






项目要求
根据用户上网的搜索记录对每天的热点搜索词进行统计,以了解用户所关心的热点话题。
要求完成:统计每天搜索数量前3名的搜索词(同一天中同一用户多次搜索同一个搜索词视为1次)。
数据

idea中直接运行
导入依赖
<dependencies>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-core -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.3.3</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.scala-tools/maven-scala-plugin -->
<dependency>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<version>2.11</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.maven.plugins/maven-eclipse-plugin -->
<dependency>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-eclipse-plugin</artifactId>
<version>2.5.1</version>
</dependency>
代码
package org.example
import org.apache.spark.{SparkConf, SparkContext}
object SearchRecordAnalysis {
def main(args: Array[String]): Unit = {
// 创建Spark配置
val conf = new SparkConf().setAppName("SearchRecordAnalysis").setMaster("local")
// 创建Spark上下文
val sc = new SparkContext(conf)
//读取数据文件
val searchRDD = sc.textFile("file:///export/data/keywords.txt")
// 将每条记录映射为(date, user, keyword)的元组
val mappedRDD = searchRDD.map { record =>
val fields = record.split(",")
(fields(0), fields(1), fields(2))
}
// 去重:同一天同一用户多次搜索同一个关键词只算一次
val distinctRDD = mappedRDD.distinct()
// 统计每天每个关键词的搜索次数
val keywordCountRDD = distinctRDD.map { case (date, user, keyword) =>
((date, keyword), 1)
}.reduceByKey(_ + _)
// 按日期分组,并找出每天搜索次数前3的关键词
val top3KeywordsByDate = keywordCountRDD.groupBy { case ((date, keyword), count) =>
date
}.mapValues { grouped =>
grouped.toList.sortBy { case ((_, _), count) => -count }.take(3).map { case ((_, keyword), count) =>
(keyword, count)
}
}
// 按日期排序输出结果
val sortedResult = top3KeywordsByDate.collect().sortBy { case (date, _) =>
date
}
// 输出结果
sortedResult.foreach { case (date, top3Keywords) =>
println(s"日期:$date")
top3Keywords.zipWithIndex.foreach { case ((keyword, count), index) =>
println(s"排名${index + 1}:搜索词:$keyword,搜索次数:$count")
}
println()
}
// 停止Spark上下文
sc.stop()
}
}
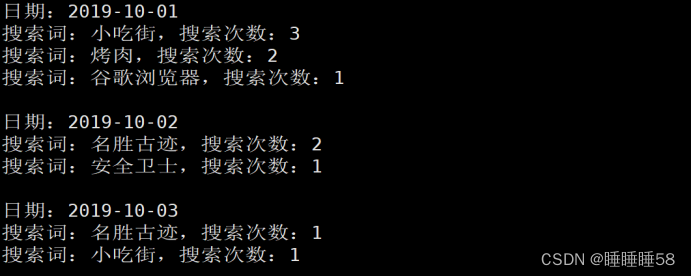
结果

scala直接运行
读取数据文件
val rdd = sc.textFile("file:///export/data/keywords.txt")

查看数据文件
rdd.collect()
将每行记录映射为(date, user, keyword)的元组
val mappedRDD = rdd.map { record =>
| val fields = record.split(",")
| (fields(0), fields(1), fields(2))
}
去除重复的搜索记录,以同一天中同一用户多次搜索同一个搜索词视为1次
val distinctRDD = mappedRDD.distinct()
对每天每个搜索词进行计数
val countRDD = distinctRDD.map(record => ((record._1, record._3), 1)).reduceByKey(_ + _)
将结果按日期分组
val groupedRDD = countRDD.map{ case ((date, keyword), count) => (date, (keyword, count))}.groupByKey()
取出每天搜索数量前3名的搜索词
val top3RDD = groupedRDD.mapValues{ iter => iter.toList.sortBy(-_._2).take(3) }
将结果按日期分组
val resultByDate = top3RDD.collectAsMap()
输出结果
resultByDate.toSeq.sortBy(_._1).foreach { case (date, keywords) =>
| println(s"日期:$date")
| for ((keyword, count) <- keywords) {
| println(s"搜索词:$keyword,搜索次数:$count")
| }
| println()
| }















 408
408











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









