






现有如下图所示的数据,请对该数据进行以下操作:
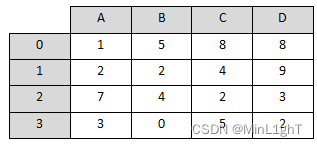
- 使用DataFrame创建该数据。
- 将图中的B列数据进行按降序排序。
- 将排序后的数据写入到csv文件,并命名为write_data.csv。
import pandas as pd
# (1)使用DataFrame创建该数据
data = {
'A': [1, 2, 7, 3],
'B': [5, 2, 4, 0],
'C': [8, 4, 2, 5],
'D': [8, 9, 3, 2]
}
df = pd.DataFrame(data)
# (2)将图中的B列数据进行按降序排序
df.sort_values(by='B', ascending=False, inplace=True)
# (3)将排序后的数据写入到csv文件
df.to_csv('write_data.csv', index=False)
现有如下图所示的两组数据,其中 A组中B列数据存在缺失值,并且该列数据为int类型,B组中的数据均为str类型。接下来,请对这些数据进行以下操作:
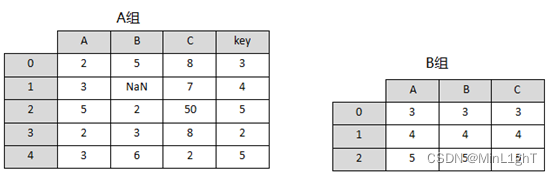
- 使用DataFrame创建这两组数据。
- 现在需要使用B组中的数据对A组中的缺失值进行填充并保持数据类型一致。
- 将合并后A组中索引名为key的索引重命名为D。
import pandas as pd
import numpy as np
# (1)使用DataFrame创建这两组数据
data_A = {
'A': [2, 3, 5, 2, 3],
'B': [5, np.nan, 2, 3, 6],
'C': [8, 7, 50, 8, 2],
'key': [3, 4, 5, 2, 5]
}
data_B = {
'A': ['3', '4', '5'],
'B': ['3', '4', '5'],
'C': ['3', '4', '5']
}
df_A = pd.DataFrame(data_A)
df_B = pd.DataFrame(data_B)
# (2)现在需要使用B组中的数据对A组中的缺失值进行填充并保持数据类型一致
df_A = df_A.combine_first(df_B)
# (3)将合并后A组中索引名为key的索引重命名为D
df_A.rename(columns={'key': 'D'})
现有如下图所示的学生信息,请根据图中的信息完成以下操作:
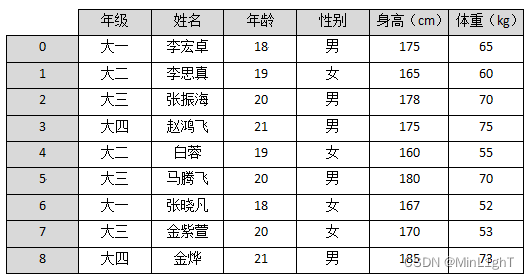
- 根据年级信息为分组键,对学生信息进行分组,并输出大一学生信息。
- 分别计算出四个年级中身高最高的同学。
- 计算大一学生与大三学生的平均体重。
import pandas as pd
# 创建数据
data = {
'年级': ['大一', '大二', '大三', '大四', '大二', '大三', '大一', '大三', '大四'],
'姓名': ['李宏卓','李思真','张振海','赵鸿飞','白蓉','马腾飞','张晓凡','金紫萱','金烨'],
'年龄': [18, 19, 20, 21, 19, 20, 18, 20, 21],
'性别': ['男', '女', '男', '男', '女', '男', '女', '女', '男'],
'身高 (cm)': [175, 165, 178, 175, 160, 180, 167, 170, 185],
'体重 (kg)': [65, 60, 70, 75, 55, 70, 52, 53, 73]
}
df = pd.DataFrame(data)
print(df)
# (1)根据年级信息为分组键,对学生信息进行分组,并输出大一学生信息
grouped = df.groupby('年级')
print("大一学生信息:")
print(grouped.get_group('大一'))
# (2)分别计算出四个年级中身高最高的同学
print("每个年级身高最高的同学:")
print(df.loc[df.groupby('年级')['身高 (cm)'].idxmax()])
# (3)计算大一学生与大三学生的平均体重
avg_weight_freshman = grouped.get_group('大一')['体重 (kg)'].mean()
avg_weight_junior = grouped.get_group('大三')['体重 (kg)'].mean()
print("大一学生平均体重:", avg_weight_freshman)
print("大三学生平均体重:", avg_weight_junior)
现有如图6-40所示的股票数据,根据图中的数据,完成以下需求:
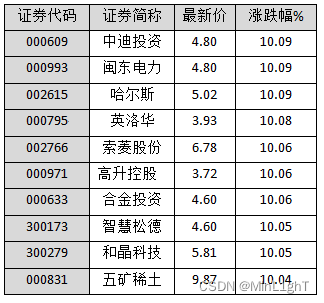
- 使用DataFrame创建该股票数据。
- 以证券简称为x轴,最新价为y轴使用条形图展示,将生成的条形图图以shares_bar.png为文件名保存在桌面上。
import pandas as pd
# 创建股票数据
data = {
'证券代码': ['000609', '000993', '002615', '000795', '002766', '000971', '000633', '300173', '300279', '000831'],
'证券简称': ['中迪投资','闽东电力','哈尔斯','英洛华','索菱股份','高升控股','合金投资','智慧松德','和晶科技','五矿稀土'],
'最新价': [4.80, 4.80, 5.02, 3.93, 6.78, 3.72, 4.60, 4.60, 5.81, 9.87],
'涨跌幅(%)': [10.09, 10.09, 10.09, 10.08, 10.06, 10.06, 10.06, 10.05, 10.05, 10.04]
}
df = pd.DataFrame(data)
# 绘制条形图
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei'] # 正常显示中文标签
plt.rcParams['axes.unicode_minus']=False # 正常显示负号
plt.bar(df['证券简称'], df['最新价']) # 创建条形图
plt.xlabel('证券简称') # 设置x轴标签
plt.ylabel('最新价') # 设置y轴标签
plt.title('股票最新价条形图') # 设置标题
# 保存条形图
plt.savefig(r"C:\Users\admin\Desktop\shares_bar.png")
plt.show() # 显示图形
导入数据
这部分代码用于加载乳腺癌数据集,并显示基本的数据信息。
from sklearn.datasets import load_breast_cancer
# 加载数据集
cancer = load_breast_cancer()
print('breast_cancer数据集的样本数: \n', len(cancer))
print('breast_cancer数据集的类型: \n', type(cancer))
# 数据集的基本信息
print('breast_cancer数据集的特征数: ', cancer.data.shape[1])
print('breast_cancer数据集的类别: ', cancer.target_names)
# 显示特征标签及名称
print('breast_cancer数据集的标签: \n', cancer.target)
print('breast_cancer数据集的特征名称: \n', cancer.feature_names)
数据拆分
这部分代码用于将数据集分为训练集和测试集,这是机器学习模型开发过程中的标准步骤,以确保模型能够在未见过的数据上进行泛化。
from sklearn.model_selection import train_test_split
print('breast_cancer数据的形状: ', cancer.data.shape)
# 拆分数据集为训练集和测试集
data_train, data_test, target_train, target_test = train_test_split(
cancer.data, cancer.target, test_size=0.2, random_state=42
)
# 输出数据形状以验证拆分
print('训练集数据的形状: ', data_train.shape)
print('测试集数据的形状: ', data_test.shape)
print('训练集标签的形状: ', target_train.shape)
print('测试集标签的形状: ', target_test.shape)PCA降维
这部分代码使用主成分分析(PCA)对数据进行降维处理,以减少模型复杂度和训练时间,同时尽量保留数据中的重要信息。
from sklearn.preprocessing import MinMaxScaler
import numpy as np
# 数据标准化
scaler = MinMaxScaler().fit(data_train)
data_train_scaled = scaler.transform(data_train)
data_test_scaled = scaler.transform(data_test)
print('标准化前训练集数据的最小值为:', np.min(data_train))
print('标准化前训练集数据的最大值为:', np.max(data_train))
print('标准化后训练集数据的最小值为:', np.min(data_train_scaled)) # Assuming 'cancer_tarinscaler' should be 'data_train_scaled'
print('标准化后训练集数据的最大值为:', np.max(data_train_scaled)) # Assuming 'cancer_tarinscaler' should be 'data_train_scaled'
print('标准化前测试集数据的最小值为:', np.min(data_test))
print('标准化前测试集数据的最大值为:', np.max(data_test))
print('标准化后测试集数据的最小值为:', np.min(data_test_scaled)) # Assuming 'cancer_testscaler' should be 'data_test_scaled'
print('标准化后测试集数据的最大值为:', np.max(data_test_scaled)) # Assuming 'cancer_testscaler' should be 'data_test_scaled'
from sklearn.decomposition import PCA
# 应用PCA降维
pca_model = PCA(n_components=10).fit(data_train_scaled)
data_train_pca = pca_model.transform(data_train_scaled)
data_test_pca = pca_model.transform(data_test_scaled)
# 输出PCA处理后的数据形状
print('PCA降维前训练集的形状: ', data_train.shape)
print('PCA降维前测试集的形状: ', data_test.shape)
print('PCA降维后训练集的形状: ', data_train_pca.shape)
print('PCA降维后测试集的形状: ', data_test_pca.shape)鸢尾花数据K-Means聚类分析
# 导入必要的库
from sklearn.datasets import load_iris
from sklearn.preprocessing import MinMaxScaler
from sklearn.cluster import KMeans
# 加载鸢尾花数据集
iris = load_iris()
iris_data = iris['data'] # 数据集的特征数据
iris_target = iris['target'] # 数据集的标签数据
iris_names = iris['feature_names'] # 数据集的特征名称
# 数据标准化
scaler = MinMaxScaler().fit(iris_data) # 创建标准化模型并拟合数据
iris_data_scaled = scaler.transform(iris_data) # 应用标准化模型到数据
# 应用K-Means聚类算法
kmeans = KMeans(n_clusters=3, random_state=123).fit(iris_data_scaled) # 创建K-Means模型,并指定簇的数量为3,随机状态123,然后拟合标准化后的数据
print('构建的KMeans模型为:\n', kmeans) # 打印模型的详细配置
# 使用模型进行预测
result = kmeans.predict([[1.5, 1.5, 1.5, 1.5]]) # 使用模型预测新的数据点的簇标签
print('花瓣长度宽度为1.5的鸢尾花预测的簇标签为:', result[0]) # 输出预测的簇标签















 9440
9440











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









