







Mysql —— 子查询的 ”必备“ 练习

每博一文案
有人说,不要因为别人说了自己的喜欢的话,而把别人当知己,深以为然,
总有那么一些人的爱,只是停留在口头上,多一分入心的都没有。
但是再多浪漫的情话,也比不过晚归时锅里热腾腾的一碗饭,
至死不渝的承诺,也比不过清早跑几条街,为你买来的豆浆油条。
两个人的感情有多深,不在于说的有多好听,而在于风雨之中的
互相扶持。真正的爱呀,从来都不该只是说说而已,而该是
行动表现出来的,正如新恋爱时代,这段经典台词:如果一个人说
喜欢你,爱你,请等到他对你百般照顾时,再相信,如果他答应
带你去的地方,等他定好机票再开心。
感情不是说说而已,因为我们已经过了耳听爱情的年纪,对你
好意时,很容易,对你好一世却很难。
每个人都有自己特殊的形状,需要磨合才能走到一起。
所以,不要因为别人说了自己喜欢听的话,而轻易的把对方当成知己,
不怕走错路,就拍交错心,不拍太认真,就拍敲错门,与人相交,
甜言蜜语,假仁假义,皆是虚妄,只有真心对真心,才能长久。
—————— 一禅心灵庙语
有关的子查询 ”必备“练习
在Mysql数据库运用中查询是用的比较多的一项,其中较为复杂的便是 我们的 —— 子查询 了,所以设定了,如下的一些练习,用于更加熟练的掌握这门技术活
关于这部分子查询的详细内容,大家可以移步到 🔜🔜🔜 Mysql 知行必会 “子查询”_ChinaRainbowSea的博客-CSDN博客
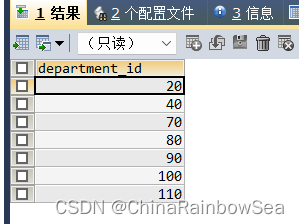
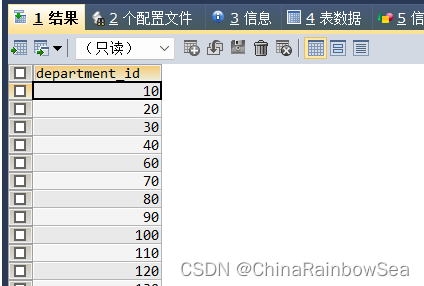
本次的练习题共为 20 道题目,需要用到的表的内容如下:


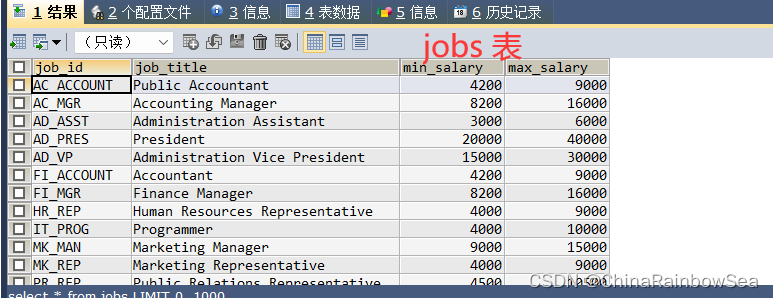
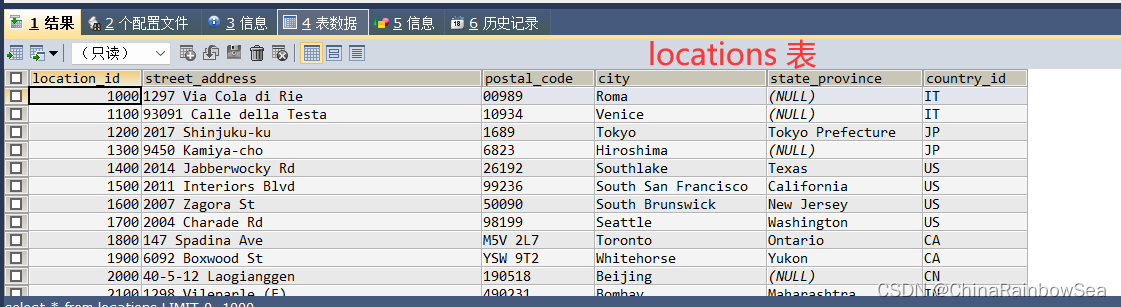
具体练习如下:
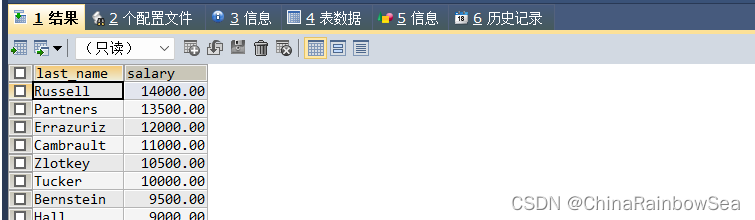
- 查询和 Zlotkey 相同部门的员工姓名和工资
思路1: 使用子查询,找到Zlotkey 对应的部门编号,再通过该部门编号找到员工姓名和工资
SELECT last_name, salary
FROM employees
WHERE department_id = (
SELECT department_id
FROM employees
WHERE last_name = 'Zlotkey');
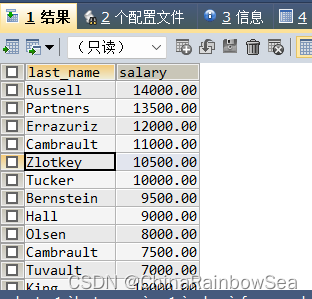
思路二: 使用自表连接,注意使用表别名,防止字段模糊,报错,关于表连接的内容大家可以移步到: 🔜🔜🔜 明了的 —— Mysql 多表连接查询_ChinaRainbowSea的博客-CSDN博客
SELECT e1.`last_name`, e1.`salary`
FROM employees e1
JOIN employees e2
ON e1.`department_id` = e2.`department_id`
WHERE e2.`last_name` = 'Zlotkey';
- 查询工资比公司平均工资高的员工的员工号,姓名和工资
思路: 通过子查询通过分组函数找到公司的平均工资,再通过主查询和子查询的的工资比较,找出其信息
SELECT employee_id, last_name, salary
FROM employees
WHERE salary > (
SELECT AVG(salary)
FROM employees );
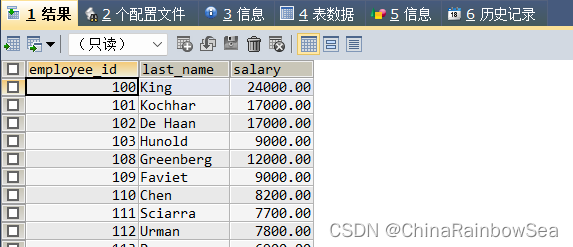
- 选择工资大于所有 job_id = ‘SA_MAN’ 的员工的工资的员工 last_name
思路: 通过子查询找到 job_id = ‘SA_MAN’下的工资,注意所有,我们使用多行子查询的多行操作符 >all
SELECT last_name
FROM employees
WHERE salary > ALL (
SELECT salary
FROM employees
WHERE job_id = 'SA_MAN' );

- 查询姓名中包含字母 u 的员工在同一个部门的员工的员工号和姓名
思路1: 先通过子查询中模糊查询**(like)** 找到 姓名中包含了 字母 u 的部门编号,在通过主查询中的多行子查询操作符 in 找到包含该部门的 员工号,和姓名
SELECT employee_id, last_name
FROM employees
WHERE department_id IN (
SELECT department_id
FROM employees
WHERE last_name LIKE '%u%' );
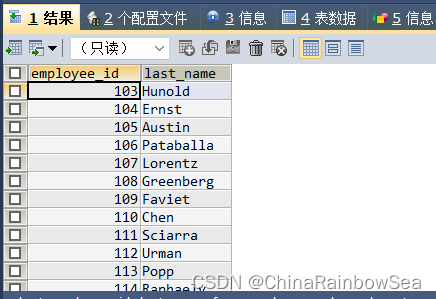
思路2: 使用表连接,再去重 DISTINCT 的 方式
SELECT DISTINCT e1.`employee_id`, e1.`last_name`
FROM employees e1
JOIN employees e2
ON e1.`department_id` = e2.`department_id`
WHERE e2.`last_name` LIKE '%u%';
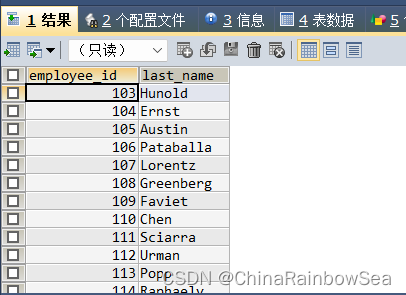
- 查询在部门的 location_id 为 1700 的部门工作的员工的员工号
思路1: 通过子查询找到 location_id 为 1700 的部门, 在通过 多行操作符找到与该部门相同的部门的员工
SELECT employee_id, last_name
FROM employees
WHERE department_id IN (
SELECT department_id
FROM departments
WHERE location_id = 1700);
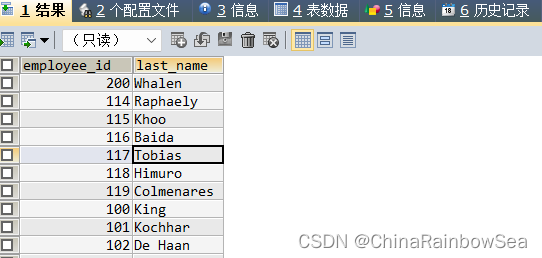
思路2: 通过表连接的方式,注意使用上表别名索引字段,防止字段模糊,报错
SELECT emp.`employee_id`, emp.`last_name`
FROM employees emp
JOIN departments dep
ON emp.`department_id` = dep.`department_id`
WHERE dep.`location_id` = 1700;
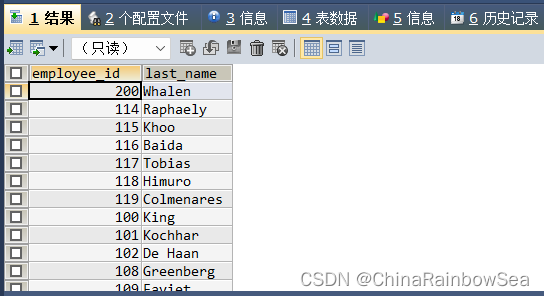
- 查询管理者是 king 的员工姓名和工资
思路1: 先通过子查询找到管理者为 king 的员工编号,再通过多行操作符 IN 找到主查询中 管理者的编号与它相符合 的员工姓名和工资,
SELECT last_name, salary
FROM employees
WHERE manager_id IN (
SELECT employee_id
FROM employees
WHERE last_name = 'King');
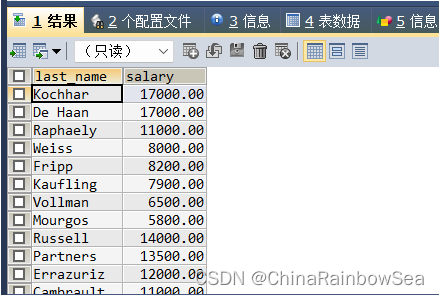
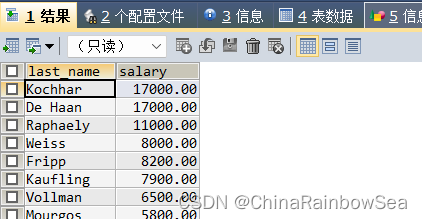
思路2: 通过多表之间的连接,再附加条件,找到,注意使用表别名,防止字段模糊,报错
SELECT emp.`last_name`, emp.`salary`
FROM employees emp
JOIN employees mag
ON emp.`manager_id` = mag.`employee_id`
WHERE mag.`last_name` = 'King';
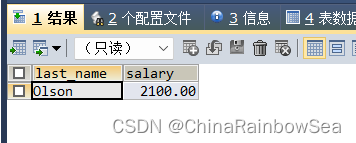
- 查询工资最低的员工信息: last_name, salary
思路: 先通过子查询——> 分组函数找到最低工资,再通过主查询与 其工资比较判断出符合条件的
SELECT last_name, salary
FROM employees
WHERE salary = (
SELECT MIN(salary)
FROM employees );
- 查询平均工资最低的部门信息
思路1: 通过多层嵌套子查询找到符合条件的信息,1. 找到各个部门的平均工资,2. 找到部门中平均工资最低的部门,3. 找到该部门的部门编号,4.主查询查找符合该部门编号的信息
使用 from 中使用子查询,子查询作为临时表使用,必须定义该子查询临时表的表别名,不然报错,通过这个方式查询到部门平均工资的最低工资 ,再使用 HAVING AVG(salary) = ** 分组函数的判断一定要使用 having ,而having 要和 group by 分组一起使用** ,具体原因大家可以移步到:🔜🔜🔜 Mysql —— 多行/聚合/分组函数_ChinaRainbowSea的博客-CSDN博客 ,查询部门中的最低平均工资的的部门编号,最后 主查询根据部门编号,查询平均工资最低的部门信息
SELECT * -- 该主查询,查询平均工资最低的部门信息
FROM departments
WHERE department_id = (
SELECT department_id -- 该子查询,查询部门中的最低平均工资的的部门编号
FROM employees
GROUP BY department_id -- having 分组函数判断 要和 group by 分组一起使用
HAVING AVG(salary) = (
SELECT MIN(avg_sal) -- 该子查询,查询部门中的最低平均工资
FROM (
SELECT AVG(salary) avg_sal -- 该子查询,查询各部门平均工资
FROM employees
GROUP BY department_id ) t_dept_avg_sal ) );
/*每个派生表必须有自己的别名,
from 中子查询作为临时表使用,必须定义表别名,不然报错*/
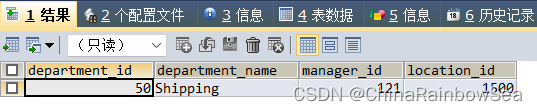
思路2: 通过多行操作符 <= all 代替 from 中使用 子查询临时表 的方式查询部门中最低平均工资, <=all 表示该查询的结果 小于等于 该子查询的所有数值
SELECT * -- 该主查询,查询平均工资最低的部门信息
FROM departments
WHERE department_id = (
SELECT department_id -- 该子查询,查询部门平均工资最低的部门号
FROM employees
GROUP BY department_id
HAVING AVG(salary) <=ALL ( -- 该子查询, 查询各个部门的平均工资
SELECT AVG(salary)
FROM employees
GROUP BY department_id ) );
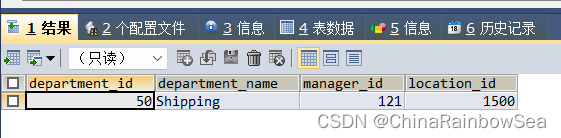
思路3: 使用 ORDER BY 和 LIMIT 代替思路2 中的 having <= all 直接找出部门平均工资最低的部门号,
ORDER BY ASC 升序 再 LIMIT 0,1 分页找到升序中第一个记录信息就是部门平均工资最低的部门号
关于 limit 分页显示的使用 大家可以移步到: 🔜🔜🔜 MySQL —— 排序,分页_ChinaRainbowSea的博客-CSDN博客_mysql 分页并排序
SELECT *
FROM departments
WHERE department_id = (
SELECT department_id -- 该子查询,查询部门平均工资最低的部门编号
FROM employees
GROUP BY department_id
ORDER BY AVG(salary) ASC
LIMIT 0,1);
/* limit 分页显示, 偏移量(从0开始和数组一样), 每页显示的记录条数
公式:(显示的第几页 -1 *每页显示的记录条数, 每页显示的记录条数)*/
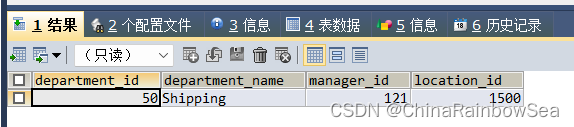
思路4: 把思路3 中的子查询结果(查询部门平均工资最低的部门编号) 作为子查询临时表使用,用于表的连接查询
SELECT dep.* -- 表连接,使用表别名索引字段,防止字段模糊,报错
FROM departments dep
JOIN (
SELECT department_id
FROM employees
GROUP BY department_id
ORDER BY AVG(salary) ASC
LIMIT 0,1 ) t_dep_avg_sal -- 子查询作为临时表使用,一定要定义表别名,防止报错
ON dep.`department_id` = t_dep_avg_sal.department_id;
/* 表连接的条件,防止笛卡尔积现象出现*/
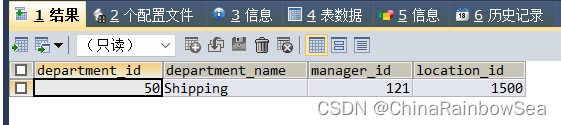
- 查询平均工资最低的部门信息和 该部门的平均工资(相关子查询)
思路1 : 从题目上看这只是在 题目8 上多加了一个查询结果而已,就是部门的平均工资,我们可以通过 关联子查询,关联这个部门编号,再通过分组函数找到平均工资, 注意: 关联子查询使用上表别名, 防止字段模糊,冲突的报错,
SELECT dep.*,(SELECT AVG(salary)
FROM employees /* 关联条件dep.department_id = department_id*/
WHERE dep.department_id = department_id ) avg_sal -- 字段别名
FROM departments dep
WHERE dep.department_id = (
SELECT department_id -- 该子查询,查询部门中的最低平均工资的的部门编号
FROM employees
GROUP BY department_id -- having 分组函数判断 要和 group by 分组一起使用
HAVING AVG(salary) = (
SELECT MIN(avg_sal) -- 该子查询,查询部门中的最低平均工资
FROM (
SELECT AVG(salary) avg_sal -- 该子查询,查询各部门平均工资
FROM employees
GROUP BY department_id ) t_dept_avg_sal ) );
/*每个派生表必须有自己的别名,
from 中子查询作为临时表使用,必须定义表别名,不然报错*/

思路2: 思路2 只是在 **题目8 的思路2 **中加上上述的关联子查询
/* 表别名,索引字段,防止字段冲突*/
SELECT dep.*, (SELECT AVG(salary)
FROM employees emp /*关联条件: dep.`department_id` = emp.department_id*/
WHERE dep.`department_id` = emp.department_id) avg_sal -- 字段别名
FROM departments dep
WHERE dep.department_id = (
SELECT department_id -- 该子查询,查询部门平均工资最低的部门号
FROM employees
GROUP BY department_id
HAVING AVG(salary) <=ALL ( -- 该子查询, 查询各个部门的平均工资
SELECT AVG(salary)
FROM employees
GROUP BY department_id ) );
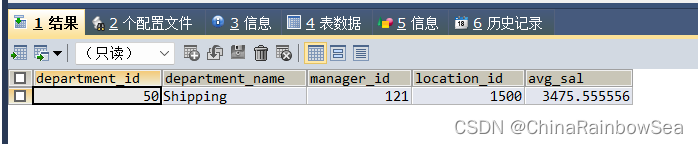
思路3: 同样思路3 只是在 题目8 的思路3 中加上关联子查询,查询该部门的平均值
SELECT dep.*, (SELECT AVG(salary)
FROM employees emp /*关联条件:dep.department_id = emp.department_id*/
WHERE dep.department_id = emp.department_id ) avg_sal
FROM departments dep
WHERE dep.department_id = (
SELECT department_id -- 该子查询,查询部门平均工资最低的部门编号
FROM employees
GROUP BY department_id
ORDER BY AVG(salary) ASC
LIMIT 0,1);
/* limit 分页显示, 偏移量(从0开始和数组一样), 每页显示的记录条数
公式:(显示的第几页 -1 *每页显示的记录条数, 每页显示的记录条数)*/
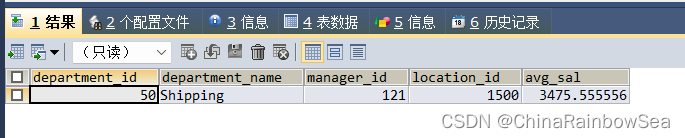
思路4: 最后的思路4 ,也是在题目8 思路4 中加上关联子查询,查询该部门的平均工资
SELECT dep.*, (SELECT AVG(salary)
FROM employees emp /*关联条件:dep.department_id = emp.department_id*/
WHERE dep.department_id = emp.department_id) avg_sal
FROM departments dep
JOIN (
SELECT department_id
FROM employees
GROUP BY department_id
ORDER BY AVG(salary) ASC
LIMIT 0,1 ) t_dep_avg_sal -- 子查询作为临时表使用,一定要定义表别名,防止报错
ON dep.`department_id` = t_dep_avg_sal.department_id;

- 查询平均工资最高的 job的信息
思路1: 使用子查询的嵌套,先1. 平均工资,再2. 查询平均工资最高的工资,3. 查询平均工资最高的job_id
4.查询平均工资最高的 job的信息,注意: from 中使用子查询,是把子查询的结果当成了一个临时表来使用,需要给这个临时表,定义一个表别名,否则会报错
SELECT * -- 主查询,查询平均工资最高的 job的信息
FROM jobs
WHERE job_id = (
SELECT job_id -- 该子查询,查询最高的平均工资的 job_id
FROM employees
GROUP BY job_id
HAVING AVG(salary) = (
SELECT MAX(avg_sal) -- 该子查询,查询最高的平均工资
FROM (
SELECT AVG(salary) avg_sal -- 该子查询,查询平均工资
FROM employees
GROUP BY job_id ) t_job_avg_sal ) )
/* from 中使用子查询, 子查询的结果当成是一个临时表,使用,
需要定义表别名,否则报错*/
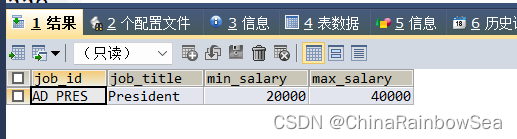
思路2: 使用 >= all 替换掉 思路1中的 from 查询最高的平均工资
SELECT * -- 主查询,查询最高平均工资的job 信息
FROM jobs
WHERE job_id = (
SELECT job_id -- 该子查询,查询最高平均工资的 job_id
FROM employees
GROUP BY job_id -- having 分组函数的判断,需要和 group by 一起使用
HAVING AVG(salary) >= ALL (
SELECT AVG(salary) -- 该子查询,查询平均工资
FROM employees
GROUP BY job_id ) );
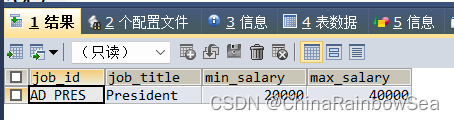
思路3: 使用 order by avg(salary) desc降序 , limit 分页 代替 思路2中的 查询最高工资的 job_id
SELECT * -- 主查询
FROM jobs
WHERE job_id = (
SELECT job_id -- 该子查询, 直接查询平均工资最高的 job_id
FROM employees
GROUP BY job_id
ORDER BY AVG(salary) DESC -- desc 降序,查询表结构
LIMIT 0,1 ); -- limit 分页显示,偏移量从0开始和数组一样, 每页显示记录条数
/* limit 公式
(显示的页数-1* 每页显示的记录条数), 每页显示记录条数*/
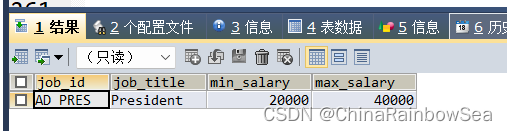
思路4: 把 思路3 的子查询(查询平均工资的job_id)结果作为一张表使用, 使用表连接的方式,查询,注意 既然使用了表连接的方式了,表的别名也不要忘了,防止字段模糊,冲突,而报错
SELECT jo.*
FROM jobs jo
JOIN (SELECT job_id
FROM employees
GROUP BY job_id
ORDER BY AVG(salary) DESC
LIMIT 0,1) t_job_avg_sal /* 表别名*/
ON jo.`job_id` = t_job_avg_sal.job_id;
/* 表之间的连接条件,防止字段重复,冲突,报错*/
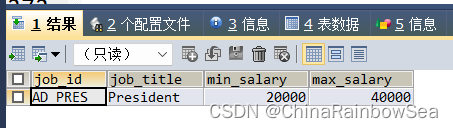
- 查询平均工资高于公司平均工资的部门有那些
思路: 先子查询到公司的平均工资,再主查询大于这个公司的平均工资的部门信息
SELECT department_id
FROM employees
WHERE department_id IS NOT NULL
GROUP BY department_id
HAVING AVG(salary) > (
SELECT AVG(salary)
FROM employees );
- 查询公司中所有 manager 的详细信息
思路1: 自表连接, 注意定义表别名
SELECT DISTINCT mgr.*
FROM employees mgr
JOIN employees emp
ON mgr.`employee_id` = emp.`manager_id`;

思路2: 子查询,先查询到该 manager ,再通过 IN 查询其中的结果
SELECT *
FROM employees
WHERE employee_id IN (
SELECT DISTINCT manager_id
FROM employees );

思路3: 基本上可以使用 IN多行操作符 都可以使用 关联子查询 EXIXTS 存在,满足条件的返回
SELECT *
FROM employees emp
WHERE EXISTS (SELECT *
FROM employees e2
WHERE emp.`employee_id` = e2.`manager_id` );
/* 关联条件: emp.`employee_id` = e2.`manager_id` */

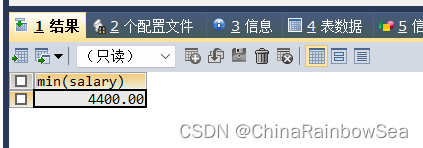
- 各个部门中最高工资中最低的那个部门,最低工资是多少
思路1: 1.各个部门最高工资,2. 最高工资的最低工资的那个部门,4.最低工资是
SELECT MIN(salary) -- 主查询
FROM employees
WHERE department_id = (
SELECT department_id -- 该子查询,查询各个部门中最下工资的最低工资的 department_id
FROM employees
GROUP BY department_id
HAVING MAX(salary) = (
SELECT MIN(max_sal) -- 该子查询,查询各个部门中最大工资的最小工资
FROM (
SELECT MAX(salary) max_sal -- 该子查询,查询各个部门中的最大工资
FROM employees
GROUP BY department_id ) t_emp_avg_sal ) );
/* 在 from 中使用子查询,把子查询的结果看成是一张表,
该表需要定义表别名,不然报错*/
思路2: 使用 <=all 多行子查询,代替: 思路1中的 from 子查询(查询各个部门中最大工资的最小工资) , <=all 全小于子查询的结果
SELECT salary -- 主查询
FROM employees
WHERE department_id = (
SELECT department_id -- 子查询, 查询各个部门中最大工资的最小工资
FROM employees
GROUP BY department_id
HAVING MAX(salary) <=ALL ( -- 子查询,查询结果各个部门中最大工资
SELECT MAX(salary)
FROM employees
GROUP BY department_id ) );
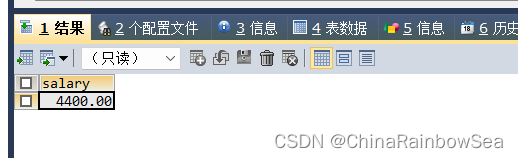
思路3: 使用 order by asc 降序 和 limit 分页 , 代替思路2 中的 <=all ,直接查询到各个部门最大工资中的最小工资的 department_id
SELECT salary
FROM employees
WHERE department_id = (
SELECT department_id
FROM employees
GROUP BY department_id
ORDER BY MAX(salary) ASC
LIMIT 0,1 );
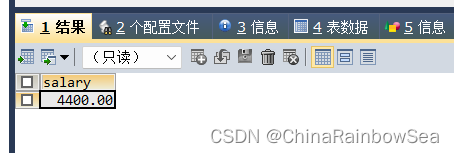
思路4: 使用 思路3 中的接查询到各个部门最大工资中的最小工资的 department_id 的子查询结果作为一张表使用,用作表连接
SELECT salary
FROM employees emp
JOIN (SELECT department_id
FROM employees
GROUP BY department_id
ORDER BY MAX(salary) ASC
LIMIT 0,1) t_emp_max_sal -- 子查询的结果作为一张表,需要定义表结果,否则报错
ON emp.`department_id` = t_emp_max_sal.department_id;
/* 表之间的连接条件: emp.`department_id` = t_emp_max_sal.department_id */
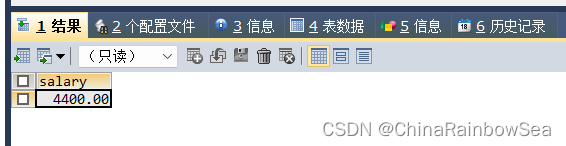
- 查询部门的部门号,其中不包括job_id 是 ‘ST_CLERK’的部门号
思路1: 方向思维,我们查找到 ST_CLERK 的部门号,再取反一下就,不是了呗
SELECT department_id
FROM departments
WHERE department_id NOT IN (
SELECT DISTINCT department_id
FROM employees
WHERE job_id = 'ST_CLERK' );
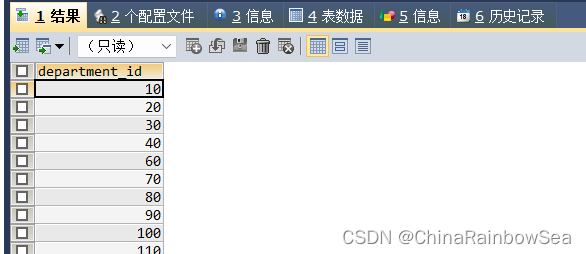
思路2: 一般可以使用 NOT IN 的都可以使用 关联子查询中的NOT EXTSIS (不存在),来查询, 同样取反,取不满足条件的,关联子查询注意使用上表别名索引字段, 防止字段模糊冲突
SELECT department_id
FROM departments dep
WHERE NOT EXISTS (
SELECT *
FROM employees emp /* 关联条件:emp.`department_id` = dep.`department_id`*/
WHERE emp.`department_id` = dep.`department_id`
AND emp.`job_id` = 'ST_CLERK' );
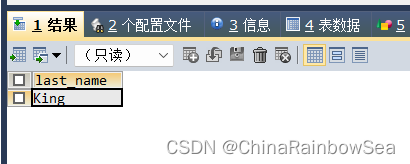
- 选择所有没有管理者的员工的 last_name
思路1: 同样反向思维,先查询含有管理者的员工,再取反操作一下
SELECT last_name
FROM employees
WHERE employee_id NOT IN (
SELECT employee_id
FROM employees
WHERE manager_id IS NOT NULL );
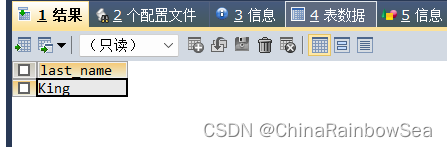
思路2: 一般可以使用 NOT IN 查询到的,都可以使用 关联子查询 NOT EXISTS 查询到,关联子查询的关联条件的注意使用表别名索引,防止字段模糊,报错
SELECT last_name
FROM employees emp
WHERE NOT EXISTS (SELECT *
FROM employees emp2
WHERE emp.`manager_id` = emp2.`employee_id`);
/* 关联条件: emp.`manager_id` = emp2.`employee_id` */
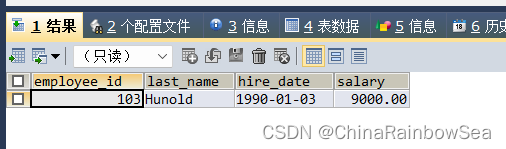
- 查询员工号,姓名,雇佣时间,工资,其中员工的管理者为 “De Haan"
思路1: 子查询该管理者的 ”De Haan" 的员工号,再使用多行子查询 IN 防止存在多个名字相同的 管理者
SELECT employee_id, last_name, hire_date, salary
FROM employees
WHERE manager_id IN (
SELECT employee_id
FROM employees
WHERE last_name = 'De Haan');
思路2: 一般可以使用 IN 查询到的,都可以使用 关联子查询中的 EXISTS 查询到, 关联子查询注意使用表别名索引字段, 防止出现字段模糊,而报错的
SELECT e1.`employee_id`, e1.`last_name`, e1.`hire_date`, e1.`salary`
FROM employees e1
WHERE EXISTS (
SELECT *
FROM employees e2
WHERE e1.`manager_id` = e2.`employee_id`
AND e2.`last_name` = 'De Haan' );

- 查询各部门中工资比本部门平均工资的高,的员工号,姓名和工资(关联子查询)
思路1: 使用关联子查询,通过主查询传给子查询部门号,子查询根据部门号,使用分组函数计算出该部门的平均工资,关联子查询,注意使用上表别名,在关联条件上,防止字段模糊,而报错
SELECT e1.`employee_id`, e1.`last_name`, e1.`salary`
FROM employees e1
WHERE salary > (SELECT AVG(salary)
FROM employees e2
WHERE e1.`department_id` = e2.`department_id`);
/* 关联条件: e1.`department_id` = e2.`department_id` */
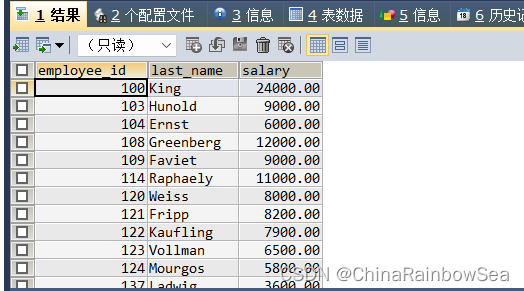
思路2: 使用 表连接的方式,把子查询的结果(查询各个部门的平均工资和部门department_id) 作为一张临时表,用来表连接,注意使用表别名,防止字段模糊,报错
SELECT emp.`employee_id`, emp.`last_name`, emp.`salary`
FROM employees emp
JOIN (
SELECT AVG(salary) avg_sal, department_id
FROM employees
GROUP BY department_id ) t_emp_avg_sal -- 子查询临时表,需要定义表别名,不然报错
ON emp.`department_id` = t_emp_avg_sal.department_id -- 表连接条件
AND emp.`salary` > t_emp_avg_sal.avg_sal
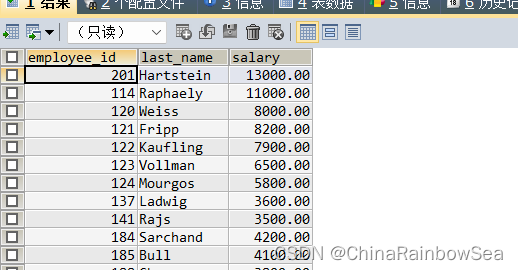
- 查询每个部门下的部门人数大于 5 的部门名称(关联子查询)
思路1: 使用关联子查询,通过主查询传递给子查询 部门编号department_id,子查询使用分组函数 count(*) 计算这个部门的人数,再返回给主查询 判断比较是否 > 5
SELECT dep.`department_name`
FROM departments dep
WHERE 5 < (
SELECT COUNT(*)
FROM employees emp
WHERE dep.`department_id` = emp.`department_id` );
/* 关联条件: dep.`department_id` = emp.`department_id` */
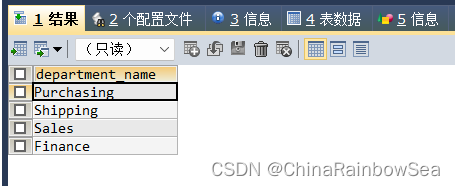
思路2: 把子查询的结果(各个部门的人数个数) 看成是一张临时表,用于表的连接,再通过表连接后进一步的筛选 > 5 的部门名称
SELECT dep.`department_name`
FROM departments dep
JOIN (
SELECT department_id, COUNT(*) count_emp
FROM employees
GROUP BY department_id ) t_emp_count -- 子查询临时表,一定要定义表别名,不然报错
ON dep.`department_id` = t_emp_count.department_id -- 表连接条件
WHERE 5 < t_emp_count.count_emp;
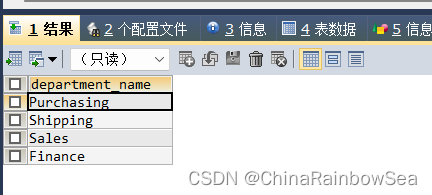
- 查询每个国家下部门个数大于2 的国家编号(关联子查询)
思路: 使用关联子查询,主查询传递给子查询 location_id ,子查询根据其字段,使用分组函数,count(*) 计数
SELECT loc.`country_id`
FROM locations loc
WHERE 2 < (SELECT COUNT(*)
FROM departments dep
WHERE loc.`location_id` = dep.`location_id`);
子查询编写技巧
- 从外往里写(就是一步一步的从主查询最后写子查询)
如果子查询相对比较简单的话,建议从外往里写,先写主查询一步一步过度到子查询,还有就是关联子查询也可以,从外往里写,因为涉及到关联条件的问题,表别名,字段
- 从里往外写 (就是先把所有需要的子查询写好,然后再和主查询拼接起来)
如果子查询结构比较复杂,你不太清楚的情况下,建议从里往外写,这样可以条例比较清晰,
- 写的子查询一定要独立运行一下看看是否符合你的要求,以及最后的子查询和主查询拼接好以后,需要进行相关的验证查看是否查询正确。这很重要,🌟🌟🌟🌟🌟
最后:
限于自身水平,其中存在的错误,希望大家给予指教,韩信点兵——多多益善,谢谢大家,后会有期,江湖再见!
















 168
168











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









