






文章目录
前言
继续iOS锁的学习。在这里深入的学习@synchronized的实现过程。
@synchronized介绍
@synchronized 结构所做的事情跟锁(lock)类似:它防止不同的线程同时执行同一段代码。但在某些情况下,相比于使用 NSLock 创建锁对象、加锁和解锁来说,@synchronized 用着更方便,可读性更高。但并不是在任意场景下都能使用@synchronized,且它的性能较低。
用法
@synchronized (obj) {}
官方文档该锁的用法:
使用@synchronized指令
@synchronized指令是在Objective-C代码中实时创建互斥锁的便捷方式。@synchronized指令会做任何其他互斥锁都会做的事情——它防止不同的线程同时获取相同的锁。然而,在这种情况下,您不必直接创建互斥量或锁定对象。相反,您只需使用任何Objective-C对象作为锁定令牌,如以下示例所示:
-(void)myMethod:(id)anObj
{
@synchronized(anObj)
{
//大括号之间的一切都受到@synchronized指令的保护。
}
}
传递给@synchronized指令的对象是用于区分受保护块的唯一标识符。
需要注意:
- 如果在两个不同的线程中执行上述方法,为每个线程上的anObj参数传递不同的对象,每个线程都会锁定并继续处理,而不会被另一个线程阻止。
- 如果在这两种情况下都传递相同的对象,其中一个线程将首先获得锁,另一个线程将阻塞,直到第一个线程完成关键部分。
作为预防措施,@synchronized块隐式地将异常处理程序添加到受保护的代码中。如果抛出异常,此处理程序会自动释放互斥体。这意味着,为了使用@synchronized指令,必须在代码中启用Objective-C异常处理。
加锁实例
- 无锁:
// @synchronized
- (void)testSynchronized {
// 模拟多窗口售票
self.ticketCount = 20;//一共有 20 张车票,分为 4 个窗口售卖
dispatch_async(dispatch_get_global_queue(0, 0), ^{
for (int i = 0; i < 5; i++) {
[self saleTicket];
}
});
dispatch_async(dispatch_get_global_queue(0, 0), ^{
for (int i = 0; i < 5; i++) {
[self saleTicket];
}
});
dispatch_async(dispatch_get_global_queue(0, 0), ^{
for (int i = 0; i < 3; i++) {
[self saleTicket];
}
});
dispatch_async(dispatch_get_global_queue(0, 0), ^{
for (int i = 0; i < 10; i++) {
[self saleTicket];
}
});
}
// 售票方法
- (void)saleTicket{
if (self.ticketCount > 0) {
self.ticketCount--;
sleep(0.1);
NSLog(@"当前余票还剩:%lu张",(unsigned long)self.ticketCount);
}else{
NSLog(@"当前车票已售罄");
}
}
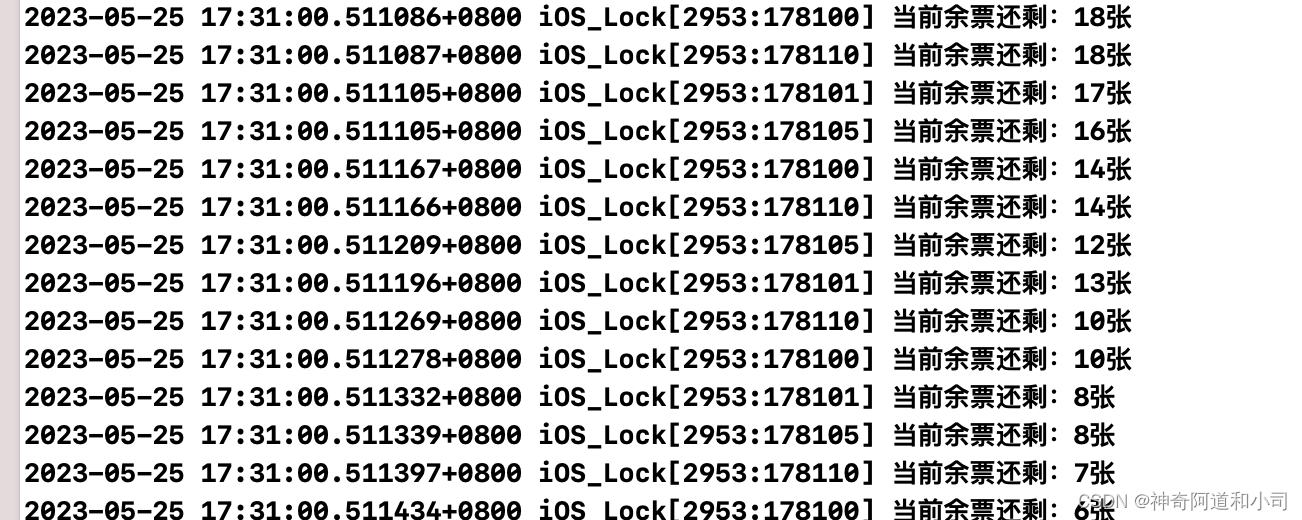
在无锁的情况下:数据在18张和14张的时候发生了冲突
- 加锁:
// @synchronized
- (void)testSynchronized {
// 模拟多窗口售票
self.ticketCount = 20;//一共有 20 张车票,分为 4 个窗口售卖
dispatch_async(dispatch_get_global_queue(0, 0), ^{
for (int i = 0; i < 5; i++) {
[self saleTicket];
}
});
dispatch_async(dispatch_get_global_queue(0, 0), ^{
for (int i = 0; i < 5; i++) {
[self saleTicket];
}
});
dispatch_async(dispatch_get_global_queue(0, 0), ^{
for (int i = 0; i < 3; i++) {
[self saleTicket];
}
});
dispatch_async(dispatch_get_global_queue(0, 0), ^{
for (int i = 0; i < 10; i++) {
[self saleTicket];
}
});
}
// 售票方法
- (void)saleTicket{
@synchronized (self) {
if (self.ticketCount > 0) {
self.ticketCount--;
sleep(0.1);
NSLog(@"当前余票还剩:%lu张",(unsigned long)self.ticketCount);
}else{
NSLog(@"当前车票已售罄");
}
}
}

@synchronized实现
打开Debug调试

上面的汇编代码可以看到,@synchronized block会变成 objc_sync_enter 和 objc_sync_exit 的成对儿调用。
那么就从这两个方法入手详细了解@synchronized。
objc_sync_enter 和 objc_sync_exit
在objc843可编译源码查看方法。接口部分给了一部分注释
#include <objc/objc.h>
/**
* 开始对“obj”进行加锁。
*
* Begin synchronizing on 'obj'.
*
*如果需要,分配与“obj”关联的递归pthread_mutex。
* Allocates recursive pthread_mutex associated with 'obj' if needed.
*
*要开始加锁的对象。
* @param obj The object to begin synchronizing on.
*
* @return OBJC_SYNC_SUCCESS once lock is acquired.
*/
OBJC_EXPORT int
objc_sync_enter(id _Nonnull obj)
OBJC_AVAILABLE(10.3, 2.0, 9.0, 1.0, 2.0);
/**
* End synchronizing on 'obj'.
* 结束对“obj”的锁。
*
* obj要结束加锁的对象。
* @param obj The object to end synchronizing on.
*
* @return OBJC_SYNC_SUCCESS or OBJC_SYNC_NOT_OWNING_THREAD_ERROR
*/
OBJC_EXPORT int
objc_sync_exit(id _Nonnull obj)
OBJC_AVAILABLE(10.3, 2.0, 9.0, 1.0, 2.0);
enum {
OBJC_SYNC_SUCCESS = 0,
OBJC_SYNC_NOT_OWNING_THREAD_ERROR = -1
};
#endif // __OBJC_SYNC_H_
注释理解:
@synchronized结构在工作时为传入的对象分配了一个锁objc_sync_enter是同步开始的函数objc_sync_exit是同步结束或者出现错误的函数
objc_sync_enter

从该方法的注释能看到,这个方法在给obj对象加锁的时候 分配的是recursive mutex。
- 可以得出
@synchronized是递归锁 - 看看源码
// Begin synchronizing on 'obj'.
// Allocates recursive mutex associated with 'obj' if needed.
// Returns OBJC_SYNC_SUCCESS once lock is acquired.
// 开始加锁
int objc_sync_enter(id obj)
{
int result = OBJC_SYNC_SUCCESS; // 定义一个整型变量 result 并初始化为 OBJC_SYNC_SUCCESS,表示操作成功。
if (obj) { //检查传入的 obj 参数是否非空。
SyncData* data = id2data(obj, ACQUIRE); // 通过 id2data 函数获取 obj 对象关联的 SyncData 结构体数据
ASSERT(data); // 断言确保获取到有效的同步数据。
data->mutex.lock(); // 通过 data 结构体中的 mutex(互斥锁)成员进行加锁操作,确保只有一个线程能够进入临界区。
} else { // 如果传入的 obj 参数为空。
// @synchronized(nil) does nothing
if (DebugNilSync) { // 检查是否启用了调试模式,用于调试 @synchronized(nil) 的情况。
_objc_inform("NIL SYNC DEBUG: @synchronized(nil); set a breakpoint on objc_sync_nil to debug"); // 向运行时库发送调试信息,提示使用者在 objc_sync_nil 上设置断点进行调试。
}
objc_sync_nil(); // 执行 objc_sync_nil 函数,该函数用于处理 @synchronized(nil) 的情况,实际上不执行任何操作。
}
return result; // 返回操作结果。
}
// 总体来说,这段代码的作用是获取对象关联的同步数据,然后对同步数据中的互斥锁进行加锁操作,确保只有一个线程能够进入临界区。如果传入的对象为空,则不执行任何操作
- 该方法的作用是获取对象关联的同步数据,然后对同步数据中的互斥锁进行加锁操作,确保只有一个线程能够进入临界区。如果传入的对象为空,则不执行任何操作
- 如果锁的对象obj不存在时分别会走
objc_sync_nil()和不做任何操作
BREAKPOINT_FUNCTION(
void objc_sync_nil(void)
);
这也是@synchronized作为递归锁但能防止死锁的原因所在:在不断递归的过程中如果对象不存在了就会停止递归从而防止死锁
obj存在
if (obj) { //检查传入的 obj 参数是否非空。
SyncData* data = id2data(obj, ACQUIRE); // 通过 id2data 函数获取 obj 对象关联的 SyncData 结构体数据
(obj存在)会通过id2data方法生成一个SyncData对象
SyncData 结构体的设计用于管理 @synchronized 关键字的同步数据,包括记录对象、线程数量以及互斥锁等信息,以实现线程同步和保护临界区的功能。
typedef struct alignas(CacheLineSize) SyncData {
struct SyncData* nextData; // 指向下一个 SyncData 结构体的指针,用于构建一个链表结构,以管理多个对象的同步数据
DisguisedPtr<objc_object> object; // 使用 DisguisedPtr 进行封装的 objc_object 类型的对象指针,表示与该同步数据相关联的对象。
int32_t threadCount; // number of THREADS using this block
// 表示正在使用该同步数据的线程数量,用于记录进入临界区的线程数量。
recursive_mutex_t mutex; // 一个递归互斥锁,用于实现线程同步和保护临界区代码。
} SyncData;
具体成员的解释如下:
nextData指的是链表中下一个SyncData,通过链表将多个对象的同步数据连接起来,方便管理和查找。object指的是当前加锁的对象, DisguisedPtr 类型的对象指针,用于存储与该同步数据关联的对象的地址threadCount表示使用该对象进行加锁的线程数,每当有线程进入临界区时,threadCount 的值会增加,线程退出临界区时,threadCount 的值会减少。通过记录线程数量,可以确保临界区的正确性。mutex即对象所关联的锁,是一个递归互斥锁。
结构体的对齐方式通过 alignas(CacheLineSize) 进行指定,其中 CacheLineSize 表示缓存行的大小,用于优化内存对齐,避免伪共享等性能问题。
既然SyncData是链表中的某一个节点,保存了节点信息,那就看看SyncList的结构
SyncList的结构
SyncList结构体的设计用于管理多个对象的同步数据,并提供了自旋锁来保护对SyncList的并发访问- 使用链表的原因可以用于存储和操作多个对象的同步信息。
struct SyncList {
SyncData *data; // 指向 SyncData 结构体的指针,用于构建一个链表结构,管理多个对象的同步数据。
spinlock_t lock; // 一个自旋锁(spinlock_t),用于保护对 SyncList 的操作,确保并发访问的正确性。
// SyncList 的构造函数使用了 constexpr 修饰符,表示该构造函数可以在编译时求值,用于初始化 SyncList 结构体的实例。构造函数初始化了 data 成员为 nil(空指针),并将 lock 成员初始化为 fork_unsafe_lock(一个自旋锁的初始状态)。
constexpr SyncList() : data(nil), lock(fork_unsafe_lock) { }
};
SyncList和SyncData的关系
既然@synchronized能在任意地方(VC、View、Model等)使用,那么底层必然维护着一张全局的表(类似于weak表)。而从SyncList和SyncData的结构可以证实系统确实在底层维护着一张哈希表,里面存储着SyncList结构的数据。SyncList和SyncData的关系如下图所示:
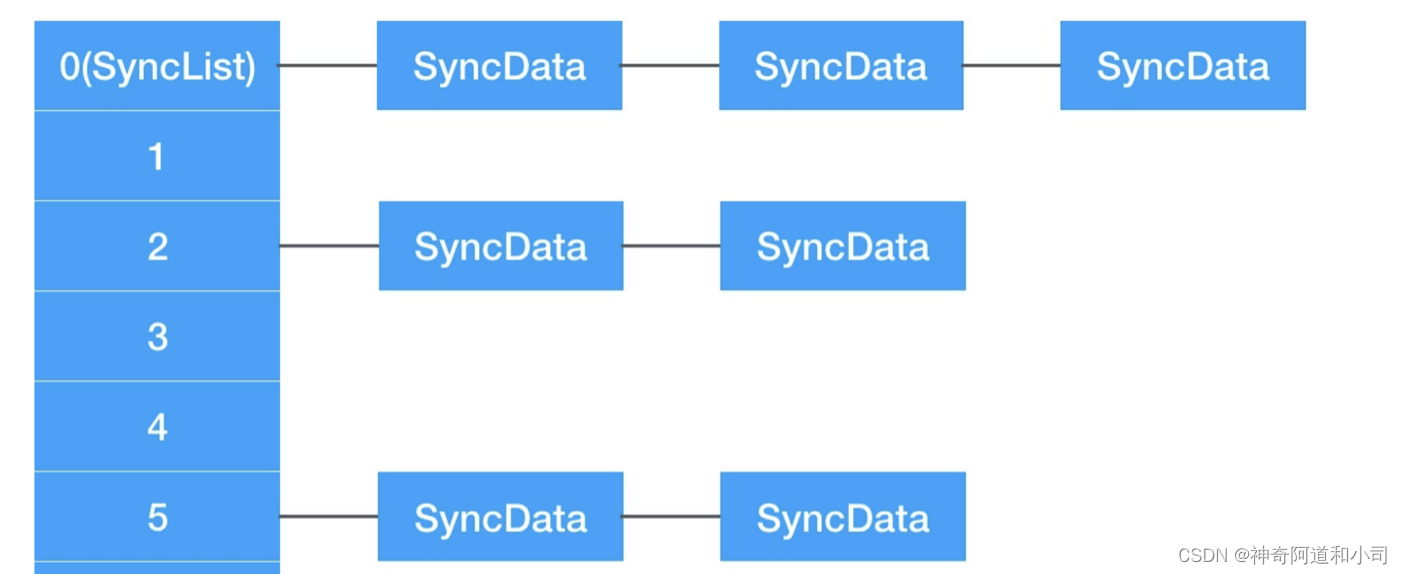
SyncList 和 SyncData 之间存在一种主从关系,即 SyncList 通过 data 指针管理多个 SyncData 结构体的链表。
具体来说,SyncList 结构体中的 data 成员是一个指针,指向第一个 SyncData 结构体的地址。通过这个指针,可以遍历整个链表,访问和管理每个 SyncData 结构体。
而 SyncData 结构体本身包含了一个指向下一个 SyncData 结构体的指针 nextData,以及其他的同步相关数据,如 object、threadCount 和 mutex。通过 nextData 指针,可以将多个 SyncData 结构体连接成一个链表。
因此,SyncList 结构体通过持有 SyncData 结构体的链表,实现了对多个对象的同步数据的管理和访问。通过操作 SyncList 中的 data 指针和 SyncData 中的 nextData 指针,可以进行链表的遍历、添加、删除等操作,以维护和操作同步数据的集合。
id2data函数的实现
id2data函数应该分成很多步骤实现,我们将 id2data函数内部实现根据他的宏定义划分各个板块挨个学习
id2data函数主要用于根据给定的对象查找与之关联的同步数据(SyncData)。它首先检查当前线程的缓存,然后再查找全局的同步数据列表,以获取与给定对象匹配的同步数据。
1. 使用快速缓存
// object 是一个类型为 id 的参数,表示待处理的对象。
// why 是一个枚举类型的参数,表示函数的使用目的
// enum usage { ACQUIRE, RELEASE, CHECK };
static SyncData* id2data(id object, enum usage why)
{
spinlock_t *lockp = &LOCK_FOR_OBJ(object); // // 从SyncList中通过object,获取lock
SyncData **listp = &LIST_FOR_OBJ(object); // // 从SyncData通过object获取data
SyncData* result = NULL; // // 设置初始值
// 如果支持直接线程键(SUPPORT_DIRECT_THREAD_KEYS 定义为真),则尝试从线程的快速缓存中查找与对象匹配的 SyncData
#if SUPPORT_DIRECT_THREAD_KEYS
// Check per-thread single-entry fast cache for matching object
// 检查每线程单项快速缓存中是否有匹配的对象
bool fastCacheOccupied = NO;
SyncData *data = (SyncData *)tls_get_direct(SYNC_DATA_DIRECT_KEY);
if (data) {
fastCacheOccupied = YES;
if (data->object == object) {
// Found a match in fast cache. 在快速缓存中找到匹配项。
uintptr_t lockCount;
result = data;
lockCount = (uintptr_t)tls_get_direct(SYNC_COUNT_DIRECT_KEY);
if (result->threadCount <= 0 || lockCount <= 0) {
_objc_fatal("id2data fastcache is buggy");
}
// enum usage { ACQUIRE, RELEASE, CHECK };
// why 是一个枚举类型的参数,表示函数的使用目的
switch(why) {
case ACQUIRE: {
lockCount++;
// 这里使用了 tls_get_direct 和 tls_set_direct 函数进行线程本地存储的读取和写入。
// 如果在快速缓存中找到了匹配的 SyncData,则将结果赋值为找到的 SyncData,并根据 why 参数进行相应的操作。
// 如果未在快速缓存中找到匹配项,则继续执行后续的逻辑。
tls_set_direct(SYNC_COUNT_DIRECT_KEY, (void*)lockCount);
break;
}
case RELEASE:
lockCount--;
tls_set_direct(SYNC_COUNT_DIRECT_KEY, (void*)lockCount);
if (lockCount == 0) {
// remove from fast cache
tls_set_direct(SYNC_DATA_DIRECT_KEY, NULL);
// atomic because may collide with concurrent ACQUIRE
OSAtomicDecrement32Barrier(&result->threadCount);
}
break;
case CHECK:
// do nothing
break;
}
return result;
}
}
- 这里有个重要的知识点——TLS:TLS全称为
Thread Local Storage,在iOS中每个线程都拥有自己的TLS,负责保存本线程的一些变量, 且TLS无需锁保护 - 快速缓存的含义为:定义两个变量
SYNC_DATA_DIRECT_KEY/SYNC_COUNT_DIRECT_KEY,与tsl_get_direct/tls_set_direct配合可以从线程局部缓存中快速取得SyncCacheItem.data和SyncCacheItem.lockCount
如果在缓存中找到当前对象,就拿出当前被锁的次数lockCount,再根据传入参数类型(获取、释放、查看)对lockCount分别进行操作
(lockCount表示被锁的次数,递归锁可以多次进入)
- 获取资源
ACQUIRE:lockCount++并根据key值存入被锁次数 - 释放资源
RELEASE:lockCount++并根据key值存入被锁次数。如果次数变为0,此时锁也不复存在,需要从快速缓存移除并清空线程数threadCount - 查看资源check:不操作
2. 获取该线程下的SyncCache
因为步骤 1 是能直接找到线程的键进行快速缓存查找。endif 这个逻辑分支是找不到确切的线程标记只能进行所有的缓存遍历。
#endif
static SyncData* id2data(id object, enum usage why)
{
....
/*2. 获取该线程下的SyncCache */
// Check per-thread cache of already-owned locks for matching object 检查匹配对象的已拥有锁的每线程缓存。
SyncCache *cache = fetch_cache(NO); // 检索当前线程的每个线程缓存对象 cache。
if (cache) { // 检查缓存是否存在。
unsigned int i;
for (i = 0; i < cache->used; i++) {
SyncCacheItem *item = &cache->list[i]; // 获取索引 i 处的缓存项。
if (item->data->object != object) continue; // 如果缓存项中的对象与指定对象不匹配,则跳过下一次迭代。
// Found a match.找到一个匹配对象
result = item->data; // 将匹配的锁数据赋值给 result 变量。
if (result->threadCount <= 0 || item->lockCount <= 0) {
_objc_fatal("id2data cache is buggy"); // 检查锁数据是否有效,如果无效,则抛出错误。
}
// 根据why的值,执行下列操作。
switch(why) {
case ACQUIRE:
item->lockCount++; // 增加锁计数。
break;
case RELEASE:
item->lockCount--; // 减少锁计数
if (item->lockCount == 0) {
// // 如果计数达到零,则从每个线程缓存中移除该项,并对线程计数执行原子递减操作。
// remove from per-thread cache
cache->list[i] = cache->list[--cache->used]; // 从每个线程缓存中移除该项
// atomic because may collide with concurrent ACQUIRE
OSAtomicDecrement32Barrier(&result->threadCount); // 并对线程计数执行原子递减操作。
}
break;
case CHECK:
// do nothing 啥也不做
break;
}
return result;
}
}
SyncCache和SyncCacheItem
typedef struct {
SyncData *data; //该缓存条目对应的SyncData
unsigned int lockCount; //该对象在该线程中被加锁的次数
} SyncCacheItem;
typedef struct SyncCache {
unsigned int allocated; //该缓存此时对应的缓存大小
unsigned int used; //该缓存此时对应的已使用缓存大小
SyncCacheItem list[0]; //SyncCacheItem数组
} SyncCache;
sync:汉语同步。
SyncCacheItem用来记录某个SyncData在某个线程中被加锁的记录,一个SyncData可以被多个SyncCacheItem持有SyncCache用来记录某个线程中所有SyncCacheItem,并且记录了缓存大小以及已使用缓存大小
3. 全局哈希表查找
快速、慢速流程都没找到缓存就会来到这步——在系统保存的哈希表进行链式查找
static SyncData* id2data(id object, enum usage why)
{
....
....
/*3. 全局哈希表查找*/
// 快速、慢速流程都没找到缓存就会来到这步——在系统保存的哈希表进行链式查找
lockp->lock(); // lockp->lock();`是在查找过程前后进行了加锁操作 是对锁进行加锁操作,确保在访问同步数据时的线程安全性。
{
SyncData* p;
SyncData* firstUnused = NULL; // 感觉是用来 寻找链表中未使用的SyncData并作标记
// 使用一个循环遍历同步数据列表,查找与给定对象匹配的同步数据项。
for (p = *listp; p != NULL; p = p->nextData) {
if ( p->object == object ) {
result = p; // 如果找到匹配项,将其赋值给 `result` 变量
// atomic because may collide with concurrent RELEASE
OSAtomicIncrement32Barrier(&result->threadCount); // 通过原子操作 `OSAtomicIncrement32Barrier` 增加该同步数据的线程计数(`threadCount`)。这是为了处理并发情况下的释放操作(`RELEASE`)可能与当前查找操作同时进行的情况。
goto done;
}
if ( (firstUnused == NULL) && (p->threadCount == 0) )
firstUnused = p;
}
// no SyncData currently associated with object 如果遍历过程中找不到与给定对象匹配的同步数据项
if ( (why == RELEASE) || (why == CHECK) ) // 则判断当前的操作类型(`why`)。如果是释放操作(`RELEASE`)或检查操作(`CHECK`),则跳转到 `done` 标签处结束。
goto done;
// an unused one was found, use it
if ( firstUnused != NULL ) { // 如果遍历过程中找到一个未被使用的同步数据项(
result = firstUnused; // 则将其作为可用的同步数据项,并将其关联到给定对象
result->object = (objc_object *)object;
result->threadCount = 1; // 然后将线程计数设置为 1,并跳转到 `done` 标签处结束。
goto done;
}
}
通过以上步骤,代码可以找到与给定对象关联的同步数据项,并进行相应的操作或返回。
- 如果找到匹配项,它会增加线程计数以表示当前线程正在使用该同步数据;
- 如果找不到匹配项,根据操作类型(如释放操作)可能会进行相应的处理。最终,通过
result变量返回找到的同步数据项或NULL值
4. 生成新数据并写入缓存
倘若前三步全均不符合 。即链表不存在——对象对于全部线程来说是第一次加锁)就会创建SyncData并存在result里。
// /*4. 生成新数据并写入缓存*/
posix_memalign((void **)&result, alignof(SyncData), sizeof(SyncData)); // 使用 posix_memalign 函数分配内存空间,并将其类型转换为 SyncData 结构体的指针。这样可以确保新的同步数据在内存中按照指定的对齐方式分配。
result->object = (objc_object *)object; // 将给定对象关联到新的同步数据项。
result->threadCount = 1; // 设置线程计数为 1。
new (&result->mutex) recursive_mutex_t(fork_unsafe_lock); // 使用定位 new 的方式在 result->mutex 成员变量上构造 recursive_mutex_t 对象,并使用 fork_unsafe_lock 作为初始值。
// new这一步和链表的初始化很相似。
result->nextData = *listp; // 将新的同步数据项插入到同步数据列表的头部,更新 *listp 的值为新的同步数据项。
*listp = result;
// 接下来,通过 done 标签进行清理和处理的步骤如下:
done:
lockp->unlock(); // 解锁 lockp,释放对锁的占用。
if (result) { // 检查 result 是否存在。如果存在,则表示是新的获取操作(ACQUIRE)。进一步处理该情况。
// Only new ACQUIRE should get here.
// All RELEASE and CHECK and recursive ACQUIRE are
// handled by the per-thread caches above.
if (why == RELEASE) { // 如果当前操作是释放操作(RELEASE)
// Probably some thread is incorrectly exiting 🉑️能表示某个线程在其他线程持有该对象时错误地退出。
// while the object is held by another thread.
return nil;
}
// 如果当前操作不是获取操作(ACQUIRE),则表示 id2data 函数存在错误
if (why != ACQUIRE) _objc_fatal("id2data is buggy");
// 检查 result->object 是否与给定对象匹配。如果不匹配,表示 id2data 函数存在错误。
if (result->object != object) _objc_fatal("id2data is buggy");
#if SUPPORT_DIRECT_THREAD_KEYS // 如果支持直接线程键(SUPPORT_DIRECT_THREAD_KEYS)
if (!fastCacheOccupied) { // 并且之前没有占用快速缓存(fastCacheOccupied),
// Save in fast thread cache
tls_set_direct(SYNC_DATA_DIRECT_KEY, result); // 则将新的同步数据项保存在快速线程缓存中。
tls_set_direct(SYNC_COUNT_DIRECT_KEY, (void*)1); // 同时,设置线程计数为 1。
} else
#endif
// 如果不满足上述条件,将新的同步数据项保存在线程缓存中。
{
// Save in thread cache
if (!cache) cache = fetch_cache(YES); // 首先获取当前线程的缓存(cache)
cache->list[cache->used].data = result; // ,并将新的同步数据项和线程计数保存到缓存列表中。
cache->list[cache->used].lockCount = 1;
cache->used++;
}
}
return result; // 函数返回 result,即找到或生成的同步数据项。
到这一步 该函数的作用就结束了。发现该函数不能实现快慢速的缓存查找,都会最终生成一个新的同步对象存在线程的缓存里面。
总结
多次锁同一个对象会有什么后果吗?
- 使用@
synchronized多次对同一个对象进行锁定不会导致任何后果或问题。每次执行@synchronized块时,会检查对象是否已被锁定,如果是,则当前线程会等待直到锁被释放。一旦锁被释放,线程可以再次获得该锁并继续执行。 - 多次锁定同一个对象可能会导致线程等待的时间增加,因为每次获取锁时都需要等待前一个锁释放。这可能会影响程序的性能。建议在确保必要性的情况下,尽量避免多次对同一个对象使用@
synchronized锁定。如果可能,可以使用其他同步机制来替代,例如使用GCD的串行队列或使用NSLock类。
加锁对象不能为nil,否则加锁无效,不能保证线程安全















 760
760











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









