






1. 有一列整数列A的DatraFrame,删除数值重复的行。
import numpy as np import pandas as pd df=pd.DataFrame([1,2,2,3,4,5,5,5,6,7,7],columns=['A']) print(df) df.drop_duplicates()
A 0 1 1 2 2 2 3 3 4 4 5 5 6 5 7 5 8 6 9 7 10 7
| A | |
|---|---|
| 0 | 1 |
| 1 | 2 |
| 3 | 3 |
| 4 | 4 |
| 5 | 5 |
| 8 | 6 |
| 9 | 7 |
2. 现有如下图所示的表格数据,请对该数据进行以下操作。
In [86]:
import numpy as np
import pandas as pd
from numpy import NaN
df=pd.DataFrame({'A':[1,4,5,NaN],
'B':[3,5,8,5.2],
'C':[2,7,NaN,9],
'D':[NaN,2,None,8.4]})
df
Out[86]:
| A | B | C | D | |
|---|---|---|---|---|
| 0 | 1.0 | 3.0 | 2.0 | NaN |
| 1 | 4.0 | 5.0 | 7.0 | 2.0 |
| 2 | 5.0 | 8.0 | NaN | NaN |
| 3 | NaN | 5.2 | 9.0 | 8.4 |
In [87]:
#(1)删除表格中的空值和缺失值。 df.dropna()
Out[87]:
| A | B | C | D | |
|---|---|---|---|---|
| 1 | 4.0 | 5.0 | 7.0 | 2.0 |
In [88]:
#(2) 将A列缺失的数据使用数字7.5填充,C列缺失的数据使用数字11填充。
df.fillna({'A':7.5,'C':11})
Out[88]:
| A | B | C | D | |
|---|---|---|---|---|
| 0 | 1.0 | 3.0 | 2.0 | NaN |
| 1 | 4.0 | 5.0 | 7.0 | 2.0 |
| 2 | 5.0 | 8.0 | 11.0 | NaN |
| 3 | 7.5 | 5.2 | 9.0 | 8.4 |
In [90]:
#(3) 将B列中的数据强制转换成int类型。 #强制转换成int 型 df['B'].astype(dtype='int') #df.dtypes #B列中有非数字类型的字符NaN,无法将其转换成int类型,若强制转换会出现ValueError异常
Out[90]:
0 3 1 5 2 8 3 5 Name: B, dtype: int32
In [91]:
#(4) 重命名列索引的名称为a,b,c,d, 并且在原有数据上进行修改。
df.rename(columns={'A':'a','B':'b','C':'c','D':'d'},inplace=True)
df
Out[91]:
| a | b | c | d | |
|---|---|---|---|---|
| 0 | 1.0 | 3.0 | 2.0 | NaN |
| 1 | 4.0 | 5.0 | 7.0 | 2.0 |
| 2 | 5.0 | 8.0 | NaN | NaN |
| 3 | NaN | 5.2 | 9.0 | 8.4 |
3. 现有如下图所示的表格数据,使用后向填充的方式填充缺失的数据。
In [25]:
import numpy as np
import pandas as pd
from numpy import NaN
df=pd.DataFrame({'A':[1,2,3,NaN],
'B':[NaN,4,NaN,6],
'C':['a',7,8,9],
'D':[NaN,2,3,NaN]})
df
Out[25]:
| A | B | C | D | |
|---|---|---|---|---|
| 0 | 1.0 | NaN | a | NaN |
| 1 | 2.0 | 4.0 | 7 | 2.0 |
| 2 | 3.0 | NaN | 8 | 3.0 |
| 3 | NaN | 6.0 | 9 | NaN |
In [26]:
df.fillna(method='bfill')
Out[26]:
| A | B | C | D | |
|---|---|---|---|---|
| 0 | 1.0 | 4.0 | a | 2.0 |
| 1 | 2.0 | 4.0 | 7 | 2.0 |
| 2 | 3.0 | 6.0 | 8 | 3.0 |
| 3 | NaN | 6.0 | 9 | NaN |
4. 现有如下图所示的表格数据,从前向后查找和判断是否有重复的数据并将重复值删除。
In [28]:
import pandas as pd
person_info = pd.DataFrame({'id':[1,2,3,4,5,4],
'name':['小铭','小月','彭岩','刘华','周华','刘华'],
'age':[18,18,29,58,36,58],
'height':[180, 180, 185,175,178,175],
'gender':['女','女','男','男','男','男']})
print(person_info)
person_info.duplicated()#从前向后查找和判断是否有重复值
id name age height gender 0 1 小铭 18 180 女 1 2 小月 18 180 女 2 3 彭岩 29 185 男 3 4 刘华 58 175 男 4 5 周华 36 178 男 5 4 刘华 58 175 男
Out[28]:
0 False 1 False 2 False 3 False 4 False 5 True dtype: bool
In [29]:
#删除重复值 person_info.drop_duplicates()
Out[29]:
| id | name | age | height | gender | |
|---|---|---|---|---|---|
| 0 | 1 | 小铭 | 18 | 180 | 女 |
| 1 | 2 | 小月 | 18 | 180 | 女 |
| 2 | 3 | 彭岩 | 29 | 185 | 男 |
| 3 | 4 | 刘华 | 58 | 175 | 男 |
| 4 | 5 | 周华 | 36 | 178 | 男 |
5. 现有如下图所示的表格数据,横向堆叠合并df1和df2,采用外连接的方式。
In [34]:
import pandas as pd
df1=pd.DataFrame({'A':['A0','A0','A1'],'B':['B0','B0','B1']})
df2=pd.DataFrame({'C':['C0','C0','C1','C3'],'D':['D0','D2','D2','D3']})
#横向堆叠合并df1和df2,采用外连接的方式
print(df1)
print(df2)
pd.concat([df1,df2],join='outer',axis=1)
A B
0 A0 B0
1 A0 B0
2 A1 B1
C D
0 C0 D0
1 C0 D2
2 C1 D2
3 C3 D3
Out[34]:
| A | B | C | D | |
|---|---|---|---|---|
| 0 | A0 | B0 | C0 | D0 |
| 1 | A0 | B0 | C0 | D2 |
| 2 | A1 | B1 | C1 | D2 |
| 3 | NaN | NaN | C3 | D3 |
6. 现有如下图所示的两组数据,其中A组中B列数据存在缺失值,并且该列数据为int类型,B组中的数据均为str类型。
In [15]:
#(1) 使用DataFrame创建这两组数据。
import pandas as pd
import numpy as np
group_a = pd.DataFrame({'A': [2,3,5,2,3],
'B': ['5',np.nan,'2','3','6'],
'C': [8,7,50,8,2],
'key': [3,4,5,2,5]})
group_b = pd.DataFrame({'A': [3,4,5],
'B': [3,4,5],
'C': [3,4,5]})
print(group_a)
print(group_b)
A B C key 0 2 5 8 3 1 3 NaN 7 4 2 5 2 50 5 3 2 3 8 2 4 3 6 2 5 A B C 0 3 3 3 1 4 4 4 2 5 5 5
In [16]:
#(2) 使用B组中的数据对A组中的缺失值进行填充,并保持数据类型一致。 group_a = group_a.combine_first(group_b) group_a
Out[16]:
| A | B | C | key | |
|---|---|---|---|---|
| 0 | 2 | 5 | 8 | 3 |
| 1 | 3 | 4 | 7 | 4 |
| 2 | 5 | 2 | 50 | 5 |
| 3 | 2 | 3 | 8 | 2 |
| 4 | 3 | 6 | 2 | 5 |
In [41]:
#(3) 将合并后A组中索引名为key的索引重命名为D。
group_a.rename(columns={'key':'D'})
Out[41]:
| A | B | C | D | |
|---|---|---|---|---|
| 0 | 2 | 5 | 8 | 3 |
| 1 | 3 | 4.0 | 7 | 4 |
| 2 | 5 | 2 | 50 | 5 |
| 3 | 2 | 3 | 8 | 2 |
| 4 | 3 | 6 | 2 | 5 |
7. 有如下一组数据:example_data= [1222, 87, 77, 92, 68, 80, 78, 84, 77, 81, 80, 80, 77, 92, 86, 76, 80, 81, 75, 77, 72, 81, 72, 84, 86, 80, 68, 77, 87, 76, 77, 78, 92, 75, 80, 78, 123, 3, 1223, 1232]
In [45]:
#自定义一个基于的函数,用于检测一组数据中是否含有异常值
import numpy as np
#ser1表示传入DataFrame的某一列
def three_sigma(ser1):
#求平均值
mean_value=ser1.mean()
#求标准差
std_value=ser1.std()
#位于(μ-30,μ+30)区间的数据是正常的,不在这个区间的数据为异常的
#ser1中的数值小于1-30或大于μ+30均为异常值
# 一旦发现有异常值,就标注为True,否则标注为False
rule=(mean_value-3*std_value>ser1)|(ser1.mean()+3*ser1.std()<ser1)
#返回异常值的位置索引
index=np.arange(ser1.shape[0])[rule]
#获取异常数据
outrange=ser1.iloc[index]
return outrange
In [46]:
# 创建数据
import pandas as pd
example_data = [1222, 87, 77, 92, 68, 80, 78, 84, 77, 81, 80, 80,
77, 92, 86, 76, 80, 81, 75, 77, 72, 81, 72, 84, 86,
80,68, 77, 87, 76, 77, 78, 92, 75, 80, 78, 123, 3, 1223, 1232]
df=pd.DataFrame(example_data,columns=['A'])
df
Out[46]:
| A | |
|---|---|
| 0 | 1222 |
| 1 | 87 |
| 2 | 77 |
| 3 | 92 |
| 4 | 68 |
| 5 | 80 |
| 6 | 78 |
| 7 | 84 |
| 8 | 77 |
| 9 | 81 |
| 10 | 80 |
| 11 | 80 |
| 12 | 77 |
| 13 | 92 |
| 14 | 86 |
| 15 | 76 |
| 16 | 80 |
| 17 | 81 |
| 18 | 75 |
| 19 | 77 |
| 20 | 72 |
| 21 | 81 |
| 22 | 72 |
| 23 | 84 |
| 24 | 86 |
| 25 | 80 |
| 26 | 68 |
| 27 | 77 |
| 28 | 87 |
| 29 | 76 |
| 30 | 77 |
| 31 | 78 |
| 32 | 92 |
| 33 | 75 |
| 34 | 80 |
| 35 | 78 |
| 36 | 123 |
| 37 | 3 |
| 38 | 1223 |
| 39 | 1232 |
In [47]:
#(1)基于3σ原则,检测数据example_data中是否存在异常值。 three_sigma(df['A'])
Out[47]:
0 1222 38 1223 39 1232 Name: A, dtype: int64
In [74]:
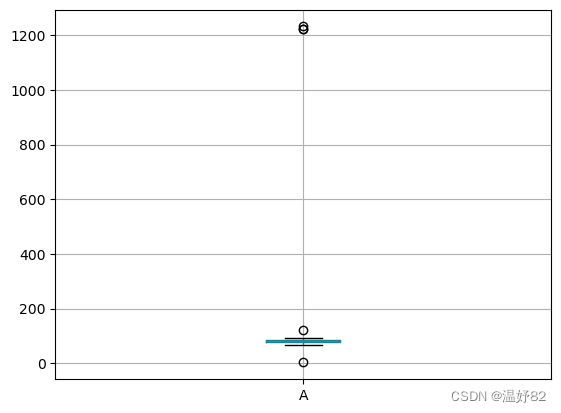
#(2) 利用箱型图检测数据example_data中是否存在异常值。 df.boxplot(column=['A'])
Out[74]:
<AxesSubplot:>
8. 有如下两个表格数据表1和表2,请通过合并重叠数据的方式填充缺失数据得到表3。
In [32]:
c=[0,1,2] i=[[3.9,3,5],[np.nan,4.6,np.nan],[np.nan,7,np.nan]] a=pd.DataFrame(i,columns=c) a
Out[32]:
| 0 | 1 | 2 | |
|---|---|---|---|
| 0 | 3.9 | 3.0 | 5.0 |
| 1 | NaN | 4.6 | NaN |
| 2 | NaN | 7.0 | NaN |
In [35]:
c=[1,2] i=[[42,np.nan,8.2],[10,7,4]] b=pd.DataFrame(i,index=c) b
Out[35]:
| 0 | 1 | 2 | |
|---|---|---|---|
| 1 | 42 | NaN | 8.2 |
| 2 | 10 | 7.0 | 4.0 |
In [37]:
a.combine_first(b)#合并重叠数据,用b的数据填充a缺失的部分
Out[37]:
| 0 | 1 | 2 | |
|---|---|---|---|
| 0 | 3.9 | 3.0 | 5.0 |
| 1 | 42.0 | 4.6 | 8.2 |
| 2 | 10.0 | 7.0 | 4.0 |
9. 读取missing_data.xls表中的数据,判断是否存在缺失值,如存在,采用前向填充的方式处理缺失值。
In [101]:
import numpy as np import pandas as pd file_data=pd.read_excel(r'F:\实训\数据分析实训\项目三 数据预处理练习\missing_data.xls') file_data
Out[101]:
| 235.8333 | 324.0343 | 478.3231 | |
|---|---|---|---|
| 0 | 236.2708 | 325.6379 | 515.4564 |
| 1 | 238.0521 | 328.0897 | 517.0909 |
| 2 | 235.9063 | NaN | 514.8900 |
| 3 | 236.7604 | 268.8324 | NaN |
| 4 | NaN | 404.0480 | 486.0912 |
| 5 | 237.4167 | 391.2652 | 516.2330 |
| 6 | 238.6563 | 380.8241 | NaN |
| 7 | 237.6042 | 388.0230 | 435.3508 |
| 8 | 238.0313 | 206.4349 | 487.6750 |
| 9 | 235.0729 | NaN | NaN |
| 10 | 235.5313 | 400.0787 | 660.2347 |
| 11 | NaN | 411.2069 | 621.2346 |
| 12 | 234.4688 | 395.2343 | 611.3408 |
| 13 | 235.5000 | 344.8221 | 643.0863 |
| 14 | 235.6354 | 385.6432 | 642.3482 |
| 15 | 234.5521 | 401.6234 | NaN |
| 16 | 236.0000 | 409.6489 | 602.9347 |
| 17 | 235.2396 | 416.8795 | 589.3457 |
| 18 | 235.4896 | NaN | 556.3452 |
| 19 | 236.9688 | NaN | 538.3470 |
In [102]:
#判断是否存在缺失值 file_data.isnull()
Out[102]:
| 235.8333 | 324.0343 | 478.3231 | |
|---|---|---|---|
| 0 | False | False | False |
| 1 | False | False | False |
| 2 | False | True | False |
| 3 | False | False | True |
| 4 | True | False | False |
| 5 | False | False | False |
| 6 | False | False | True |
| 7 | False | False | False |
| 8 | False | False | False |
| 9 | False | True | True |
| 10 | False | False | False |
| 11 | True | False | False |
| 12 | False | False | False |
| 13 | False | False | False |
| 14 | False | False | False |
| 15 | False | False | True |
| 16 | False | False | False |
| 17 | False | False | False |
| 18 | False | True | False |
| 19 | False | True | False |
In [104]:
file_data.fillna(method='ffill')#前向填充ffill处理缺失值
Out[104]:
| 235.8333 | 324.0343 | 478.3231 | |
|---|---|---|---|
| 0 | 236.2708 | 325.6379 | 515.4564 |
| 1 | 238.0521 | 328.0897 | 517.0909 |
| 2 | 235.9063 | 328.0897 | 514.8900 |
| 3 | 236.7604 | 268.8324 | 514.8900 |
| 4 | 236.7604 | 404.0480 | 486.0912 |
| 5 | 237.4167 | 391.2652 | 516.2330 |
| 6 | 238.6563 | 380.8241 | 516.2330 |
| 7 | 237.6042 | 388.0230 | 435.3508 |
| 8 | 238.0313 | 206.4349 | 487.6750 |
| 9 | 235.0729 | 206.4349 | 487.6750 |
| 10 | 235.5313 | 400.0787 | 660.2347 |
| 11 | 235.5313 | 411.2069 | 621.2346 |
| 12 | 234.4688 | 395.2343 | 611.3408 |
| 13 | 235.5000 | 344.8221 | 643.0863 |
| 14 | 235.6354 | 385.6432 | 642.3482 |
| 15 | 234.5521 | 401.6234 | 642.3482 |
| 16 | 236.0000 | 409.6489 | 602.9347 |
| 17 | 235.2396 | 416.8795 | 589.3457 |
| 18 | 235.4896 | 416.8795 | 556.3452 |
| 19 | 236.9688 | 416.8795 | 538.3470 |
10. 读取ele_loss.csv和alarm.csv表数据,查看两个表的形状,以ID和data两个键作为主键进行内连接,查看合并后的数据。
In [112]:
import numpy as np import pandas as pd file1=open(r'F:\实训\数据分析实训\项目三 数据预处理练习\ele_loss.csv') file1_data=pd.read_csv(file1) file1_data
Out[112]:
| ID | date | ele | loss | |
|---|---|---|---|---|
| 0 | 21261001 | 2010/9/1 | 1091.5 | 0.169615 |
| 1 | 21261001 | 2010/9/2 | 1079.5 | 0.145556 |
| 2 | 21261001 | 2010/9/3 | 858.0 | 0.151048 |
| 3 | 21261001 | 2010/9/6 | 883.5 | 0.162778 |
| 4 | 21261001 | 2010/9/7 | 1027.5 | 0.133186 |
| 5 | 21261001 | 2010/9/8 | 997.0 | 0.159571 |
| 6 | 21261001 | 2010/9/9 | 1022.0 | 0.184799 |
| 7 | 21261001 | 2010/9/10 | 991.0 | 0.153268 |
| 8 | 21261001 | 2010/9/13 | 788.5 | 0.154878 |
| 9 | 21261001 | 2010/9/14 | 792.5 | 0.154881 |
| 10 | 21261001 | 2010/9/15 | 923.5 | 0.156584 |
| 11 | 21261001 | 2010/9/16 | 915.5 | 0.162028 |
| 12 | 21261001 | 2010/9/17 | 961.0 | 0.166650 |
| 13 | 21261001 | 2010/9/20 | 1160.5 | 0.156170 |
| 14 | 21261001 | 2010/9/21 | 921.0 | 0.160503 |
| 15 | 21261001 | 2010/9/27 | 957.5 | 0.180380 |
| 16 | 21261001 | 2010/9/28 | 1048.0 | 0.180077 |
| 17 | 21261001 | 2010/9/29 | 889.0 | 0.164753 |
| 18 | 21261001 | 2010/9/30 | 668.0 | 0.165815 |
| 19 | 21261001 | 2010/10/8 | 562.0 | 0.172527 |
| 20 | 21261001 | 2010/10/11 | 545.0 | 0.177149 |
| 21 | 21261001 | 2010/10/12 | 685.0 | 0.175806 |
| 22 | 21261001 | 2010/10/13 | 762.0 | 0.170726 |
| 23 | 21261001 | 2010/10/14 | 837.5 | 0.208254 |
| 24 | 21261001 | 2010/10/15 | 635.5 | 0.180619 |
| 25 | 21261001 | 2010/10/18 | 693.5 | 0.207981 |
| 26 | 21261001 | 2010/10/19 | 660.0 | 0.188989 |
| 27 | 21261001 | 2010/10/20 | 540.5 | 0.184330 |
| 28 | 21261001 | 2010/10/21 | 445.0 | 0.180350 |
| 29 | 21261001 | 2010/10/22 | 416.0 | 0.179278 |
| 30 | 21261001 | 2010/10/25 | 507.0 | 0.186143 |
| 31 | 21261001 | 2010/10/26 | 416.5 | 0.181382 |
| 32 | 21261001 | 2010/10/27 | 414.5 | 0.211829 |
| 33 | 21261001 | 2010/10/28 | 363.0 | 0.244156 |
| 34 | 21261001 | 2010/10/29 | 353.5 | 0.226345 |
| 35 | 21261001 | 2010/11/1 | 363.0 | 0.221923 |
| 36 | 21261001 | 2010/11/3 | 400.5 | 0.231142 |
| 37 | 21261001 | 2010/11/4 | 368.5 | 0.243218 |
| 38 | 21261001 | 2010/11/5 | 364.0 | 0.269537 |
| 39 | 21261001 | 2010/11/8 | 378.0 | 0.194556 |
| 40 | 21261001 | 2010/11/9 | 390.5 | 0.229689 |
| 41 | 21261001 | 2010/11/10 | 400.0 | 0.220326 |
| 42 | 21261001 | 2010/11/11 | 351.0 | 0.219265 |
| 43 | 21261001 | 2010/11/12 | 336.0 | 0.248774 |
| 44 | 21261001 | 2010/11/15 | 401.0 | 0.199438 |
| 45 | 21261001 | 2010/11/16 | 445.0 | 0.206474 |
| 46 | 21261001 | 2010/11/17 | 447.0 | 0.203799 |
| 47 | 21261001 | 2010/11/18 | 422.5 | 0.238839 |
| 48 | 21261001 | 2010/11/19 | 438.5 | 0.205163 |
In [113]:
file2=open(r'F:\实训\数据分析实训\项目三 数据预处理练习\alarm.csv') file2_data=pd.read_csv(file2) file2_data
Out[113]:
| ID | date | alarm | |
|---|---|---|---|
| 0 | 21261001 | 2012/10/11 | 电压断相 |
| 1 | 21261001 | 2012/10/10 | A相电流过负荷 |
| 2 | 21261001 | 2010/9/3 | 电流不平衡 |
| 3 | 21261001 | 2010/9/6 | C相电流过负荷 |
| 4 | 21261001 | 2010/5/13 | 电流不平衡 |
| 5 | 21261001 | 2010/5/12 | 电压缺相 |
| 6 | 21261001 | 2010/2/15 | 电流不平衡 |
| 7 | 21261001 | 2010/9/16 | C相电流过负荷 |
| 8 | 21261001 | 2010/9/17 | A相电流过负荷 |
| 9 | 21261001 | 2011/9/15 | C相电流过负荷 |
| 10 | 21261001 | 2010/8/11 | 电压断相 |
| 11 | 21261001 | 2010/9/16 | C相电流过负荷 |
| 12 | 21261001 | 2010/9/17 | 电流不平衡 |
| 13 | 21261001 | 2010/7/20 | 电压断相 |
| 14 | 18403001 | 2010/7/21 | C相电流过负荷 |
| 15 | 18403001 | 2010/7/22 | 电压缺相 |
| 16 | 18403001 | 2010/7/25 | C相电流过负荷 |
| 17 | 21880001 | 2010/11/4 | 电流不平衡 |
| 18 | 21880001 | 2010/11/1 | A相电流过负荷 |
| 19 | 21880001 | 2011/1/9 | C相电流过负荷 |
| 20 | 16345001 | 2010/7/15 | 电压缺相 |
| 21 | 16940001 | 2010/10/24 | 电流不平衡 |
| 22 | 16429001 | 2010/2/28 | 电压断相 |
| 23 | 16429001 | 2010/3/1 | A相电流过负荷 |
| 24 | 17059001 | 2011/12/15 | 电流不平衡 |
In [114]:
pd.merge(file1_data,file2_data,on=['ID','date'])
Out[114]:
| ID | date | ele | loss | alarm | |
|---|---|---|---|---|---|
| 0 | 21261001 | 2010/9/3 | 858.0 | 0.151048 | 电流不平衡 |
| 1 | 21261001 | 2010/9/6 | 883.5 | 0.162778 | C相电流过负荷 |
| 2 | 21261001 | 2010/9/16 | 915.5 | 0.162028 | C相电流过负荷 |
| 3 | 21261001 | 2010/9/16 | 915.5 | 0.162028 | C相电流过负荷 |
| 4 | 21261001 | 2010/9/17 | 961.0 | 0.166650 | A相电流过负荷 |
| 5 | 21261001 | 2010/9/17 | 961.0 | 0.166650 | 电流不平衡 |
11. 删除数据——探索Iris纸鸢花数据
In [4]:
#导入必要的库 import pandas as pd import numpy as np #从目标地址导入数据集 file11='F:\实训\数据分析实训\项目三 数据预处理练习\iris.data'
Out[4]:
'F:\\实训\\数据分析实训\\项目三 数据预处理练习\\iris.data'
In [3]:
#(1) 将数据集存成变量iris iris = pd.read_csv(file11) iris.head()
Out[3]:
| 5.1 | 3.5 | 1.4 | 0.2 | Iris-setosa | |
|---|---|---|---|---|---|
| 0 | 4.9 | 3.0 | 1.4 | 0.2 | Iris-setosa |
| 1 | 4.7 | 3.2 | 1.3 | 0.2 | Iris-setosa |
| 2 | 4.6 | 3.1 | 1.5 | 0.2 | Iris-setosa |
| 3 | 5.0 | 3.6 | 1.4 | 0.2 | Iris-setosa |
| 4 | 5.4 | 3.9 | 1.7 | 0.4 | Iris-setosa |
In [5]:
#(2) 创建数据框的列名称['sepal_length','sepal_width', 'petal_length', 'petal_width', 'class'] iris = pd.read_csv(file11,names = ['sepal_length','sepal_width','petal_length','petal_width','class']) iris.head()
Out[5]:
| sepal_length | sepal_width | petal_length | petal_width | class | |
|---|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 | Iris-setosa |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 | Iris-setosa |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 | Iris-setosa |
| 3 | 4.6 | 3.1 | 1.5 | 0.2 | Iris-setosa |
| 4 | 5.0 | 3.6 | 1.4 | 0.2 | Iris-setosa |
In [6]:
#(3) 数据框中有缺失值吗? pd.isnull(iris).sum()
Out[6]:
sepal_length 0 sepal_width 0 petal_length 0 petal_width 0 class 0 dtype: int64
In [7]:
#(4) 将列petal_length的第10到19行设置为缺失值 iris.iloc[10:20,2:3] = np.nan iris.head(20)
Out[7]:
| sepal_length | sepal_width | petal_length | petal_width | class | |
|---|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 | Iris-setosa |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 | Iris-setosa |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 | Iris-setosa |
| 3 | 4.6 | 3.1 | 1.5 | 0.2 | Iris-setosa |
| 4 | 5.0 | 3.6 | 1.4 | 0.2 | Iris-setosa |
| 5 | 5.4 | 3.9 | 1.7 | 0.4 | Iris-setosa |
| 6 | 4.6 | 3.4 | 1.4 | 0.3 | Iris-setosa |
| 7 | 5.0 | 3.4 | 1.5 | 0.2 | Iris-setosa |
| 8 | 4.4 | 2.9 | 1.4 | 0.2 | Iris-setosa |
| 9 | 4.9 | 3.1 | 1.5 | 0.1 | Iris-setosa |
| 10 | 5.4 | 3.7 | NaN | 0.2 | Iris-setosa |
| 11 | 4.8 | 3.4 | NaN | 0.2 | Iris-setosa |
| 12 | 4.8 | 3.0 | NaN | 0.1 | Iris-setosa |
| 13 | 4.3 | 3.0 | NaN | 0.1 | Iris-setosa |
| 14 | 5.8 | 4.0 | NaN | 0.2 | Iris-setosa |
| 15 | 5.7 | 4.4 | NaN | 0.4 | Iris-setosa |
| 16 | 5.4 | 3.9 | NaN | 0.4 | Iris-setosa |
| 17 | 5.1 | 3.5 | NaN | 0.3 | Iris-setosa |
| 18 | 5.7 | 3.8 | NaN | 0.3 | Iris-setosa |
| 19 | 5.1 | 3.8 | NaN | 0.3 | Iris-setosa |
In [8]:
#(5) 将petal_lengt缺失值全部替换为1.0 iris.petal_length.fillna(1,inplace = True) iris
Out[8]:
| sepal_length | sepal_width | petal_length | petal_width | class | |
|---|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 | Iris-setosa |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 | Iris-setosa |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 | Iris-setosa |
| 3 | 4.6 | 3.1 | 1.5 | 0.2 | Iris-setosa |
| 4 | 5.0 | 3.6 | 1.4 | 0.2 | Iris-setosa |
| ... | ... | ... | ... | ... | ... |
| 145 | 6.7 | 3.0 | 5.2 | 2.3 | Iris-virginica |
| 146 | 6.3 | 2.5 | 5.0 | 1.9 | Iris-virginica |
| 147 | 6.5 | 3.0 | 5.2 | 2.0 | Iris-virginica |
| 148 | 6.2 | 3.4 | 5.4 | 2.3 | Iris-virginica |
| 149 | 5.9 | 3.0 | 5.1 | 1.8 | Iris-virginica |
150 rows × 5 columns
In [9]:
#(6) 删除列class del iris['class'] iris.head()
Out[9]:
| sepal_length | sepal_width | petal_length | petal_width | |
|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 |
| 3 | 4.6 | 3.1 | 1.5 | 0.2 |
| 4 | 5.0 | 3.6 | 1.4 | 0.2 |
In [10]:
#(7) 将数据框前三行设置为缺失值 iris.iloc[0:3,:] = np.nan iris.head()
Out[10]:
| sepal_length | sepal_width | petal_length | petal_width | |
|---|---|---|---|---|
| 0 | NaN | NaN | NaN | NaN |
| 1 | NaN | NaN | NaN | NaN |
| 2 | NaN | NaN | NaN | NaN |
| 3 | 4.6 | 3.1 | 1.5 | 0.2 |
| 4 | 5.0 | 3.6 | 1.4 | 0.2 |
In [11]:
#(8) 删除有缺失值的行 iris = iris.dropna(how = 'any') iris.head()
Out[11]:
| sepal_length | sepal_width | petal_length | petal_width | |
|---|---|---|---|---|
| 3 | 4.6 | 3.1 | 1.5 | 0.2 |
| 4 | 5.0 | 3.6 | 1.4 | 0.2 |
| 5 | 5.4 | 3.9 | 1.7 | 0.4 |
| 6 | 4.6 | 3.4 | 1.4 | 0.3 |
| 7 | 5.0 | 3.4 | 1.5 | 0.2 |
In [12]:
#(9) 重新设置索引 iris = iris.reset_index(drop = True) iris.head()
Out[12]:
| sepal_length | sepal_width | petal_length | petal_width | |
|---|---|---|---|---|
| 0 | 4.6 | 3.1 | 1.5 | 0.2 |
| 1 | 5.0 | 3.6 | 1.4 | 0.2 |
| 2 | 5.4 | 3.9 | 1.7 | 0.4 |
| 3 | 4.6 | 3.4 | 1.4 | 0.3 |
| 4 | 5.0 | 3.4 | 1.5 | 0.2 |
12.泰坦尼克数据预处理
In [36]:
#(1) 读取数据 file12=open(r'F:\实训\数据分析实训\项目三 数据预处理练习\titanic_train.csv') tk=pd.read_csv(file12) tk # passengerId:旅客 id;survived:0 代表遇难,1 代表存活;pclass:舱位,1-3 分别代表一二三等舱; # name:旅客姓名;sex:旅客性别;age:年龄; # sibsp:船上的同代亲属人数,如兄弟姐妹;parch:船上的非同代亲属人数,如父母子女; # ticket:船票编号;fare:船票价格;cabin:客舱号;embarked:登船港口
Out[36]:
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S |
| 4 | 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 886 | 887 | 0 | 2 | Montvila, Rev. Juozas | male | 27.0 | 0 | 0 | 211536 | 13.0000 | NaN | S |
| 887 | 888 | 1 | 1 | Graham, Miss. Margaret Edith | female | 19.0 | 0 | 0 | 112053 | 30.0000 | B42 | S |
| 888 | 889 | 0 | 3 | Johnston, Miss. Catherine Helen "Carrie" | female | NaN | 1 | 2 | W./C. 6607 | 23.4500 | NaN | S |
| 889 | 890 | 1 | 1 | Behr, Mr. Karl Howell | male | 26.0 | 0 | 0 | 111369 | 30.0000 | C148 | C |
| 890 | 891 | 0 | 3 | Dooley, Mr. Patrick | male | 32.0 | 0 | 0 | 370376 | 7.7500 | NaN | Q |
891 rows × 12 columns
In [59]:
#(2) 统计age列缺失值的个数 tk.Age.isnull().sum() print(tk.Age.isnull().sum())
177
In [60]:
#(3) 去掉Age和Sex这两列带有缺失值的行 tk.dropna(axis=0,subset=['Age','Sex'])
Out[60]:
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S |
| 4 | 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 885 | 886 | 0 | 3 | Rice, Mrs. William (Margaret Norton) | female | 39.0 | 0 | 5 | 382652 | 29.1250 | NaN | Q |
| 886 | 887 | 0 | 2 | Montvila, Rev. Juozas | male | 27.0 | 0 | 0 | 211536 | 13.0000 | NaN | S |
| 887 | 888 | 1 | 1 | Graham, Miss. Margaret Edith | female | 19.0 | 0 | 0 | 112053 | 30.0000 | B42 | S |
| 889 | 890 | 1 | 1 | Behr, Mr. Karl Howell | male | 26.0 | 0 | 0 | 111369 | 30.0000 | C148 | C |
| 890 | 891 | 0 | 3 | Dooley, Mr. Patrick | male | 32.0 | 0 | 0 | 370376 | 7.7500 | NaN | Q |
714 rows × 12 columns
In [132]:
#(4) 根据“Age”的大小逆序排列 tk.sort_values(by='Age',ascending=False)
Out[132]:
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 630 | 631 | 1 | 1 | Barkworth, Mr. Algernon Henry Wilson | male | 80.0 | 0 | 0 | 27042 | 30.0000 | A23 | S |
| 851 | 852 | 0 | 3 | Svensson, Mr. Johan | male | 74.0 | 0 | 0 | 347060 | 7.7750 | NaN | S |
| 493 | 494 | 0 | 1 | Artagaveytia, Mr. Ramon | male | 71.0 | 0 | 0 | PC 17609 | 49.5042 | NaN | C |
| 96 | 97 | 0 | 1 | Goldschmidt, Mr. George B | male | 71.0 | 0 | 0 | PC 17754 | 34.6542 | A5 | C |
| 116 | 117 | 0 | 3 | Connors, Mr. Patrick | male | 70.5 | 0 | 0 | 370369 | 7.7500 | NaN | Q |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 859 | 860 | 0 | 3 | Razi, Mr. Raihed | male | NaN | 0 | 0 | 2629 | 7.2292 | NaN | C |
| 863 | 864 | 0 | 3 | Sage, Miss. Dorothy Edith "Dolly" | female | NaN | 8 | 2 | CA. 2343 | 69.5500 | NaN | S |
| 868 | 869 | 0 | 3 | van Melkebeke, Mr. Philemon | male | NaN | 0 | 0 | 345777 | 9.5000 | NaN | S |
| 878 | 879 | 0 | 3 | Laleff, Mr. Kristo | male | NaN | 0 | 0 | 349217 | 7.8958 | NaN | S |
| 888 | 889 | 0 | 3 | Johnston, Miss. Catherine Helen "Carrie" | female | NaN | 1 | 2 | W./C. 6607 | 23.4500 | NaN | S |
891 rows × 12 columns
In [61]:
#(5) 求船员年龄的平均数(排除缺失值) tk['Age'].mean()
Out[61]:
29.69911764705882
In [66]:
#(6) 计算每类船舱对应的平均票价(pivot_table)
#tk.groupby('Pclass')['Fare'].mean()
#三个参数:index:表示接下来要统计的信息是以谁为基准的,index就=谁(每个船舱等级对应的平均票价,所以index = Pclass船舱等级)
# values:表示用统计Pclass与谁之间的关系,values就=谁(Pclass与票价之间的关系,values = Fare)
# aggfunc:表示Pclass与Fare之间的什么关系,求的是船舱等级与票价的平均值之间的关系,所以aggfunc=np.mean()
tk_pj= tk.pivot_table(index = "Pclass",
values = "Fare",
aggfunc = np.mean)
tk_pj
Out[66]:
| Fare | |
|---|---|
| Pclass | |
| 1 | 84.154687 |
| 2 | 20.662183 |
| 3 | 13.675550 |
In [67]:
#(7) 求每类船舱对应的平均存活率(pivot_table)
#三个参数:index:表示接下来要统计的信息是以谁为基准的,index就=谁(每个船舱等级对应的平均存活率,所以index = Pclass船舱等级)
# values:表示用统计Pclass与谁之间的关系,values就=谁(Pclass与存活率之间的关系,values = Survived)
# aggfunc:表示Pclass与Survived之间的什么关系,求的是船舱等级的平均存活率的关系,所以aggfunc=np.mean()
tk_chl= tk.pivot_table(index = "Pclass",
values = "Survived",
aggfunc = np.mean)
tk_chl
Out[67]:
| Survived | |
|---|---|
| Pclass | |
| 1 | 0.629630 |
| 2 | 0.472826 |
| 3 | 0.242363 |
In [68]:
#(8) 求不同船舱等级乘客的平均年龄(pivot_table)
tk_nl= tk.pivot_table(index = "Pclass",
values = "Age",
aggfunc = np.mean)
tk_nl
Out[68]:
| Age | |
|---|---|
| Pclass | |
| 1 | 38.233441 |
| 2 | 29.877630 |
| 3 | 25.140620 |
In [69]:
#(9) 计算不同的登船地点(C,Q,S)对应的总票价和总获救人数。(pivot_table)
#用.pivot_table()的话,对于index ,接下来要统计的东西是以登船地点为基准的,所以index = "Embarked"
#对于values,要统计的是不同登船地点与票价和是否获救之间的关系,所以values = ["Fare","Survived" ]
#对于aggfunc,要统计的是不同登船地点的总的票价和总的获救人数,所以aggfunc = np.sum
tk_9= tk.pivot_table(index = "Embarked",
values =["Fare","Survived"],
aggfunc = np.sum)
tk_9
Out[69]:
| Fare | Survived | |
|---|---|---|
| Embarked | ||
| C | 10072.2962 | 93 |
| Q | 1022.2543 | 30 |
| S | 17439.3988 | 217 |















 3743
3743











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









