






项目目标:实现一个JavaAPI文档的站内搜索引擎
有一个网页,上面带有一个搜索框,用户输入查询词之后进行搜索,将会在服务器上面搜索出与查询词相关的文档,并把这些信息返回到页面上面,用户点击搜索结果,就可以跳转到具体的详细页面;
根据JavaAPI文档,实现一个站内搜索引擎,会有一个网页,上面有一个搜索框,当用户从网页输入一个查询词之后,能够得到哪些API文档和这个查询词相关,会在服务器中得到所有和查询词相关的文档,并且返回相关信息给前端页面上面,进行点击搜索结果中文档的url,就可以跳转到对应的线上文档页面中


输入数据是查询词,输出数据包含着若干条搜索结果,每一个搜索结果包含着标题,描述,URL,用户点击搜索结果的时候,会先把请求发送到搜狗的服务器上面,搜狗服务器会返回一个302的重定向响应,浏览器再根据这个302在跳转到最终的落地页,为啥要进行重定向统计点击量
一)认识搜索引擎:
1)搜索引擎主页有一个搜索框,在搜索框里面进行输入的内容,称之为查询词,可以是一个词,两个词,还可以是一段话;
2)还有搜索结果页,里面包含了若干个搜索结果;
3)针对每一个搜索结果,带有颜色的,它一般都会包含查询词或者查询词的一部分或者和查询词具有一部分的相关性;
下面是搜索结果的一部分: 在浏览器上面输入土巴兔
4)标红的部分都是查询词或者是查询词的一部分,或者是带有一部分的相关性,比如说在搜索框里面输入了土巴免,就会立即返回土巴兔的相关内容;
5)每一个搜索结果都包含了好几个部分:
5.1标题(必有)(带有官网的那一部分文字);
5.2描述(通常是页面的摘要信息)(必有),对于查询词的解析信息,(介绍土巴兔的详细信息)
5.3子链接:像上面图片中的装修,一站式装修,这些都是一个a标签,点击之后都会有反应
像什么北京,登录;
5.4展示URL(必有):点击不跳转,上面的www.to8to.com -,品牌广告;
5.5图片(可爱的小兔子);
5.6点击URL(在标题下面里面),进行点击URL,浏览器将会跳转到落地页,就是搜索结果对应的一个页面(必有),标题下面有一个带颜色的横线;
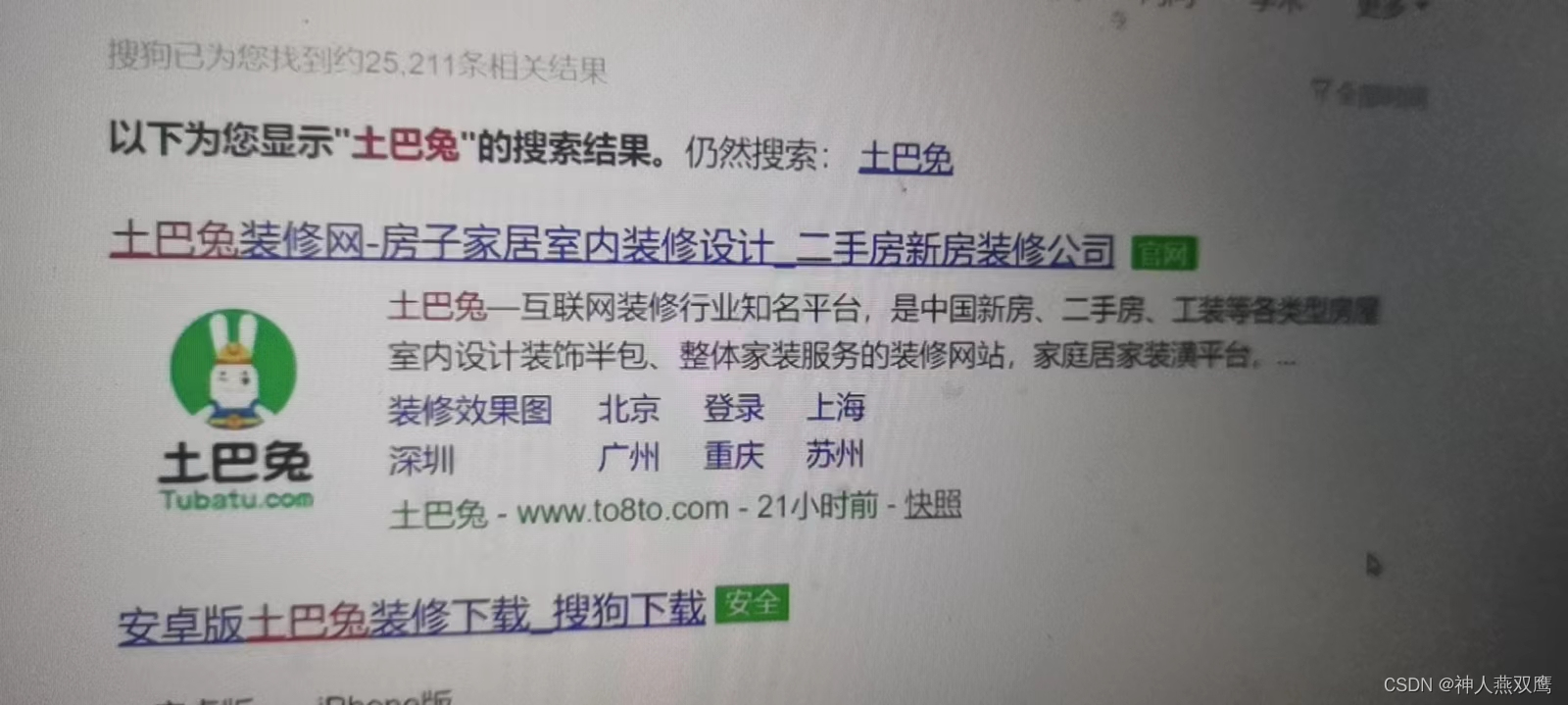

但是这个一个url里面,一定是有标题,描述,展示url还有点击url

二)搜索引擎的功能:
1)搜索引擎的功能,就是搜索,也叫做查找,查找用户的输入的查询词在哪些网页中出现过,或者说出现过一部分,就可以把结果展示到网页上面,用户进行点击结果就可以跳转到该页面,也就是详情页;
2)但是浏览器来如何获取到网页数据信息呢?
2.1)自然搜索结构:网页数据通常是通过爬虫
2.2)广告搜索结构:广告主把物料提供给广告平台,比如说在浏览器上面输入的不孕不育,就会在网页开头有大量的广告会显示出来,这里面的广告主就是医院,这里面的广告平台就是搜狗,在搜狗网页上展示的搜索广告来说,每一次用户点击这个搜索广告就会计费,广告主(医院)会给广告平台(搜狗也称之为制作搜索引擎的人)
1)像百度,搜狗这样的搜索引擎,进行全网搜索,整个互联网上所有的页面都可以获取到让你搜索,那么进行处理的数据量集时十分庞大的,现在是不具有搞全网搜索的条件的,因为没有那么多服务器,可以搞一个数据量比较小的多站内搜索,咱们现在所做的搜索引擎,叫做Java API文档
2)但是为什么要用JavaAPI文档,因为官方文档上面没有一个好用的搜索框,况且JavaAPI文档数量比较少,当前有限的硬件资源足够进行处理,况且文档内容不需要使用爬虫来进行获取,可以直接在官网上面进行下载,例如说想要找一下String类的用法,就必须先要找java.lang这个包,再去找String类,就显得十分的麻烦,如果不知道String类在哪个包下面就无法查找;
1)官方文档上面没有一个好的搜索框
2)Java API文档数量比较少,也就只有几万个页面,当前的硬件资源已经足够处理;
3)文档内容不需要使用爬虫来进行获取,只需要在官方文档上面进行下载即可
三)搜索引擎是如何进行工作的?和正排索引以及倒排索引的执行流程
当有了倒排索引之后,就可以根据用户进行输入的查询词就可以找到相关联的文档
1)搜索引擎绝对不是一个简单的小网页,需要在很多的网页数据中查询到你进行输入的查询词或者是部分查询词;
2)搜索引擎后台此时已经获取到了很多很多的网页数据,其中的每一个网页数据又是一个个的HTML,每一个HTML都是一个文档,每一个文档都是一个页面,要进行的工作就是想知道查询词在那些文档里面出现过;
如何查询某一个查询词在那些文档中出现过呢?
1)暴力搜索,依次遍历每一个文件,来进行查看当前文件中是否包含查询词,因为文档数目是非常多的,依次进行遍历文档的话效率就会非常的低效,因为搜索引擎针对时间效率上面的要求是非常高的,在几秒内或者几毫秒内返回大量的数据;
2)倒排索引:这是一种特殊的数据结构(Key是字符串,Value就是List<Integer>)
假设现在有两个网页,也就是有两个文档:
docID:1这个docID对应的文档内容是:乔布斯发布了苹果手机
docID:2这个docID对应的文档内容是:乔布斯卖了四斤苹果
正排索引:就是说给定文档ID也就是docID来进行查询到文档内容倒排索引:根据文档内容也就是某一个查询词来查找对应的文档ID,进一步来说就是根据这个词来进行查找这个词语在那些文档中出现过;

想要根据正排索引来进行制作倒排索引,首先就要根据文档内容进行分词操作,分词就是一句话中都存在着那些词;
分词操作就是在这个文档中都有哪些词,来进行分开,在文档为docID=1的文档中文档内容是,乔布斯发布了苹果手机,就根据这个文档来进行分词操作:
在上面的语句模块中,又重新的建立了一个映射关系,这个映射关系是从词语到文档ID建立了一个映射关系,正排索引是根据文档ID来进行查找到文档的内容,而倒排索引就是根据这个词的内容信息来找到在这个词语哪些文档ID中存在过
针对文档一和文档二来进行综合分析,刚才我们针对文档一进行分词了,现在来进行针对以下文档二来进行分词:
正排索引是根据文档ID来查询对应的文档内容,倒排索引是根据文档内容中的某一个词语来查询这个词语在那些索引中出现过,而倒排索引的构建过程是依靠遍历正排索引来构建的



四)搜索引擎的处理过程:
1.根据所有文档内容构建倒排索引
1.1)根据的正排索引来进行遍历也就是遍历docID来查找到所有文档内容
1.2)对分别查询到的每一个文档内容来进行分词,比如说取出了文档1,分成了若干个词,现在开始遍历这些词
1.3)创建一个HashMap,Key对应String,value对应List<Integer>
1.4)发现的分词和HashMap中的String中的值相同,就把这个词对应的docID给追加到key对应的list<Integer>里面,如果此时文档中的这一个词在指定的HashMap中没有出现过,那么就把这个put("这个词",这个词出现的第一次的docID),这是第一次在倒排索引中进行插入;
1)此时如果说搜索框里面输入了乔布斯,先去查找倒排索引,查询到文档ID
2)那么需要最终给前端返回的文档就包括文档1和文档2
3)此时再根据文档ID来进行查询到对应的文档信息
整个搜索过程:当有了倒排索引之后,根据用户的查询词就可以快速查询到相关联的文档

五)有了正排索引和倒排索引以后的分词过程:
1)比如说在输入框里面输入小明爱吃苹果,此时先对查询词进行分词,分成小明,爱吃,苹果,然后遍历分词结果依次在倒排索引,倒排搜索之前已经制作好了,在倒排索引当中进行查找
2)这时就查找苹果这个词就在哈希表里面,根据"苹果“这个词就可以根据倒排索引Key查找到对应的文档ID是1和2,这个时候就成功地根据了文档内容来进行查询到了对应的docID;
3)因为此时返回给前端的是一个文档,再根据刚才的docID再来成功的进行查询到了文档内容,就可以把这个根据文档ID查询的文档直接返回给前端了;
六)基于分词的基本思路:
1)基于词典,汉语中一共有4W多个常用字,这些字组成几十万个词,计算机把所有可能成词的词语放到一个词典里面,大约有几十万个词,后面来进行分词的时候,计算机就看看这两个字放在一起是否可以组合出现在词典里面,进行查询词典;
2)基于概率,要统计很多的文本信息,哪两个,三个,四个汉字出现在一起组成的词语的概率比较高大概率就说明是一个词;
3)当前商业公司分词库基本都能达到99%以上的准确率,分词算法一般都是公司的商业机密,可以使用现成的第三方库,虽然不会太准确,但是也够用;
七)简介JAVAAPI文档
JavaAPI有一个线上版本,还有一个可以进行离线下载的版本
下载好线下API文档,分析里面的内容,在搜索结果中填写上若干线上文档结果的链接地址,相当于搜索关键词之后,一进行点击,就可以找到若干个搜索结果,点击其中一个搜索结果,就可以进行跳转到线上文档的链接里面了(直接跳转到线上文档),从下面这个位置开始下载
Java Development Kit 8 Documentation (oracle.com)
1)线上文档链接:https://www.oracle.com/cn/java/technologies/javase-jdk8-doc-downloads.html
2)在线下文档链接里面:直接点击docs里面的api里面的index.html和线上文档一模一样了
线下文档里面:点击api里面的java里面的util里面就有很多的API接口
3)线上文档的链接地址是:https://docs.oracle.com/javase/8/docs/api/index.html
1)假设想要从线下文档里面查询Collection的用法:
C:JavaAPI\docs\api\java\util\Collection.html
2)要想从线上文档里面进行获取到Collection的用法下面:
https:\\docs.oracle.com\javase\8\docs\api\java\util\Collection.html
3)发现这两个目录有一部分是相同的,后面进行分析线下文档的时候,就可以根据当前文档的路径来进行拼接出对应的线上文档的URL
八)项目的模块划分:
1)预处理模块,把下载好的html文档(JavaAPI)进行一次初步的处理,简单分析结构并干掉这里面的html标签,最后成为一个行文本格式的文件,每一行对应着一个文档,使用\3来进行分割,包含了标题,URL和正文,并把这个文件转化成一个文档对象
上面指的JavaAPI文档是指的docus目录下面api目录下面的所有文件html,都要被转换成行文本的格式
2)索引模块:将预处理得到的输出(行文本数据),构建正排+倒排索引这样的数据结构
正排索引:根据文档ID来查询到对应的文档的相关信息,正派索引只是一种约定
倒排索引:根据分词中的词语来进行查找这些词在哪些文档ID中存在,倒排索引可以通过遍历正派索引的方式来构建
3)搜索模块:进行完成一次搜索过程基本流程,从用户输入关键词并得到最终的查询结果过程
4)前端页面:有一个页面,展示结果并让用户输入数据
九)预处理模块:
1)预处理遍历api目录得到所有的html文件:
1)把JAVAAPI里面的目录中的所有HTML进行处理,处理得到一个单个的文件,使用行文本的方式来进行组织,为什么要得到一个单个的行文本呢呢?主要是为了在后续的时候做索引方便,直接按行读取就可以了,后续只要按行读取文件就可以了,制作倒排索引的时候不需要遍历文件就可以,直接读取一个文件
2)遍历所有的list的html文件处理成行文本的格式
1)遍历所有的html文件,把他处理成行文本的格式,每一行对应着一个HTML文档,每一行中又包含三列,第一列表示这个文档的标题,第二列表示这个文档的URL(对应的线上文档版本的url,根据本地的URL来进行拼接),第三列表示这个文档的正文(去掉HTML标签),使用/3来进行分割,因为每一个文档文件都是一个HTML,所以要先得到api目录下面的每一个HTML文件,然后再进行处理,HTML并不是网页的正文内容;
2)当前下载好的JavaAPI文档中的每一个文件用记事本打开都是一个HTML文件,包含着html标签,所以要把所有html标签都过滤掉,这些HTML标签没啥用,去除里面的html标签是为了让搜索结果只集中到文档的正文上面,就不用关心什么body标签,head标签里面的内容,因为这些标签并不是网页正文的内容,所以把它们过滤掉;
package common; //这个包底下存放一些各个功能模块的一些公共属性 //这个类表示一个文档对象,只有有了这些内容我们才可以制作索引,完成搜索内容 public class DocInfo { private int DocID;//表示HTML文档的唯一身份标识,这是不可以重复的 private String title;//该文档的标题,可以使用文件名来进行使用,Collection.html=>collection private String URL; //该文档对应的线上文档的URL,根据本地文件路径可以拼接成先上文档的URL private String content;//表示该文档的正文,表示该文档的正文 //把HTML文件里面的html标签去掉,从而留下的内容 } //上面这些部分就是我们解析文件中提取出来的部分,后续就可以根据这些内容制作索引
1)在JavaAPI目录下有很多级目录,每一个目录底下都包含着html文件,就要写方法实现来进行遍历这些HTML文件,在写循环递归的时候别忘了写终止条件,当执行完这段代码之后,当前api目录下面的所有目录中的html文件就会全部被放到list里面了
//当这个方法递归完毕以后,当前inputPath目录下面的所有子目录中的html文件的路径就被放到fileList这个list中了 public static List<File> GetAllFile(File file,List<File> list) { //循环递归式的将inputPath对应的全部目录和文件都遍历一遍 if(file==null||file.equals("")) { return; } File[] files=file.listFiles(); //相当于是linux里面的命令ls,这就是把当前目录中的所有的文件都罗列出来了,当前目录就是root对象所对应的目录 for(File f:files) { if(f.isDirecty()){ //如果当前f是一个目录那么就递归式的调用enumFile GetAllFile(f, list); }else { //如果当前我们的f不是一个目录,而是一个文件,就查看当前文件的后缀名是不是.html,如果是,就把这个文件对象加入到list里面 if (f.getAbsolutePath().endsWith(".html")) { list.add(f); } } } return list; }
2)创建一个类叫做PreProcess类,用这个类遍历文档目录,读取所有的HTML文档内容,把结果解析成行文本文件每一行都包含着文档标题,文档的URL和文档的内容(去除html标签的内容),这个PreProcess类相当于是一个文档处理类
再进行遍历list中的每一个文件,把他进行设置成行文本的方式,给每一个文件设置成几个属性,标题+线上URL+文档内容,再把这里面的每一个部分放到一个文件里面的一行
进行设置标题的时候:直接把文件名当作标题就行了
进行设置线上URL的时候,本地目录和线上文档目录进行字符串拼接就可以了
进行设置文档的时候,我们要去掉里面的html标签还有\n
public static void main(String[] args) throws IOException { JavaAPI文档的具体路径: //下载好的JAVAAPI文档在哪里 1)private static final String inputpath="C:\Users\18947\Downloads\jdk-8u341-docs-all (1)\docs\jdk\api" //预处理模块所生成的行文本路径在哪里也就是输出的文件目录 2)private static final String outputpath="d:\java.txt"; //通过main方法完整整个预处理的过程 //1.进行枚举出inputPathJavaAPI里面下的所有html文件,通过文件递归的方式,因为JAVAAPI里面既有文件路径和html,html和路径是混杂在一起的,所以不管有几个目录都要找出来 FileWriter fileWriter=new FileWriter(new File(outputpath)); File file=new File(inputpath); List<File> list=new ArrayList<>(); GetAllFile(file,list); System.out.println(list); System.out.println(list.size()); //2.我们进行根据枚举出来的html文件进行遍历,依次打开每一个文件,并读取里面的内容 //再把内容转化成需要的结构化的数据,并转化成DocInfo对象,标题和url和正文,line这个字符串就对应着一个html文件 for(File f:list) { System.out.println("现在这个文件正在转换中"+f.getAbsolutePath()); //注意:我们最后输出的文件应该是一个行文本文件,每一行对应着HTML文件,这个line就包含了每一个HTML文档应该包含的信息 line这个对象就是一个行文本文件里面的内容 String line=Convent(f); fileWriter.write(line); } //3.最终的DocInfo对象放到最终的输出文件outPath里面,写成行文本的方式 fileWriter.close(); }
private static String Convent(File f) throws IOException { //1根据f转换成标题 String Title=ConventTitle(f); // System.out.println(Title); //2根据f转换成线上版本的url; String Url=ConventUrl(f); System.out.println(Url); //3.根据f转换成文章正文,去掉这里面的html标签和换行符,避免转换成行文本的时候出现问题 String Content=ConventContent(f); System.out.println(Content); //4.把这三个部分拼成一个行文本 return Title+"\3"+Url+"\3"+Content+"/n"; //使用\3来进行分割三个同一行数据的效果,是ASCILL码为三的字符 //我们不能拿分号进行分割,你能保证你的正文里面没有分号吗?使用/t中,你能保证你的正文没有空格吗?但是html文档中是不会出现\3的 } //提取正文方法就是一个简单的字符串处理,就是为了把普通的html变成普通的字符串,去掉里面的html标签和换行符 private static String ConventContent(File f) throws IOException { } private static String ConventUrl(File f) { String path="https://docs.oracle.com/javase/8/docs/api"; String resultpath=f.getAbsolutePath().substring(inputPath.length()); return path+resultpath; } private static String ConventTitle(File f) { //把文件名当作标题(去除.html后缀名) //在这里面一定要分别出文件名和全路径的区别,文件名是:"collection.html" //全路径是指:"D://Java100//API/collection.html",相当于是这个文件的父亲目录+这个文件名 //我们去掉最终的.html后缀最为文件名就可以了 return f.getName().substring(0,f.getName().length()-".html".length()); }细致+发散+手黑


0)里面创建一个类,叫做DocInfo,这个Common包是存放各个功能模块可能用到的公共信息
1)这一个DocInfo类表示JavaAPI的一个文档对象表示一个HTML文档,里面包含了文档ID,文档的标题,对应线上文档的URL,还有文档正文;
2)所以要根据线上文档,提取每一个API文档的html文件的属性放到这个对象里面
substring(startIndex,len)从哪一个位置开始,截取多少字符串的长度

处理正文:
采取的方式是一个字符一个字符的来进行遍历,定义一个布尔变量
如果当前的值是true,表明当前读取的内容是html正文,不是标签
如果当前的值是false,表明当前读取到的内容是html标签
如果当前字符是<,就把flag设置成false,把读到的字符全部进行省略
如果当前字符是>,就把flag设置成true,读取到的一个一个的字符就存放到StringBuilder中
读取文件的过程中,如果文件是二进制文件,就是使用字节流,如果文件是文本文件,就使用字符流,如果文件是二进制文件,就使用字节流

十)预处理模块总结:
1)递归方法进行遍历指定目录中的所有的html文件
2)分析每一个html文档的内容,将每一个html文档转化成一个行文本的格式,标题+url+正文,标题直接通过html的标题来截取,url是通过线上文档和线下文档的url关联关系来拼接的
再去除正文的过程中,要干掉里面的html标签和换行符,通过布尔变量来解决
模块思路:
1)通过递归的方式,把当前的api目录下面的所有.html文件放到一个List<File>里面
2)遍历这个list中的文件,解析成行文本的格式,一个文件对应着一个行文本,把若干个行文本文件写到一个文件里面,方便后续进行构建正排+倒排索引,在行文本处理过程中,干掉所有的html标签和换行符,况且文件名和全路径不要搞混了
package com.example.demos.PreprocessingJavaFile; import java.io.*; import java.util.ArrayList; import java.util.List; public class ProcessFile { public static String InputPath="D:/JavaAPI/docs/api/"; public static String outputPath="D:/doc.txt"; //1.得到D public static void GetAllFile(File fatherFile, List<File> files){ File[] Fs=fatherFile.listFiles(); if(Fs==null||Fs.length==0){ return; } for(File f:Fs){ if(f.getAbsolutePath().endsWith(".html")){ files.add(f); }else{ GetAllFile(f,files); } } } public static String ConventContent(File f) throws IOException { FileReader reader=new FileReader(f); boolean flag=false; StringBuilder builder=new StringBuilder(); while(true){ int ch= reader.read(); if(ch==-1){ break; } if(flag==true){ if(ch=='<') { flag=false; continue; } if(ch=='\n'||ch=='\r') ch=' '; builder.append((char)ch); }else{ if(ch=='>'){ flag=true; } } } return builder.toString(); } public static void main(String[] args) throws IOException { //1.处理获取到指定路径下面的所有文档 List<File> list=new ArrayList<>(); GetAllFile(new File(InputPath),list); System.out.println(list.size()); //2.遍历这些文档,把他处理成行文本的格式 FileWriter writer=new FileWriter(new File(outputPath)); int count=0; for(File file:list){ System.out.println(file.getAbsoluteFile()+"长在处理中"+count); String line=ConventHTMLFile(file); writer.write(line); writer.flush(); count++; } writer.close(); } private static String ConventHTMLFile(File file) throws IOException { String title=ConventTitle(file); String content=ConventContent(file); String url=ConventUrl(file); return title+"\3"+url+"\3"+content+"\n"; } private static String ConventUrl(File file) { String fatherUrl="https:/docs.oracle.com/javase/8/docs/api/"; String resultUrl=fatherUrl+file.getAbsolutePath().substring(InputPath.length()); // System.out.println(resultUrl); return resultUrl; } private static String ConventTitle(File file) { return file.getName().substring(0,file.getName().length()-".html".length()); } }

十一)索引模块
1)使用第三方库来分词:
制作索引模块:根据行文本文件,创建正排索引和倒排索引
1.要引入分词的第三方库,在这里面使用的就是ansj,还要安装对应的jar包
<dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.11</version> <scope>test</scope> </dependency> <dependency> <groupId>org.ansj</groupId> <artifactId>ansj_seg</artifactId> <version>5.1.6</version> </dependency>2)为了验证它是否可以实现分词,写一个测试代码来进行验证
通过调用ToAnalysis.parse(传入的字符串)就可以完成分词
调用getTerms()就可以获取到分词结果
分词库分词英文的时候会自动将英文单词转化成小写,在结果中,如果直接打印term,就会出现词性等相关信息,如果想要忽略这些信息,就可以直接进行打印term.getName(),这就会直接显示我们要进行分的词,但是还是小写
import org.ansj.domain.Term; import org.ansj.splitWord.analysis.ToAnalysis; import java.util.List; public class TestAll { public static void main(String[] args) { String str="我毕业于内蒙古工业大学"; List<Term> list= ToAnalysis.parse(str).getTerms(); for(Term term:list) { System.out.println(term.getName()); } } }
2)理解正排索引和倒排索引:
索引类需要包含两方面的内容,正排索引和倒排索引
正排索引是根据文档ID来查询文档内容:
private List<DocInfo> forwordIndex=new ArrayList<>();倒排索引是根据文档中的一个词来查询文档ID
private HashMap<String,List<Integer>> invertedIndex=new ArrayList<>();HashMap<String,ArrayList<Integer>>可以吗?不太行,想要的是不光这个词在那些文档中出想过,还想知道这个词在每一个对应文档中的权重是多少?
之前咱们想返回一个简单的文档ID,但是此时返回的是权重信息,此时就不能返回Integer了
为啥是一个List<Weight>数组,因为一个词在不同的文章中出现过,一个文章中也可能有多个词,词找文档ID再找权重信息,三者是一一对应的;

3)权重的理解:
1)但是所设计的倒排索引不光想知道这些词在那些文档中出现过,还想要知道这个词在文档中的权重是多少,权重指的是词和该文档之间相关的程度,相关程度越高,权重就越大,本身是一个整数,后续排序的时候会使用到,因为本身如果在网站上输入一个内容,排在最前面的是相关性最强的;
2)实际的商业搜索引擎中是根据查询词和文档之间的相关性来进行降序排序,网站会把相关程度很高的文档排在前面,相关程度越低的,就越靠后,这是和用户的需求相对应的,用户的体验也就越好,但是相关性这是一个很大的话题,有一个专门的岗位叫做算法工程师来做这个事情
3)此处就是使用简单粗暴的方式来进行相关性的衡量,就看这个词语在文档中的出现次数,出现次数越多,就认为相关性越强,只能通过词频来衡量,词在标题中出现,就应该要相关性比在正文中出现更强一些,比如说用户本身输入了一个ArrayList,但是在最终实际结果的展示中,就应该把ArrayList.html的信息展示在列表中比较靠前的位置,因为本身用户想要查询的是ArrayList的用法,所以可以此处进行设置一个简单的公式来进行描述权重,weight=这个词在标题里面出现的次数*10+在文章正文里面出现的次数,但是相关性是一个很大的话题(文章属性+用户信息),是有专门的算法工程师来进行运算的,但是实际上有很多很多的维度来描述相关性,还有文章属性和用户特征来综合衡量;

4)编写Index类对于向上暴露的接口:
1.1)创建一个包,叫做index,创建一个类叫做OperateIndex类,他想上暴露的是两个接口
正排索引,根据文档ID查询文档信息,倒排索引,根据文章信息查询权重信息(文档ID)
1.2)其次还有一个方法buildIndex,构建正排索引和倒排索引,这个方法的作用就是根据预处理模块得到的行文本数据,构建正排和倒排索引,加载到内存中的数据结构里面
正排索引:读取当前的行文本数据,构建文档对象,插入到数组当中
倒排索引:根据正派索引来构建
//word这个词在文档中所占的权重是多少 static public class Weight{ public String word; public int DocID; public int weight; } 一个词会有多个Weight对象,每一个词,在每一个文章里面都对应着一个weight对象,举个例子: collection Weight对象----针对文档一:{ word:weight, DocID:1 weight:90 } Weight对象----针对文档二:{ word:weight, DocID:2 weight:70 }


5)构建正排索引:List<Document>
1)打开文件,并且读取行文本文件(可以多个线程读多个文件),尝试读取每一行
2)会构建正排索引的过程:读取到的每一行按照\3来进行分割,针对切分结果构建DocInfo对象3)并加入到正排索引里面(List<DocID,DocInfo>)
4)构建倒排的过程,要先进行遍历正排索引,针对刚才构建的DocInfo对象,DocInfo里面的内容进行进一步处理

1)如果分成的String[]的长度不等于三,直接进行返回;
2)如果在进行构建正排索引的时候发现文件格式有问题,该如何进行解决呢?
不应该让某一个问题来影响到索引构建过程,而是我们直接返回,打印日志3)正派索引的创建的过程中,文档ID如何指定,就使用正排索引的数组下标充当文档ID,虽然之前预处理的过程中的行文本的数据并没有docID,但是可以使用正排索引的数组下标充当docID,可以把新的循环处理的每一行数据构造成docInfo对象,再把docInfo对象插入到数组末尾,如果数组本身是0个元素,那么新的元素所处于的下标就是0
4)在实际开发中多线程同时读取一个文件是很少见的,因为涉及到同一个文件的读取要涉及到光标的控制,没有办法做到完全并行,因为本身多个线程要竞争同一个光标,但是多线程同时读取多个文件是可能的,多个线程多个光标比较好;
public void BuildIndex(String inputPath) throws IOException { long StartTime=System.currentTimeMillis(); System.out.println("开始构建正排索引和倒排索引"); //1.获得文件读取的对象 BufferedReader bufferedReader=new BufferedReader(new FileReader(inputPath)); //2.循环读取文件 while(true){ String line=bufferedReader.readLine(); if(line==null){ break; } //我们读取一行,分出来的三个部分就是一个文档的标题,正文,URL String[] strings=line.split("\3"); if(strings.length!=3){ System.out.println("当前文件格式有问题"); //当前我们文件格式出问题了,我们是应该终止程序还是进行忽略呢?当前场景下有1W多个文件,如果某一个文件格式出现了问题,我们是不应该让 //某一个文件的错误来进行影响到整体的索引结构 continue; } Document document=new Document(); document.Title=strings[0]; document.url=strings[1]; document.content=strings[2]; document.DocID=forwordIndex.size(); //直接把Document对象放在数组的最后一个位置,此时正排索引构建完成 forwordIndex.add(document); //构建这个文档的倒排索引 CreateBackWordIndex(document); } long EndTime=System.currentTimeMillis(); System.out.println("构建正派索引和倒排索引的工作完成,消耗时间"+String.valueOf(EndTime-StartTime)); bufferedReader.close(); }
6)构建倒排索引:
倒排索引的结构:
每一个分词里面都对应着一个List<Weight>,每一个List<Weight>里面都对应着多个weight对象,每当查询词在一个文档中出现过,ArrayList<Weight>里面追加一个weight对象
构建倒排索引的时机:构建倒排索引方法传入Document对象,要根据传递过来的Document对象中的文章标题和文章内容来进行分词,再根据分词结果来进行构建出Weight对象;
1)先根据标题来进行分词;
2)进行遍历标题分词结果,统计标题中每一个单词出现的次数;
3)再来根据正文进行分词;
4)遍历正文分词结果,统计正文中每一个单词出现的次数;
文章的每一个词在标题中的出现次数和在正文中的出现次数都使用这个WordCount类来进行处理
class WordCount{ public int TitleCount; public int ContentCount; public WordCount(int titleCount, int contentCount) { TitleCount = titleCount; ContentCount = contentCount; } }5)把这两部分的结果来整理到一个HashMap里面,HashMap<String,WordCount>,词就是key,value就是标题中的出现次数+正文中的出现次数,这个WordCount又是一个类,里面统计的是这个词在文章正文中出现的次数和在文章标题中出现的次数
6)遍历HashMap,依次构建Weight对象并且更新索引的映射关系;

private void CreateBackWordIndex(Document document) { //1.现根据文章标题来进行分词 List<Term> TitleList= ToAnalysis.parse(document.Title).getTerms(); //2.遍历分词结果,统计标题中每一个词出现的权重 HashMap<String,WordCount> CountMap=new HashMap<>(); for(Term term:TitleList){ String TermData=term.getName(); WordCount wordCount=CountMap.get(TermData); if(wordCount==null){ //当前这个词在HashMap中不存在 wordCount=new WordCount(1,0); CountMap.put(TermData,wordCount); }else{ //当前这个词在哈希表中存在 wordCount.TitleCount++; } } //3.再根据文章内容来进行分词 List<Term> ContentList=ToAnalysis.parse(document.content).getTerms(); //4.遍历分词结果,再去统计这个词在正文中出现的次数 for(Term term:ContentList){ String ContentData=term.getName(); WordCount wordCount= CountMap.get(ContentData); if(wordCount==null){ //当前这个词在哈希表中不存在 wordCount=new WordCount(0,1); CountMap.put(ContentData,wordCount); }else{ //当前这个词在Hash表中存在 wordCount.ContentCount++; } } //5.遍历HashMap,创建Weight对象,依次构建Weight对象 for(Map.Entry<String,WordCount> entry:CountMap.entrySet()){ String key= entry.getKey(); WordCount wordCount= entry.getValue(); Weight weight=new Weight(); weight.DocID=document.DocID; //标题出现次数*10+正文中出现次数 //我们要将weight加入到倒排索引中,倒排索引是一个HashMap,value就是由weight组成的ArrayList,根据这个词,我们就要先找到这个词对应的 //ArrayList weight.weight= wordCount.ContentCount+ wordCount.TitleCount*10; weight.word=key; ArrayList<Weight> weights= (ArrayList<Weight>) backwordIndex.get(key); if(weights==null){ //当前键值对不存在 weights=new ArrayList<>(); weights.add(weight); backwordIndex.put(key,weights); }else{ //到了这一步,就有一个合法的ArrayList weights.add(weight); } } }

创建索引模块的时候出现的问题:
1)读取行文本格式的数据的时候,转化成String格式的字符串数组之后,如果发现字符数组的长度不是3,那么说明这个行文本有问题
2)咱们调用List<Term> TitleList= ToAnalysis.parse(document.Title).getTerms();得到的每一个Term对象里面包括了分词之后词的名字还有词的词性,通过term.getName()就可以得到词的具体内容了,况且里面的单词已经被转成小写了
3)这里面的HashMap<String,WordCount> map=new HashMap<>();应该是局部变量,是用来进行统计当前文档的词在这个文章中的标题和正文中出现了几次,而咱们的HashMap<String,Weight>应该是全局变量;
1)由于索引中的词全部是小写的,那么进行查询的词也必须全部是小写的
2)现在进行测试一下正排索引和倒排索引的构建过程,arraylist为例来进行查询一下词语
3)后来发现了错误,你前面进行文件分割的时候一定不能分割错误:
Index index=new Index(); //1.先进行创建索引 index.BuildIndex("D:\\SelectAPI\\Result.txt"); //2.开始模拟进行搜索,先找到这个词对应的权重信息,相当于先进行查找倒排索引 ArrayList<Weight> list= (ArrayList<Weight>) index.GetInverted("arraylist"); for(Weight weight:list){ System.out.println(weight.DocID); System.out.println(weight.weight); System.out.println(weight.word); //3.进行查找正排索引,可以看出weight中必须含有文档ID Document document= index.GetDocInfo(weight.DocID); System.out.println(document.getTitle()); System.out.println(document.getUrl()); System.out.println("________________________"); }
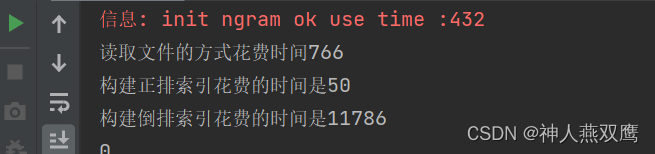
public void BuildIndex(String inputPath) throws IOException { class Timer{ public long readFileTime; public long buildForwardTime; public long buildBackwardTime; } Timer timer=new Timer(); System.out.println("开始构建正排索引和倒排索引"); //1.获得文件读取的对象 BufferedReader bufferedReader=new BufferedReader(new FileReader(inputPath)); //2.循环读取文件 while(true){ long t1=System.currentTimeMillis(); String line=bufferedReader.readLine(); if(line==null){ break; } long t2=System.currentTimeMillis(); //我们读取一行,分出来的三个部分就是一个文档的标题,正文,URL String[] strings=line.split("\3"); if(strings.length!=3){ System.out.println("当前文件格式有问题"); //当前我们文件格式出问题了,我们是应该终止程序还是进行忽略呢?当前场景下有1W多个文件,如果某一个文件格式出现了问题,我们是不应该让 //某一个文件的错误来进行影响到整体的索引结构 continue; } Document document=new Document(); document.Title=strings[0]; document.url=strings[1]; document.content=strings[2]; document.DocID=forwordIndex.size(); //我们直接把Document对象放在数组的最后一个位置 forwordIndex.add(document); //构建这个文档的倒排索引 long t3=System.currentTimeMillis(); CreateBackWordIndex(document); long t4=System.currentTimeMillis(); timer.readFileTime+=t2-t1; timer.buildForwardTime+=t3-t2; timer.buildBackwardTime+=t4-t3; } System.out.println("读取文件的方式花费时间"+timer.readFileTime); System.out.println("构建正排索引花费的时间是"+timer.buildForwardTime); System.out.println("构建倒排索引花费的时间是"+timer.buildBackwardTime); bufferedReader.close(); }
package com.example.demos.BackAndBuildBuilder;
import lombok.Data;
import org.ansj.domain.Term;
import org.ansj.splitWord.analysis.ToAnalysis;
import java.io.*;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
class Timer{
public long readFileTime;
public long buildForwardTime;
public long buildBackTime;
}
public class Index {
Timer timer=new Timer();
//word这个词再对应的docID对应的文章中对应的权重是多少
@Data
static class Weight{
public int docID;
public String word;
//此时的计算公式是文章中出现的次数+标题中出现的次数*15
public int weight;
}
private List<DocInfo> forwardList=new ArrayList<>();
private HashMap<String,List<Weight>> backwardMap=new HashMap<>();
//1.查询正排索引
public DocInfo getForwardList(Integer docID){
return forwardList.get(docID);
}
//2.查询倒排索引
public List<Weight> getBackWordWeight(String term){
return backwardMap.get(term);
}
//3.构建正排索引和倒排索引,八行文本中的数据读取出来,加载到内存中的数据结构里面
public void BuildIndex(String inputPath) throws IOException {
Long startTime=System.currentTimeMillis();
System.out.println("构建索引开始");
BufferedReader reader=new BufferedReader(new FileReader(new File(inputPath)));
while(true){
long t1=System.currentTimeMillis();
String line=reader.readLine();
long t2=System.currentTimeMillis();
if(line==null||line.equals("")) break;
DocInfo docInfo=createForWordIndex(line);//构建正排索引
long t3=System.currentTimeMillis();
createBackWordIndex(docInfo);//创建该文档的倒排索引
long t4=System.currentTimeMillis();
System.out.println("此时"+docInfo.getDoctitle()+"正排和倒排索引创建完成");
timer.readFileTime+=t2-t1;
timer.buildForwardTime+=t3-t2;
timer.buildBackTime+=t4-t3;
}
long endTime=System.currentTimeMillis();
System.out.println("构建索引结束"+(endTime-startTime)+"毫秒");
System.out.println("readFileTime"+timer.readFileTime+",buildForwardTime"+timer.buildForwardTime+",buildBackForWardTime"+timer.buildBackTime);
reader.close();
}
private DocInfo createForWordIndex(String line) {
String[] strings=line.split("\3");
if(strings.length!=3){
System.out.println("当前这一行数据不符合行文本的结果");
return null;
}
//把这一行按照/3来进行分割,分割出来的三个部分就是标题,url和正文
DocInfo docInfo=new DocInfo();
docInfo.setDocId(forwardList.size());
docInfo.setDocconent(strings[2]);
docInfo.setDocurl(strings[1]);
docInfo.setDoctitle(strings[0]);
forwardList.add(docInfo);
return docInfo;
}
private void createBackWordIndex(DocInfo docInfo) {
//统计对应的词在文章中标题和正文中出现的次数
@Data
class WordCount{
public int TitleCount;
public int ContentCount;
public WordCount(int TitleCount,int ContentCount){
this.TitleCount=TitleCount;
this.ContentCount=ContentCount;
}
}
HashMap<String,WordCount> wordCountHashMap=new HashMap<>();
//1.遍历文章的标题进行分词,针对于文章的标题进行分词以后,统计每一个词在标题中出现的次数记录到WordCount中的titleCount里面
String title= docInfo.getDoctitle();
List<Term> Titlelist=ToAnalysis.parse(title).getTerms();
for(Term term:Titlelist){
//此时的word已经被转化成小写了
String word=term.getName();
WordCount wordCount=wordCountHashMap.get(word);
if(wordCount!=null){
//当前这个词已经在文章中出现过了
wordCount.TitleCount++;
}else{
//当前这个词在哈希表中不存在,也就是说当前这个词第一次在文章中出现
WordCount newWordCount=new WordCount(1,0);
wordCountHashMap.put(word,newWordCount);
}
}
//2.遍历文档的所有内容进行分词,然后统计每一个词在正文中出现的次数记录到WordCount中的contentCount里面
String content=docInfo.getDocconent();
List<Term> list=ToAnalysis.parse(content).getTerms();
for(Term term:list) {
String word = term.getName();
WordCount wordCount = wordCountHashMap.get(word);
if (wordCount != null) {
wordCount.ContentCount++;
} else {
//这个词之前在文章中没有出现过,在正文中是第一次出现
wordCount=new WordCount(1, 0);
wordCountHashMap.put(word, wordCount);
}
}
//3.根据HashMap<String,WordCount>来创建倒排索引HashMap<String,List<Weight>>
for(Map.Entry<String,WordCount> entry:wordCountHashMap.entrySet()){
String key=entry.getKey();
WordCount wordCount=entry.getValue();
Weight weight=new Weight();
//标题中出现次数*10+正文中的出现次数
weight.setWeight(wordCount.getContentCount()+wordCount.getTitleCount()*10);
weight.setDocID(docInfo.getDocId());
weight.setWord(key);
List<Weight> weights=backwardMap.getOrDefault(key,null);
if(weights==null){
//表示这个词是第一次出现在倒排索引中,倒排是一个HashMap,value就是一个Weight构成的ArrayList,要根据这个词先找到HashMap对应的ArrayList
weights=new ArrayList<>();
weights.add(weight);
backwardMap.put(key,weights);
}else{
//表示这个词之前已经在别的文档中出现过了
//weights是倒排拉链
weights.add(weight);
}
}
}
//下面这个是测试代码用来测试正排索引和倒排索引的构建是否正确
public static void main(String[] args) throws IOException {
Index index=new Index();
index.BuildIndex("D:/Doc.txt");
// 由于索引的key都是小写的,所以此时查询的词必须全是小写的
List<Index.Weight> list=index.getBackWordWeight("arraylist");
System.out.println(list);
for(Index.Weight weight:list){
System.out.println(weight.getWeight() + weight.getDocID() + weight.getWord()+"\n");
DocInfo info=index.getForwardList(weight.docID);
System.out.println(info.getDocconent());
}
}
}
构建正排索引和倒排索引的过程就是只在服务器启动之后一次之后进行构建,构建索引很慢,那么服务器启动就会很慢;
1)构建索引模块还是需要进行优化的,索引构建过程,每一次服务器启动的时候,就要进行构建索引,这样就会导致隐患,线上服务器是7*24小时运行,服务器当即又是不可避免的,出现宕机能够快速恢复,就能把损失将降低最小,如果服务器宕机又进行重启,在几秒内重新启动,损失也就损失几秒钟,其实影响就不大,如果此时宕机好长时间,此时损失就非常明显了
2)如何优化索引模块的构建时间呢?思路还是和原来一样,需要要找到性能瓶颈才能优化,给核心模块步骤都加上时间,(第一步读文件,第二部构建正排,第三步构建倒排)但是创建正排索引和创建倒排索引的过程都是在while循环,再进行读文件的时候进行的,不应该在大的循环中进行加入过多的打印信息,一方面打印信息很多看起来会很不方便,况且另一方面打印函数本身也是有时间消耗的,此时测试的时间结果就不准确
3)可以通过创建一个时间类来进行记录每一个重要模块所执行的时间,发现构建倒排索引的过程中的分词操作的性能瓶颈最长,给构建倒排索引的每一个过程中也加上时间记录,进行统计,分次操作花费多长时间?这三个执行时间就可以通过做减法的方式得到
要想此时分析构建倒排索引的性能瓶颈此时应该构建倒排索引的每一段时间进行执行打印操作,也统计构建标题,构建正文需要多长时间,可以把每一个环节计划记录一个更详细的时间
构建倒排的代码中,性能瓶颈在于分词操作上,尤其是针对正文分词时间最长,分词本身是一个很复杂的逻辑,分词操作是性能瓶颈
分析原因:分词本身就是一个很复杂的操作;
4)解决方案:因为文档内容固定,分词结果也是固定的,完全可以在预处理模块把标题和正文分词好,存好在一个文件里面,后续服务器在进行构建索引,直接加载分词结果就可以了,不需要重复进行分词,预处理阶段就把分词分好写到文件里面;

十二)搜索模块目标:从前到后的搜索功能处理完成
1)分词:针对前端用户输入的查询词进行分词,因为用户输入的一段话里面有很多词语
2)触发:进行遍历分词结果,去倒排索引中查找和所有这个分词结果相关的记录,这时候出来一大堆Weight对象,进行查询的每一个词所得到的Weight数组都要放到一个大的集合里面(List),因为每一个Weight都对应着一个词,每一个词都对应着一个DocID,每一个DocID都对应着一个DocInfo对象;
3)排序:根据相关性高低,根据weight中的weight大小对List进行降序排序
4)相关性包装结果:遍历List,取出里面的所有Weight,得到DocID
5)把刚才的DocID所对应的DocInfo信息(正排索引中查找到DocIfo对象)查找到,组装成一个响应数据,返回给前端
从用户输入查询词到整个结果的开发:
1)进行创建一个包,创建一个类,表示查询的结果,里面包含了查询文章的标题,展示URL,点击URL,文章内容(包含关键词或者关键词的一部分)(点击URL和展示URL的内容是一样的),这个类是根据正排索引中的DocInfo得到的;
2)在从这个包里面进行创建一个类,通过这个类完成核心搜索过程,来进行提供一个方法,期望的就是根据用户进行输入的查询词(String类型)来返回最终的一个搜索结果(List<Info>)

如何设置返回结果的正文?
1)在进行设置返回结果的正文的时候,并不是将所有的DocInfo对象的正文内容返回给前端,而是从正文中摘取一段摘要信息
2)这个摘要的规则是:
2.1)先根据这个词来查找到正文的位置,调用IndexOf方法来查询
weight中的内容是一个查询词(小写),weight中的词是从分词结果中来的
DocInfo中的Content的内容是大写的,因为真的这部分内容是直接从行文本文件中进行读取的,没有涉及到分词操作,就不会自动转化成小写)
2.2)IndexOf方法查询不到具体的位置,极端情况下,说明这个词只在标题中出现过,但是在正文中没有出现过,所以在正文中肯定找不到了,如果成功进行查询,就记住位置是FirstPos;2.3)从FirstPos里面向前找60个字符,作为描述的开始,如果说前面不足60个,那么就从正文头部开始
2.4)从FirstPos像后面开始找100个字符作为描述内容,如果说后面不足100个字符,那就把后面的都算上
Result类:public class Result { public String ClickURL; public String ShowURL; public String Title; public String Content; public String getClickURL() { return ClickURL; } public void setClickURL(String clickURL) { ClickURL = clickURL; } public String getShowURL() { return ShowURL; } public void setShowURL(String showURL) { ShowURL = showURL; } public String getTitle() { return Title; } public void setTitle(String title) { Title = title; } public String getContent() { return Content; } public void setContent(String content) { Content = content; } }import org.ansj.domain.Term; import org.ansj.splitWord.analysis.ToAnalysis; import java.io.IOException; import java.util.ArrayList; import java.util.Collections; import java.util.Comparator; import java.util.List; //通过这个类来进行完成搜索过程 public class SearcherServlet { public static Index index=new Index(); public SearcherServlet() throws IOException { //进行搜索之前,我们要先进行创建好正排索引和倒排索引 index.BuildIndex("D:\\\\SelectAPI\\\\Result.txt"); } public static List<Result> Search(String query){ List<Weight> resultWeight=new ArrayList<>(); List<Result> results=new ArrayList<>(); //1.现根据我们的查询词进行分词 List<Term> list=ToAnalysis.parse(query).getTerms(); //2.根据查询出来的每一个词,找到我们的倒排索引 for(Term term:list){ //此时的data就是小写的 String data=term.getName(); ArrayList<Weight> weights= (ArrayList<Weight>) index.GetInverted(data); //在这里面我们要注意一个问题,我们此时不知道用户输入的查询词是什么,很可能无法查询到对应的倒排索引 if(weights==null){ continue; } resultWeight.addAll(weights); } //3.排序根据weight权重进行排序 Collections.sort(resultWeight, new Comparator<Weight>() { @Override public int compare(Weight o1, Weight o2) { return o2.weight- o1.weight; } }); //4.依据我们倒排索引中的weight找到对应的文档ID for(Weight weight:resultWeight){ Result result=new Result(); //5.根据文档ID查询到正排索引,查询到文档内容,封装成Result对象 Document document= index.GetDocInfo(weight.DocID); result.Title= document.Title;; result.ClickURL= document.url; result.ShowURL=document.url; //这个方法做的是主要是从正文中摘取一段摘要信息,根据当前的这个词,找到在正文中的一部分片段,把这个片段周围位置的词都获取到,然后返回位置给前端 result.Content=Procession(document,weight.word);//这就是前面我们为什么要向Weight中添加word属性 results.add(result); } return results; }
import org.ansj.domain.Term; import org.ansj.splitWord.analysis.ToAnalysis; import java.io.IOException; import java.util.ArrayList; import java.util.Collections; import java.util.Comparator; import java.util.List; //通过这个类来进行完成搜索过程 public class Searcher { public static Index index=new Index(); public Searcher() throws IOException { //进行搜索之前,我们要先进行创建好正排索引和倒排索引 index.BuildIndex("D:\\\\SelectAPI\\\\Result.txt"); } public static List<Result> Search(String query){ List<Weight> resultWeight=new ArrayList<>(); List<Result> results=new ArrayList<>(); //1.现根据我们的查询词进行分词 List<Term> list=ToAnalysis.parse(query).getTerms(); //2.根据查询出来的每一个词,找到我们的倒排索引 for(Term term:list){ //此时的data就是小写的 String data=term.getName(); ArrayList<Weight> weights= (ArrayList<Weight>) index.GetInverted(data); //在这里面我们要注意一个问题,我们此时不知道用户输入的查询词是什么,很可能无法查询到对应的倒排索引 if(weights==null){ continue; } resultWeight.addAll(weights); } //3.排序根据weight权重进行排序 Collections.sort(resultWeight, new Comparator<Weight>() { @Override public int compare(Weight o1, Weight o2) { return o2.weight- o1.weight; } }); //4.依据我们倒排索引中的weight找到对应的文档ID for(Weight weight:resultWeight){ Result result=new Result(); //5.根据文档ID查询到正排索引,查询到文档内容,封装成Result对象 Document document= index.GetDocInfo(weight.DocID); result.Title= document.Title;; result.ClickURL= document.url; result.ShowURL=document.url; //这个方法做的是主要是从正文中摘取一段摘要信息,根据当前的这个词,找到在正文中的一部分片段,把这个片段周围位置的词都获取到,然后返回位置给前端 result.Content=Procession(document.content,weight.word);//这就是前面我们为什么要向Weight中添加word属性 results.add(result); } return results; } private static String Procession(String content,String word) { //1.查找word在content中出现的位置,但是这里面的Content是大小写都有,所以我们要统一成全部是小写,在进行查找 int index=content.toLowerCase().indexOf(word); //2.我们有可能出现index查询不到的情况,这种情况就是极端情况下,某一个词只在标题中出现,而没有在正文中出现 if(index==-1){ return ""; } //从index向前找60个字符,如果不足60个字符,就从正文头部开始 int firstPos=index<60?0:index-60; //从first向后找160个字符,如果大于整个正文的长度全部进行返回 if(firstPos+160>content.length()){ return content.substring(0,content.length()); } //否则就从开始位置向后找160个字符 return content.substring(firstPos,firstPos+160)+"......."; } public static void main(String[] args) throws IOException { Searcher searcherServlet=new Searcher();//构建这个对象就相当于是构建了索引模块 List<Result> list=searcherServlet.Search("ArrayList"); for(Result result:list){ System.out.println(result); } } }
private static String Procession(String content,String word) { //1.查找word在content中出现的位置,但是这里面的Content是大小写都有,所以我们要统一成全部是小写,在进行查找 int index=content.toLowerCase().indexOf(word); //2.我们有可能出现index查询不到的情况,这种情况就是极端情况下,某一个词只在标题中出现,而没有在正文中出现 if(index==-1){ return ""; } //从index向前找60个字符,如果不足60个字符,就从正文头部开始 int firstPos=index<60?0:index-60; //从first向后找160个字符,如果大于整个正文的长度全部进行返回 if(firstPos+160>content.length()){ return content.substring(0,content.length()); } //否则就从开始位置向后找160个字符 return content.substring(firstPos,firstPos+160)+"......."; }针对搜索模块的测试:
1)针对某个查询词,看看搜索出来的结果是否都包含指定查询词
2)针对搜索结果,是否按照权重来进行排序
3)针对搜索结果,里面包含的标题,url,描述是否正确
4)URL是否可以成功的进行跳转
5)描述是否包含指定的词
6)搜索结果的数目是否符合预期,搜索时间是否符合预期
7)描述前面比较短的情况
8)描述后边比较短的情况
9)描述中是否带有...
做这个项目的时候要注意几件事情:
1)一定要创建Searcher对象,因为已经在Seacher类构造方法里面进行了构建索引的过程,如果直接调用方法查询可能会出现错误,索引都还没有构建呢,可能会出现查询错误
2)在文章中查询查询词的时候,可能查询不到,因为这个词只在标题中出现过,没有在正文中出现过
在实际开发中要将需求梳理清楚,再来根据代码中的细节,就可以设计出很多的测试用例,等价类,边界值,因果图
十三)搜搜模块的开发
Servlet后端代码的开发:搜索模块中的核心的搜索类,已经完成了,现在要做的事情就是把搜索类放到一个服务器里面,让服务器来进行搜索过程,调用搜索类里面的方法,应该创建一个服务器,来进行调用后端接口;
1)当前如果将项目打包部署到linux服务器上面,当前打的war包肯定不能直接放到linux上面去执行,Tomact本身会创建新的Servlet实例,Servlet实例本身又包含着Searcher对象的实例,又包含了Index的实例并且需要build,build本身又依赖了一个预处理得到的文件,这个时候直接把war包放到linux服务器是不行的,需要把预处理得到的文件也部署上去,并且要把build的路径写对
2)为什么之前咱们已经有一个文档Document对象了,为什么还要进行创建一个result对象呢?因为result对象里面有展示URL和点击URL,况且返回的不是一个完整的docInfo中的content,而是content内容的一部分,为什么weight字段里面要包含查询词,来一个权重信息进行排序,来一个DocID找到文档,查询词是为了后续创建Result对象的时候,返回content一部分来这个词定位文章中的位置的,因为后需要进行遍历weight,用户输入多个查询词,不知道具体的查询词是什么,所以要在weight中进行指定查询词
还是要进行约定前后端的交互接口:
请求:GET/search?query="我们前端的搜索词"
响应:通过Json来进行组织,返回的是一个Json数组,返回的是我们的一个个Result对象
[ { title:"我是标题", showURL:"我是展示URL", clickURL:"我是点击URL", content:"我是描述信息", }, { title:"我是标题", showURL:"我是展示URL", clickURL:"我是点击URL", content:"我是描述信息", } ]1)当我们把项目war包部署到Tomact之后,发现在收到第一次请求的时候,才触发了构建索引(正排索引+倒排索引),创建Servlet实例之后,在处理请求的代码里面创建了Search对象,而Searcher里面构建触发了索引的构建,index.bulid构建,第一次响应时间就很长,Servlet实例的创建是一个懒加载的过程,咱们的Servlet实例并不是在Tomact一启动的时候就进行实例化,而是在收到第一个请求之后才进行实例化操作,不能让第一次请求时间太久
2)解决方案,应该进行Tomact服务器启动的时候就进行创建,而不是等到收到请求之后才创建Servlet实例,才去创建索引,只需要修改web.xml里面的配置就行了;
只需要在web.xml里面加上一个标签,Tomact在一进行启动的时候就进行创建Servlet实例;
3)当前这个war是不可以放在linux上运行的,因为Tomact肯定会进行创建Servlet实例,Servlet实例里面又包含了Searcher对象的实例,Searcher对象里面的实例又包含了index的实例并且需要进行build,build又依赖了一个行文本文件
<load-on-startup>1</load-on-startup>
1)加上了这个标签之后目的是:让服务器已进行启动就创建对应的Servlet的实例,如果标签里面的值小于等于0,表示收到请求才进行Servlet的实例化2)如果说这个值大于0就表示服务器启动就立即进行实例化,当这个值大于0的时候,这个值越小,就越先进行加载

3)本质上来说就是第一次响应时间太长了,应该让我们的服务器已进行启动就创建Servlet的实例,实例创建好了,索引构造完了,其实后面的响应就快了
但是说在Tomact服务器加载过程中,用户的请求就来了怎么办?此时页面加载就会变得非常慢
0)Servlet实例还没有创建好,后端程序就无法进行处理Http请求,后端就无法返回响应数据,必须等到Servlet实例进行创建好,才可以进行处理请求,这个时候就可以告诉用户,我还没初始化完呢,请等一下
1)其实在实际的搜索引擎中,会把整个系统拆分成不同的服务器,HTTP服务器+搜索服务器,这样就做到各自独立去进行重启,(搜索服务器需要加载索引,启动速度比较慢,这样的情况下,如果在搜索服务器启动的过程中,HTTP请求就来了,HTTP服务器就会告诉用户,我们还没准备好,搜索服务器还没有启动好);
2)但是实际上,搜索服务器通常有多台,重启不至于把所有的服务器都重启,总会留下一些可以正常工作的搜索服务器,就能保证HTTP服务器始终会得到想要的结果
3)在工作当中使用的都是分布式的系统,拆分成多台服务器就可以保证有一台服务器出现问题就可以保证不至于影响全局
发现这里面还是有一个问题:当项目部署到Tomact服务器上面,发现总时间达到了45s,但是我们在Tomact看到读取文件的时间,构建正排索引倒排索引的总时间还是要比它小的,那么时间去哪里了?在idea上面还是一致的
在这里面还有一个Bug,在IDEA里面打印日志的时间就很短(System打印),而咱们的Tomact上行打印日志,时间就比较久
这就取决于打印日志的缓冲策略,众所周知,访问内存的速度永远是比访问磁盘的速度快的,我们平时在和磁盘交互的时候是有缓冲区的,当写磁盘的时候,会把很多数据积累在一起一块写,一起来进行刷新;
3)在Tomact里面,是行缓冲,在每一次打印换行都会刷新缓冲区,咱们在一直进行换行,所以就在就在频繁一直访问磁盘,而我们的构建倒排的过程就是在操作内存
4)Idea是全部缓冲,打印换行不会影响到刷新缓冲区,但是在Tomact里面执行,打印时间太久,每一次打印都会刷新缓冲区,频繁访问磁盘,所以我们应该把日志直接去掉,所以打印日志还是对整体程序执行效果会有影响的
5)性能优化的前提就是根据测试结果找到性能瓶颈,因此优化手段就是直接把日志去掉,以后我们在开发中,不能再一个循环里面频繁的打印日志,防止影响程序的执行效果
6)每一个循环中处理1000个文档打印1条日志,打印日志时间会大大缩短,同时还可以看到日志信息














 11万+
11万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









