







一、项目背景要求
- 根据用户上网的搜索记录对每天的热点搜索词进行统计,以了解用户所关心的热点话题。
- 要求完成:
1.统计每天搜索数量前3名的搜索词(同一天中同一用户多次搜索同一个搜索词视为1次)
2.使用scala编程,并用 spark sql 运行结果
二、数据文件
- 字段分别是:时间,用户,搜索词
2019-10-01,tom,小吃街
2019-10-01,jack,谷歌浏览器
2019-10-01,jack,小吃街
2019-10-01,look,小吃街
2019-10-01,steven,烤肉
2019-10-01,lojas,烤肉
2019-10-01,look,小吃街
2019-10-02,marry,安全卫士
2019-10-02,tom,名胜古迹
2019-10-02,marry,安全卫士
2019-10-02,leo,名胜古迹
2019-10-03,tom,名胜古迹
2019-10-03,leo,小吃街
三、项目开发
环境配置
- idea编程,创建maven项目
- 下载scala,并配置好scala系统变量
- 导入依赖
<dependencies>
<!-- scala和spark sql 的依赖 -->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>版本号</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>版本号</version>
</dependency>
</dependencies>
代码编写
创建一个 scala 的 object 类
package com.task.hotWord
import org.apache.spark.sql.types.{StringType, StructField, StructType}
import org.apache.spark.sql.{DataFrame, SparkSession}
object hotWordCnt {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.appName("hotSearchCount")
// .master("local[*]") //本地运行模式
.getOrCreate()
val value: StructType = StructType(List(
StructField("time", StringType, nullable = true),
StructField("user", StringType, nullable = true),
StructField("word", StringType, nullable = true)
))
val line: DataFrame = spark.read
.schema(value)
// .csv("E:\\IdeaProject\\hadoop\\project\\src\\main\\java\\com\\data\\keywords.txt")
.csv(args(0))
line.createTempView("hotWord")
val frame: DataFrame = spark.sql(
"""
|select
|time ,
|word
|from (
| select
| time,
| word,
| count(distinct user) as cnt,
| row_number () over (partition by time order by time,count(distinct user) desc) as row
| from hotWord
| group by time,word
|) t
|where row <= 3
|""".stripMargin)
frame.show()
frame.write
.format("csv")
.option("header",true)
.save(args(1))
spark.stop()
}
}
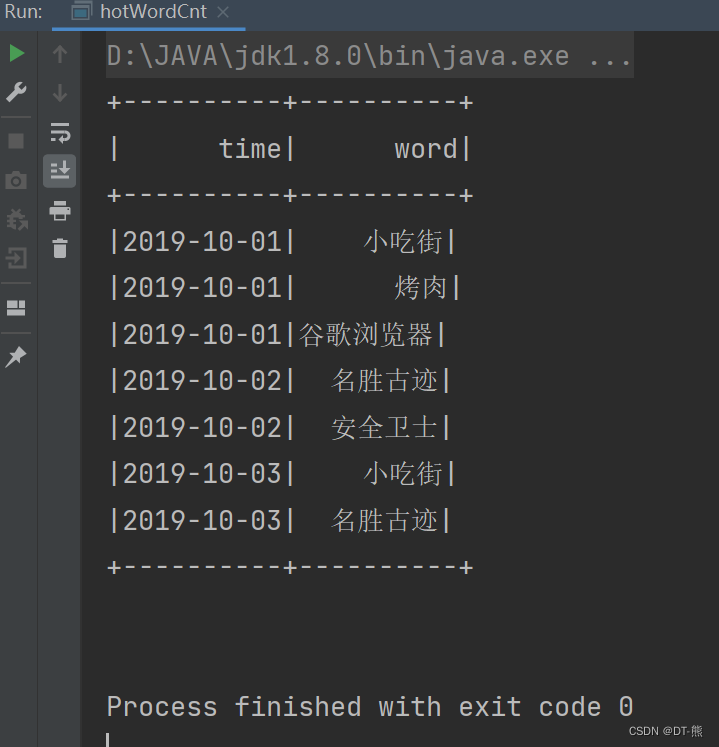
结果展示:















 1498
1498











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









