < n; ++i)
{
count++;
}
});
}
for (auto& x : threads)
{
x.join();
}
cout << "count = " << count << endl;
return 0;
}
上面的demo是粗粒度的加锁:进入for循环之前就加锁,直到线程执行完for循环才进行解锁
unique_lock和lock_guard一样,都是一种锁的RAII,但比起lock_guard,unique_lock提供了更多的功能
- unique_lock可以手动加锁与解锁,而lock_guard的加锁与解锁跟随lock_guard的生命周期
- unique_lock提供了try_lock,try_lock_for,try_lock_until等接口
- unique_lock可以移动赋值与拷贝,而lock_guard则禁止所有的拷贝
条件变量
关于线程之间的同步,可以使用condition_variable类来实现
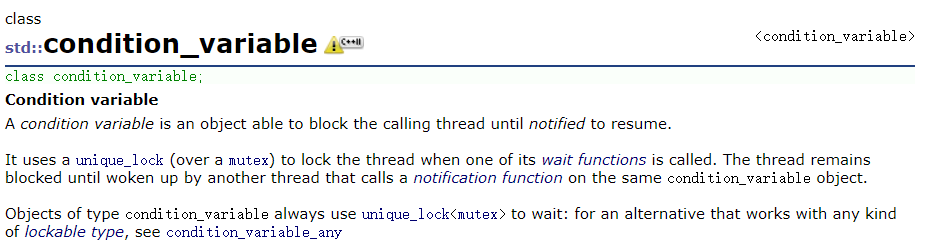

wait:条件变量下的等待,通常使用第二个重载版本,将一把锁和一个可执行对象传递作为参数。当可执行对象的执行结果为真时,线程才能往下执行。否则线程将陷入条件变量下的等待。
和Posix的pthread_cond_wait一样,两者都需要配合一把锁使用,当然了,unix环境下,C++的condition_variable肯定封装了pthread_cond_wait。
- 当线程陷入条件变量下的等待时,两者都会先解锁后等待
- 当线程被唤醒时,两者都会先加锁再往下执行
- 这是为了防止死锁

第二种重载方法其实就是一个条件的while判断。Unix的接口pthread_cond_wait只是简单的进行条件变量下的等待,至于等待之前需要满足的前置条件则需要程序员自己设置,C++的condition_variable则将前置条件进行了封装,形成了wait的第二个重载。
不用条件变量带来的问题:连续运行+顺序不确定
设置条件变量是为了保证线程之间的同步,若不设置条件变量,我们无法保证哪个线程先执行。在一些需要控制线程执行顺序的场景中,这将导致bug。
同时,不使用条件变量还可能导致线程饥饿,即一个线程一直访问临界资源,而其他线程无法访问临界资源。这和操作系统的调度机制有关,若线程切换的成本高于对当前线程加锁并访问临界区资源的成本,那么操作系统就倾向于不进行线程切换,让当前线程反复申请锁并访问临界资源。
以上的两个问题都可以使用条件变量来解决。合理的使用条件变量,为线程设置同步关系,可以使线程公平的访问临界资源。
shared_ptr是否线程安全?
异常安全和线程安全都是在编程中需要关注的问题,shared_ptr的RAII属性可以很好的解决异常安全的问题,但是shared_ptr是线程安全的吗?这个问题的答案分为两点:
- 首先,shared_ptr实现的拷贝的线程安全,即对引用计数进行++与–操作是线程安全的
- 但是访问被shared_ptr托管的资源却不是线程安全的
也就是标准库的shared_ptr只实现的拷贝的线程安全,内置的引用计数一定是准确的,这不仅解决了正常运行程序的资源泄漏问题,同时也解决了异常结束程序的资源泄漏问题,做到了异常安全。
比如这个模拟实现的shared_ptr:
namespace myptr
{
template <class T>
class shared_ptr
{
public:
shared_ptr(T* ptr)
: _ptr(ptr)
, _pCount(new int(1))
{}
shared_ptr(const shared_ptr<T>& p)
{
_ptr = p._ptr;
_pCount = p._pCount;
(*_pCount)++;
}
void Release()
{
if (--(*_pCount) == 0) // 当计数为0,需要释放pCount
{
if (_ptr) // 如果_ptr为空,只要释放pCount
{
delete _ptr;
_ptr = nullptr;
}
cout << "~shared_ptr()" << endl;
delete _pCount;
_pCount = nullptr;
}
}
shared_ptr<T>& operator=(const shared_ptr<T>& p)
{
// 指向资源不同时,使两指针指向同一资源,并且计数增加
if (_ptr != p._ptr) // 当指向资源相同时,没有必要进行赋值
{
Release(); // 先释放该指针之前指向的空间
_ptr = p._ptr;
_pCount = p._pCount;
* _pCount++;
}
}
~shared_ptr()
{
Release();
}
T& operator*() { return *_ptr; }
T* operator->() { return _ptr; }
T* _ptr;
int* _pCount;
};
}
int main()
{
myptr::shared_ptr<int> p_i(new int(3));
vector<thread> threads(5);
int n = 10000;
for (int i = 0; i < threads.size(); ++i)
{
threads[i] = thread([&](){
for (int j = 0; j < n; ++j)
{
myptr::shared_ptr<int> pt_i = p_i;
}
});
}
for (auto& thread : threads)
{
thread.join();
}
cout << "指针的最后引用数: " << *(p_i._pCount) << endl;
return 0;
}
多个线程不断的拷贝同一个shared_ptr,这会使得该shared_ptr的引用计数++。当线这些拷贝的shared_ptr出了作用域,即线程结束时,该shared_ptr的引用计数会–。运行该程序:
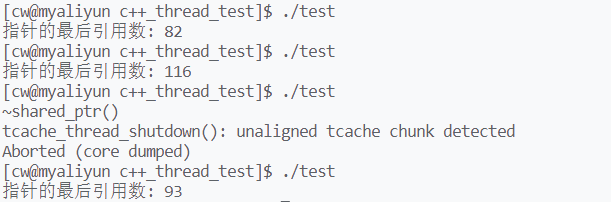
有时引用计数的值大于1,有时小于1(程序运行崩溃),有时等于1。如果模拟实现的shared_ptr的拷贝是线程安全的,那么最后打印出的count值应该是1,然而实际上count的值总是大于或小于1。这是因为线程对count的访问不是互斥的,为解决这个线程安全问题,可以设置count为atomic类,或者对count加锁。
修改demo,对count进行加锁:
namespace myptr
{
template <class T>
class shared_ptr
{
public:
shared_ptr(T* ptr)
: _ptr(ptr)
, _pCount(new int(1))
, _pmtx(new mutex)
{}
shared_ptr(const shared_ptr<T>& p)
{
_ptr = p._ptr;
_pCount = p._pCount;
_pmtx = p._pmtx;
_pmtx->lock();
(*_pCount)++;
_pmtx->unlock();
}
void Release()
{
bool flag = false;
_pmtx->lock();
if (--(*_pCount) == 0) // 当计数为0,需要释放pCount
{
flag = true;
if (_ptr) // 如果_ptr为空,只要释放pCount
{
delete _ptr;
_ptr = nullptr;
}
delete _pCount;
_pCount = nullptr;
}
_pmtx->unlock();
if (flag)
delete _pmtx;
}
shared_ptr<T>& operator=(const shared_ptr<T>& p)
{
// 指向资源不同时,使两指针指向同一资源,并且计数增加
if (_ptr != p._ptr) // 当指向资源相同时,没有必要进行赋值
{
Release(); // 先释放该指针之前指向的空间
_ptr = p._ptr;
_pCount = p._pCount;
_pmtx = p._pmtx;
_pmtx->lock();
(*_pCount)++;
_pmtx->unlock();
}
}
~shared_ptr()
{
Release();
}
T& operator*() { return *_ptr; }
T* operator->() { return _ptr; }
T* _ptr;
int* _pCount;
mutex* _pmtx;
};
}
- 加入一个指向mutex的指针作为类的成员变量,构造函数new一个mutex并保存其地址
- 之后的拷贝构造与拷贝赋值都需要拷贝这把锁的地址
- 对拷贝构造与拷贝赋值中的count++进行加锁
- 对析构函数判断count是否为0的语句进行加锁
- 要注意的是:count为0需要将锁的资源也delete,否则会导致内存泄漏。这里用了一个标记变量控制锁的释放
运行结果:
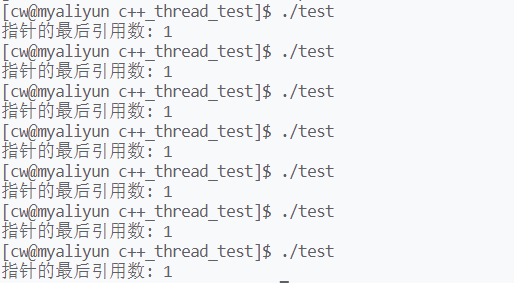
而智能指针是一种类似指针的结构,它必须重载*与->操作符,实现指针的解引用和地址访问操作。但是保证了拷贝安全的shared_ptr解引用/地址访问后获得的资源却不是线程安全的,当然了,对于智能指针指向资源的线程安全本来就应该由我们实现,毕竟智能指针只是用来托管资源的。修改demo,使线程访问智能指针托管的资源,每个线程都对其进行10000次++操作,共有5个线程:
int main()
{
myptr::shared_ptr<int> p_i(new int(3));
vector<thread> threads(5);
mutex mtx;
int n = 10000;
for (int i = 0; i < threads.size(); ++i)
{
threads[i] = thread([&](){
for (int j = 0; j < n; ++j)
{
myptr::shared_ptr<int> pt_i = p_i;
(*pt_i)++;
}
});
}
for (auto& thread : threads)
{
thread.join();
}
cout << "指针的最后引用数: " << *(p_i._pCount) << endl;
cout << "p_i指向的值: " << *p_i << endl;
return 0;
}
运行结果:

懒汉与饿汉,双检锁
首先,懒汉和饿汉都是单例模式的具体实现方式。
- 饿汉:程序一启动,main函数执行前,单例对象就要进行构造
- 但如果单例对象的构造时间很长,这会导致程序的启动时间太慢
- 饿汉的好处是:它比懒汉简单,没有线程安全的问题
- 懒汉:只有程序显式定义了单例对象,才会进行对象的构造
- 与饿汉相比,使用懒汉的程序初始化更快,但是构造单例对象的开销始终存在
- 懒汉的缺点就是:存在线程安全问题,即多个线程同时构造单例对象
- 而饿汉模式下,单例对象的构造在main函数之前,此时的程序只有一个执行流,故不存在线程安全问题
对于懒汉存在的线程安全问题,需要使用双检锁来解决,下面是一个没有加锁的懒汉类:
class Singleton
{
public:
static Singleton* GetInstance()
{
if (_pInstance == nullptr)
{
_pInstance = new Singleton;
}
return _pInstance;
}
private:
Singleton(){};
Singleton(Singleton const&) = delete;
Singleton& operator=(Singleton const&) = delete;
static Singleton* _pInstance;
};
Singleton* Singleton::_pInstance = nullptr;
它有一个静态成员函数GetInstance
- 该函数通过单例对象的指针检查单例对象是否被创建
- 若单例对象的指针为空,该函数将创建单例对象
- 若单例对象的指针不为空,该函数将返回其地址
在多线程执行的程序中,单例对象的指针_pInstance就是一个共享资源,存在数据不一致的问题:可能线程判断_pInstance为空,准备执行new语句,但是却被系统切走,其他线程准备执行new语句时也被切走。等到这些准备执行new语句的线程被切回来时,它们将创建多个单例对象,这就不符合单例模式的定义了。所以我们需要对访问_pInstance的语句进行加锁,修改单例类,添加mutex成员:
class Singleton
{
public:
static Singleton* GetInstance()
{
lock_guard<mutex> guard(_mtx);
if (_pInstance == nullptr)
{
_pInstance = new Singleton;
}
return _pInstance;
}
private:
Singleton(){};
Singleton(Singleton const&) = delete;
Singleton& operator=(Singleton const&) = delete;
static Singleton* _pInstance;
static mutex _mtx;
};
mutex Singleton::_mtx;
Singleton* Singleton::_pInstance = nullptr;
虽然修改后的单例类保证了线程安全,但是它不够合理:线程每次调用GetInstance获取单例对象的指针时都需要加锁,但是加锁只有在创建单例对象时需要加锁。继续修改单例类:
class Singleton
{
public:
static Singleton* GetInstance()
{
if (_pInstance == nullptr)
{
lock_guard<mutex> guard(_mtx);
_pInstance = new Singleton;
}
return _pInstance;
}
private:
Singleton(){};
Singleton(Singleton const&) = delete;
Singleton& operator=(Singleton const&) = delete;
static Singleton* _pInstance;
static mutex _mtx;
};
mutex Singleton::_mtx;
Singleton* Singleton::_pInstance = nullptr;
只对new语句加锁可以吗?因为判断语句if (_pInstance == nullptr)也是对共享资源_pInstance的访问,所以这样修改同样会导致线程安全问题。继续修改单例类:
class Singleton
{
public:
static Singleton* GetInstance()
{
if (_pInstance == nullptr)
{
lock_guard<mutex> guard(_mtx);
if (_pInstance == nullptr)
{
_pInstance = new Singleton;
}
}
return _pInstance;
}
private:
Singleton(){};
Singleton(Singleton const&) = delete;
Singleton& operator=(Singleton const&) = delete;
static Singleton* _pInstance;
static mutex _mtx;
};
mutex Singleton::_mtx;
Singleton* Singleton::_pInstance = nullptr;
只需要在加锁之前判断_pInstance是否为空,这个判断语句可以防止只是想获取单例对象指针的线程进行加锁。而对于要创建单例对象的线程们,通过第一个判断语句后,竞争锁资源,只有一个线程可以执行new语句。其他线程继续竞争锁,但是因为第二个判断语句,它们不会执行new语句。
总结一下双检锁:
- 对于单例对象没有被创建之前:很多线程都能通过第一个判断语句,进而竞争锁资源
- 但只有一个线程能进入临界区,通过第二个判断语句,执行new语句创建出单例对象
- 其他没有抢到锁的线程继续竞争锁资源,抢到锁后,因为第二个判断语句的阻拦,它们不会执行new语句
- 所以,双检锁的第一个检查是为了在单例对象创建后,获取其指针的线程能够不用加锁,快速的得到锁
- 双检锁的第二个检查是为了保护共享资源,实现真正的“单例”















 1425
1425











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









