






创建Maven工程
修改pom文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>MRDemo</artifactId>
<version>1.0-SNAPSHOT</version>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>6</source>
<target>6</target>
</configuration>
</plugin>
</plugins>
</build>
<dependencies>
<!-- hadoop所需要的依赖-->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.3</version>
</dependency>
<!-- 单元测试-->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
<!-- log4j:日志管理工具-->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.30</version>
</dependency>
<dependency>
<groupId>org.codehaus.mojo</groupId>
<artifactId>exec-maven-plugin</artifactId>
<version>3.1.1</version>
</dependency>
</dependencies>
</project>创建三个类,如PTMapper、PTReducer、PTDriver类
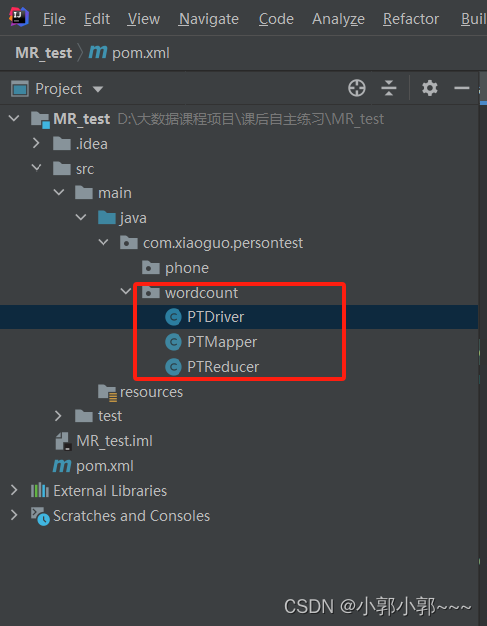
编辑MapReducer中Map和Reducer中的逻辑代码
/*
KEYIN, VALUEIN, KEYOUT, VALUEOUT
分为两种泛型
第一种泛型
KEYIN:读取数据时偏移量的类型
VALUEIN:读取一行一行数据的类型
第二种泛型
KEYOUT:写出时key的类型
VALUEOUT:写出时value的类型
*/
public class PTMapper extends Mapper<LongWritable, Text, Text, LongWritable> {
private Text outKey = new Text();
private LongWritable outValue = new LongWritable();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//1、将数据进行切割
String line = value.toString();
//1.1将Text转成String----为了使用StringAPI进行
//1,2进行切割
String[] words = line.split(" ");
//2、遍历数据
for (String word : words) {
//3、封装key,value
// //创建key对象
// Text outKey = new Text();
// //创建value对象
// LongWritable outValue = new LongWritable();
//给key,value赋值
outKey.set(word);
outValue.set(1);
//4、将key,value写出去
context.write(outKey,outValue);
}
}
}/*
Reduce阶段会运行ReduceTask,ReduceTask会调用Reducer类
作用:在该类中实现需要在ReduceTask中实现的业务逻辑代码
<KEYIN, VALUEIN, KEYOUT, VALUEOUT>
第一组泛型:
KEYIN:读取key的类型(Mapper写出的key的类型)
VALUEIN:读取的value的类型(Mapper写出的value)
第二组泛型:
keyout:写出key的类型----单词的类型
valueout:写出value的类型-----单词的数量
*/
public class PTReducer extends Reducer<Text, LongWritable, Text, LongWritable> {
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
//设置value的和
long sum = 0;
//遍历所有的value
for (LongWritable value : values) {
//将LongWritable的类型转换为long
long v = value.get();
//累加v
sum += v;
}
//封装key,value
LongWritable outValue = new LongWritable();
outValue.set(sum);
//将key,value写出
context.write(key,outValue);
}
}编辑Driver类中的代码
public class PTDriver {
public static void main(String[] args) throws InterruptedException, IOException, ClassNotFoundException {
//创建job实例
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
//给job赋值
//关联本程序的jar,如果是本地可以不写,在集群上必须写
job.setJarByClass(PTDriver.class);
//设置Mapper类和Reducer类
job.setMapperClass(PTMapper.class);
job.setReducerClass(PTReducer.class);
//设置Map输出的key,value的类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
//设置最终输出的key,value的类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
//设置文件输入路径和输出路径
FileInputFormat.setInputPaths(job,new Path("D:\\大数据课程项目\\hadoop_code\\Hello.txt"));//这里我的路径是这个,因个人而定
//输出路径的话一定不能存在,否则会运行失败,报错
FileOutputFormat.setOutputPath(job,new Path("D:\\大数据课程项目\\hadoop_code\\output"));//这里我的文件路径里没有output,运行时会自动创建
//运行Job
/*
waitForCompletion(boolean verbose)
verbose:是否打印信息
返回值:如果job执行成功返回true
*/
boolean b = job.waitForCompletion(true);
//最终输出结果
System.out.println(b);
}
}运行结果
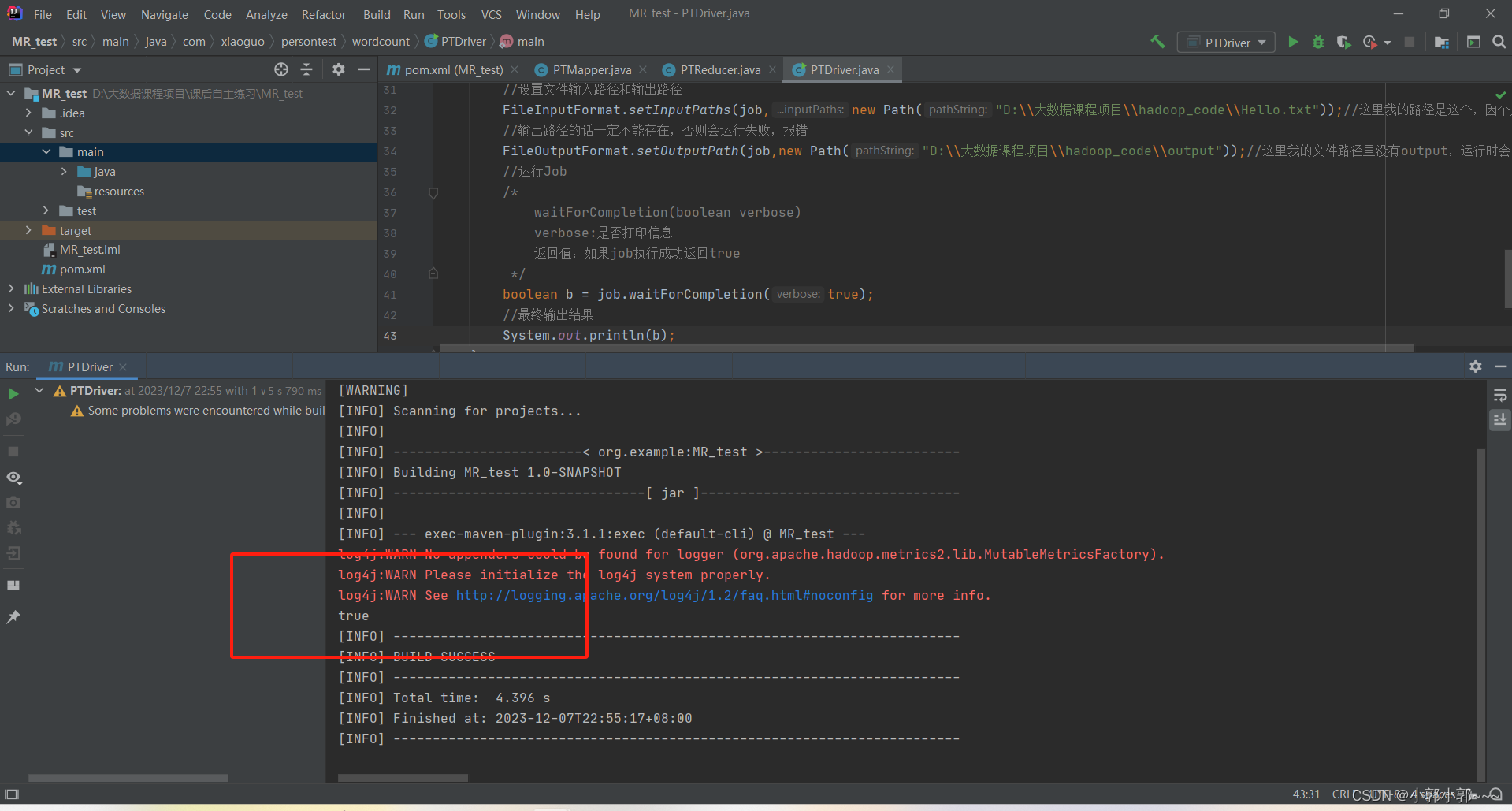
实验结果
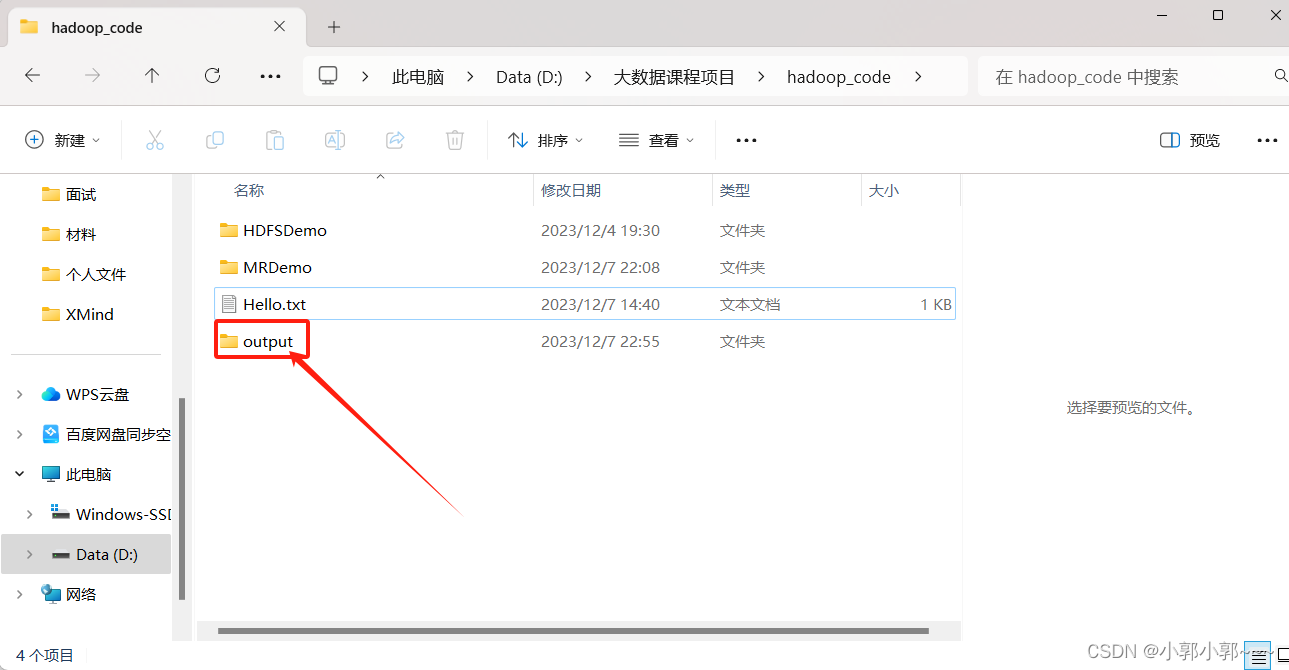
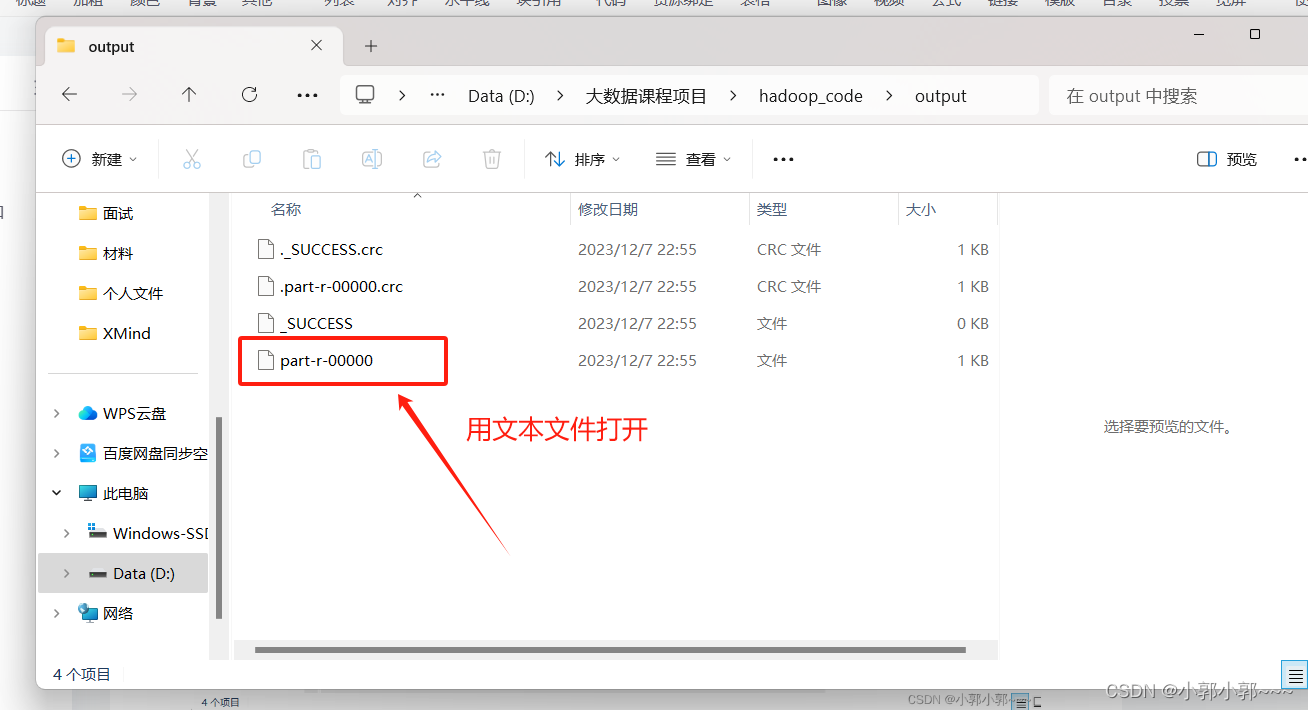
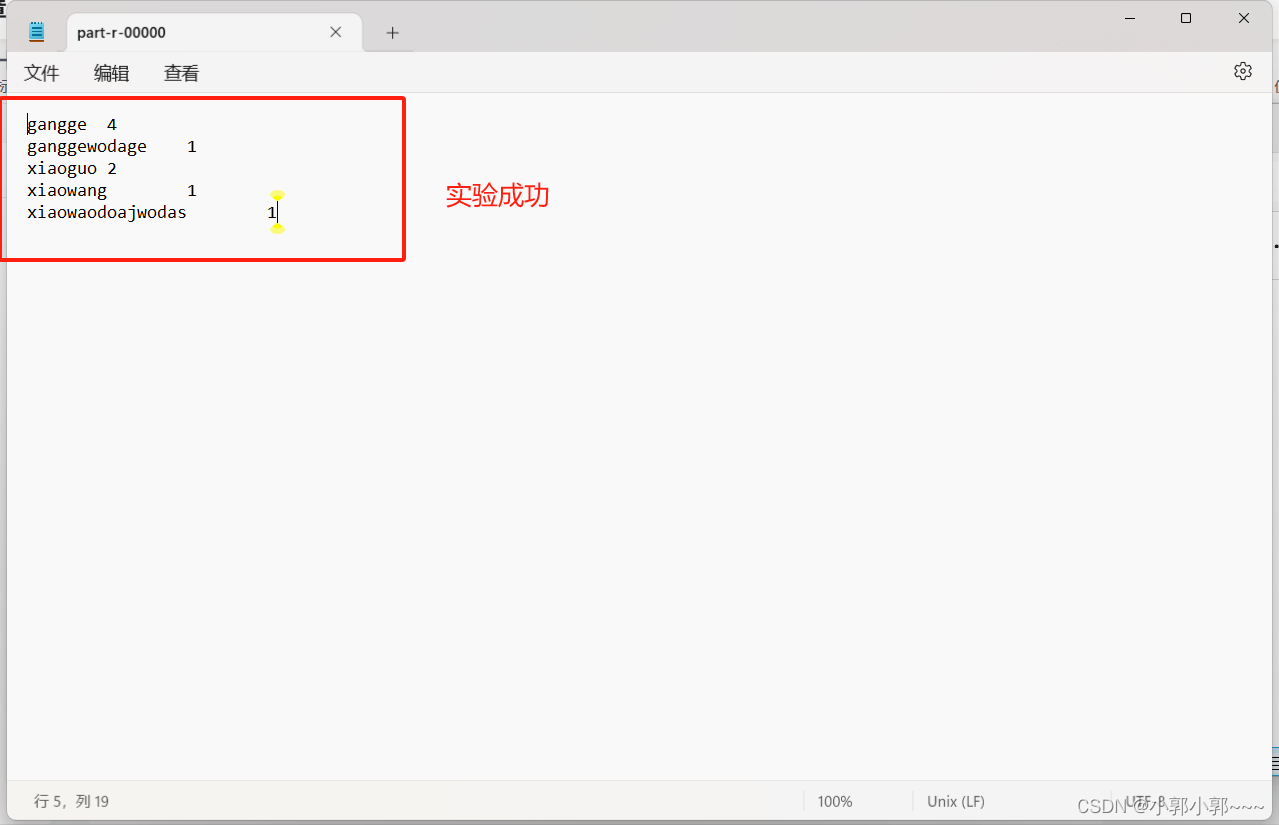
--------------------------------------------2023/12/8---------------------------------------------------
在集群中提交
IDEA中Driver配置
public class WCDriver3 {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//创建Job实例
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
//给Job赋值
//2.1关联本程序的JAR 如果是本地可以不写,在集群上必须写
job.setJarByClass(WCDriver3.class);
//2.2设置Mapper和Reducer类
job.setMapperClass(WCMapper.class);
job.setReducerClass(WCReducer.class);
//2.3设置mapper输出的key,value类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
//2.4设置最终输出的key,value的类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
//2.5设置输入和输出路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
//输出路径一定不能存在,否则一定报错
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//运行Job
/*
waitForCompletion(boolean verbose)
verbose:是否打印信息
返回值:如果job执行成功返回true
*/
boolean b = job.waitForCompletion(true);
}
}打成jar包(双击package)
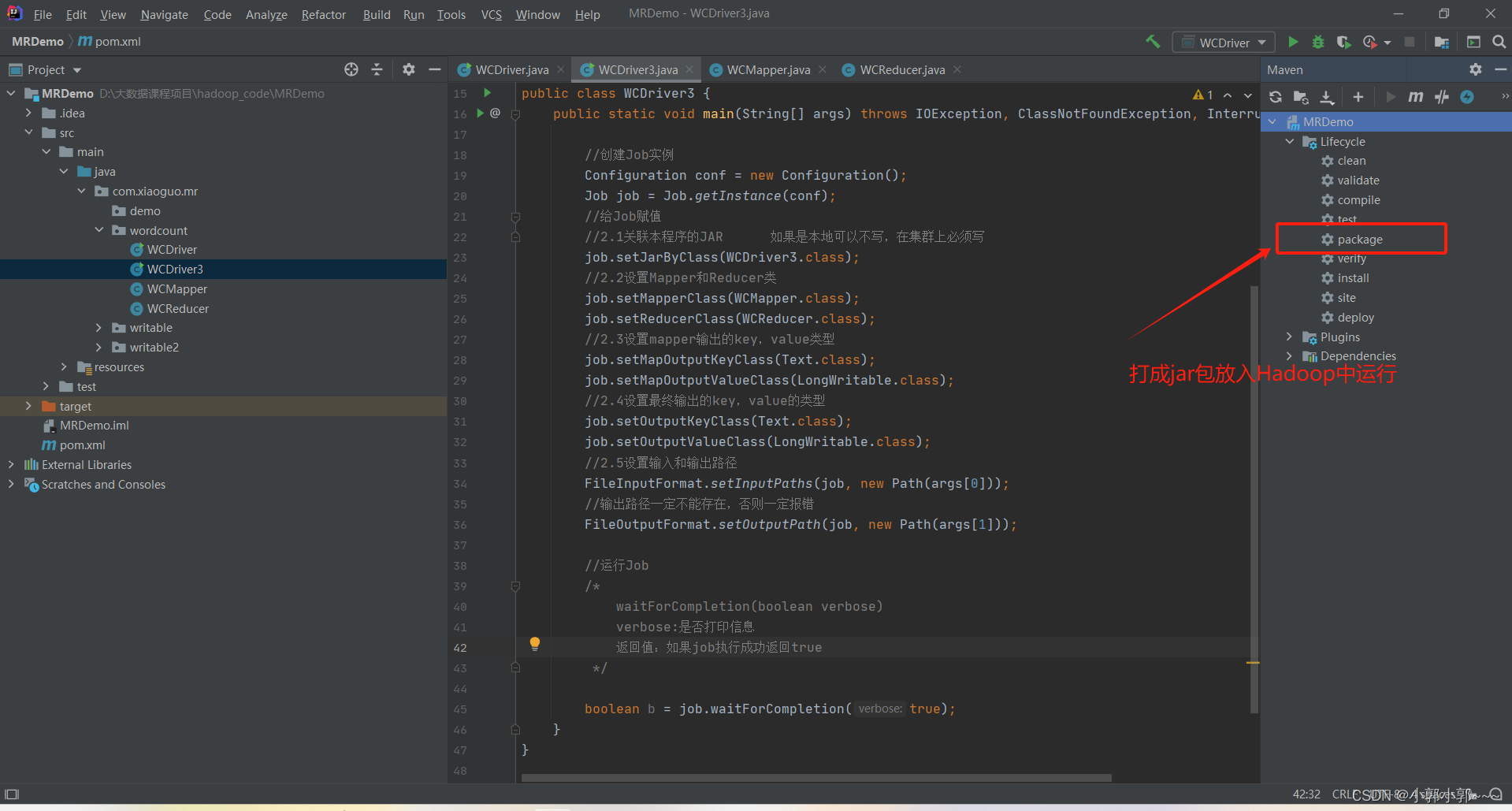
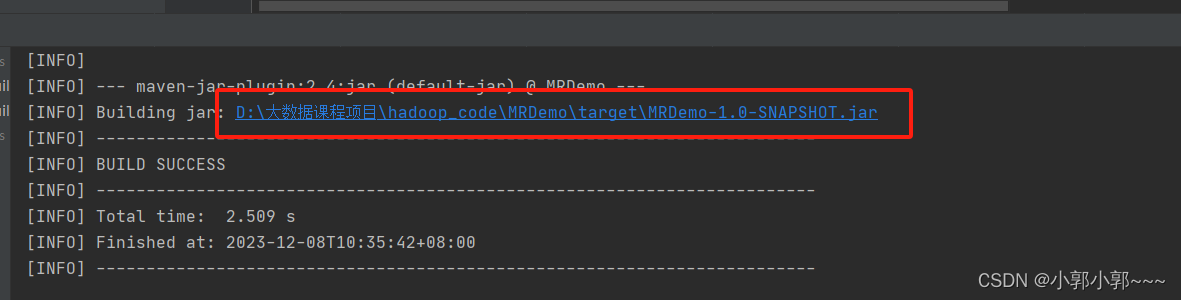
这里为我打成jar包的路径
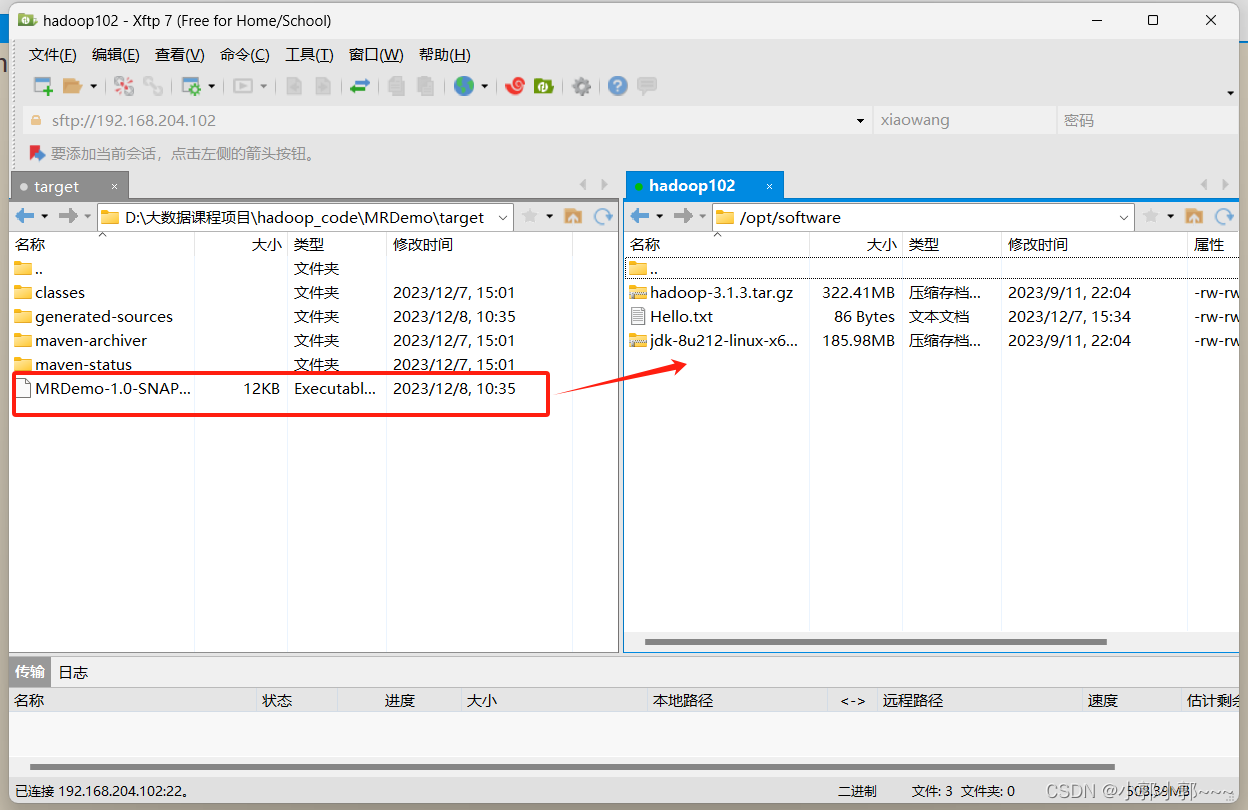
 将jar包上传到hadoop
将jar包上传到hadoop
集群上的命令

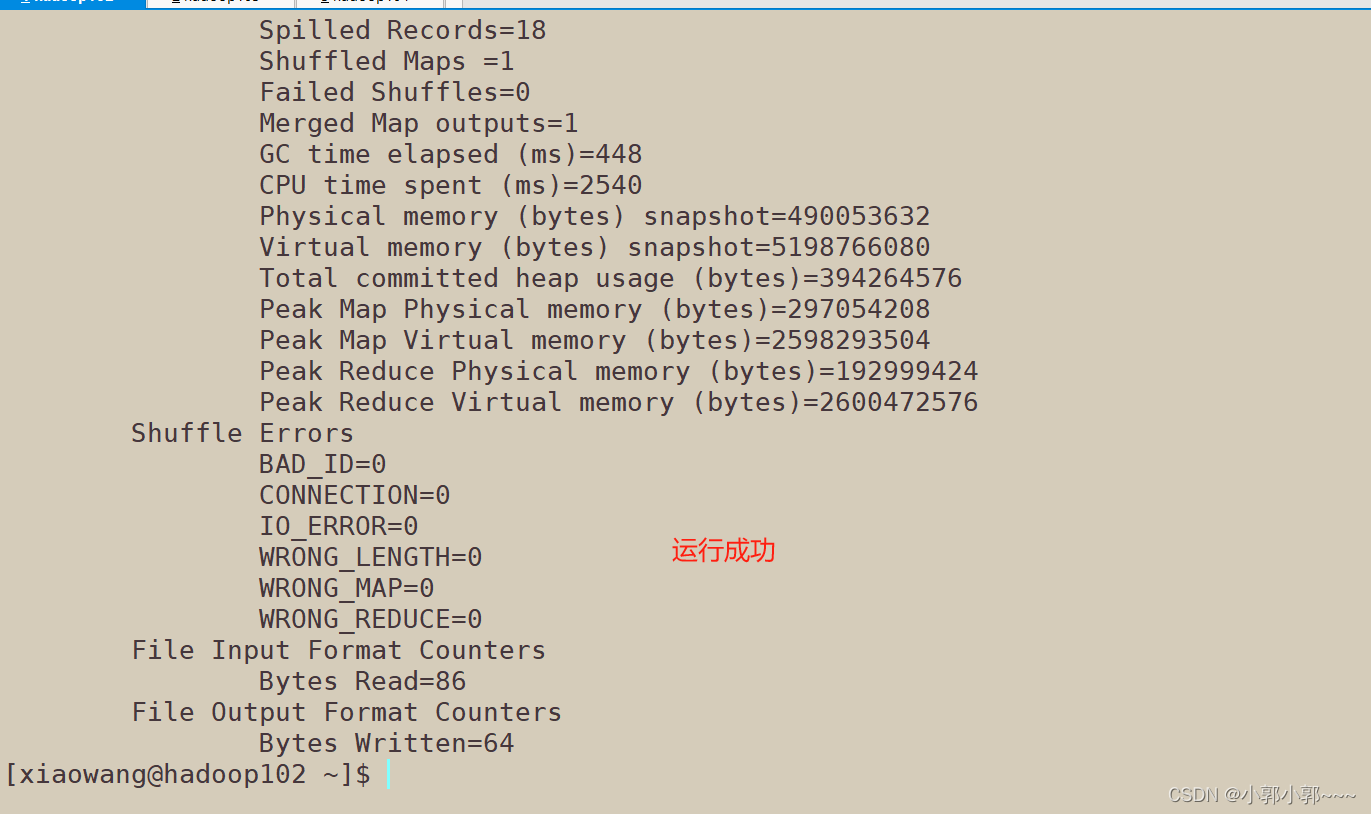
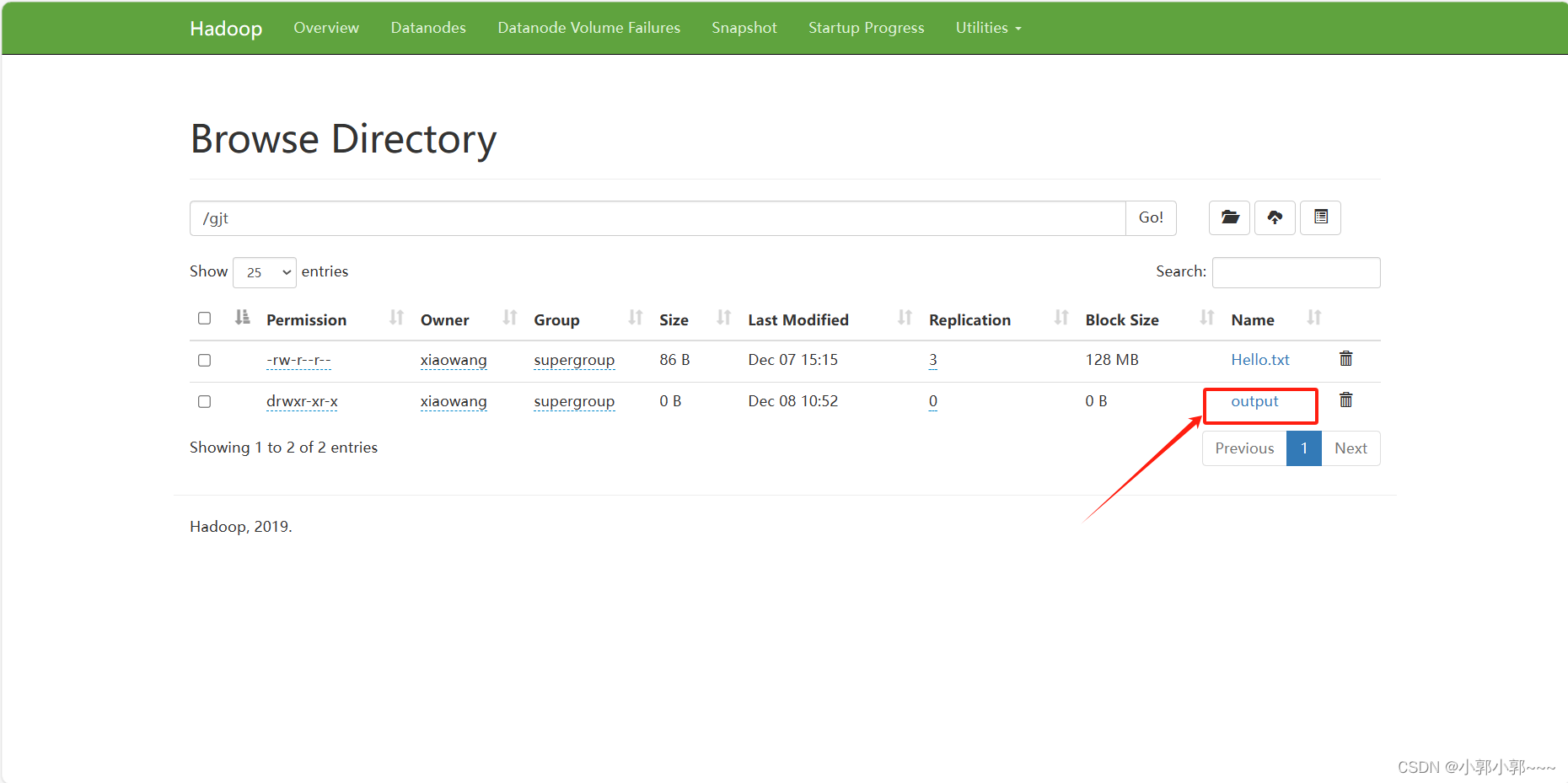
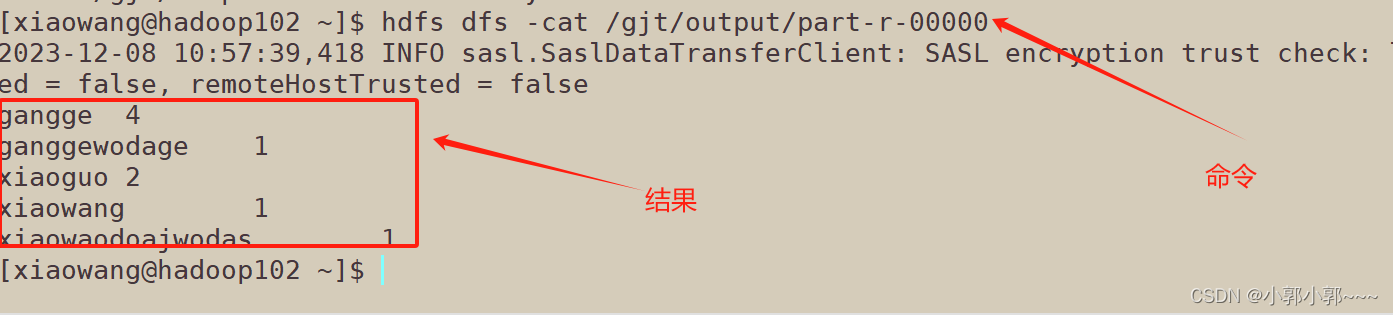
从网页端查看运行结果















 2362
2362











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









