






前言
这里采用的是scrapy爬虫,安装就不用说了,这个真的教不了,我推荐安装anancond3。
爬虫部分
创建项目
我这里是利用pycharm来写的,打开pycharm里面的命令行,运行
scrapy satartprocject dangdang
cd spiders
scrapy genspider book
这样就可以创建好项目了
利用这样可以来调试,或者我们可以采用断点调试,scrapy很适合断点调试的。
scrapy shell "http://search.dangdang.com/?key=python&act=input&page_index=1"
代码
book.py
import scrapy
from bs4 import BeautifulSoup
from ..items import DangdangItem
class BookSpider(scrapy.Spider):
name = 'book'
allowed_domains = ['dangdang.com']
# http://search.dangdang.com/?key=python&act=input&page_index=100
start_urls = ['http://search.dangdang.com/?key=python&act=input&page_index=1']
def parse(self, response):
soup = BeautifulSoup(response.text, 'lxml')
bigimgs = soup.find('ul', class_='bigimg')
books = bigimgs.find_all('li')
for book in books:
item = DangdangItem()
title = book.find('a', class_='pic')
target = book.find('p', class_='name')
price = book.find('span', class_='search_now_price')
comment_num = book.find('p', class_='search_star_line')
information = book.find('p', class_="search_book_author")
span = information.find_all('span')
item['title'] = title['title']
item['link'] = target.find('a')['href']
item['target'] = target.text
item['price'] = price.text
item['comment_num'] = comment_num.text
item['author'] = span[0].text
item['press'] = span[-1].text
item['time'] = span[1].text
yield item
next = response.xpath("//a[normalize-space(translate(text(),' ', ' '))='下一页']/@href").extract_first()
next_url = response.urljoin(next)
print('下一页:{}'.format(next_url))
yield scrapy.Request(url=next_url, callback=self.parse, dont_filter=True)
items.py
import scrapy
class DangdangItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# pass
title = scrapy.Field()
target = scrapy.Field()
link = scrapy.Field()
price = scrapy.Field()
comment_num = scrapy.Field()
author = scrapy.Field()
press = scrapy.Field()
time = scrapy.Field()
main.py
from scrapy.cmdline import execute
execute('scrapy crawl book'.split())
其余的设置由于篇幅的设置,我就不上了,都是套路,这个真的没法教,我们运行main.py就可以爬取数据了,由于限制,我们只爬取了6000条数据。
数据预处理
import pandas as pd
import numpy as np
import json
import matplotlib.pyplot as plt
import seaborn as sns
plt.style.use('ggplot')#使用ggplot样式
plt.rcParams['font.family'] = ['sans-serif']
plt.rcParams['font.sans-serif'] = ['SimHei']# 替换sans-serif字体为黑体
plt.rcParams['axes.unicode_minus'] = False # 解决坐标轴负数的负号显示问题
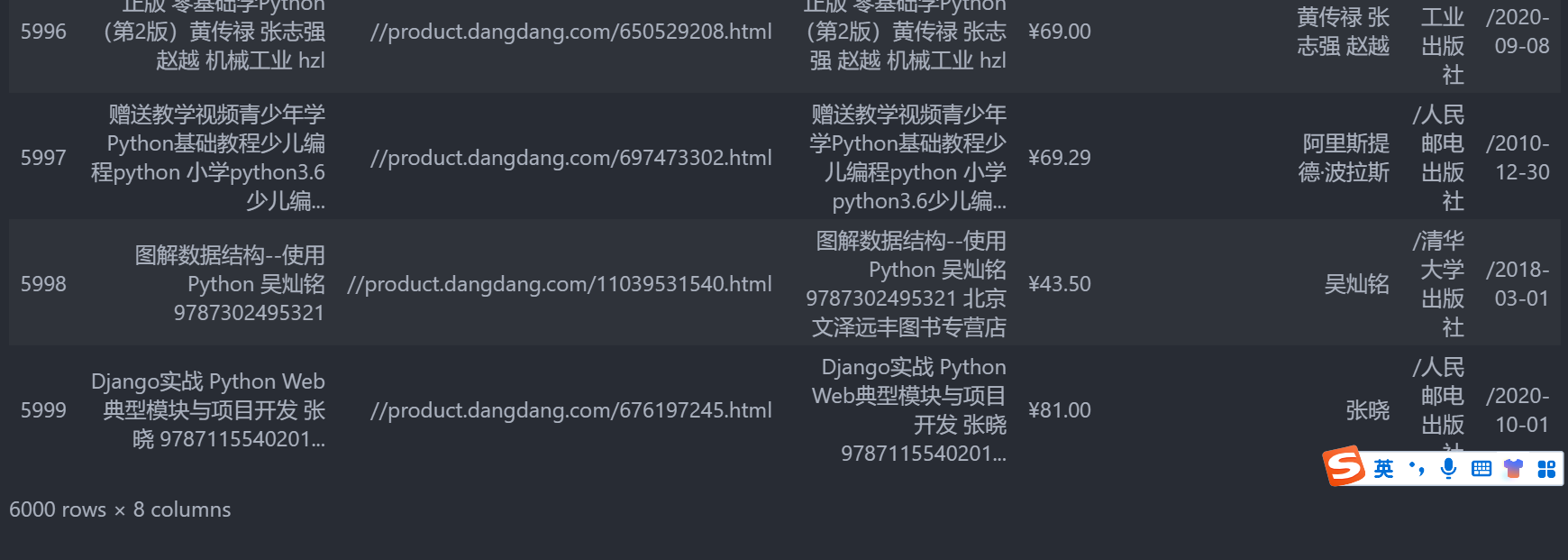
df = pd.read_json('books.json')
df
df = df.replace(r'^\s*$', np.nan, regex=True)
df = df.fillna(0)
df['price_num'] = df['price'].str.extract('([+-]?\d+(\.\d+)?)', expand=True)
df['com_num'] = df['comment_num'].str.extract('([+-]?\d+(\.\d+)?)', expand=True)[0]
df.to_excel('books.xlsx',index=None)

数据分析
df['price_num'] = df['price_num'].astype('float')
df['com_num'] = df['com_num'].astype('int')
df.set_index('title',inplace=True)
df.sort_values(['price_num'],ascending=False)['price_num'].tail(10).plot(kind='bar',figsize=(10,8))
plt.xticks(rotation=45)
plt.ylabel('价格')
plt.xlabel('书籍')
plt.subplots_adjust(bottom=0.4)
plt.savefig('书籍价格排行.jpg',dpi=300)
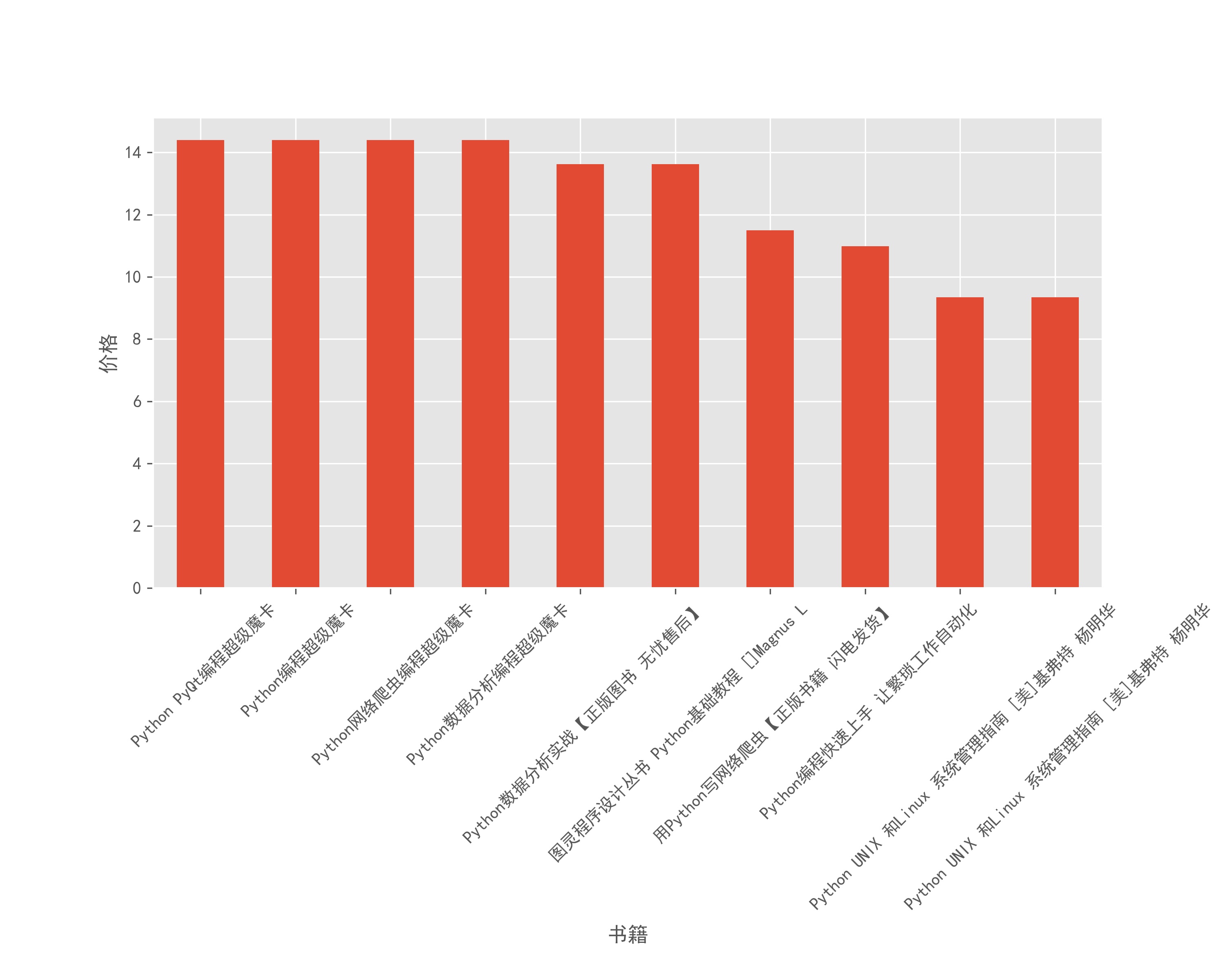
当然要给大家省钱。
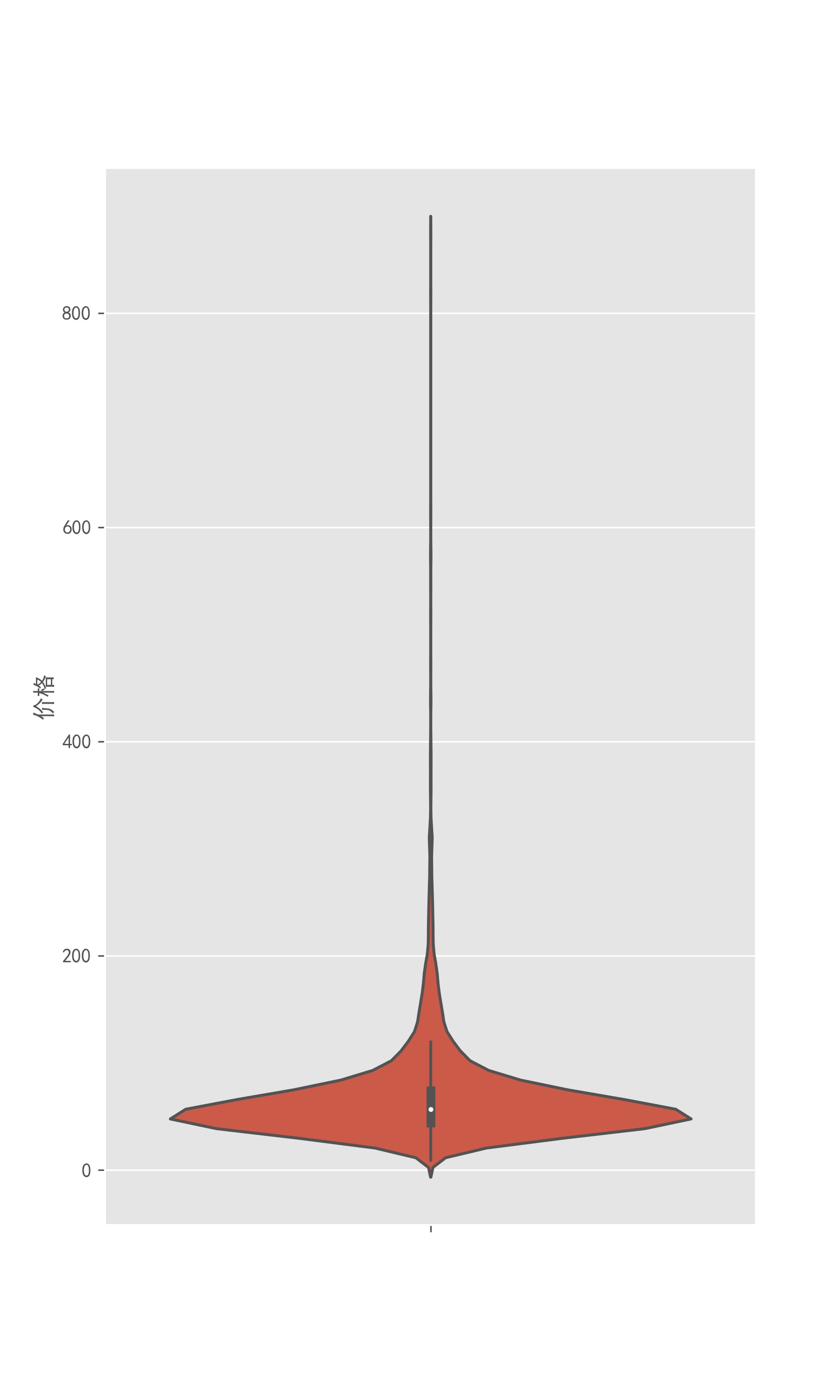
fig,ax = plt.subplots(figsize=(6,10))
ax = sns.violinplot(y=df["price_num"])
ax.set_ylabel('价格')
plt.savefig('书籍价格小提琴图.jpg',dpi=300)
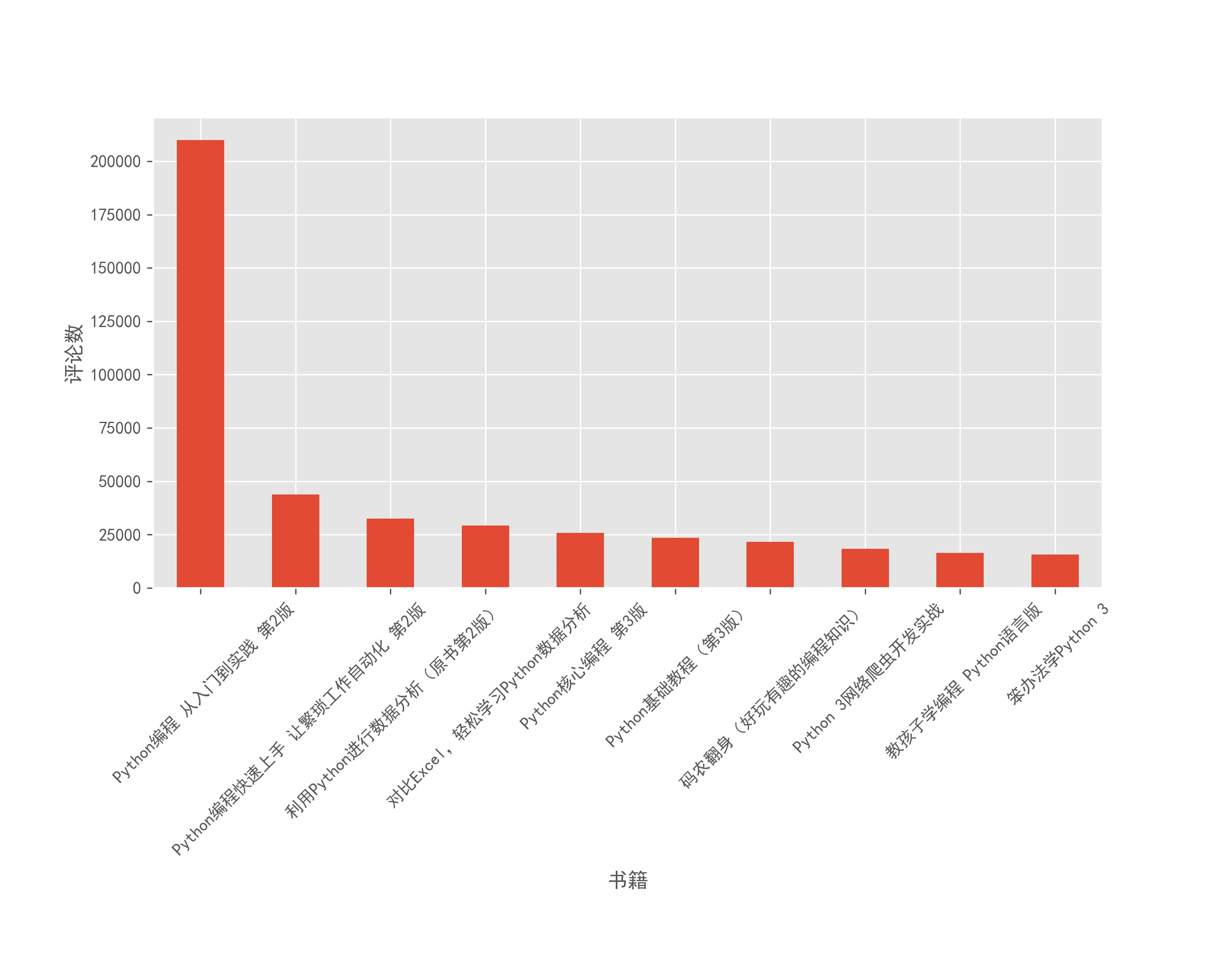
df.sort_values(['com_num'],ascending=False)['com_num'].head(10).plot(kind='bar',figsize=(10, 8))
plt.xticks(rotation=45)
plt.ylabel('评论数')
plt.xlabel('书籍')
plt.subplots_adjust(bottom=0.4)
plt.savefig('书籍评论排行.jpg',dpi=300)
import seaborn as sns
fig,ax = plt.subplots(figsize=(8,10))
ax = sns.violinplot(y=df[df["com_num"]>0]['com_num'])
ax.set_ylabel('评论数')
plt.savefig('评论人数小提琴图.jpg',dpi=300)

俺也不敢说,也不敢问,为什么第一名那么高,所以说嘛,这个评论数也只是我们买书的参考而已。
df.sort_values(by = ['com_num','price_num'],ascending=[False,True]).head()[['com_num','price_num']]

词云图
我们把读书的介绍变成词云图,怎么说呢,其实python的中文分词不是很好,一般的中文分词都是要钱的,我记得图悦不要,但是图悦网站为什么打不开了。
from wordcloud import WordCloud
txt = df['target'].to_list()
re_move=[',',"。",'\n','\xa0']
import matplotlib.pyplot as plt
import jieba
for i in re_move:
txt=str(txt).replace(i," ")
word=jieba.lcut(txt) #使用精确分词模式进行分词后保存为word列表
import collections
text = word
lst = text # lst存放所谓的100万个元素
d = collections.Counter(lst)
d
d = dict(d)
data = pd.DataFrame(d,index=[0])
data = data.T
data.sort_values(0,ascending=False,inplace=True)
data.to_excel('关键词.xlsx')
Excel处理一下。
data = pd.read_excel('关键词.xlsx')
text = ','.join([i for i in data['关键词']])
from os import path
from PIL import Image
import os
import imageio
import wordcloud
from imageio import imread
from wordcloud import WordCloud, STOPWORDS
from os import path
import numpy as np
import matplotlib.pyplot as plt
d = path.dirname(__file__) if "__file__" in locals() else os.getcwd()
text = text
wc = wordcloud.WordCloud(
width=3000,
height=3000,
background_color='white', # 背景颜色白色
font_path='msyh.ttc', # 指定字体路径,微软雅黑,可从win自带的字体库中找
scale=1).generate(text) # 默认为1,越大越清晰
plt.imshow(wc)
plt.axis('off')
plt.show()
wc.to_file('关键词词云图.png')

总结
python爬虫真的不难,还有就是scrapy真的好用,大家可以多学习,这个真的没法教。还有就是献给初学者,想学习python,非计算机专业的学python,特别是理工科的,还是很有必要的,但是要找工作的就免了吧,python真的找不到工作的,还有就是一个现象,python真的有点过火了。python全能,但是python也是全不能。我用这个开源中国写的,崩溃了一次,难受,所以保存是好习惯。















 487
487











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









